

By/Gao Kaiyuan Image Source: Internet
Introduction
[email protected]
I have been reviewing materials related to Paddle, so I decided to take a closer look at the source code of Baidu’s ERNIE. When I skimmed through it before, I noticed that ERNIE 2.0 and ERNIE-tiny are quite similar to BERT. I wonder what changes have been made in the updates~ After finishing, I will organize a summary similar to the one below. If any colleagues researching Paddle or ERNIE want to discuss, feel free to add me, haha.
Original Content @2019.05.16
The BERT model has been out for a while now. I have previously read papers and blogs interpreting it: NLP’s Killer Tool BERT Model Interpretation[1], but I had not looked closely at the implementation in the source code. Recently, I had the opportunity to use it, so I took some time to examine it and record my findings for discussion.
Note that the source code reading series requires prior knowledge of NLP-related concepts, such as the attention mechanism, transformer framework, as well as basic knowledge of Python and TensorFlow. The principles of BERT are not the focus of this article.
Here is a compilation of materials related to BERT: Summary of BERT-related papers, articles, and code resources[2]
Today, I will introduce the main model implementation of BERT – BertModel, with the code located in:
-
modeling.py module[3]
There are comments inside the code blocks as well as outside.
If there are any misunderstandings in the interpretation, please feel free to point them out~
1. Configuration Class (BertConfig)
This part of the code mainly defines some default parameters for the BERT model and includes some file handling functions.
class BertConfig(object):
"""Configuration class for the BERT model."""
def __init__(self,
vocab_size,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
initializer_range=0.02):
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.hidden_act = hidden_act
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.initializer_range = initializer_range
@classmethod
def from_dict(cls, json_object):
"""Constructs a `BertConfig` from a Python dictionary of parameters."""
config = BertConfig(vocab_size=None)
for (key, value) in six.iteritems(json_object):
config.__dict__[key] = value
return config
@classmethod
def from_json_file(cls, json_file):
"""Constructs a `BertConfig` from a json file of parameters."""
with tf.gfile.GFile(json_file, "r") as reader:
text = reader.read()
return cls.from_dict(json.loads(text))
def to_dict(self):
"""Serializes this instance to a Python dictionary."""
output = copy.deepcopy(self.__dict__)
return output
def to_json_string(self):
"""Serializes this instance to a JSON string."""
return json.dumps(self.to_dict(), indent=2, sort_keys=True) + "\n"
Parameter Meanings
-
vocab_size: Size of the vocabulary -
hidden_size: Number of neurons in the hidden layer -
num_hidden_layers: Number of hidden layers in the Transformer encoder -
num_attention_heads: Number of heads in multi-head attention -
intermediate_size: Number of neurons in the intermediate hidden layer (e.g., feed-forward layer) -
hidden_act: Activation function for the hidden layer -
hidden_dropout_prob: Dropout rate for the hidden layer -
attention_probs_dropout_prob: Dropout rate for the attention part -
max_position_embeddings: Maximum position encoding -
type_vocab_size: Vocabulary size for token_type_ids -
initializer_range: Standard deviation for truncated_normal_initializer initialization method
One thing to note is that you may find the type_vocab_size parameter a bit confusing at first. It actually refers to the Segment A and Segment B in the next sentence prediction task. This is also explained in the downloaded bert_config.json file, where the default value should be 2. Refer to this Issue[4]
2. Obtaining Word Vectors (Embedding_lookup)
For the input word_ids, it returns the embedding table. One can use either one-hot or tf.gather()
def embedding_lookup(input_ids, # word_id: 【batch_size, seq_length】
vocab_size,
embedding_size=128,
initializer_range=0.02,
word_embedding_name="word_embeddings",
use_one_hot_embeddings=False):
