
Edited by Machine Heart
Contributors: Siyuan, Wang Shuting
This month, Google’s BERT has received a lot of attention, as the research has refreshed the state-of-the-art performance records in 11 NLP tasks with its pre-trained model. The authors of the paper stated that they would release the code and pre-trained model by the end of this month, but it has not been released yet. Therefore, many researchers are trying to reduce computational power by using medium-sized datasets or using OpenAI’s Transformer pre-trained model as initialization.
The two BERT implementation projects introduced in this article are based on TensorFlow and Keras, respectively. The TensorFlow-based project will use a medium-sized dataset and other techniques to reduce computational power, and it has been found that using TextCNN instead of the Transformer backbone network while retaining the BERT pre-training task can still achieve very good results. The Keras-based project attempts to use the pre-trained OpenAI Transformer as initialization weights and retrain the BERT pre-trained model with relatively low computational power, then apply the pre-trained BERT to different tasks.
Both projects are trying to use the core ideas of BERT and apply them to other NLP tasks with lower computational costs. Of course, if readers wish to use the large BERT pre-trained model, they will need to wait for Google’s official release of the code and model.
Introduction to BERT
BERT stands for Bidirectional Encoder Representations from Transformers, where “bidirectional” means that the model can utilize information from both the preceding and following words when processing a particular word. This “bidirectionality” comes from the fact that BERT differs from traditional language models; it does not predict the most likely current word given all preceding words but randomly masks some words and uses all unmasked words for prediction. The image below shows three types of pre-trained models, where both BERT and ELMo use bidirectional information, while OpenAI GPT uses unidirectional information.
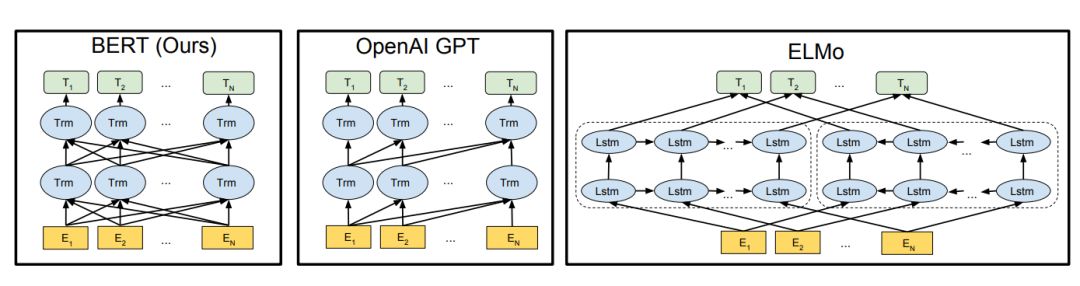
The above shows the architectures of different pre-trained models. BERT can be seen as a new model that combines the advantages of OpenAI GPT and ELMo. ELMo uses two independently trained LSTMs to obtain bidirectional information, while OpenAI GPT, using a new type of Transformer, can only obtain unidirectional information like traditional language models. The main goal of BERT is to improve the pre-training tasks based on OpenAI GPT to simultaneously leverage the advantages of deep Transformer models and bidirectional information.
The core process of BERT is very simple. It first extracts two sentences from the dataset, where the second sentence has a 50% probability of being the next sentence of the first one, thus learning the relationship between sentences. Then, it randomly removes some words from both sentences and asks the model to predict what these words are, which helps learn the relationships within sentences. Finally, the processed sentences are fed into a large Transformer model, and by using two loss functions, it can simultaneously learn the above two objectives to complete the training.
Introduction to TensorFlow Implementation Project
BERT has recently made new progress in over ten NLP tasks. This project is a TensorFlow implementation of the papers “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” and “Attention is All You Need”.
This project provides pre-training methods and code, along with some adjustments to accelerate convergence. This TensorFlow implementation does not require too much computational power when using medium-sized datasets, so interested readers can also try it. Of course, readers who wish to use the large pre-trained BERT model can wait for Google’s official model release.
