
Source | Zhihu
Address | https://zhuanlan.zhihu.com/p/69290203
Author | Ph0en1x
Editor | WeChat public account on Machine Learning Algorithms and Natural Language Processing
This article is for academic sharing only. If there is any infringement, please contact us to delete it.
This article first introduces the basic structure of the Transformer in detail, and then introduces well-known applications based on Transformer such as GPT, BERT, MT-DNN, and GPT-2, along with GitHub links, to see how Transformer demonstrates its power in various famous models.
1. Replacing RNN – Transformer
Before introducing the Transformer, let’s review the structure of RNN.
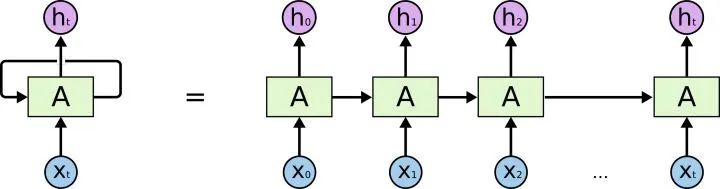
If you have a certain understanding of RNN, you must know that RNN has two obvious problems:
-
Efficiency issue: It needs to process words one by one, and the next word must wait for the hidden state output of the previous word before it can start processing.
-
If the distance of transmission is too long, there will also be gradient vanishing, gradient explosion, and forgetting problems.
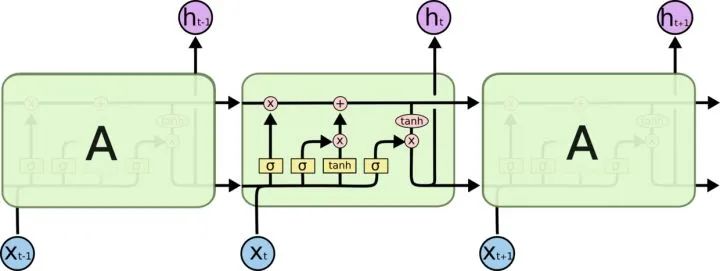
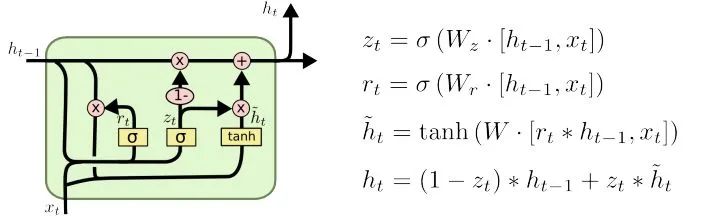
To alleviate the gradient and forgetting issues during transmission, various RNN cells were designed, the most famous two being LSTM and GRU.
LSTM (Long Short Term Memory)
GRU (Gated Recurrent Unit)
However, as a blogger on the internet puts it, this is like changing the wheels of a horse-drawn carriage; why not just switch to a car?
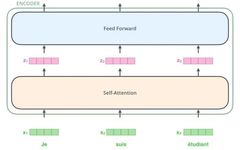
Thus, we have the core structure we are going to introduce in this article – Transformer. The Transformer is a work proposed by Google Brain in 2017, redesigned to address the weaknesses of RNN, solving the efficiency issues and defects during transmission, and outperforming RNN in many problems. The basic structure of Transformer is shown in the figure below; it is an N-to-N structure, meaning that each Transformer unit is equivalent to a layer of RNN, receiving all words of an entire sentence as input and then outputting a result for each word in the sentence. However, unlike RNN, Transformer can process all words in the sentence simultaneously, and the operation distance between any two words is 1, which effectively solves the efficiency and distance problems mentioned above.
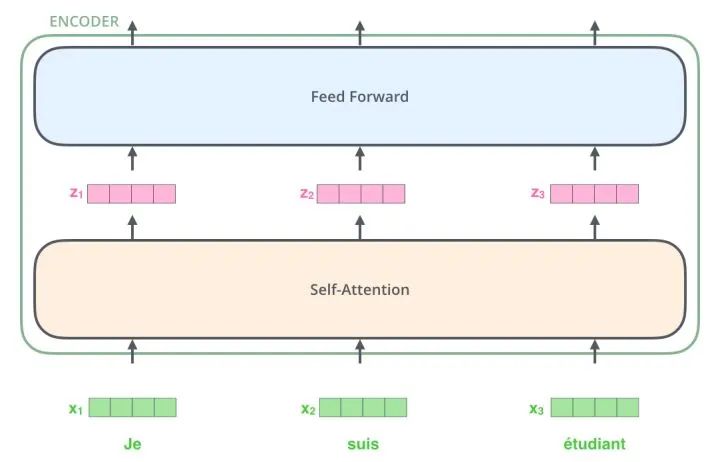
Each Transformer unit has two important sub-layers: the Self-Attention layer and the Feed Forward layer, which will be detailed later. The article builds a Seq2Seq-like language translation model using Transformer and designs two different Transformer structures for the Encoder and Decoder.