# The default input shape is 【batch_size, seq_length, input_num】
# If the input is 2D 【batch_size, seq_length】, expand to 【batch_size, seq_length, 1】
if input_ids.shape.ndims == 2:
input_ids = tf.expand_dims(input_ids, axis=[-1])
embedding_table = tf.get_variable(
name=word_embedding_name,
shape=[vocab_size, embedding_size],
initializer=create_initializer(initializer_range))
flat_input_ids = tf.reshape(input_ids, [-1]) # 【batch_size*seq_length*input_num】
if use_one_hot_embeddings:
one_hot_input_ids = tf.one_hot(flat_input_ids, depth=vocab_size)
output = tf.matmul(one_hot_input_ids, embedding_table)
else: # Indexing
output = tf.gather(embedding_table, flat_input_ids)
input_shape = get_shape_list(input_ids)
# output: [batch_size, seq_length, num_inputs]
# Reshape to: [batch_size, seq_length, num_inputs*embedding_size]
output = tf.reshape(output,
input_shape[0:-1] + [input_shape[-1] * embedding_size])
return (output, embedding_table)
Parameter Meanings
-
input_ids: Word ID 【batch_size, seq_length】 -
vocab_size: Embedding vocabulary -
embedding_size: Embedding dimension -
initializer_range: Embedding initialization range -
word_embedding_name: Name for the embedding table -
use_one_hot_embeddings: Whether to use one-hot embeddings -
Return: 【batch_size, seq_length, embedding_size】
3. Subsequent Processing of Word Vectors (embedding_postprocessor)
We know that the BERT model’s input consists of three parts: token embedding, segment embedding, and position embedding. In the previous section, we only obtained the token embedding. This part of the code refines the information, adds regularization, and dropout, then outputs the final embedding. Note that in the Transformer paper, the position embedding is generated by fixed values from the sin/cos function, while in this code implementation, it is randomly generated like ordinary word embeddings, making it trainable. The reason for this choice may be that the data used for training BERT is much larger than that in the original Transformer, allowing the model to learn independently.
def embedding_postprocessor(input_tensor, # [batch_size, seq_length, embedding_size]
use_token_type=False,
token_type_ids=None,
token_type_vocab_size=16, # Typically 2
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=0.02,
max_position_embeddings=512, # Max position encoding, must be >= max_seq_len
dropout_prob=0.1):
input_shape = get_shape_list(input_tensor, expected_rank=3) # 【batch_size, seq_length, embedding_size】
batch_size = input_shape[0]
seq_length = input_shape[1]
width = input_shape[2]
output = input_tensor
# Segment position information
if use_token_type:
if token_type_ids is None:
raise ValueError("`token_type_ids` must be specified if"
"`use_token_type` is True.")
token_type_table = tf.get_variable(
name=token_type_embedding_name,
shape=[token_type_vocab_size, width],
initializer=create_initializer(initializer_range))
# Since token-type-table is relatively small, one-hot embedding is used here for acceleration
flat_token_type_ids = tf.reshape(token_type_ids, [-1])
one_hot_ids = tf.one_hot(flat_token_type_ids, depth=token_type_vocab_size)
token_type_embeddings = tf.matmul(one_hot_ids, token_type_table)
token_type_embeddings = tf.reshape(token_type_embeddings,
[batch_size, seq_length, width])
output += token_type_embeddings
# Position embedding information
if use_position_embeddings:
# Ensure seq_length is less than or equal to max_position_embeddings
assert_op = tf.assert_less_equal(seq_length, max_position_embeddings)
with tf.control_dependencies([assert_op]):
full_position_embeddings = tf.get_variable(
name=position_embedding_name,
shape=[max_position_embeddings, width],
initializer=create_initializer(initializer_range))
# Here, position embedding is a learnable parameter, [max_position_embeddings, width]
# However, the actual input sequence usually does not reach max_position_embeddings
# Thus, to improve training speed, use tf.slice to extract the embedding of the sentence length
position_embeddings = tf.slice(full_position_embeddings, [0, 0],
[seq_length, -1])
num_dims = len(output.shape.as_list())
