1. Essence of Transformer
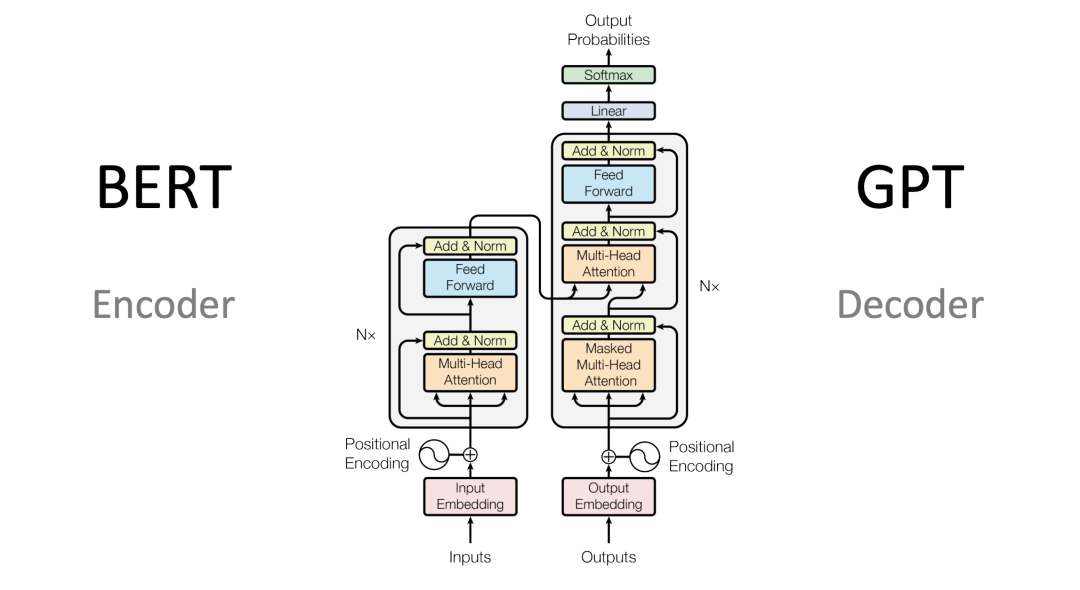
Transformer Architecture: It mainly consists of four parts: input section (input-output embeddings and position encoding), multi-layer encoder, multi-layer decoder, and output section (output linear layer and Softmax).
Transformer Architecture
-
Input Section:
-
Source Text Embedding Layer: Converts the numerical representation of words in the source text into vector representation, capturing the relationships between words.
-
Position Encoder: Generates position vectors for each position in the input sequence so that the model can understand the position information in the sequence.
-
Target Text Embedding Layer (used in decoder): Converts the numerical representation of words in the target text into vector representation.
-
Encoder Section:
-
Composed of N stacked encoder layers.
-
Each encoder layer consists of two sub-layer connections: The first sub-layer is a multi-head self-attention sub-layer, and the second sub-layer is a feed-forward fully connected sub-layer. Each sub-layer is followed by a normalization layer and a residual connection.
-
Decoder Section:
-
Composed of N stacked decoder layers.
-
Each decoder layer consists of three sub-layer connections: The first sub-layer is a masked multi-head self-attention sub-layer, the second sub-layer is a multi-head attention sub-layer (from encoder to decoder), and the third sub-layer is a feed-forward fully connected sub-layer. Each sub-layer is followed by a normalization layer and a residual connection.
-
Output Section:
-
Linear Layer: Converts the output vector from the decoder into the final output dimension.
-
Softmax Layer: Converts the output of the linear layer into a probability distribution for final prediction.
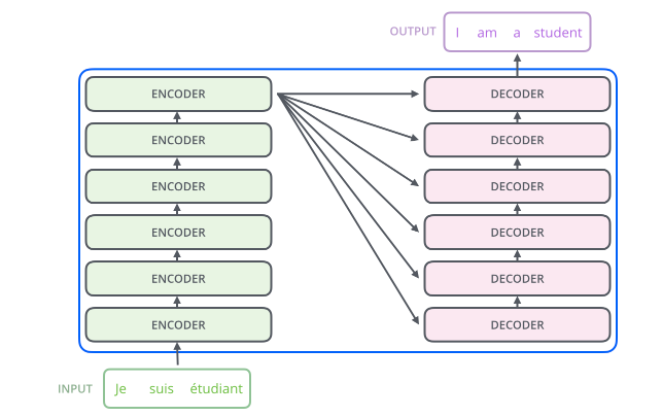
Encoder-Decoder: On the left are N encoders, and on the right are N decoders, where N is 6 in Transformer.