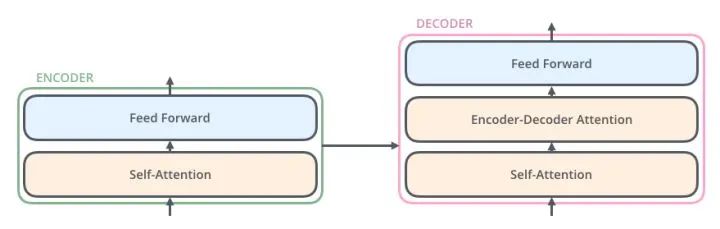
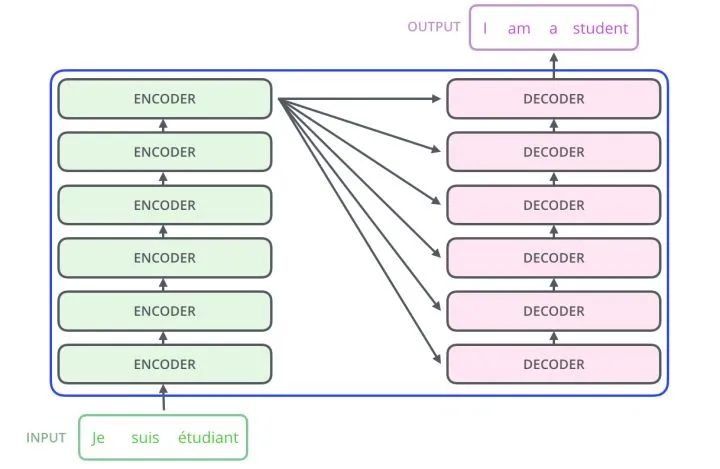
The Decoder Transformer has an additional Encoder-Decoder Attention layer compared to the Encoder Transformer, which receives outputs from the Encoder as parameters. Finally, by stacking according to the diagram below, we can complete the structure of the Transformer Seq2Seq.
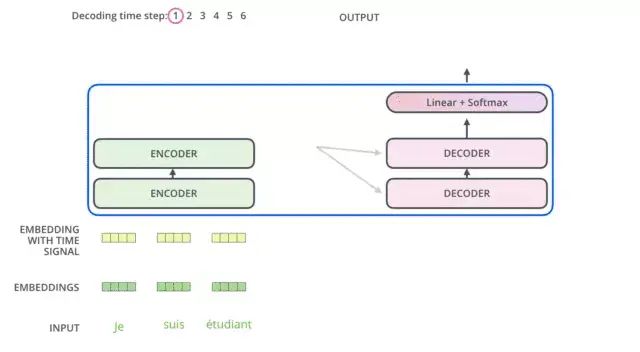
Let’s take an example to illustrate how to use this Transformer Seq2Seq for translation:
-
First, the Transformer encodes the sentence in the original language to obtain memory.
-
During the first decoding, the input is only a
<SOS>marker, indicating the start of the sentence. -
The decoder uses this unique input to generate the unique output, predicting the first word of the sentence.
-
During the second decoding, the output from the first decoding is appended to the input, turning the input into
<SOS>and the first word of the sentence (ground truth or the previous prediction), and the second output generated by the decoder is used to predict the second word of the sentence. This process continues (similar to Seq2Seq).
 Having understood the general structure of Transformer and how to use it to complete translation tasks, let’s take a look at the detailed structure of Transformer:
Having understood the general structure of Transformer and how to use it to complete translation tasks, let’s take a look at the detailed structure of Transformer:
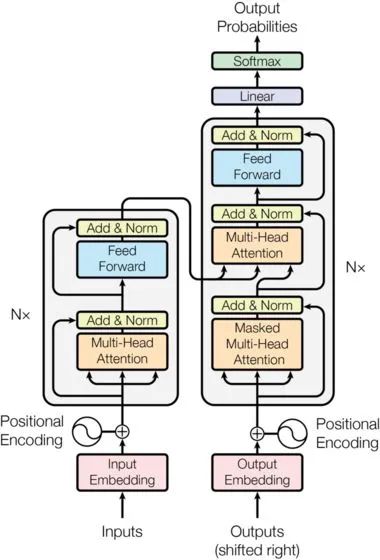
The core components are the Self-Attention and Feed Forward Networks mentioned above, but there are many other details. Next, we will start to interpret the Transformer structure one by one.