# Word embedding tensor is [batch_size, seq_length, width]
# Since position encoding is independent of input content, its shape is always [seq_length, width]
# We cannot add position embedding to word embedding
# Therefore, we need to expand the position encoding to [1, seq_length, width]
# Then we can add them through broadcasting.
position_broadcast_shape = []
for _ in range(num_dims - 2):
position_broadcast_shape.append(1)
position_broadcast_shape.extend([seq_length, width])
position_embeddings = tf.reshape(position_embeddings,
position_broadcast_shape)
output += position_embeddings
output = layer_norm_and_dropout(output, dropout_prob)
return output
4. Constructing Attention Mask
This part of the code constructs the attention_mask for the attention visual field. Since each sample goes through a padding process, the padding part cannot attend to other parts during self-attention. The input is the padding-processed [batch_size, from_seq_length,…] of input_ids and the mask marking vector of shape [batch_size, to_seq_length].
def create_attention_mask_from_input_mask(from_tensor, to_mask):
from_shape = get_shape_list(from_tensor, expected_rank=[2, 3])
batch_size = from_shape[0]
from_seq_length = from_shape[1]
to_shape = get_shape_list(to_mask, expected_rank=2)
to_seq_length = to_shape[1]
to_mask = tf.cast(
tf.reshape(to_mask, [batch_size, 1, to_seq_length]), tf.float32)
broadcast_ones = tf.ones(
shape=[batch_size, from_seq_length, 1], dtype=tf.float32)
mask = broadcast_ones * to_mask
return mask
5. Attention Layer (Attention Layer)
This part of the code implements multi-head attention, primarily derived from the paper “Attention is All You Need”. In the attention mechanism, the from_tensor serves as the query, while the to_tensor serves as the key and value. When both are the same, it is self-attention. For a more detailed introduction to attention, please refer to 【Understanding Attention Mechanism Principles and Models[5]】.
def attention_layer(from_tensor, # 【batch_size, from_seq_length, from_width】
to_tensor, # 【batch_size, to_seq_length, to_width】
attention_mask=None, # 【batch_size, from_seq_length, to_seq_length】
num_attention_heads=1, # Number of attention heads
size_per_head=512, # Size of each head
query_act=None, # Activation function for query transformation
key_act=None, # Activation function for key transformation
value_act=None, # Activation function for value transformation
attention_probs_dropout_prob=0.0, # Dropout for attention layer
initializer_range=0.02, # Initialization range
do_return_2d_tensor=False, # Whether to return a 2D tensor.
# If True, output shape is 【batch_size*from_seq_length, num_attention_heads*size_per_head】
# If False, output shape is 【batch_size, from_seq_length, num_attention_heads*size_per_head】
batch_size=None, # If input is 3D,
# then batch is the first dimension, but 3D may have been compressed to 2D, so batch_size needs to be specified
from_seq_length=None, # Same as above
to_seq_length=None): # Same as above
def transpose_for_scores(input_tensor, batch_size, num_attention_heads,
seq_length, width):
output_tensor = tf.reshape(
input_tensor, [batch_size, seq_length, num_attention_heads, width])
output_tensor = tf.transpose(output_tensor, [0, 2, 1, 3]) #[batch_size, num_attention_heads, seq_length, width]
return output_tensor
from_shape = get_shape_list(from_tensor, expected_rank=[2, 3])
to_shape = get_shape_list(to_tensor, expected_rank=[2, 3])
if len(from_shape) != len(to_shape):
raise ValueError(
"The rank of `from_tensor` must match the rank of `to_tensor`.")
if len(from_shape) == 3:
batch_size = from_shape[0]
from_seq_length = from_shape[1]
to_seq_length = to_shape[1]
elif len(from_shape) == 2:
if (batch_size is None or from_seq_length is None or to_seq_length is None):
raise ValueError(
"When passing in rank 2 tensors to attention_layer, the values "
"for `batch_size`, `from_seq_length`, and `to_seq_length` "
"must all be specified.")
