Programmers transitioning to AI are following this account👇👇👇
1. Difference Between Attention Mechanism and Self-Attention Mechanism
The difference between Attention mechanism and Self-Attention mechanism
The traditional Attention mechanism occurs between the elements of the Target and all elements in the Source.
In simple terms, the calculation of weights in the Attention mechanism requires participation from the Target. That is, in the Encoder-Decoder model, the calculation of Attention weights requires not only the hidden states in the Encoder but also those in the Decoder.
Self-Attention:
It is not the Attention mechanism between input and output sentences, but rather the Attention mechanism that occurs between internal elements of the input sentence or the output sentence.
For example, in the Transformer, when calculating weight parameters, the word vectors are converted to corresponding KQV, only matrix operations at the Source are needed, and information from the Target is not utilized.
2. Purpose of Introducing Self-Attention Mechanism
The input received by the neural network consists of many vectors of varying sizes, and there are certain relationships between different vectors. However, during actual training, these relationships cannot be fully utilized, resulting in poor model training outcomes. For example, in machine translation problems (sequence-to-sequence problems where the machine decides how many labels), part-of-speech tagging problems (one vector corresponds to one label), semantic analysis problems (multiple vectors correspond to one label), and other text processing issues.
To address the issue that fully connected neural networks cannot establish correlations among multiple related inputs, the self-attention mechanism is introduced. The self-attention mechanism aims to make the machine pay attention to the correlations between different parts of the entire input.