Self Attention
Self Attention is the attention of a certain word in the sentence to all its own words. It calculates the weight of each word for this word and represents this word as the weighted sum of all words. Each Self Attention operation is like performing a Convolution or Aggregation operation for each word. The specific operation is as follows:
First, each word goes through three matrices Wq, Wk, and Wv for a linear transformation, dividing into three to generate its own query, key, and vector vectors. When performing Self Attention centered on a word, the key vector of this word is used to perform a dot product with the query vector of each word, and then the weights are normalized through Softmax. Then, using these weights, the weighted sum of all word vectors is calculated as the output of this word. The specific process is shown in the figure below:
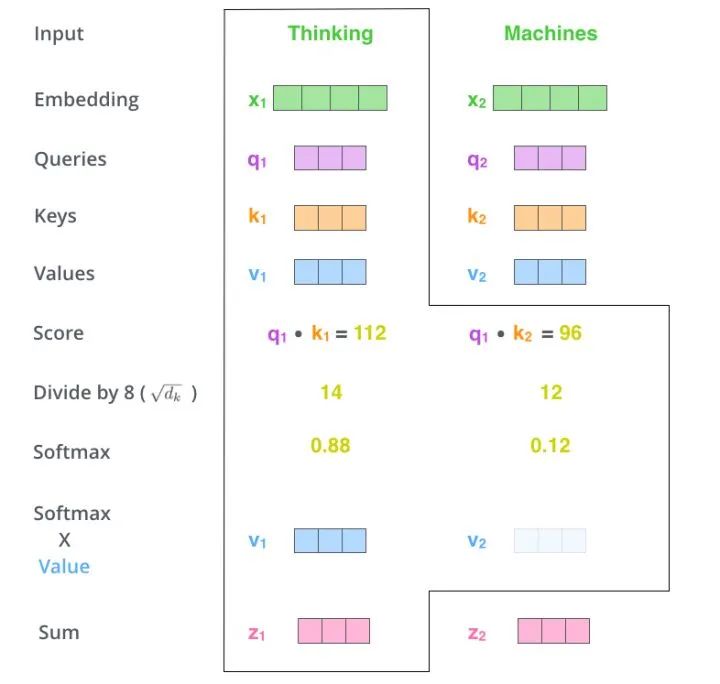
Before normalization, it is necessary to standardize by dividing by the dimension of the vector dk, so the final Self Attention can be represented in matrix transformation form as:
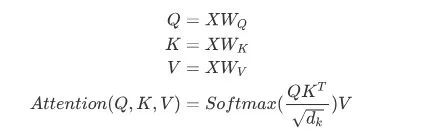
Ultimately, each Self Attention receives n word vectors as input and outputs n aggregated vectors.
As mentioned earlier, the Self Attention in the Encoder is different from that in the Decoder; in the Encoder, Q, K, and V all come from the output of the previous layer unit, while in the Decoder, only Q comes from the output of the previous Decoder unit, and K and V come from the output of the last layer of the Encoder. This means that the Decoder calculates weights based on the current state and the output of the Encoder, and then weights the Encoder’s encoding to obtain the next layer’s state.
Masked Attention
By observing the structure diagram above, we can also find another difference between the Decoder and Encoder: the input layer of each Decoder unit must first go through a Masked Attention layer. So what is the difference between Masked Attention and the ordinary version of Attention?
The Encoder needs to encode the entire sentence, so each word must consider the contextual relationship. Therefore, during the calculation process, each word can see all words in the sentence. However, the Decoder, similar to the Seq2Seq decoder, can only see the states of the preceding words, so it is a unidirectional Self-Attention structure.
The implementation of Masked Attention is also very simple; just perform a bitwise AND operation with a lower triangular matrix M before the Softmax step of ordinary Self Attention.
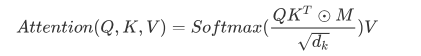
Multi-Head Attention
Multi-Head Attention is to perform the above Attention operation h times and then concatenate the h outputs to obtain the final output. This greatly improves the stability of the algorithm and is used in many Attention-related works. In the implementation of Transformer, to improve the efficiency of Multi-Head, W is expanded by h times, and then the same words of different heads’ K, Q, and V are arranged together for simultaneous calculation through view (reshape) and transpose operations. After completing the calculations, they are concatenated again through reshape and transpose, which is equivalent to parallel processing of all heads.
Position-wise Feed Forward Networks
In both the Encoder and Decoder, the n vectors output after Attention are fed into a fully connected layer, completing a position-wise feedforward network.
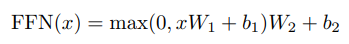
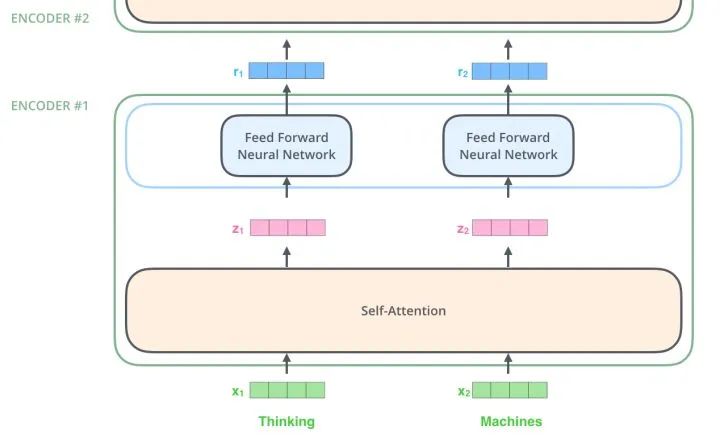
Add & Norm
This is a residual network that simply adds the input of one layer to its normalized output. In the Transformer, every Self Attention layer and FFN layer is followed by an Add & Norm layer.