# To facilitate shape annotation, the following abbreviations are used:
# B = batch size (number of sequences)
# F = `from_tensor` sequence length
# T = `to_tensor` sequence length
# N = `num_attention_heads`
# H = `size_per_head`
# Compress from_tensor and to_tensor into 2D tensors
from_tensor_2d = reshape_to_matrix(from_tensor) # 【B*F, hidden_size】
to_tensor_2d = reshape_to_matrix(to_tensor) # 【B*T, hidden_size】
# Input from_tensor into a fully connected layer to obtain query_layer
# `query_layer` = [B*F, N*H]
query_layer = tf.layers.dense(
from_tensor_2d,
num_attention_heads * size_per_head,
activation=query_act,
name="query",
kernel_initializer=create_initializer(initializer_range))
# Input from_tensor into a fully connected layer to obtain key_layer
# `key_layer` = [B*T, N*H]
key_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=key_act,
name="key",
kernel_initializer=create_initializer(initializer_range))
# Same as above
# `value_layer` = [B*T, N*H]
value_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=value_act,
name="value",
kernel_initializer=create_initializer(initializer_range))
# Transform query_layer into multi-head: [B*F, N*H] ==> [B, F, N, H] ==> [B, N, F, H]
query_layer = transpose_for_scores(query_layer, batch_size,
num_attention_heads, from_seq_length,
size_per_head)
# Transform key_layer into multi-head: [B*T, N*H] ==> [B, T, N, H] ==> [B, N, T, H]
key_layer = transpose_for_scores(key_layer, batch_size, num_attention_heads,
to_seq_length, size_per_head)
# Calculate attention scores by performing dot product between query and key, then scale, refer to the original paper for the formula
# `attention_scores` = [B, N, F, T]
attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True)
attention_scores = tf.multiply(attention_scores,
1.0 / math.sqrt(float(size_per_head)))
if attention_mask is not None:
# `attention_mask` = [B, 1, F, T]
attention_mask = tf.expand_dims(attention_mask, axis=[1])
# If the elements in attention_mask are 1, then through the following operation, (1-1)*-10000, adder is 0
# If the elements in attention_mask are 0, then through the following operation, (1-0)*-10000, adder is -10000
adder = (1.0 - tf.cast(attention_mask, tf.float32)) * -10000.0
# The attention score we ultimately obtain is generally not very large,
# so the operation above makes the score for mask=0 effectively negative infinity
attention_scores += adder
# Negative infinity becomes 0 after softmax, which means that the position with mask=0 does not compute attention scores
# `attention_probs` = [B, N, F, T]
attention_probs = tf.nn.softmax(attention_scores)
# Apply dropout to attention_probs, although this seems a bit strange, the original Transformer paper does it this way
attention_probs = dropout(attention_probs, attention_probs_dropout_prob)
# `value_layer` = [B, T, N, H]
value_layer = tf.reshape(
value_layer,
[batch_size, to_seq_length, num_attention_heads, size_per_head])
# `value_layer` = [B, N, T, H]
value_layer = tf.transpose(value_layer, [0, 2, 1, 3])
# `context_layer` = [B, N, F, H]
context_layer = tf.matmul(attention_probs, value_layer)
# `context_layer` = [B, F, N, H]
context_layer = tf.transpose(context_layer, [0, 2, 1, 3])
if do_return_2d_tensor:
# `context_layer` = [B*F, N*H]
context_layer = tf.reshape(
context_layer,
[batch_size * from_seq_length, num_attention_heads * size_per_head])
else:
