

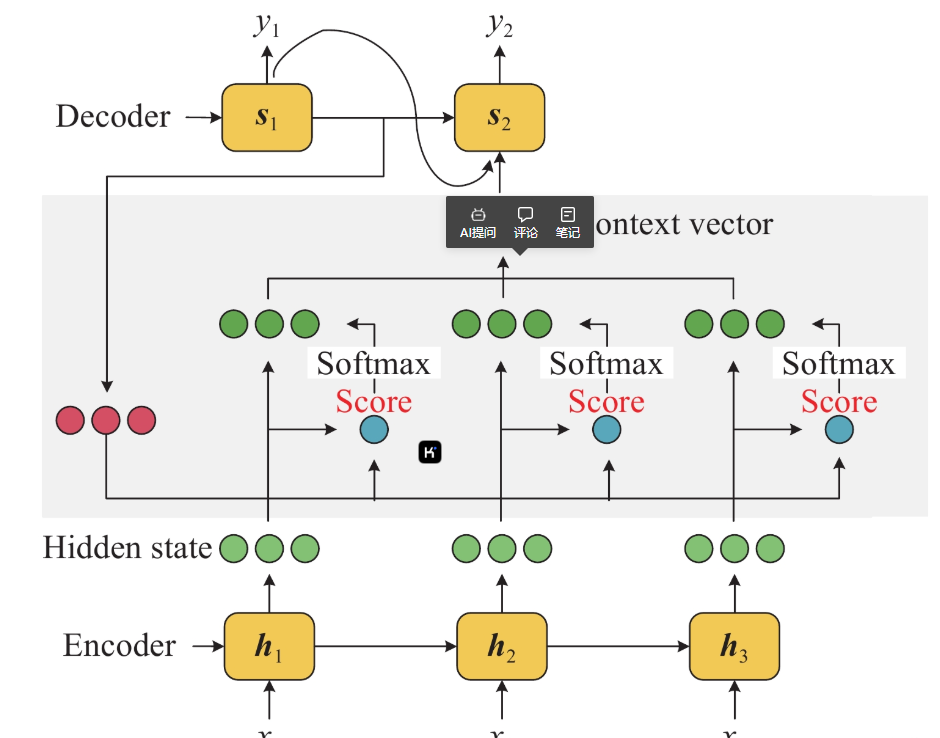
1. Basic Principles of Attention Mechanism
1. Input Representation
In Natural Language Processing (NLP) tasks, the input data is usually in text form, and we need to convert this text into a numerical form that the model can process. This process is called embedding. The embedding layer maps each word to a vector in a high-dimensional space, known as word vectors. Word vectors can capture the semantic information of words and can be processed by neural networks.