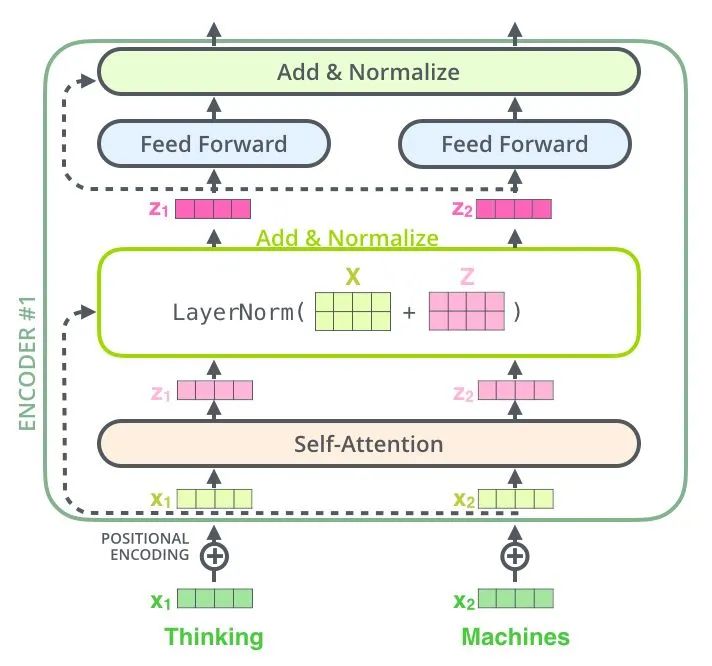
Positional Encoding
Since there is neither RNN nor CNN in the Transformer, all words in the sentence are treated equally, meaning there is no chronological relationship between the words. In other words, it may carry the same shortcomings as the bag-of-words model. To solve this problem, the Transformer proposes the Positional Encoding scheme, which adds a fixed vector to each input word vector to represent its position. The Positional Encoding used in this article is as follows:
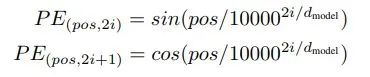
Where pos is the position of the word in the sentence, and i is the i-th position in the word vector, which means adding a wave with a different phase or gradually increasing wavelength to each column of the word vector to uniquely distinguish the position.
Transformer Workflow
The workflow of the Transformer is the concatenation of each sub-process introduced above:
-
The input word vectors are first added to Positional Encoding and then input into the Transformer.
-
Each Encoder Transformer performs a Multi-head self attention -> Add & Normalize -> FFN -> Add & Normalize process, then outputs to the next Encoder.
-
The output of the last Encoder will be retained as memory.
-
Each Decoder Transformer performs a Masked Multi-head self attention -> Multi-head self attention -> Add & Normalize -> FFN -> Add & Normalize process, where the
KandVduring Multi-head self attention come from the memory of the Encoder. The output needs to obtain the last layer embedding according to the task requirements. -
The output vector of the Transformer can be used for various downstream tasks.
GitHub Link: github.com/harvardnlp/a
Post Scriptum
Although the Transformer paper proposed a model for natural language translation, many articles refer to this model as Transformer. However, we prefer to call the substructures using Self-Attention in the paper as Transformer. The paper and source code also include many other optimizations such as dynamic learning rate, Residual Dropout, and Label Smoothing, which will not be elaborated here. Interested friends can read the relevant references for more information.
2. Unidirectional Two-Stage Training Model – OpenAI GPT
GPT (Generative Pre-Training) is a model proposed by OpenAI in 2018, which uses the Transformer model to solve various natural language problems, such as classification, reasoning, question answering, similarity, and other applications. GPT adopts a Pre-training + Fine-tuning training mode, allowing a large amount of unlabeled data to be utilized, greatly improving the effectiveness of these problems.
GPT is one of the attempts to use the Transformer for various natural language tasks, with the following three key points:
-
Pre-Training method
-
Unidirectional Transformer model
-
Fine-Tuning with variations in input data structure
If you have already understood the principles of Transformer, then understanding the above three points will give you a deeper insight into GPT.
Pre-Training Training Method
Many machine learning tasks require labeled datasets as input to complete. However, there is a large amount of unlabeled data around us, such as text, images, code, etc. Labeling this data requires a lot of manpower and time, and the speed of labeling is far less than the speed of data generation, so labeled data often only occupies a small part of the total dataset. With the continuous improvement of computing power, the amount of data that computers can handle is gradually increasing. If we cannot utilize this unlabeled data well, it would be a waste.
Therefore, semi-supervised learning and the pre-training + fine-tuning two-stage mode have become increasingly popular. The most common two-stage method is Word2Vec, which uses a large amount of unlabeled text to train word vectors with certain semantic information, and then uses these word vectors as input for downstream machine learning tasks, which can greatly improve the generalization ability of downstream models.
However, Word2Vec has a problem, where a single word can only have one embedding. This means that polysemy cannot be well represented.
