Click above toJoin the Computer Vision Alliance for more insights
For academic sharing only, does not represent the stance of this public account, contact for removal if infringing
Reprinted from: Machine Heart
Recommended AI Doctor’s Notes Series
Zhuhua Zhou’s “Machine Learning” hand-pushed notes have officially been open-sourced! Printable version with PDF download link attached
CNN improves performance by stacking more convolutional layers, while transformers quickly saturate as the layers get deeper. Based on this, researchers from the National University of Singapore and ByteDance AI Lab introduced the Re-attention mechanism to regenerate attention maps at a low computational cost to enhance diversity between layers. The proposed DeepViT model also achieved impressive performance.
Vision transformers (ViT) have now been successfully applied to image classification tasks. Recently, researchers from the National University of Singapore and ByteDance’s US AI Lab showed that, unlike convolutional neural networks that improve performance by stacking more convolutional layers, the performance of ViT saturates rapidly when extended to deeper architectures.
How did they reach this conclusion?
Specifically, the researchers observed empirically that this difficulty in scaling is caused by attention collapse: as the transformer deepens, the attention maps gradually become similar or even nearly identical after certain layers. In other words, in the top layers of the deep ViT model, the feature maps tend to be the same. This fact indicates that the self-attention mechanism in deeper ViT models cannot learn effective representation concepts, hindering the model from achieving the expected performance improvement.
Based on the above observations, the researchers proposed a simple and effective method called Re-attention, which can regenerate attention maps while ignoring computational and storage costs to increase their diversity across different layers. With this method, we can train deeper ViT models with sustained performance improvements through minor modifications to existing ViT models. Furthermore, when training the DeepViT model with 32 transformer blocks, it achieved a competitive Top-1 image classification accuracy on the ImageNet dataset. Compared to ViT-32B, the variant model DeepViT-32B improved the Top-1 accuracy by 1.6%.

Paper link: https://arxiv.org/pdf/2103.11886.pdf
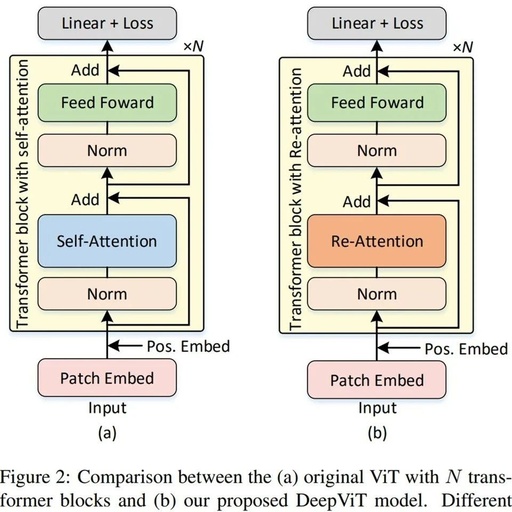
As shown in Figure 2, the ViT model consists of three parts: a linear layer for patch embedding, transformer blocks with multi-head self-attention and feature encoding feedforward layers, and a linear layer for classification score prediction. The researchers first reviewed the uniqueness of the transformer block, particularly the self-attention mechanism, and then studied the problem of attention collapse.
