

New Intelligence Report
New Intelligence Report
Source: Google AI
Editor: LRS
[New Intelligence Guide] Based on pre-training experience, more data leads to better performance! Google recently published a paper at NAACL 2021 that can automatically generate text data from knowledge graphs, so there’s no need to worry about insufficient corpora anymore!
Large pre-trained natural language processing (NLP) models, such as BERT, RoBERTa, GPT-3, T5, and REALM, fully utilize massive natural language corpora from the web and fine-tune labeled data for specific tasks to achieve excellent pre-training results, even surpassing human performance in some NLP tasks.
However, natural language text itself represents a limited range of knowledge, and facts may be contained in unstructured data like long sentences in various ways.
Moreover, the presence of non-factual information and harmful content in text may ultimately lead to model bias.
In addition to unstructured text, another source of information is the knowledge graph, which is a form of structured data.
Data contained in knowledge graphs is typically factual, and the information is usually extracted from reliable corpora, with post-processing filtering and manual editing ensuring that inappropriate and erroneous information is removed.
Therefore, if a model can combine both, it can improve accuracy and reduce harmful information. However, the reality is that there are different structural forms between knowledge graphs and text, making it difficult to integrate them into the existing corpora of language models.
Based on this idea, Google proposed a new model, the Knowledge Enhanced Language Model (KELM), which has been accepted at NAACL 2021.

This paper mainly explores how to convert knowledge graphs into natural language sentences to enhance existing pre-training corpora, allowing them to integrate into the pre-training of language models without changing their structure.
The dataset used in the study is primarily the publicly available English knowledge graph Wikidata KG, which the model can convert into natural language text to create a synthetic corpus.
Previous related work proposed a retrieval-based language model, REALM, and Google provided stronger capabilities for this language model, integrating the natural language corpus and knowledge graph into pre-training using the synthesized corpus.
The corpus is currently available on GitHub, with each line including a triple and a sentence. Below is an example from the test set:
Niklaus Troxler occupation Graphic designer, date of birth 01 May 1947 Niklaus Troxler (born May 1, 1947) is a Swiss graphic designer.
Converting Knowledge Graphs into Natural Language Text
Knowledge graphs include factual information explicitly represented in a structured format, typically in the form of triples [subject entity, relation, object entity], for example, [10×10 photobooks, inception, 2012].
A set of related triples is called an entity subgraph. An example of an entity subgraph based on the previous triple example is {[10×10 photobooks, instance of, non-profit organization], [10×10 photobooks, inception, 2012]}, as shown in the figure below, KG can be seen as interconnected entity subgraphs.
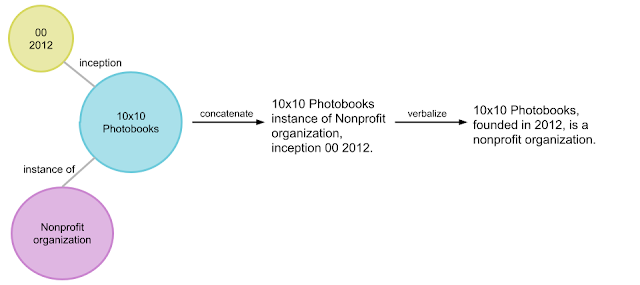
Transforming subgraphs into natural language text is a standard task in NLP known as data-to-text generation.
Although significant progress has been made in data-to-text generation on benchmark datasets like WebNLG, converting the entire KG into natural text presents additional challenges. Large entities and relationships are much larger and more diverse than small benchmark datasets.
Additionally, benchmark datasets consist of predefined subgraphs that can form fluent, meaningful sentences. For the entire KG, such segmented entity subgraphs also need to be created.
To convert Wikidata KG text into synthetic, natural, and fluent sentences, Google also developed a linguistic pipeline called Text from KG Generator (TEKGEN), which consists of several parts: a large heuristic-constructed training corpus capable of automatically aligning Wikipedia and Wikidata KG triples, a text-to-text generator (T5) that converts KG triples into text, an entity subgraph creator that generates combinations of triples into language, and a post-processing filter to eliminate low-quality outputs.
The output is a corpus containing the entire Wikidata KG as natural text, which we call the knowledge-enhanced language model corpus. It consists of approximately 18M sentences, containing about 45M triples and around 1500 relationships.

Combining knowledge graphs and natural language text in pre-training our evaluations indicate that knowledge graph linguification is an effective method to fuse knowledge graphs with natural language text. By enhancing REALM’s retrieval library, it can effectively generate text, which only includes text from Wikipedia.
To evaluate the effectiveness of this linguification, the paper used the KELM corpus (i.e., linguified triples) to enhance the REALM retrieval corpus and compared its retrieval performance with that of the concatenated triples enhanced corpus without linguification, measuring the accuracy on two popular open-domain question answering datasets (Natural Questions and Web Questions) for each data augmentation technique.
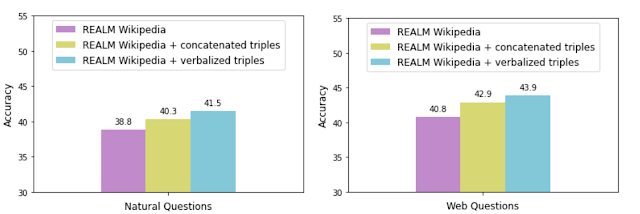
Using the concatenated triples enhanced REALM can improve accuracy and also add some latent knowledge information that is not represented in the text.
The enhanced linguified triples make the integration of knowledge graphs with natural language text corpora smoother, leading to higher accuracy.
Additionally, the research team observed a similar trend on a knowledge probe called LAMA, which uses fill-in-the-blank question query models.
This paper using the KELM model provides a publicly available knowledge graph corpus as natural text. The authors found that knowledge graph linguification can be used to integrate knowledge graphs and natural text corpora to overcome their structural differences.
This has practical applications for knowledge-intensive tasks (e.g., question answering), where providing factual knowledge is essential. Furthermore, this corpus can also be applied to the pre-training of large language models, reducing harmful information and enhancing authenticity.
This work encourages further progress in integrating structured knowledge sources into the pre-training of large language models.
References:
https://ai.googleblog.com/
https://arxiv.org/abs/2010.12688
Recommended Reading:
Why Do BERT and GPT-3 Always ‘Not Speak Human’? Because They Have Read Too Much Reddit
The ‘Grazing Goat’ Problem That Has Confounded Mathematicians for 200 Years, Elementary School Students Can Only Understand the First Step
Listen to Bengio Talk About Deep Learning! Turing Award Winner David Patterson and Over 200 AI Leaders Share! | The 2021 Intelligence Conference Is Coming
A Deaf Person Also Wants to Understand Every News | Sogou Releases the World’s First Sign Language AI Synthesizer with 5.1 Billion Views in Three Years! The 30-Year-Old ‘TA’ Connects ‘Three Rui’ to Scene-Level Intelligence, Entering Ultra-Intelligent Medical Care