2. Calculating Attention Weights

3. Weighted Sum

4. Output

5. Example Code

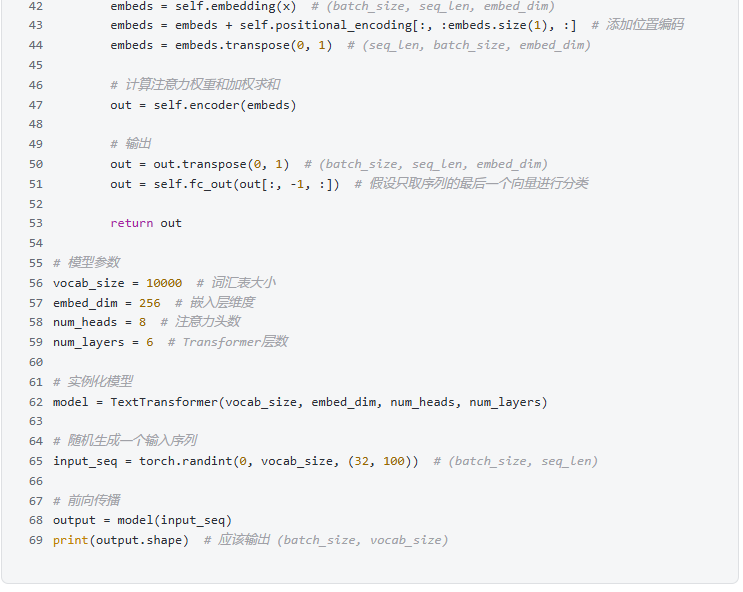
2. Types of Attention Mechanisms
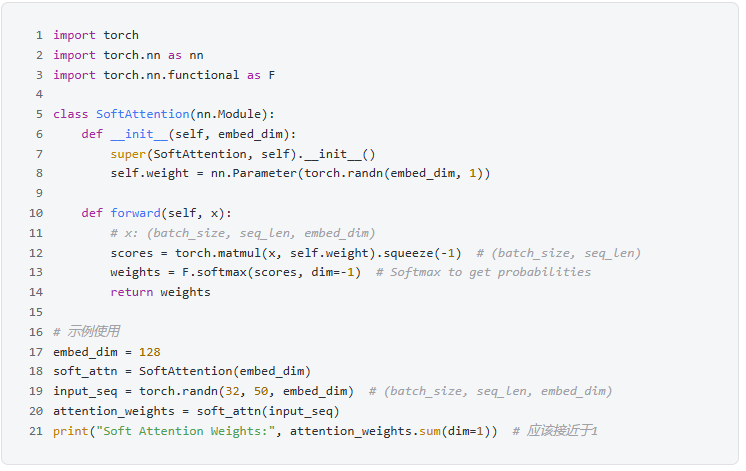
1. Soft Attention
2. Hard Attention
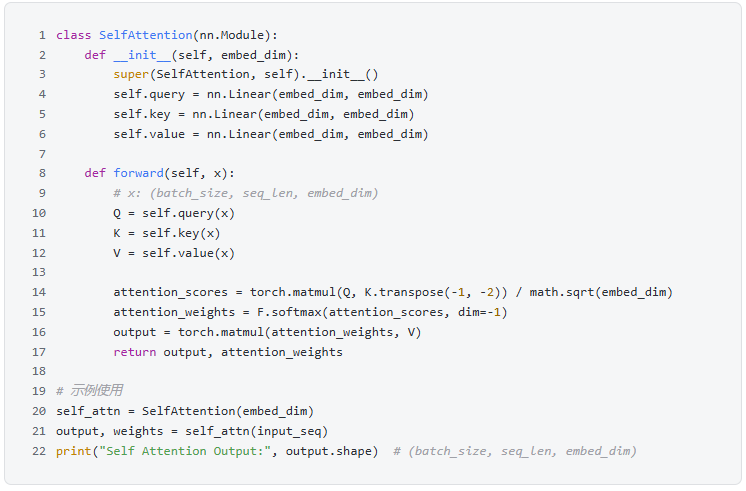
3. Self-Attention
4. Multi-Head Attention