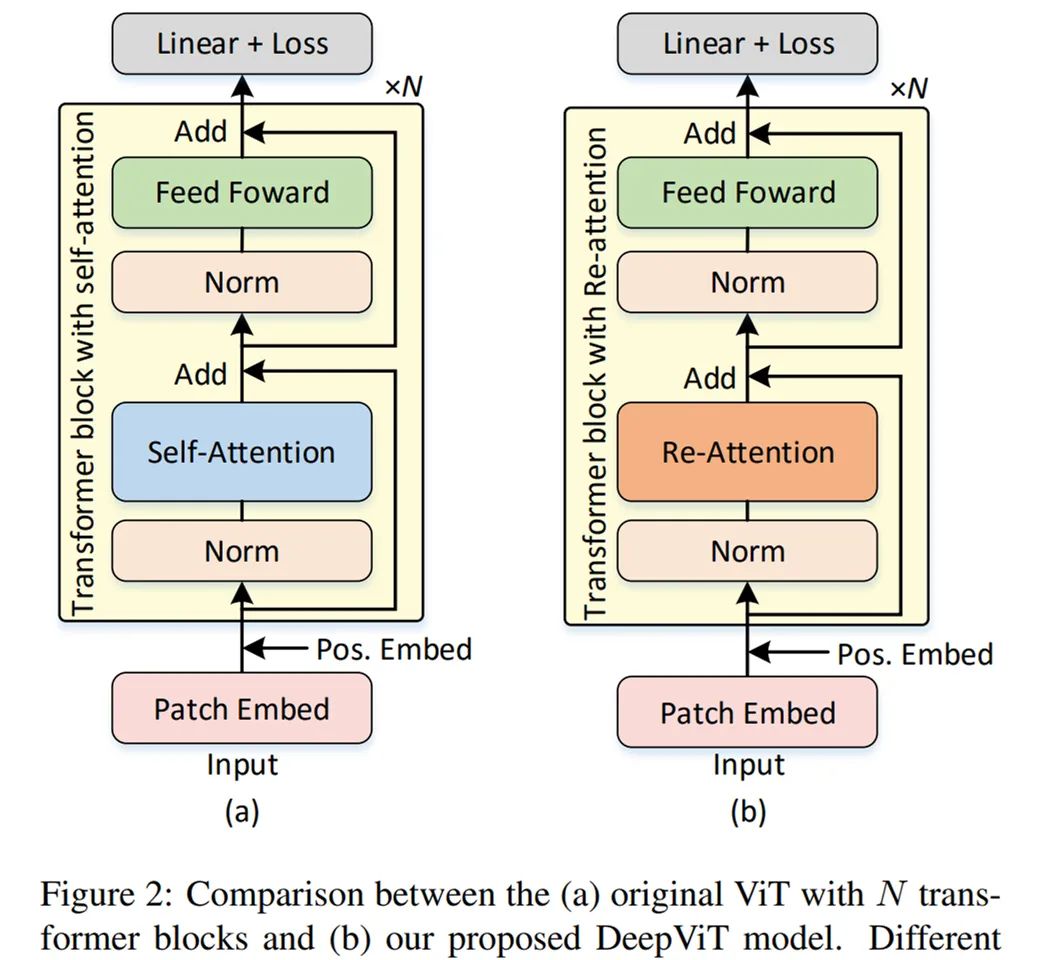
Comparison of the original ViT model with N transformer blocks and the DeepViT model proposed in this study.
Inspired by the success of deep CNNs, the researchers systematically studied the performance changes of ViT as depth increases. Without loss of generality, they first fixed the hidden dimensions and the number of attention heads at 384 and 12, respectively, and then stacked different numbers of transformer blocks (from 12 to 32) to establish multiple ViT models corresponding to different depths. The variation curves of the Top-1 classification accuracy on the ImageNet dataset for the original ViT and DeepViT are shown in Figure 1 below:
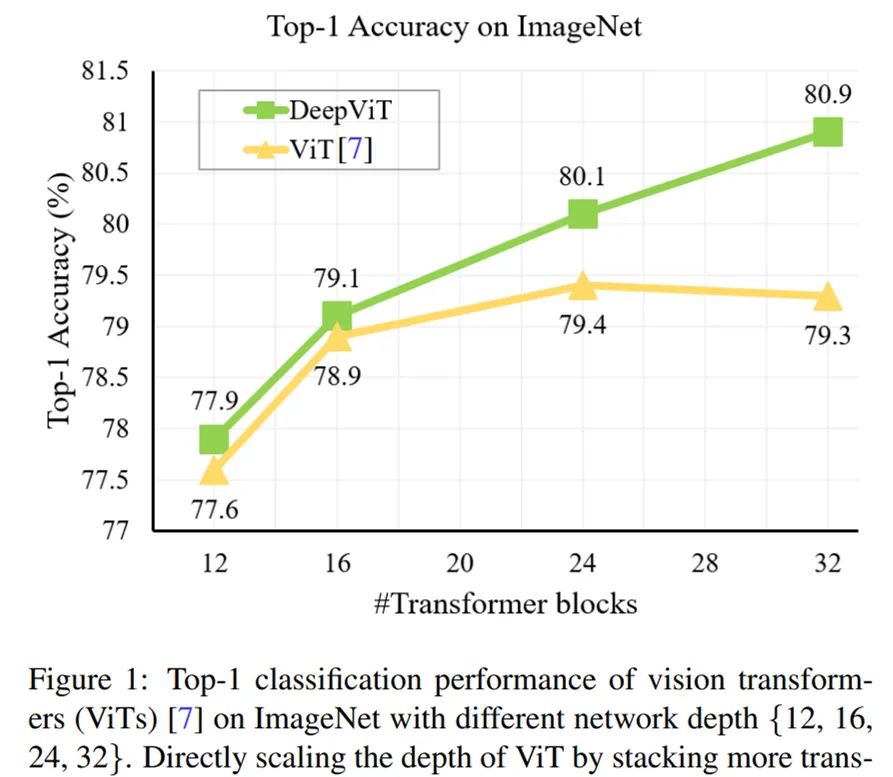
The results indicate that as the model depth increases, the classification accuracy improves slowly, and the saturation speed increases. More specifically, when using 24 transformer blocks, performance stops improving. This phenomenon suggests that existing ViT models struggle to enhance performance in deeper architectures.