3. Detailed Explanation of Self-Attention
For an input of a set of vectors, the output is also a set of vectors, where the input length is N (N can vary), and the output is also a vector of length N.
3.1 Single Output
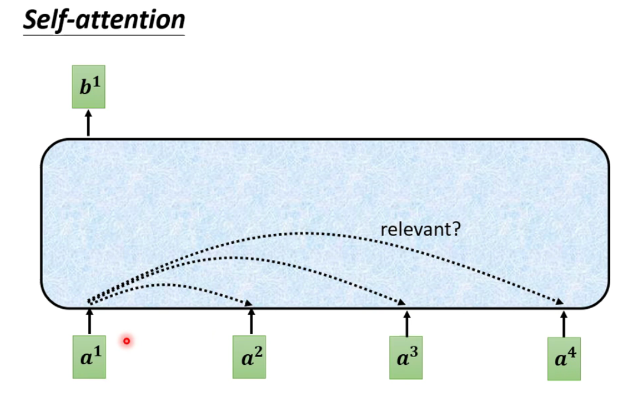
For each input vector a, after passing through the blue part of self-attention, an output vector b is produced. This vector b is derived by considering the influence of all input vectors on a1, resulting in four output vectors b corresponding to four word vectors a.
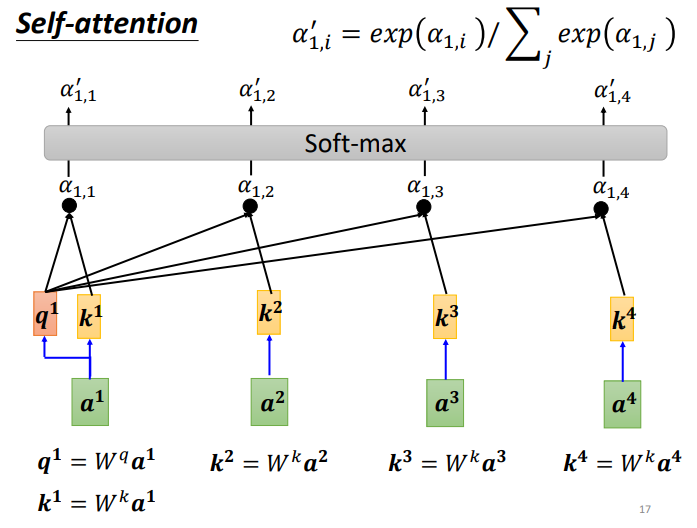
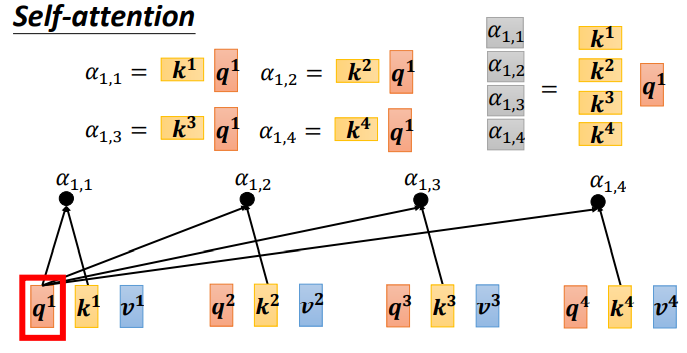
Taking b1’s output as an example
First, how to calculate the correlation degree of each vector in the sequence with a1, there are two methods:
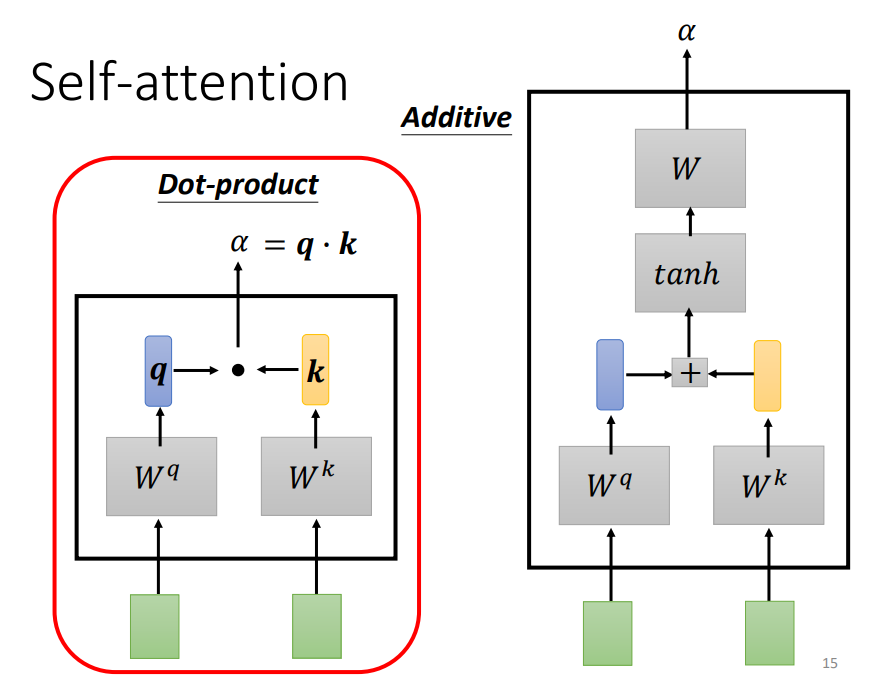
The dot-product method multiplies two vectors by different matrices w to obtain q and k, then performs a dot product to get α, which is used in transformers.
In the above diagram, the green part represents input vectors a1 and a2, and the gray Wq and Wk are weight matrices that need to be learned and updated. By multiplying a1 with Wq, a vector q is obtained, and by multiplying a2 with Wk, a value k is obtained. Finally, the dot product of q and k yields α, which indicates the correlation degree between the two vectors.
The additive model on the right also multiplies the input vector with weight matrices and sums them, then projects using tanh into a new function space and multiplies with the weight matrix to obtain the final result.
Each α (also known as the attention score) can be computed, where q is called the query and k is called the key.