# `context_layer` = [B, F, N*H]
context_layer = tf.reshape(
context_layer,
[batch_size, from_seq_length, num_attention_heads * size_per_head])
return context_layer
To summarize, the main flow of the attention layer is:
-
Verify the shape of the input tensor and extract batch_size, from_seq_length, to_seq_length; -
Convert the input to a 2D matrix if it is a 3D tensor; -
Use from_tensoras the query andto_tensoras the key and value, obtainingquery_layer,key_layer, andvalue_layerafter passing through a fully connected layer; -
Transform the above tensors into multi-head using transpose_for_scores; -
Calculate attention_scoreandattention_probsaccording to the formula in the paper (note the trick withattention_mask):
-
Multiply the resulting attention_probswith the value and return a 2D or 3D tensor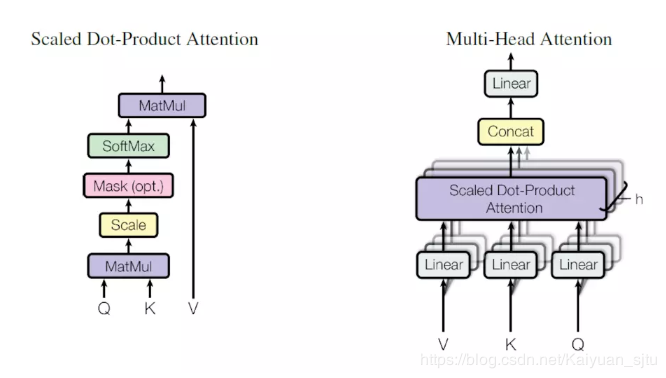
6. Transformer
The following code is the core code of the well-known Transformer, which can be considered a reproduction of the original code from “Attention is All You Need”. Refer to the 【original paper[6]】 and 【original code[7]】.
def transformer_model(input_tensor, # 【batch_size, seq_length, hidden_size】
attention_mask=None, # 【batch_size, seq_length, seq_length】
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
intermediate_act_fn=gelu, # Activation function for feed-forward layer
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
initializer_range=0.02,
do_return_all_layers=False):
# Note that because the final output must have hidden_size, we have num_attention_head areas,
# Each head area has size_per_head more hidden layers
# So hidden_size = num_attention_head * size_per_head
if hidden_size % num_attention_heads != 0:
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (hidden_size, num_attention_heads))
attention_head_size = int(hidden_size / num_attention_heads)
input_shape = get_shape_list(input_tensor, expected_rank=3)
batch_size = input_shape[0]
seq_length = input_shape[1]
input_width = input_shape[2]
# Since there are residual operations in the encoder, the shapes need to be the same
if input_width != hidden_size:
raise ValueError("The width of the input tensor (%d) != hidden size (%d)" %
(input_width, hidden_size))
# Reshape operations are fast on CPU/GPU, but not friendly on TPU
# Therefore, to avoid frequent reshaping between 2D and 3D, we represent all 3D tensors as 2D matrices
prev_output = reshape_to_matrix(input_tensor)
all_layer_outputs = []
for layer_idx in range(num_hidden_layers):
with tf.variable_scope("layer_%d" % layer_idx):
layer_input = prev_output
with tf.variable_scope("attention"):
# Multi-head attention
attention_heads = []
with tf.variable_scope("self"):
# Self-attention
attention_head = attention_layer(
from_tensor=layer_input,
to_tensor=layer_input,
attention_mask=attention_mask,
num_attention_heads=num_attention_heads,
size_per_head=attention_head_size,
attention_probs_dropout_prob=attention_probs_dropout_prob,
initializer_range=initializer_range,
do_return_2d_tensor=True,
batch_size=batch_size,
from_seq_length=seq_length,
to_seq_length=seq_length)
attention_heads.append(attention_head)
attention_output = None
if len(attention_heads) == 1:
attention_output = attention_heads[0]
else:
# If there are multiple heads, concatenate them
attention_output = tf.concat(attention_heads, axis=-1)