Project address: https://github.com/brightmart/bert_language_understanding
Pre-training and Fine-tuning Experiments
The project authors replaced the Transformer with TextCNN, substituting BERT’s backbone network. They found that using a model pre-trained with a masked language model on a large amount of raw data significantly improves performance. Therefore, they believe that the pre-training and fine-tuning strategies are independent of the model and pre-training tasks. Thus, the backbone network can be modified to add more pre-training tasks or define new pre-training tasks, and pre-training is not limited to masked language models or next-sentence prediction tasks. Surprisingly, for medium-sized datasets (e.g., one million data points), even without using external data, as long as the pre-training tasks (such as masked language models) are utilized, performance can be greatly improved, and the model can converge faster. Sometimes, during the fine-tuning phase, training may only require a few epochs.
Purpose
Although open-source (tensor2tensor) and the official implementations of Transformer and BERT are about to arrive, they might be difficult to understand. The authors of this project do not intend to completely replicate the original files but rather apply the main ideas to solve NLP problems in a better way. Most of the work in this article was modified from another GitHub project last year: text classification (https://github.com/brightmart/text_classification).
Performance
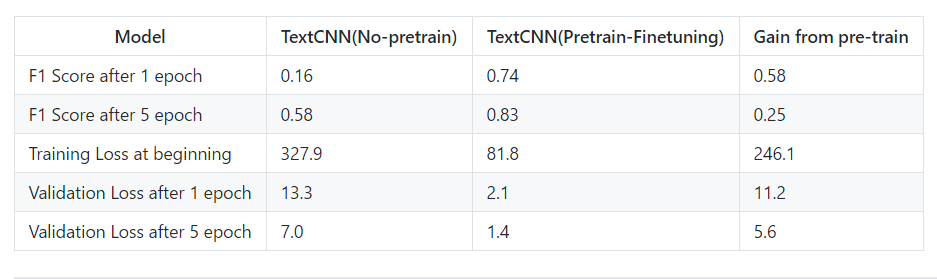
The image below shows the testing results of the text classification task on a medium-sized dataset (cail2018, 450,000) where the TextCNN using BERT pre-training ideas significantly outperforms other models:
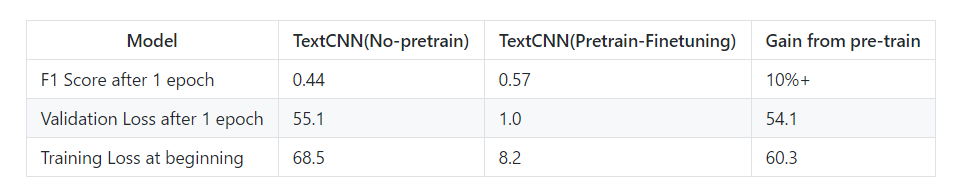
The image below shows the testing results on a small dataset (private, 100,000):
Details of TensorFlow Implementation Project
Usage
If you want to pre-train the BERT model on a masked language model and use it on new NLP tasks, the usage can mainly be divided into two steps. It is worth noting that this project does not provide a pre-trained model, so the pre-training process requiring a lot of computational power still needs to be performed by yourself.
1. Pre-train the BERT language model
python train_bert_lm.py [DONE]2. Fine-tune the model on the new task
python train_bert_fine_tuning.py [Done]In the author’s experiments, even at the starting point of fine-tuning, just recovering parameters from the pre-trained model results in lower loss compared to training from scratch. The F1 score of the pre-trained model is also higher than that of training from scratch, and the F1 score from scratch needs to grow from zero.
Additionally, to quickly test new ideas and models, you can set the hyperparameter test_mode to True. In this mode, the model will only load a small amount of data for testing, making training very fast.
In the basic steps, you can also solve text classification problems through Transform:
python train_transform.py [DONE, but a bug exists preventing it from converging, welcome you to fix, email: [email protected]]The pre-training and fine-tuning processes also have other optional hyperparameters that control the size of the model and the training process:
-
d_model: Model dimension, default is [512].
-
num_layer: Number of layers, default is [6].
-
num_header: Number of heads in self-attention mechanism, default is [8].
-
d_k: Dimension of Key (K) and Query (Q), default is [64].