ELMo was the first to think about collecting contextual information for each word during the pre-training phase, using a bi-LSTM-based language model to add contextual semantic information to word vectors:
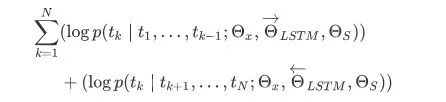
The above formula represents the left and right LSTM-RNNs, which share the input word vector X and the RNN layer weights S, meaning that the output of the bidirectional RNN is used to predict the next word (the next word to the right, and the previous word to the left). The specific structure is shown in the figure below:
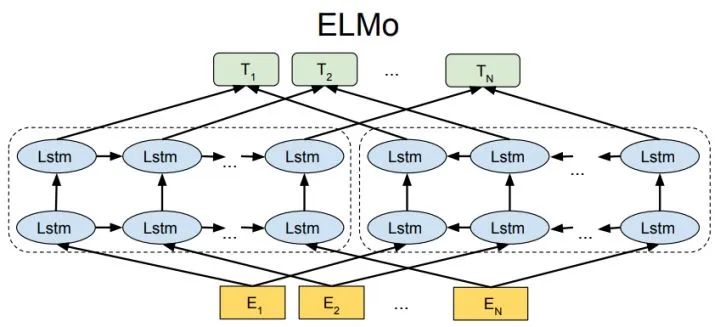
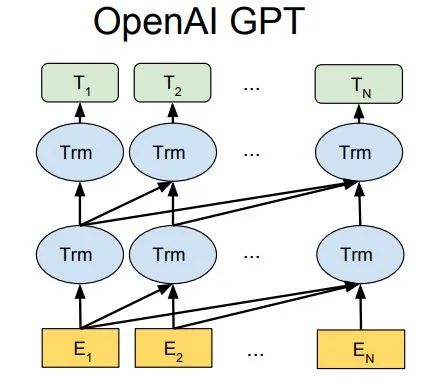
But ELMo uses RNN to complete the language model pre-training. So how can we use Transformer to accomplish pre-training?
Unidirectional Transformer Structure
OpenAI GPT uses a unidirectional Transformer to complete this pre-training task.
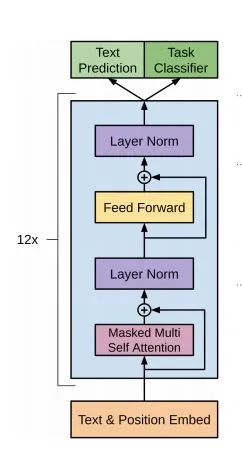
What is a unidirectional Transformer? In the Transformer paper, it is mentioned that the Transformer Blocks used in the Encoder and Decoder are different. In the Decoder Block, Masked Self-Attention is used, meaning that each word in the sentence can only pay attention to all preceding words, including itself; this is the unidirectional Transformer. The Transformer structure used by GPT replaces the Self-Attention in the Encoder with Masked Self-Attention, as shown in the figure below:
Since a unidirectional Transformer can only see the preceding words, the language model is:
The training process is actually very simple: the word vectors of the n words in the sentence (the first being <SOS>) are added to Positional Encoding and input into the aforementioned Transformer. The n outputs predict the next word at that position (<SOS> predicts the first word in the sentence; the prediction result of the last word is not used for language model training).
Since Masked Self-Attention is used, the words at each position cannot “see” the subsequent words, meaning that during prediction, it cannot see the “answers”, ensuring the model’s rationality; this is why OpenAI adopted a unidirectional Transformer.
Fine-Tuning and Variations in Input Data Structure
Next, we enter the second step of model training, fine-tuning the model parameters with a small amount of labeled data.
The output of the last word from the previous step was not utilized; in this step, we need to use this output as input for downstream supervised learning.
To avoid overfitting during Fine-Tuning, the paper also mentions auxiliary training objectives, similar to a multi-task model or semi-supervised learning. The specific method is to supervise the learning using the prediction result of the last word while continuing the unsupervised training of the previous words, making the final loss function:
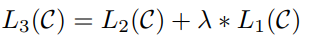
For different tasks, the input data format needs to be modified:
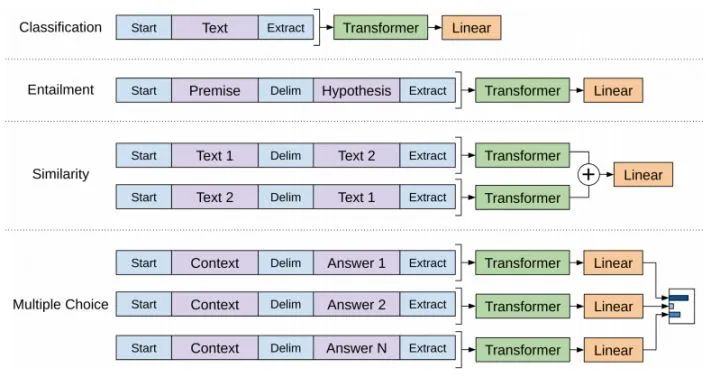
-
Classification: For classification problems, no modifications are needed.
-
Entailment: For reasoning problems, the premise and hypothesis can be separated by a delimiter.
-
Similarity: For similarity problems, since the model is unidirectional, but similarity is independent of order, the results of the two sentences should be summed after reversing their order for final inference.
-
Multiple Choice: For question-answering problems, the context and question are placed together and separated from the answer for prediction.
GitHub Link: github.com/openai/finet
Post Scriptum
OpenAI GPT has made great explorations in the application of Transformer and the two-stage training method, achieving very good results and paving the way for the subsequent BERT.
3. Bidirectional Two-Stage Training Model – BERT
BERT (Bidirectional Encoder Representation from Transformer) is a natural language representation framework based on Transformer proposed by Google Brain in 2018. It is a star model that became popular upon its release. Like GPT, BERT adopts a Pre-training + Fine-tuning training method and has achieved better results in tasks such as classification and tagging.