# Perform a linear mapping on the attention output, to make the shape consistent with the input
# Then dropout + residual + norm
with tf.variable_scope("output"):
attention_output = tf.layers.dense(
attention_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
attention_output = dropout(attention_output, hidden_dropout_prob)
attention_output = layer_norm(attention_output + layer_input)
# Feed-forward
with tf.variable_scope("intermediate"):
intermediate_output = tf.layers.dense(
attention_output,
intermediate_size,
activation=intermediate_act_fn,
kernel_initializer=create_initializer(initializer_range))
# Use linear transformation on the output of the feed-forward layer to return to ‘hidden_size’
# Then dropout + residual + norm
with tf.variable_scope("output"):
layer_output = tf.layers.dense(
intermediate_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
layer_output = dropout(layer_output, hidden_dropout_prob)
layer_output = layer_norm(layer_output + attention_output)
prev_output = layer_output
all_layer_outputs.append(layer_output)
if do_return_all_layers:
final_outputs = []
for layer_output in all_layer_outputs:
final_output = reshape_from_matrix(layer_output, input_shape)
final_outputs.append(final_output)
return final_outputs
else:
final_output = reshape_from_matrix(prev_output, input_shape)
return final_output
Using the accompanying diagram will enhance understanding, as BERT only contains the encoder, and there is no decoder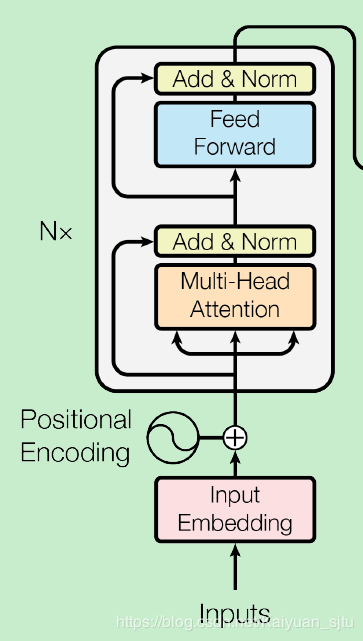
7. Function Entry (Init)
The constructor of the BertModel class. With the groundwork laid in the previous sections, we can implement the BERT model now.
def __init__(self,
config, # BertConfig object
is_training,
input_ids, # 【batch_size, seq_length】
input_mask=None, # 【batch_size, seq_length】
token_type_ids=None, # 【batch_size, seq_length】
use_one_hot_embeddings=False, # Whether to use one-hot; otherwise tf.gather()
scope=None):
config = copy.deepcopy(config)
if not is_training:
config.hidden_dropout_prob = 0.0
config.attention_probs_dropout_prob = 0.0
input_shape = get_shape_list(input_ids, expected_rank=2)
batch_size = input_shape[0]
seq_length = input_shape[1]
# Not masking, all elements are 1
if input_mask is None:
input_mask = tf.ones(shape=[batch_size, seq_length], dtype=tf.int32)
if token_type_ids is None:
token_type_ids = tf.zeros(shape=[batch_size, seq_length], dtype=tf.int32)
with tf.variable_scope(scope, default_name="bert"):
with tf.variable_scope("embeddings"):
# Word embedding
(self.embedding_output, self.embedding_table) = embedding_lookup(
input_ids=input_ids,
vocab_size=config.vocab_size,
embedding_size=config.hidden_size,
initializer_range=config.initializer_range,
word_embedding_name="word_embeddings",
use_one_hot_embeddings=use_one_hot_embeddings)
# Add position embedding and segment embedding
# Layer norm + dropout
self.embedding_output = embedding_postprocessor(
input_tensor=self.embedding_output,
use_token_type=True,
token_type_ids=token_type_ids,
token_type_vocab_size=config.type_vocab_size,
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=config.initializer_range,
max_position_embeddings=config.max_position_embeddings,
dropout_prob=config.hidden_dropout_prob)
with tf.variable_scope("encoder"):
# input_ids is the padded word_ids: [25, 120, 34, 0, 0]
# input_mask is the valid word marking: [1, 1, 1, 0, 0]
attention_mask = create_attention_mask_from_input_mask(
input_ids, input_mask)