Encoder-Decoder
-
Encoder::
-
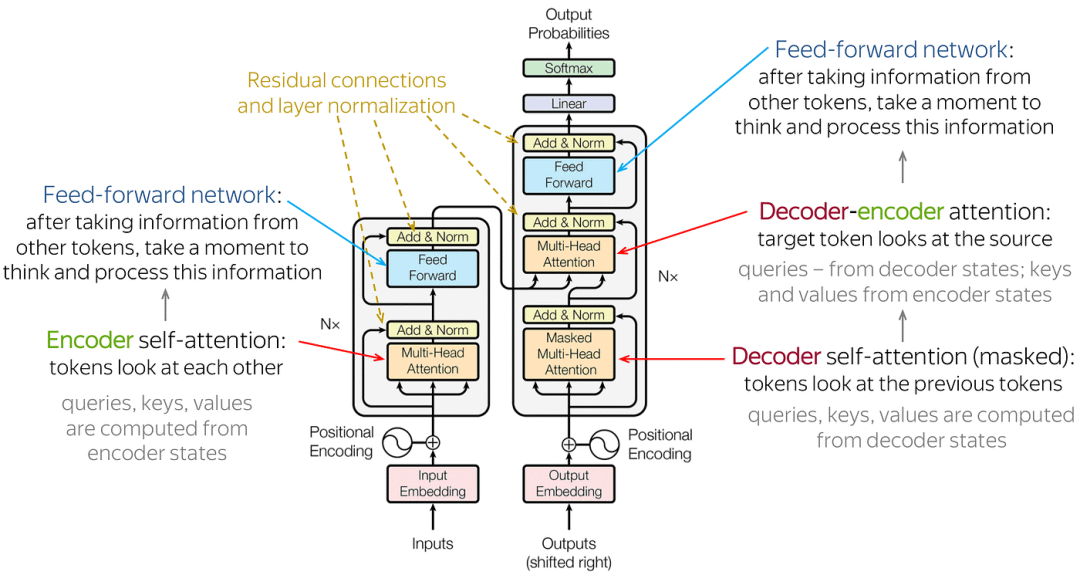
There are a total of 6 identical encoder layers in the encoder part of the Transformer.
Each encoder layer has two sub-layers, namely the Multi-Head Attention layer and the Position-wise Feed-Forward Network. Each sub-layer has a residual connection (dashed line in the figure) and layer normalization (LayerNorm), collectively referred to as Add&Norm operation.
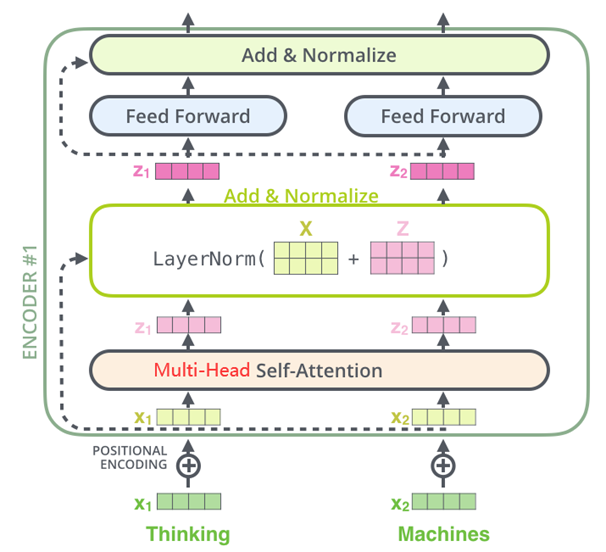
Encoder Architecture
-
Decoder::
-
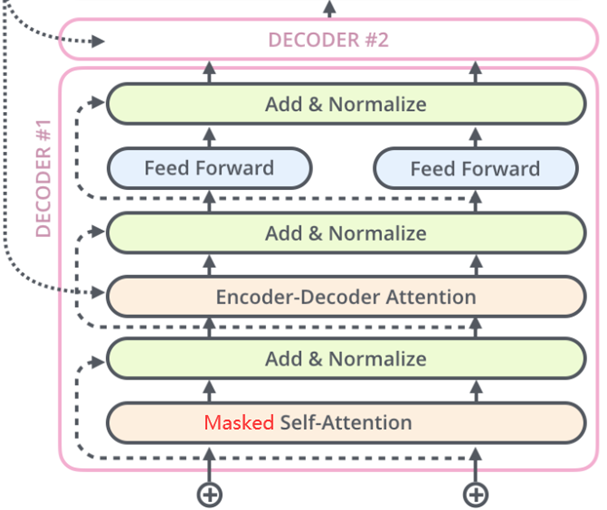
The decoder part of the Transformer also consists of 6 identical decoder layers.
