Integrating Text and Knowledge Graph Embeddings to Enhance RAG Performance
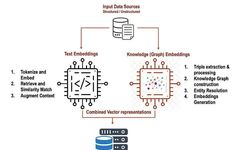
Source: DeepHub IMBA This article is approximately 4600 words long and is recommended to be read in 10 minutes. In this article, we will combine text and knowledge graphs to enhance the performance of our RAG. In our previous articles, we introduced examples of combining knowledge graphs with RAG. In this article, we will combine … Read more