To measure the changes in attention maps across different layers, the researchers calculated the cross-layer similarity between attention maps from different layers:
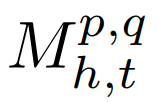
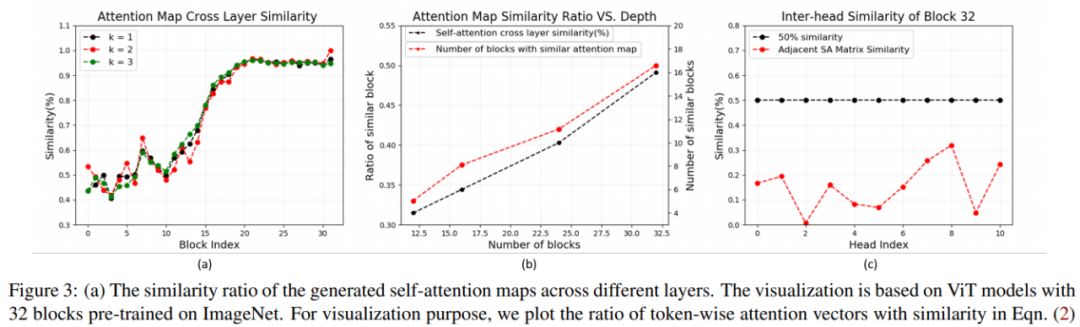
Where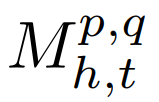 is related to four factors:p and q are two different layers, h is the attention head, t is the specific input, and the results are shown in Figure 3 below.Figure (a) indicates that as depth increases, the attention maps become increasingly similar to the attention maps of k nearby blocks;Figure (c) shows that even at the 32nd block, the similarity between attention heads within the same layer is still relatively low, indicating that the main similarity is still between layers.
is related to four factors:p and q are two different layers, h is the attention head, t is the specific input, and the results are shown in Figure 3 below.Figure (a) indicates that as depth increases, the attention maps become increasingly similar to the attention maps of k nearby blocks;Figure (c) shows that even at the 32nd block, the similarity between attention heads within the same layer is still relatively low, indicating that the main similarity is still between layers.
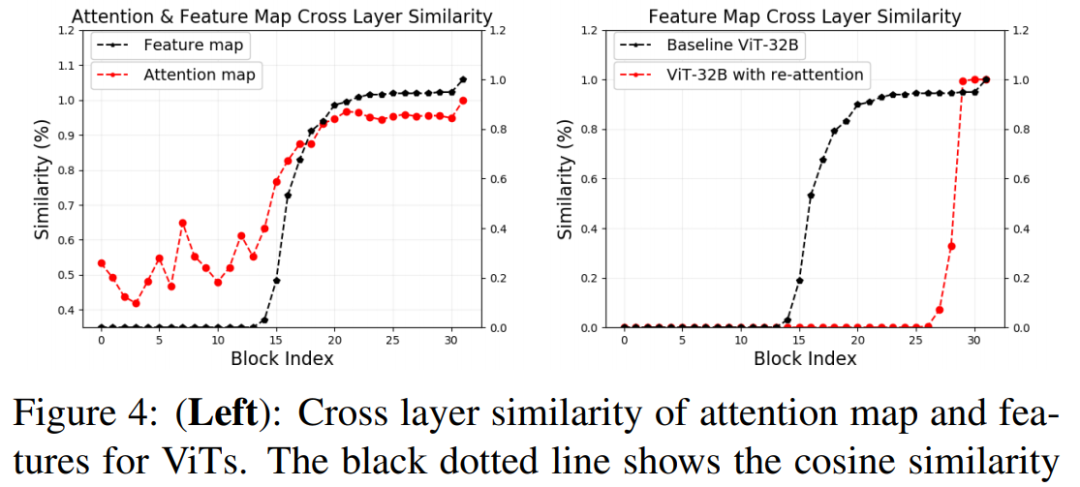
To understand how attention collapse affects the performance of ViT models, the researchers further explored how it impacts feature learning at deeper levels. For a specific 32-block ViT model, by studying their cosine similarities, they compared the final output features with the outputs of each intermediate transformer block.