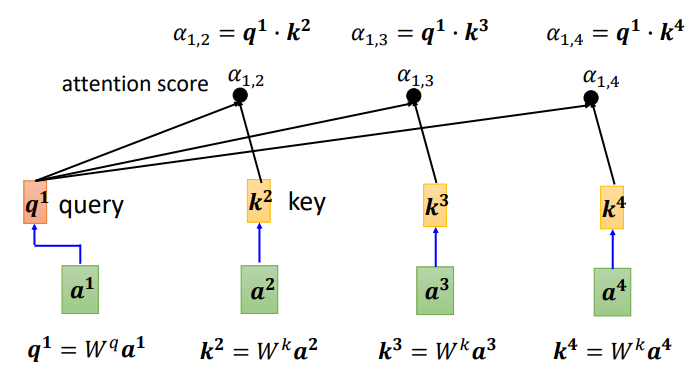
Additionally, the correlation of a1 with itself can be calculated, and after obtaining the correlation degrees of each vector with a1, a softmax can be applied to compute an attention distribution, normalizing the correlation degrees to reveal which vectors are most related to a1.
Next, important information from the sequence needs to be extracted based on α′:
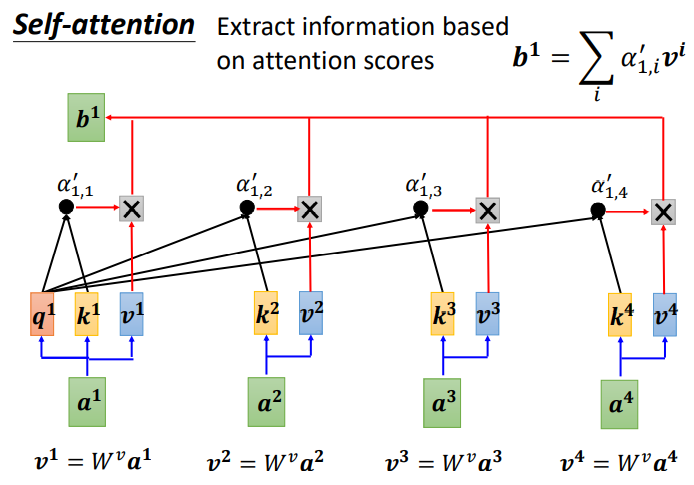
First, calculate v, which is the key value. v is calculated in the same way as q and k, also by multiplying the input a by the weight matrix W. After obtaining v, it is multiplied by the corresponding α′, and then each v multiplied by α’ is summed to produce the output b1.
If a1 and a2 have a high correlation, then α1,2′ will be relatively large, meaning the output b1 is likely to be close to v2, indicating that the attention score determines the contribution of that vector in the result;
3.2 Matrix Form
The generation of b1 can be represented using matrix operations:
Step 1:Generation of q, k, v in matrix form
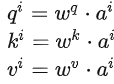
Written in matrix form:
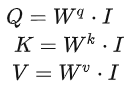
Combine the four inputs a into a matrix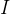 , this matrix has four columns, corresponding to a1 to a4,
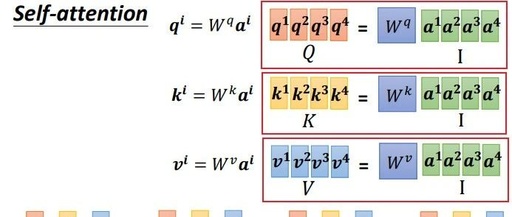
, this matrix has four columns, corresponding to a1 to a4,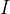 multiplied by the corresponding weight matrix W to obtain the corresponding matrices Q, K, and V, representing query, key, and value respectively.
multiplied by the corresponding weight matrix W to obtain the corresponding matrices Q, K, and V, representing query, key, and value respectively.