Each decoder layer has three sub-layers, masked self-attention layer, Encoder-Decoder attention layer, and position-wise feed-forward network. Similarly, each sub-layer has a residual connection (dashed line in the figure) and layer normalization (LayerNorm), and the two together are called Add&Norm operation.
2. Principles of Transformer
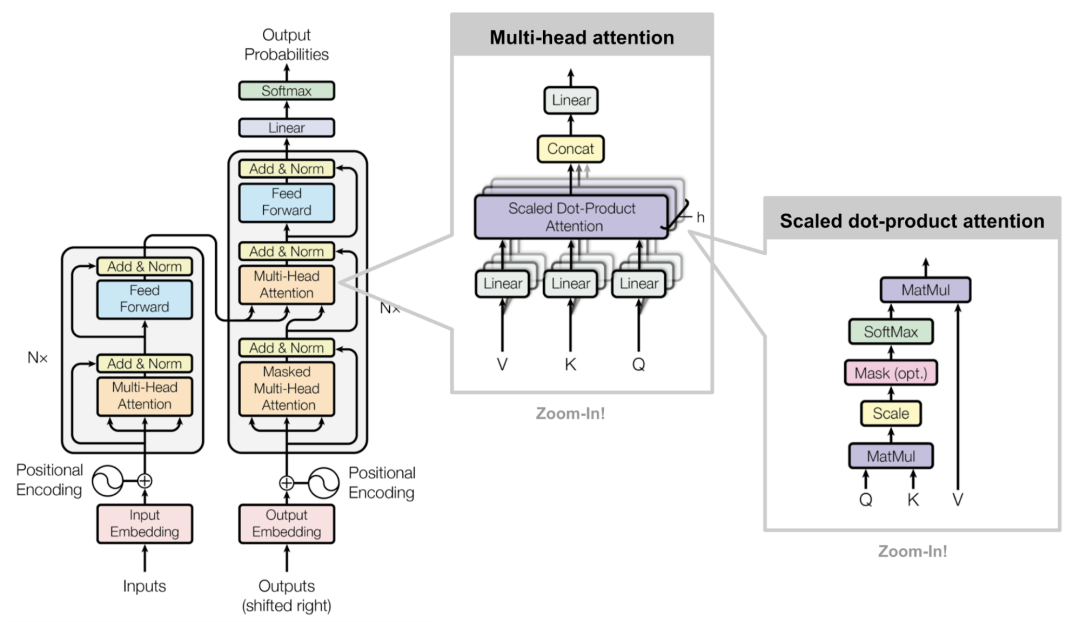
Working Principle of Transformer
Multi-Head Attention: allows the model to focus on information from different positions simultaneously. By splitting the original input vector into multiple heads (head), each head can independently learn different attention weights, enhancing the model’s ability to focus on different parts of the input sequence.
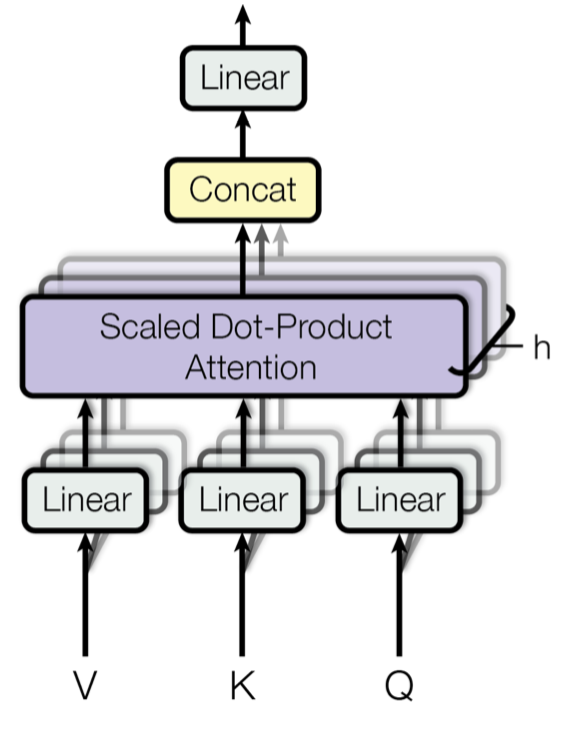
Multi-Head Attention (Multi-Head Attention)
-
Input Linear Transformation: For the input Query, Key, and Value vectors, they are first mapped to different subspaces through linear transformations. The parameters of these linear transformations are what the model needs to learn.