BERT and GPT are very similar; both are two-stage training models based on Transformer, divided into Pre-Training and Fine-Tuning stages, and both train a general Transformer model unsupervised in the Pre-Training stage, then fine-tune the parameters of this model in the Fine-Tuning stage to adapt it to different downstream tasks.
Although BERT and GPT seem very similar, their training objectives, model structures, and usage still have some differences:
-
GPT uses a unidirectional Transformer, while BERT uses a bidirectional Transformer, which means there is no need for the Mask operation;
-
The difference in the structures used directly leads to different training objectives in the Pre-Training stage;
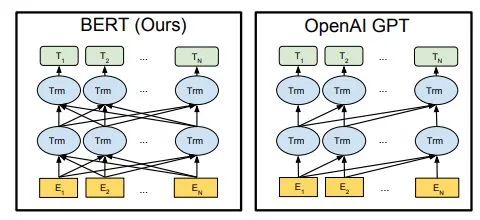
Bidirectional Transformer
BERT uses a Transformer structure without Masking, which is exactly the same as the Encoder Transformer structure in the Transformer paper:
GPT had to use a unidirectional structure to complete the language model training, which requires that when predicting the next word in Pre-Training, it can only see the current and previous words; this is the reason why GPT abandoned the original bidirectional structure of Transformer in favor of a unidirectional structure.
BERT aims to obtain information from both contexts simultaneously, rather than completely abandoning the information from the next context like GPT, so it uses a bidirectional Transformer. However, this means that it cannot use the normal language model as the pre-training objective because the structure of BERT allows each output of the Transformer to see the entire sentence, which means that whatever output you use for prediction will “see itself,” leading to the “see itself” problem. Although ELMo uses a bidirectional RNN, the two RNNs are independent, so it can avoid the “see itself” problem.
Pre-Training Stage
In order to use the bidirectional Transformer model, BERT had to abandon the language model used in GPT as the pre-training objective function. Instead, BERT proposed a completely different pre-training method.
-
Masked Language Model (MLM)
In Transformer, we want to know information from both the preceding and following contexts, but at the same time, we need to ensure that the entire model does not know the information of the word to be predicted. Therefore, we simply do not tell the model the information of this word. In other words, BERT removes some words that need to be predicted from the input sentence, then analyzes the sentence through the context and finally uses the output corresponding to the position to predict the removed words. This is similar to doing a cloze test.
However, directly replacing a large number of words with <MASK> tags may cause some issues; the model might think that it only needs to predict the output corresponding to <MASK> while ignoring outputs in other positions. Additionally, the input data in the Fine-Tuning stage does not contain <MASK> tags, which can also lead to different data distribution issues. To alleviate the impact of training brought by this, BERT adopts the following approach:
1. Randomly select 15% of the words in the input data for prediction; among these 15% of words:
2. 80% of the word vectors are replaced with <MASK> during input;
3. 10% of the word vectors are replaced with the word vectors of other words during input;
4. The remaining 10% remain unchanged.
This way, it tells the model that it might give you the answer, it might not give you the answer, or it might give you the wrong answer. In places where there are <MASK> tags, it will check your answers, and in places without <MASK> tags, it may also check your answers. Therefore, the <MASK> tag does not have any special significance for you, so you must predict the output for all positions well.
-
Next Sentence Prediction (NSP)
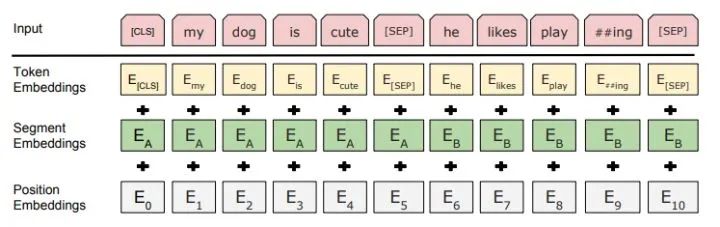
BERT also proposed another pre-training method called NSP, which is conducted simultaneously with MLM, forming a multi-task pre-training. This pre-training method involves inputting two consecutive sentences into the Transformer, with the left sentence preceded by a <CLS> tag, and its output is used to determine whether the two sentences have a continuous contextual relationship. Using negative sampling, positive and negative samples each account for 50%.
To distinguish the order of the two sentences, BERT adds a Segment Embedding that needs to be learned during pre-training along with Positional Encoding. This way, the input to BERT consists of the sum of word vectors, position vectors, and segment vectors. Additionally, a <SEP> tag is used to separate the two sentences.