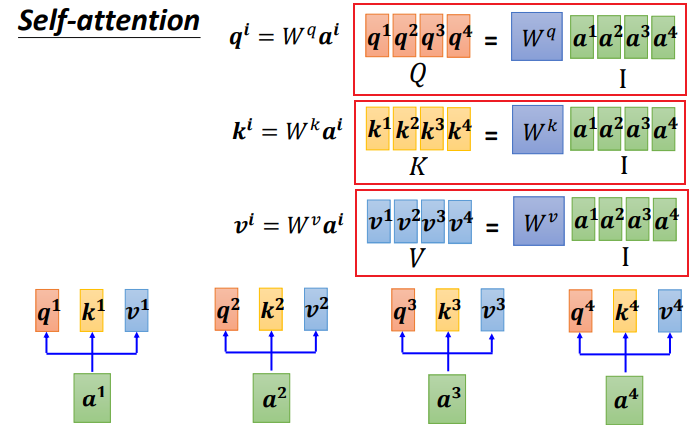
The three Ws are the parameters we need to learn
Step 2:Using the obtained Q and K to calculate the correlation between every two input vectors, which is to compute the attention value α. There are various methods to calculate α, usually using the dot product approach.
First, for q1, multiply it with the matrix K formed by concatenating k1 to k4 to obtain 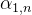 concatenated matrix.
concatenated matrix.
Similarly, q1 to q4 can also be concatenated into matrix Q and directly multiplied by matrix K:

The formula is:
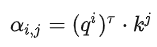
In matrix form:
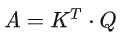
Each value in matrix A records the size of the Attention between the corresponding two input vectors, and A’ is the matrix after softmax normalization.
Step 3:Using the obtained A’ and V to calculate the output vector b corresponding to each input vector a from the self-attention layer:
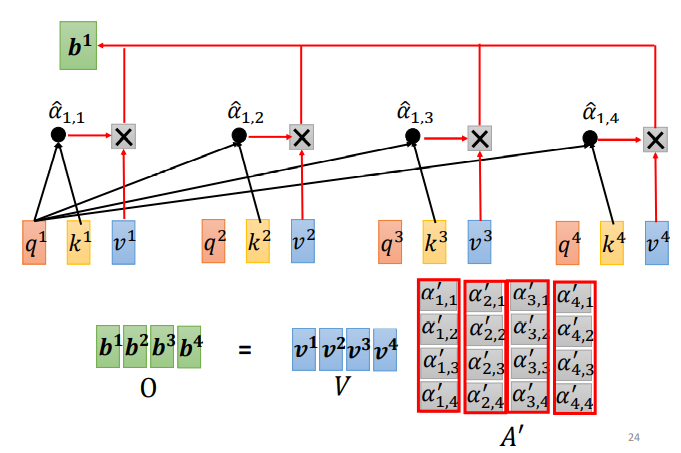
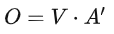
Written in matrix form:
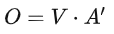
To summarize the self-attention operation process, the input is I, and the output is O:
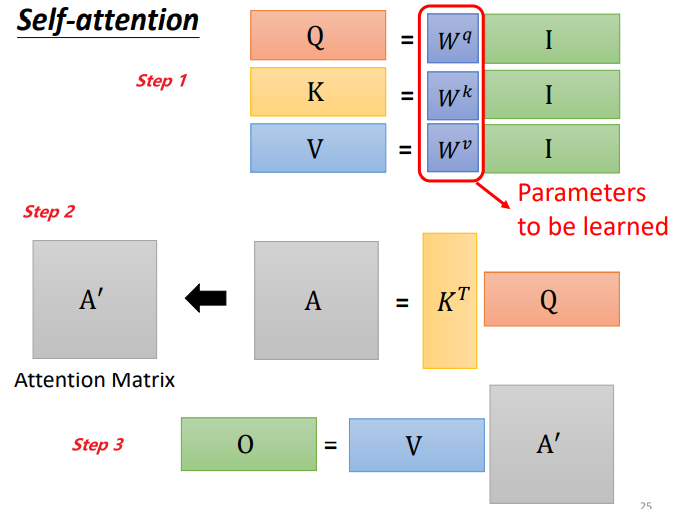
The matrices Wq, Wk, and Wv are the parameters that need to be learned.