The results in Figure 4 below indicate that: the similarity between feature maps and attention maps is very high, and the learned features stop changing after the 20th block. The increase in attention similarity is closely correlated with feature similarity. This observation suggests that attention collapse is the reason for the non-scalability of ViT.
As mentioned above, one of the main obstacles to scaling ViT to deeper layers is the issue of attention collapse. Therefore, the researchers proposed two solutions: one is to increase the hidden dimensions of the self-attention computation, and the other is the new re-attention mechanism.
Self-Attention in High-Dimensional Space
One solution to overcome attention collapse is to increase the embedding dimension of each token, which enhances the representational capacity of each token embedding to encode more information. Consequently, the resulting attention maps become more diverse, reducing the similarity between attention maps of each block. Without loss of generality, this study verified this method through a series of experiments based on the ViT model, with 12 blocks used for rapid experimentation. Based on previous transformer-based work, the researchers selected four embedding dimensions ranging from 256 to 768. The detailed configuration results are shown in the table below:
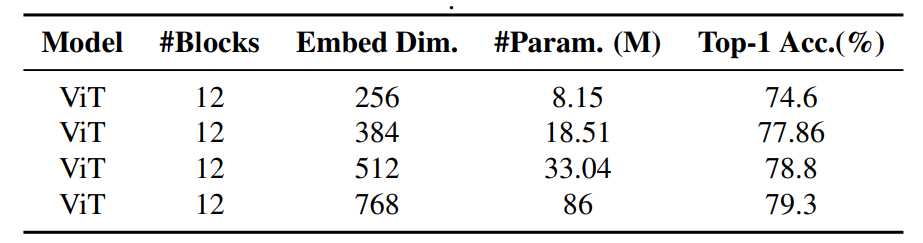
Figure 5 below shows the impact of embedding dimensions on the similarity of generated cross-layer self-attention maps. As can be seen, as the embedding dimension increases, the number of similar attention maps decreases. However, the model size also increases rapidly.
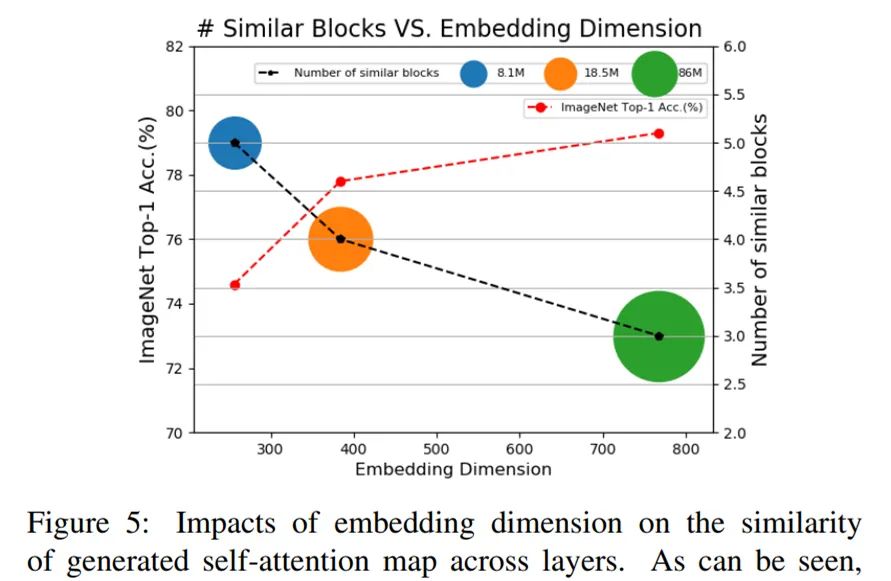
The above text demonstrates that in high-dimensional, especially in deep networks, there is similarity in attention maps between different transformer blocks. However, the researchers found that the similarity of attention maps from different heads of the same transformer block is quite small, as shown in Figure 3(c). Clearly, different heads from the same self-attention layer focus on different aspects of the input tokens. Based on this observation, the researchers suggest establishing cross-head communication to regenerate attention maps, which will improve the performance of training deep ViT.