-
Split Multi-Head: After linear transformation, the Query, Key, and Value vectors are split into multiple heads. Each head performs attention calculations independently.
-
Scaled Dot-Product Attention: Within each head, scaled dot-product attention is used to calculate the attention scores between Query and Key. This score determines which parts of the Value vector the model should focus on when generating output.
-
Apply Attention Weights: The computed attention weights are applied to the Value vector to obtain a weighted intermediate output. This process can be understood as filtering and focusing on input information based on attention weights.
-
Concatenate and Linear Transformation: The weighted outputs of all heads are concatenated, and then a linear transformation is applied to obtain the final Multi-Head Attention output.
Scaled Dot-Product Attention: (scaled dot-product attention) is a key component of the multi-head attention mechanism in the Transformer model.
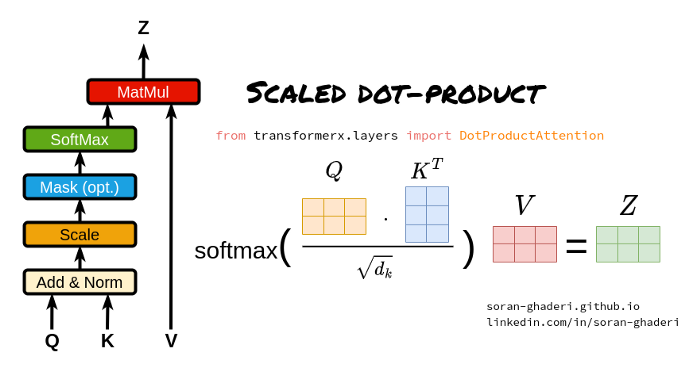
Scaled Dot-Product Attention (scaled dot-product attention)
-
Query, Key, and Value Matrices:
-
Query Matrix (Q): Represents the current focus or information requirement, used to match with the Key matrix.
-
Key Matrix (K): Contains identification information for each position in the input sequence, used for matching with the Query matrix.
-
Value Matrix (V): Stores the actual values or information corresponding to the Key matrix; when a Query matches a Key, the corresponding Value will be used to compute the output.
-
Dot Product Calculation:
-
By calculating the dot product between the Query matrix and the Key matrix (i.e., multiplying corresponding elements and summing), the similarity or matching degree between the Query and each Key is measured.
-
Scaling Factor:
-
Since the results of the dot product operation can be very large, especially when the input dimension is high, this may cause the softmax function to saturate when calculating attention weights. To avoid this problem, scaled dot-product attention introduces a scaling factor, usually the square root of the input dimension. Dividing the dot product result by this scaling factor keeps the input to the softmax function within a reasonable range.
-
Softmax Function:
-
The scaled dot product result is input into the softmax function to compute the attention weights of each Key relative to the Query. The softmax function converts the raw scores into a probability distribution, ensuring that the sum of the attention weights for all Keys equals 1.
-
Weighted Sum:
-
The computed attention weights are used to perform a weighted sum on the Value matrix to obtain the final output. This process allocates more focus to Values that match the Query more closely based on the magnitude of the attention weights.
3. Improvements in Transformer Architecture
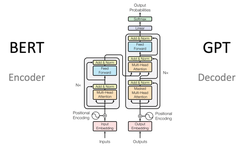
BERT:BERT is a pre-trained language model based on Transformer, whose greatest innovation lies in the introduction ofbidirectional Transformer encoder, which allows the model to consider the contextual information both before and after the input sequence.