# Stacking transformer modules
# `sequence_output` shape = [batch_size, seq_length, hidden_size].
self.all_encoder_layers = transformer_model(
input_tensor=self.embedding_output,
attention_mask=attention_mask,
hidden_size=config.hidden_size,
num_hidden_layers=config.num_hidden_layers,
num_attention_heads=config.num_attention_heads,
intermediate_size=config.intermediate_size,
intermediate_act_fn=get_activation(config.hidden_act),
hidden_dropout_prob=config.hidden_dropout_prob,
attention_probs_dropout_prob=config.attention_probs_dropout_prob,
initializer_range=config.initializer_range,
do_return_all_layers=True)
# `self.sequence_output` is the output of the last layer, shape is 【batch_size, seq_length, hidden_size】
self.sequence_output = self.all_encoder_layers[-1]
# The 'pooler' part converts the encoder output 【batch_size, seq_length, hidden_size】
# to 【batch_size, hidden_size】
with tf.variable_scope("pooler"):
# Take the first token tensor corresponding to the last layer's [CLS], which is crucial for classification tasks
# sequence_output[:, 0:1, :] gets [batch_size, 1, hidden_size]
# We need to use squeeze to remove the second dimension
first_token_tensor = tf.squeeze(self.sequence_output[:, 0:1, :], axis=1)
# Then add a fully connected layer, output remains [batch_size, hidden_size]
self.pooled_output = tf.layers.dense(
first_token_tensor,
config.hidden_size,
activation=tf.tanh,
kernel_initializer=create_initializer(config.initializer_range))
Conclusion
With the in-depth understanding of the source code above, we will be more adept at using the BertModel. Here is a simple example of using the model:
# Assuming the input has been tokenized into word_ids. shape=[2, 3]
input_ids = tf.constant([[31, 51, 99], [15, 5, 0]])
input_mask = tf.constant([[1, 1, 1], [1, 1, 0]])
# segment_embedding. Indicates that the first two words of the first sample belong to sentence 1, and the last word belongs to sentence 2.
# The first word of the second sample belongs to sentence 1, the second word belongs to sentence 2, and the third element is 0 indicating padding.
# The original code is like this, but it seems unnecessary to use 2, I don't know if I misunderstood something.
token_type_ids = tf.constant([[0, 0, 1], [0, 2, 0]])
# Create an instance of BertConfig
config = modeling.BertConfig(vocab_size=32000, hidden_size=512,
num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
# Create an instance of BertModel
model = modeling.BertModel(config=config, is_training=True,
input_ids=input_ids, input_mask=input_mask, token_type_ids=token_type_ids)
label_embeddings = tf.get_variable(...)
# Get the first token of the last layer, which is the [CLS] vector representation, can be considered as a sentence embedding
pooled_output = model.get_pooled_output()
logits = tf.matmul(pooled_output, label_embeddings)
The main flow of building the BERT model is as follows:
-
Embed the input sequence (three parts), then proceed with ‘Attention is all you need’; -
Simply put, input the embedding into the transformer to obtain the output; -
In detail, it is embedding –> N * [multi-head attention –> Add(Residual) & Norm –> Feed-Forward –> Add(Residual) & Norm]; -
Isn’t it simple~ -
There are also some other auxiliary functions in the source code, which are not very difficult to understand, so I won’t elaborate further.
References
NLP’s Killer Tool BERT Model Interpretation: https://blog.csdn.net/Kaiyuan_sjtu/article/details/83991186
[2]Summary of BERT-related papers, articles, and code resources: http://www.52nlp.cn/bert-paper-%E8%AE%BA%E6%96%87-%E6%96%87%E7%AB%A0-%E4%BB%A3%E7%A0%81%E8%B5%84%E6%BA%90%E6%B1%87%E6%80%BB
[3]modeling.py module: https://github.com/google-research/bert/blob/master/modeling.py
[4]Refer to this Issue: https://github.com/google-research/bert/issues/16
[5]Understanding Attention Mechanism Principles and Models: https://blog.csdn.net/Kaiyuan_sjtu/article/details/81806123
[6]Original Paper: https://arxiv.org/abs/1706.03762
[7]Original Code: https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/transformer.py
Submission Email: [email protected]

▼SubmissionClick to Read the Original Like the article, give it a thumbs up