Specifically, this study generates a new set of attention maps based on the attention maps of heads by dynamically aggregating them. A transformation matrix is used and multiplied by the multi-head attention maps to obtain the new map, and this transformation matrix is learnable. The formula is as follows:
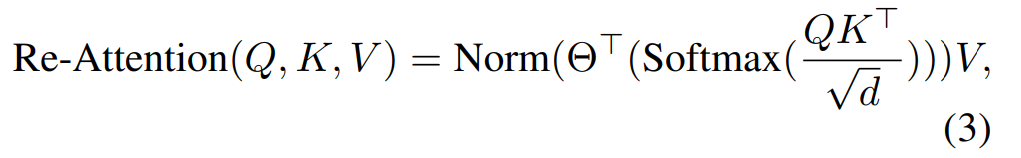
In the experimental section, the researchers first further demonstrated the attention collapse problem through experiments, and then demonstrated the advantages of the Re-attention method through a large number of controlled variable experiments. This study integrated Re-attention into the transformer, designing two improved versions of ViT, named DeepViT. Finally, DeepViT was compared with models with SOTA performance.
Analysis of Attention Collapse
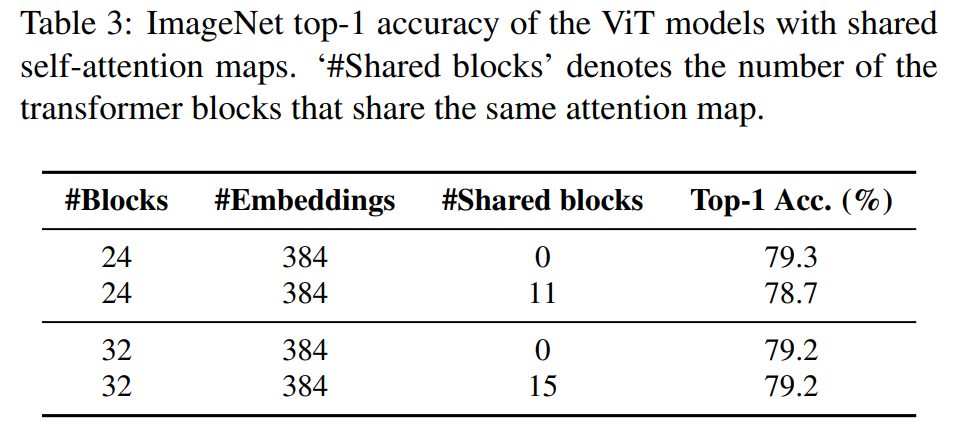
As the model gets deeper, the attention maps of deeper blocks become more similar. This means that adding more blocks to the deep ViT model may not improve model performance. To further validate this statement, the researchers designed an experiment to reuse the attention maps computed in the early blocks of ViT and replace the attention maps after that. The results are shown in Table 3 below:
Comparison of Re-attention and Self-attention. The researchers first evaluated the effectiveness of Re-attention by directly replacing the self-attention in ViT with the Re-attention module. Table 4 shows the comparison of Top-1 accuracy on the ImageNet dataset without varying the number of transformer blocks:
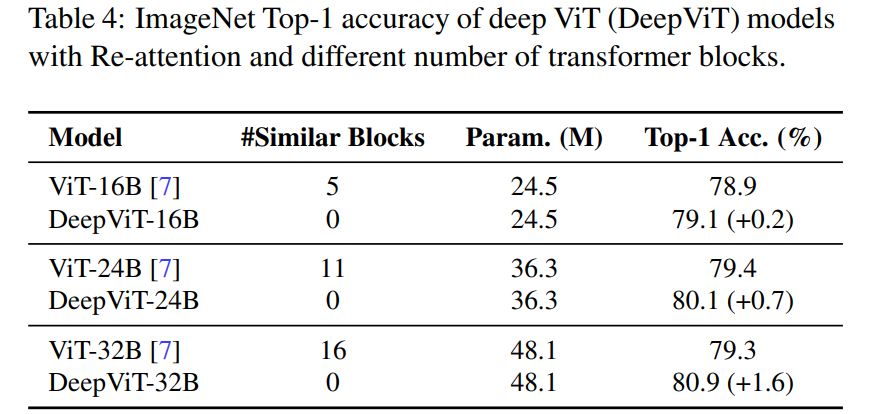
Table 4: ImageNet Top-1 Accuracy.