-
d_v: Dimension of Value (V), default is [64].
default hyperparameter is d_model=512,h=8,d_k=d_v=64(big). if you want to train the model fast, or have a small dataset or want to train a small model, use d_model=128,h=8,d_k=d_v=16(small), or d_model=64,h=8,d_k=d_v=8(tiny).Implementation Details
First, the implementation environment for TensorFlow is relatively simple: python 3+ tensorflow 1.10. Secondly, pay attention to the following issues during implementation:
1. What parameters can be shared and cannot be shared between the pre-training and fine-tuning phases?
Basically, all parameters used in the backbone network during the pre-training and fine-tuning phases can be shared.
Since many parameters can be shared, the fine-tuning phase only needs to learn a few parameters; additionally, the word embeddings in both phases can also be shared.
Therefore, by the initial stage of fine-tuning, most parameters have already been learned.
2. How to implement a masked language model?
To simplify things, you can generate many sentences based on the file. Each sentence is truncated and padded to the same length, and then a word is randomly selected to be replaced with [MASK], the word itself, or a random word.
3. How to make the fine-tuning phase more efficient without affecting the results and knowledge learned during the pre-training phase?
Use a smaller learning rate during the fine-tuning phase, allowing for adjustments only within a very small range.
Keras Implementation
The TensorFlow-based implementation also does not provide a pre-trained language model, which requires a lot of computational power during the pre-training phase. This computational power requirement is unacceptable for many researchers and developers. However, since the official implementation and pre-trained model have not yet been released, some developers have utilized the pre-trained OpenAI Transformer as initialization parameters and trained a new BERT pre-trained model, significantly reducing computational power requirements.
Project address: https://github.com/Separius/BERT-keras
In this Keras implementation project, the author uses the pre-trained OpenAI Transformer as the initialization condition and trains a new BERT. The project author states that this allows pre-training without using TPU. Below are the main statements of the Keras implementation, including loading the pre-trained OpenAI Transformer model, loading the BERT model, and saving the new pre-trained weights, etc.
# this is a pseudo code you can read an actual working example in tutorial.ipynb
text_encoder = MyTextEncoder(**my_text_encoder_params) # you create a text encoder (sentence piece and openai's bpe are included)
lm_generator = lm_generator(text_encoder, **lm_generator_params) # this is essentially your data reader (single sentence and double sentence reader with masking and is_next label are included)
task_meta_datas = [lm_task, classification_task, pos_task] # these are your tasks (the lm_generator must generate the labels for these tasks too)
encoder_model = create_transformer(**encoder_params) # or you could simply load_openai()
trained_model = train_model(encoder_model, task_meta_datas, lm_generator, **training_params) # it does both pretraining and finetuning
trained_model.save_weights('my_awesome_model') # save it
model = load_model('my_awesome_model', encoder_model) # load it later and use it!The author states that this project has some important notes. Depending on different tasks and requirements, the model structure and pre-training process can be modified according to these notes.
-
The core idea of this library is to use OpenAI’s pre-trained model as the initial state for training a new model, allowing BERT to be trained using GPU.
-
Loading the OpenAI model through Keras has been tested on both TensorFlow backend and Theano backend.
-
For most NLP models, this project can define data generators and task metadata that can be used even in other frameworks.
-
The dataset and Transformer will perform some unit tests. If you are not familiar with the code, you can read these tests.
-
Other encoders, such as LSTM or BiQRNN, can also be used for training.
-
What will happen when the official code is released? The data reader will remain stable, and it may even be possible to import the weights released by the official into this library (the author believes he will complete this process, as the actual Transformer is still relatively easy to implement).
-
The author strongly recommends reading the tutorial.ipynb file in the project, which demonstrates the entire usage process of the project.
Important Code Concepts
-
Task: There are two general tasks, sentence-level tasks (such as next sentence prediction and sentiment analysis) and token-level tasks (such as part-of-speech tagging and named entity recognition).
-
Sentence: A “sentence” represents an instance with labels and all content, providing a target for each task (a single label value for sentence-level tasks, and a label for each token for token-level tasks) and a mask; for token-level tasks, in addition to ignoring padding, the first symbol vector is also used to predict the category (the [CLS] symbol in BERT).
-
TaskWeightScheduler: The project authors hope to start training from the language model and then transition to classification tasks, which can be quickly implemented using this class.
-
special_tokens: pad, start, end, delimiter, mask


Click “Read Original” to sign up and participate.