3. Applications of Attention Mechanism
1. Machine Translation

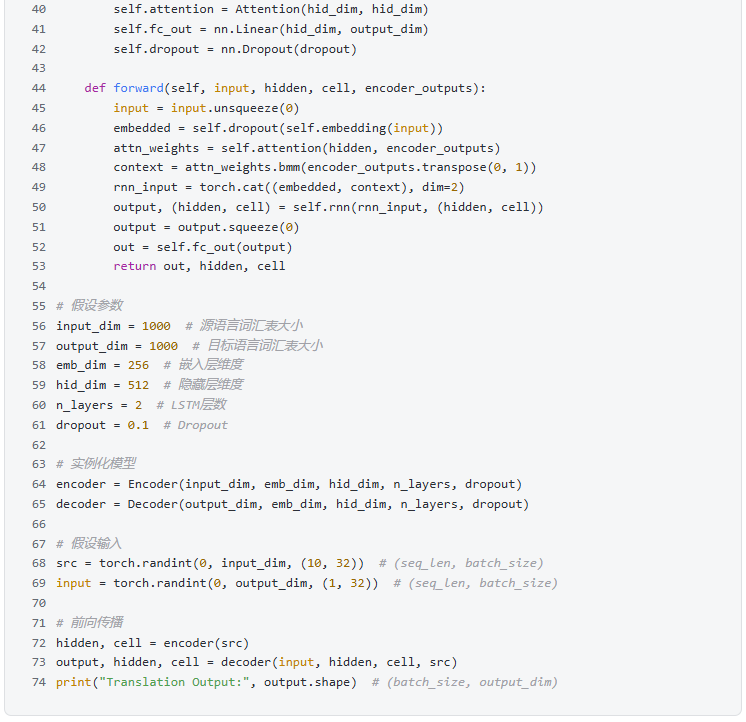
2. Text Summarization

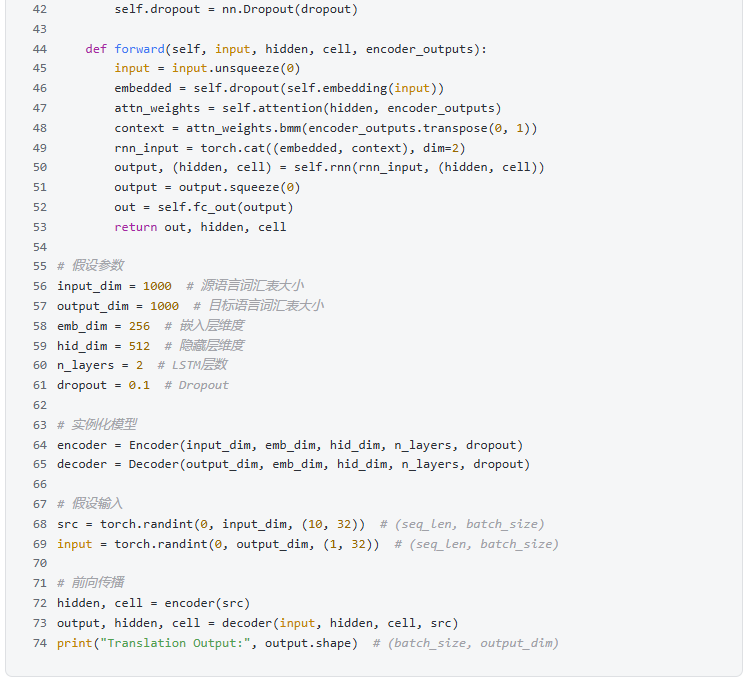
3. Image Recognition
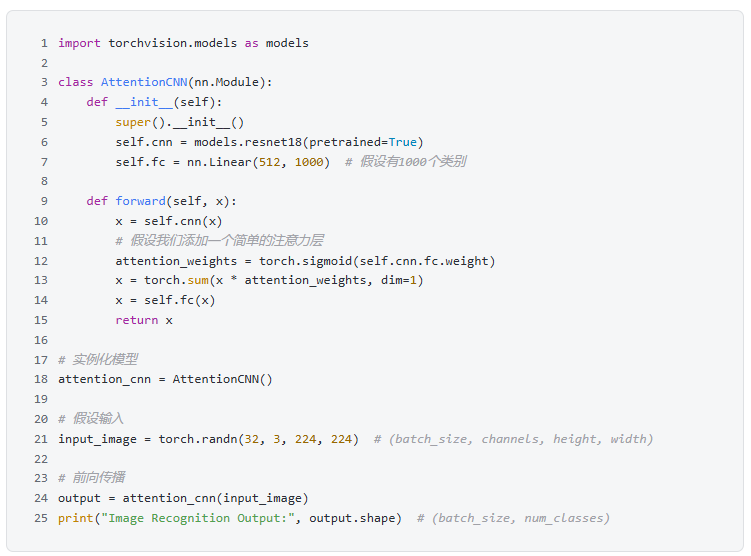
4. Speech Recognition
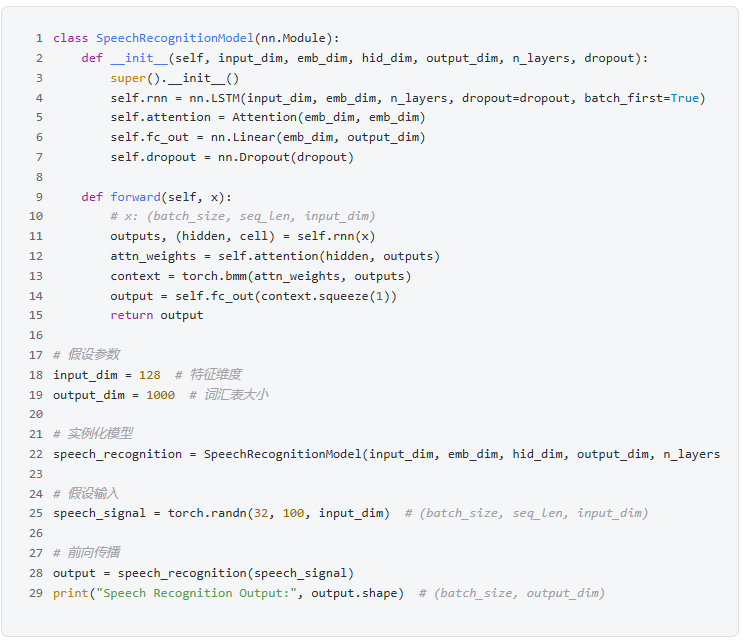
For the source code, please scan the QR code below to contact the teaching assistant.