Comparison with SOTA Models
Based on Re-attention, the researchers designed two variants of ViT, namely DeepViT-S and DeepViT-L, which have 16 and 32 transformer blocks, respectively. For these two models, Re-attention replaced self-attention.
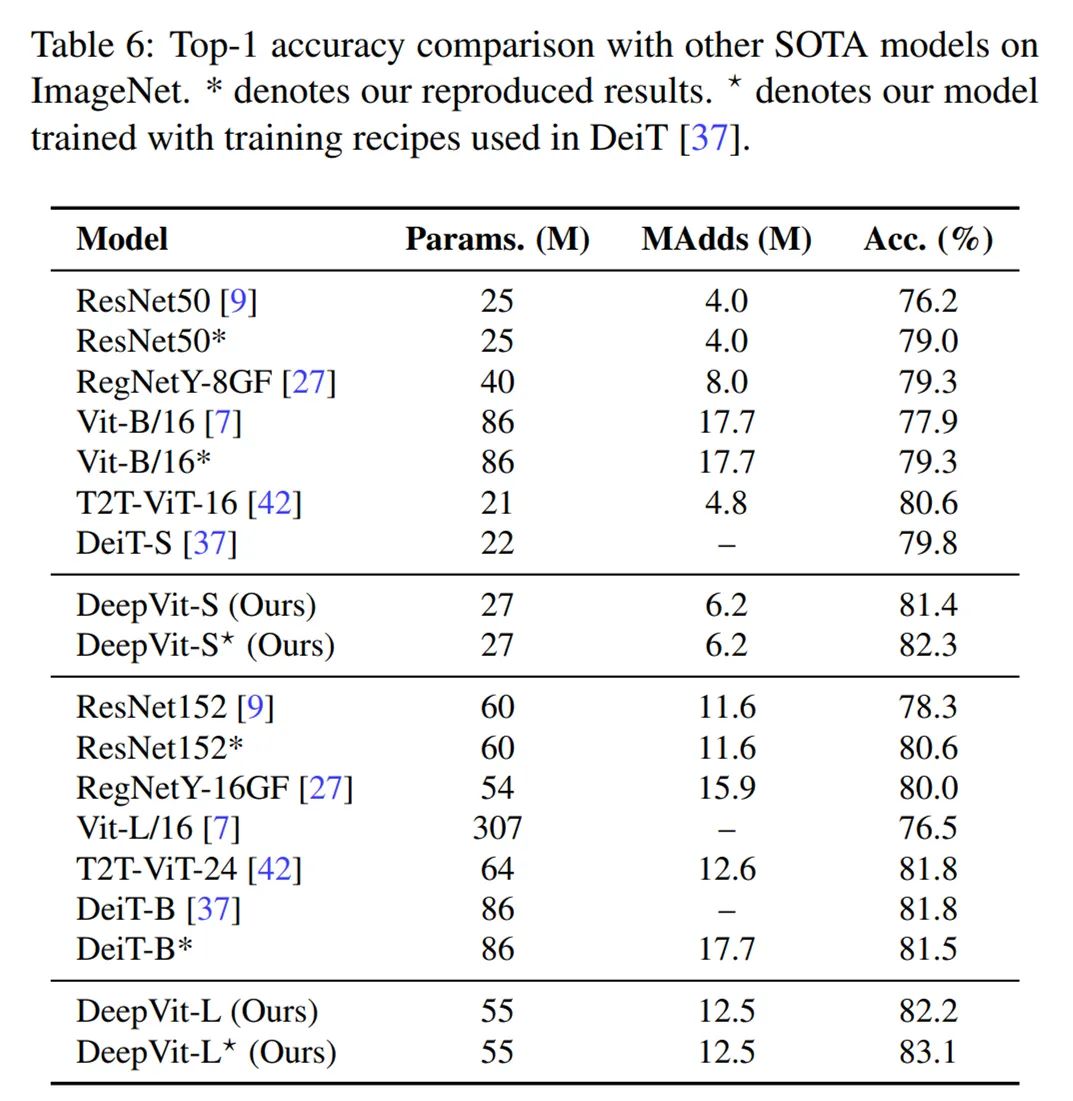
To achieve a similar parameter count as other ViT models, the researchers adjusted the embedding dimensions accordingly, with the results shown in Table 6 below: the DeepViT model achieved better Top-1 accuracy than the latest CNN and ViT models with fewer parameters.