The overall Pre-Training schematic is as follows:
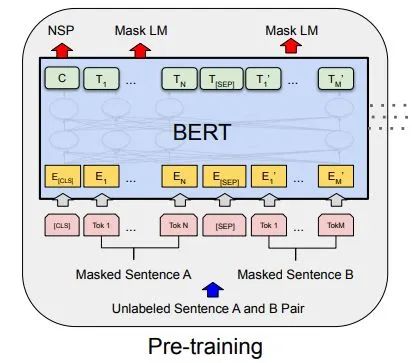
Fine-Tuning Stage
The Fine-Tuning stage of BERT is not much different from that of GPT. Because it uses a bidirectional Transformer, it abandons the auxiliary training objectives used in the Fine-Tuning stage of GPT, which is the language model. Additionally, the output vector used for classification prediction is changed from the last word output position of GPT to the <CLS> position at the beginning of the sentence. The Fine-Tuning schematic for different tasks is as follows:
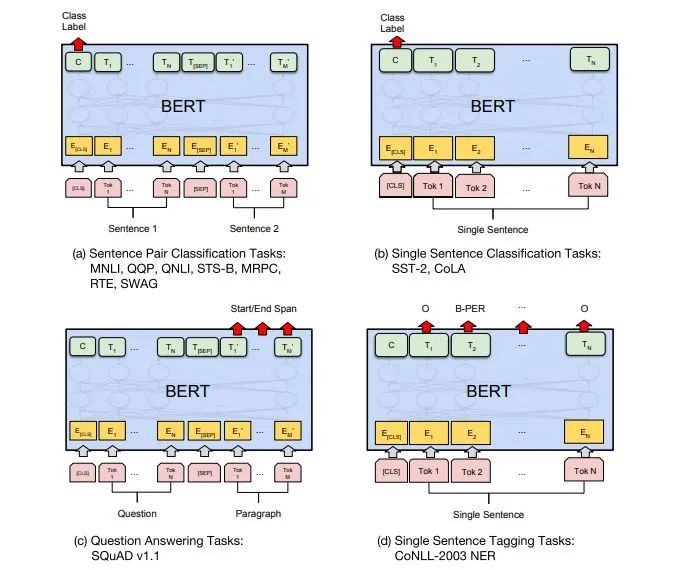
GitHub Link: github.com/google-resea
Post Scriptum
In my opinion, BERT is merely a trade-off of the GPT model. In order to simultaneously obtain contextual information of sentences in both stages, it uses a bidirectional Transformer model. However, this comes at the cost of losing the traditional language model, opting instead for a more complex pre-training method with MLM + NSP.
4. Multi-Task Model – MT-DNN
MT-DNN (Multi-Task Deep Neural Networks) still adopts the two-stage training method of BERT and the bidirectional Transformer. In the Pre-Training stage, MT-DNN is almost identical to BERT, but in the Fine-Tuning stage, MT-DNN adopts a multi-task fine-tuning approach. It simultaneously uses the context embeddings output by Transformer for training tasks such as single-sentence classification, text pair similarity, text pair classification, and question answering. The overall structure is shown in the figure below:
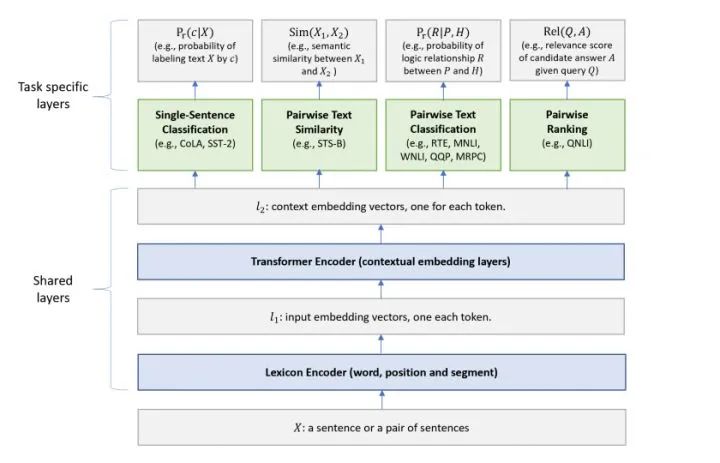
GitHub Link: github.com/namisan/mt-d
5. Unidirectional General Model – GPT-2
GPT-2 continues to use the unidirectional Transformer model originally used in GPT, and the purpose of this article is to leverage the advantages of unidirectional Transformer as much as possible to do things that the bidirectional Transformer used by BERT cannot achieve. That is, to generate subsequent text based on preceding text.
The idea of GPT-2 is to completely abandon the Fine-Tuning process and instead use a larger, unsupervised training, and more general language model to accomplish various tasks. We do not need to define what tasks this model should perform because much of the information contained in the labels already exists in the corpus. Just like a person who has read extensively can easily perform tasks such as automatic summarization, question answering, and article continuation based on the content they have read.
Strictly speaking, GPT-2 may not be considered a multi-task model, but it indeed uses the same model and parameters to complete different tasks. So how does GPT-2 use the language model to accomplish multiple tasks?
Usually, for specific tasks, we train dedicated models that can return the corresponding output for a given input, that is:
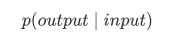
So if we want to design a general model, this model needs to provide a task type along with the input, and then produce the corresponding output based on the given input and task. The model can then be represented as follows:
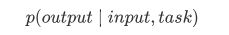
It used to be that if I wanted to translate a sentence, I needed to design a specific translation model, and if I wanted a question-answering system, I needed to design a dedicated question-answering model. But if a model is smart enough and can generate subsequent text based on your preceding text, we can distinguish various problems by adding some identifiers in the input. For example, we can directly ask: (“Natural Language Processing”, Chinese translation) to get the result we need: Nature Language Processing. In my understanding, GPT-2 is more like an omniscient question-answering system; by providing an identifier for a given task, it can give appropriate answers for various fields and tasks. GPT-2 meets the zero-shot setting, meaning that during the training process, it does not need to be told what tasks it should complete, and it can still provide reasonable answers for predictions.