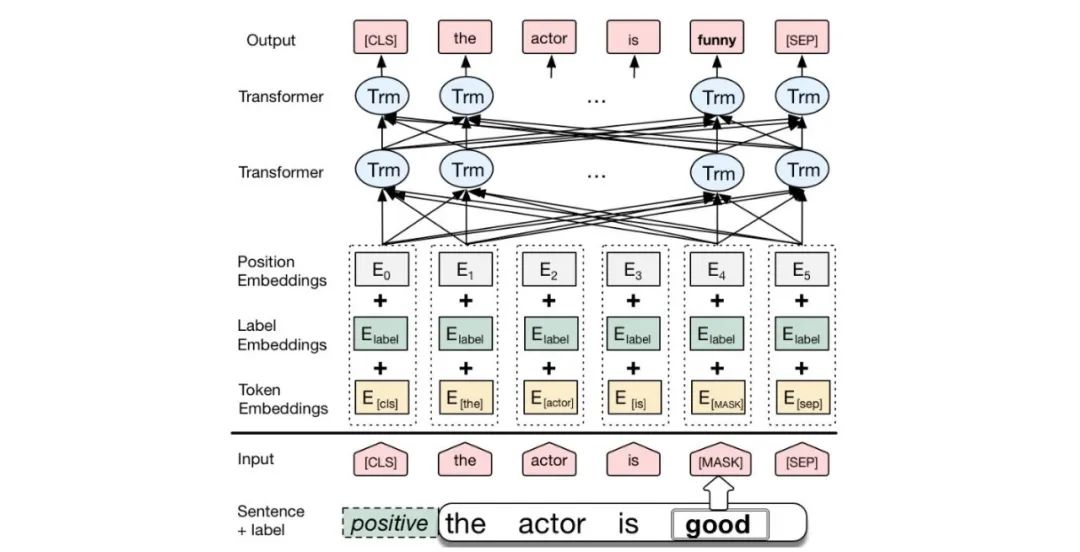
BERT Architecture
-
Input Layer (Embedding):
-
Token Embeddings: Converts words or sub-words into fixed-dimensional vectors.
-
Segment Embeddings: Used to differentiate between different sentences in a sentence pair.
-
Position Embeddings: Since the Transformer model itself does not have the capability to process sequence order, position embeddings are added to provide position information of words in the sequence.
Encoding Layer (Transformer Encoder): BERT model uses a bidirectional Transformer encoder for encoding.
Output Layer (Pre-trained Task-specific Layers):
-
MLM Output Layer: Used to predict masked words. During training, the model randomly masks some words in the input sequence and tries to predict these words based on context.
-
NSP Output Layer: Used to determine if two sentences are consecutive sentence pairs. During training, the model receives pairs of sentences as input and tries to predict whether the second sentence is the subsequent sentence of the first one.
GPT:GPT is also a pre-trained language model based on Transformer, whose greatest innovation lies in the use ofunidirectional Transformer encoder, which allows the model to better capture the contextual information of the input sequence.
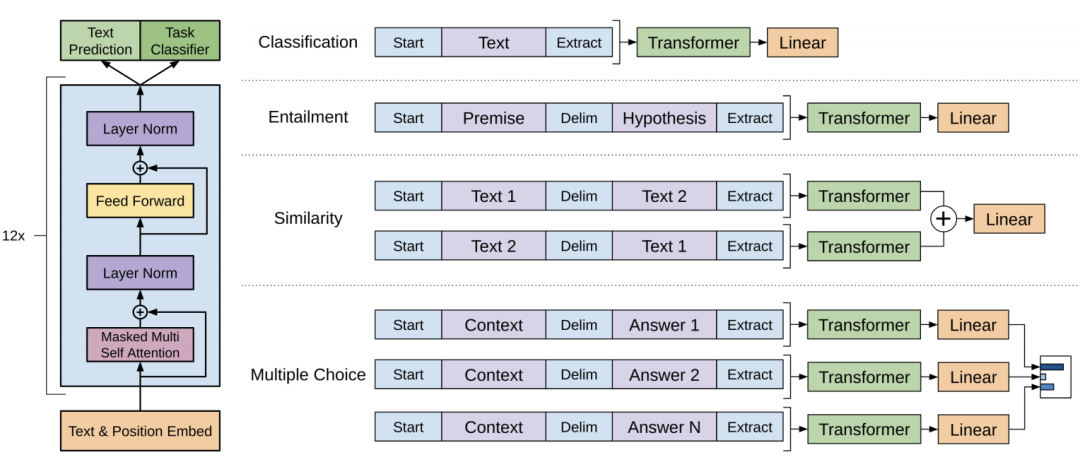
GPT Architecture
-
Input Layer (Input Embedding):
-
Converts the input words or symbols into fixed-dimensional vector representations.
-
May include word embeddings, position embeddings, etc., to provide semantic and positional information of the words.
Encoding Layer (Transformer Encoder): GPT model uses a unidirectional Transformer encoder for encoding and generation.
Output Layer (Output Linear and Softmax):
-
The linear output layer converts the output of the last Transformer Decoder Block into a vector of vocabulary size.
-
The Softmax function converts the output vector into a probability distribution for word selection or generating the next word.