I am Wang Bo Kings, a PhD from a 985 university, Huawei Cloud expert, CSDN blog expert (a high-quality author in the field of artificial intelligence). A single AI open-source project has now gained over 2100 stars. Currently working on AI-related content, feel free to exchange learning and life issues together, let’s progress together!
Our WeChat group covers the following directions (but is not limited to): artificial intelligence, computer vision, natural language processing, object detection, semantic segmentation, autonomous driving, GAN, reinforcement learning, SLAM, face detection, latest algorithms, latest papers, OpenCV, TensorFlow, PyTorch, open-source frameworks, learning methods…
This is my private WeChat, limited spots, let’s improve together!
Wang Bo’s public account, welcome to follow, plenty of insights
Wang Bo Kings’ series of hand-pushed notes (with high-definition PDF download):
Doctor’s Notes | Zhuhua Zhou’s “Machine Learning” hand-pushed notes Chapter 1 Mind Map
Doctor’s Notes | Zhuhua Zhou’s “Machine Learning” hand-pushed notes Chapter 2 “Model Evaluation and Selection”
Doctor’s Notes | Zhuhua Zhou’s “Machine Learning” hand-pushed notes Chapter 3 “Linear Models”
Doctor’s Notes | Zhuhua Zhou’s “Machine Learning” hand-pushed notes Chapter 4 “Decision Trees”
Doctor’s Notes | Zhuhua Zhou’s “Machine Learning” hand-pushed notes Chapter 5 “Neural Networks”
Doctor’s Notes | Zhuhua Zhou’s “Machine Learning” hand-pushed notes Chapter 6 Support Vector Machines (Part 1)
Doctor’s Notes | Zhuhua Zhou’s “Machine Learning” hand-pushed notes Chapter 6 Support Vector Machines (Part 2)
Doctor’s Notes | Zhuhua Zhou’s “Machine Learning” hand-pushed notes Chapter 7 Bayesian Classification (Part 1)
Doctor’s Notes | Zhuhua Zhou’s “Machine Learning” hand-pushed notes Chapter 7 Bayesian Classification (Part 2)
Doctor’s Notes | Zhuhua Zhou’s “Machine Learning” hand-pushed notes Chapter 8 Ensemble Learning (Part 1)
Doctor’s Notes | Zhuhua Zhou’s “Machine Learning” hand-pushed notes Chapter 8 Ensemble Learning (Part 2)
Doctor’s Notes | Zhuhua Zhou’s “Machine Learning” hand-pushed notes Chapter 9 Clustering
Doctor’s Notes | Zhuhua Zhou’s “Machine Learning” hand-pushed notes Chapter 10 Dimensionality Reduction and Metric Learning
Doctor’s Notes | Zhuhua Zhou’s “Machine Learning” hand-pushed notes Chapter 11 Sparse Learning
Doctor’s Notes | Zhuhua Zhou’s “Machine Learning” hand-pushed notes Chapter 12 Computational Learning Theory
Doctor’s Notes | Zhuhua Zhou’s “Machine Learning” hand-pushed notes Chapter 13 Semi-Supervised Learning
Doctor’s Notes | Zhuhua Zhou’s “Machine Learning” hand-pushed notes Chapter 14 Probabilistic Graph Models