So what has GPT-2 done to meet these requirements?
1. **Broaden and enlarge the dataset**
The first thing is to allow the model to read extensively; if the training samples are not enough, how can it perform reasoning? The previous work was targeted at specific problems, so the datasets were relatively narrow. GPT-2 collected a larger and more extensive dataset while ensuring the quality of this dataset by retaining high-quality content from web pages. It ultimately formed a dataset called WebText, consisting of 8 million texts and 40GB of data.
2. **Increase network capacity**
With more books, the brain’s capacity must also increase; otherwise, it will not remember the content in the books. To improve network capacity and enhance learning potential, GPT-2 increased the number of stacked layers in the Transformer to 48 layers, with a hidden layer dimension of 1600, and the parameter count reached 1.5 billion.
3. **Adjust network structure**
GPT-2 increased the vocabulary size to 50257, the maximum context size from 512 in GPT to 1024, and the batch size from 512 to 1024. Additionally, some minor adjustments were made to the Transformer, such as placing the normalization layer before each sub-block, adding another normalization layer after the last Self-attention, and changing the initialization method of the residual layer, etc.
GitHub Link: github.com/openai/gpt-2
Post Scriptum
The most astonishing aspect of GPT-2 is its remarkable generation capability, which is primarily attributed to its data quality and astonishing parameter count and dataset scale. The parameter count of GPT-2 is so large that the models used for experiments are still in an underfitting state; if training continues, the performance can further improve.
6. Conclusion
Summarizing all the developments regarding the work of Transformer, I have also organized some personal insights about the trends in deep learning development:
-
1. Supervised models are evolving toward semi-supervised and even unsupervised directions.
The growth rate of the amount of data far exceeds the speed of data labeling, leading to a large amount of unlabeled data. This unlabeled data is not without value; on the contrary, if we find the right “alchemy,” we can obtain unexpected value from these massive amounts of data. How to utilize this unlabeled data to improve task performance has become an increasingly significant issue.
-
2. From complex models with a small amount of data to simple models with a large amount of data.
The fitting ability of deep neural networks is very powerful; a simple neural network model is sufficient to fit any function. However, using simpler network structures for the same task requires higher data volume. As the data volume increases and the data quality improves, the requirements for the model will decrease. The larger the data volume, the easier it is for the model to capture features that conform to the true distribution of the real world. Word2Vec is an example; it uses a very simple objective function, but due to the use of a large amount of text, the trained word vectors contain many interesting characteristics.
-
3. Development from dedicated models to general models.
GPT, BERT, MT-DNN, and GPT-2 all use pre-trained general models to continue with downstream machine learning tasks without needing to modify the model itself too much. If a model has sufficient expressive power and the amount of data used during training is large enough, its generalizability will be stronger, and it will not need too many modifications for specific tasks. The most extreme case is like GPT-2, which can train a general multi-task model without even knowing what downstream tasks will be required during training.
-
4. Improving the scale and quality of data.
GPT, BERT, MT-DNN, and GPT-2 have all achieved remarkable results in succession, but I believe that the improvement in performance is more due to the increase in data scale than structural adjustments. As models become more generalized and simplified, more attention will be paid to how to obtain, clean, and refine higher quality and larger amounts of data to improve model performance. The impact of data processing adjustments will surpass that of model structure adjustments.
In summary, DL competitions will eventually become a contest of resources and computing power among major companies. A new topic may emerge in a few years: green AI, low-carbon AI, and sustainable AI…
The above ↑↑↑↑
References
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is All you Need[J]. neural information processing systems, 2017: 5998-6008.
[2] nlp.seas.harvard.edu/20
[3] jalammar.github.io/illu
[4] Radford, Alec, et al. “Improving language understanding by generative pre-training.” URL s3-us-west-2. amazonaws. com/openai-assets/research-covers/languageunsupervised/language understanding paper. pdf (2018).
[5] Peters M E, Neumann M, Iyyer M, et al. DEEP CONTEXTUALIZED WORD REPRESENTATIONS[J]. north american chapter of the association for computational linguistics, 2018: 2227-2237.
[6] Devlin J, Chang M, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. arXiv: Computation and Language, 2018.
[7] Liu X, He P, Chen W, et al. Multi-Task Deep Neural Networks for Natural Language Understanding.[J]. arXiv: Computation and Language, 2019.
[8] Radford A, Wu J, Child R, et al. Language models are unsupervised multitask learners[J]. OpenAI Blog, 2019, 1(8).
Important! A WeChat group for academic exchange on Natural Language Processing has been established.
You can scan the QR code below to join the group for discussion.
Please modify the note to [School/Company + Name + Direction] when adding.
For example – Harbin Institute of Technology + Zhang San + Dialogue System.
Account owner, please avoid promoting products. Thank you!

Recommended Reading:
【Long Article Detailed Explanation】From Transformer to BERT Model
Sailor Translation | Understand Transformer from Scratch
A picture is worth a thousand words! A hands-on guide to building a Transformer with Python