4. Multi-head Self-attention
The advanced version of self-attention is Multi-head Self-attention, where multiple heads are used due to the various forms and definitions of correlation. Thus, it is necessary to have multiple q’s, with different q’s responsible for different types of correlations.
For a single input a
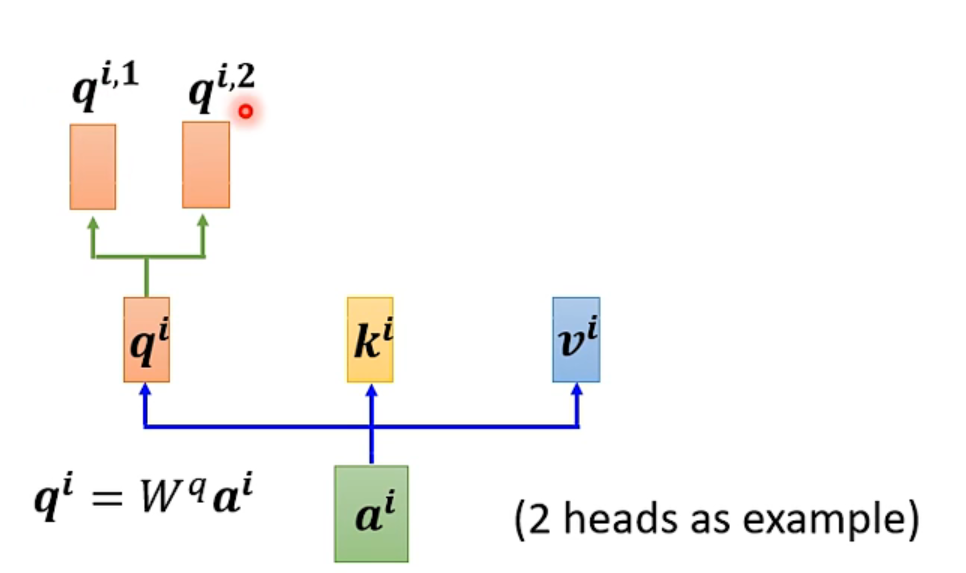
First, similarly, multiply a by the weight matrix W, and then use two different W’s to obtain two different q’s, where i represents the position, and 1 and 2 denote the first and second q at that position.
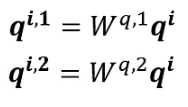
This diagram shows two heads, indicating that there are two different types of correlations.
Similarly, k and v also need to have multiple heads, with two k’s and v’s calculated in the same way as q, first calculating ki and vi, then multiplying with two different weight matrices.
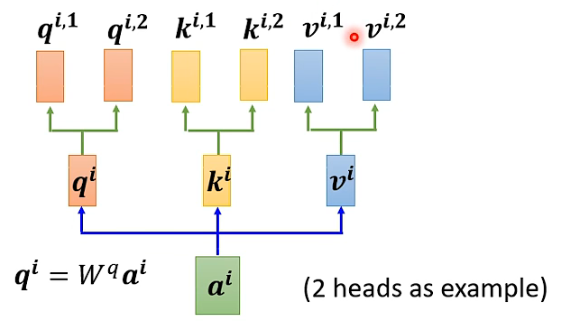
The same applies to multiple input vectors, where each vector has multiple heads:
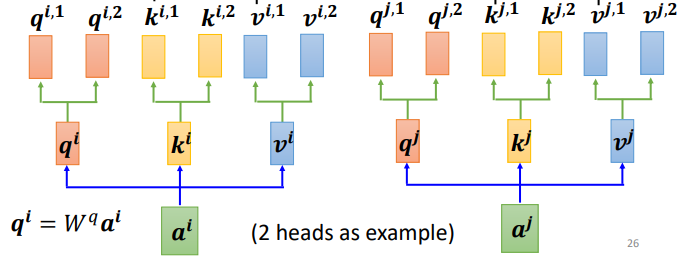
How to perform self-attention with multiple heads after calculating q, k, and v?
Similar to the above process, but class 1 is computed together and class 2 is computed together, resulting in two independent processes and two b’s.
For 1:
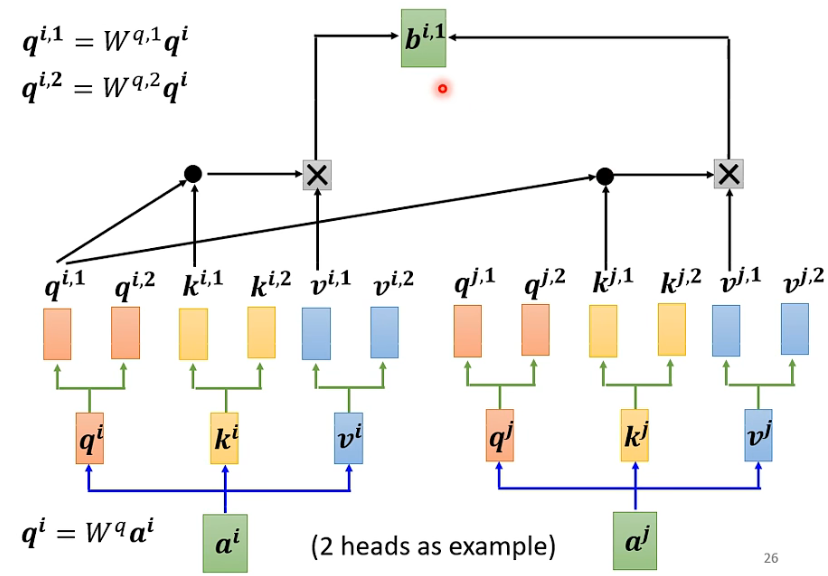
For 2:
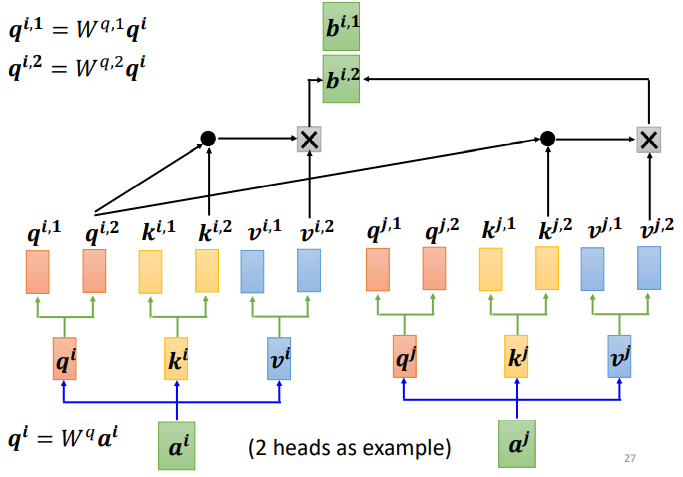
This is just an example with two heads; the process is the same for multiple heads, where b is calculated separately.

5. Positional Encoding
When training self-attention, positional information is actually missing, with no distinction between previous and later inputs. The above-mentioned a1, a2, a3 do not represent the order of inputs, just the number of input vectors, unlike RNNs that have a clear order for inputs, such as in translation tasks where “machine learning” is input sequentially. In contrast, self-attention inputs are processed simultaneously, producing outputs simultaneously as well.
How to reflect positional information in Self-Attention? By using Positional Encoding.

If ai is added to ei, positional information is reflected, where i indicates the position.
The vector length is set manually or can be trained from the data.
6. Difference Between Self-Attention and RNN
The main differences between Self-attention and RNN are:
1. Self-attention can consider all inputs, while RNN seems to only consider previous inputs (left). However, this issue can be avoided using bidirectional RNNs.
2. Self-attention can easily consider inputs from a long time ago, while the earliest inputs in RNNs become difficult to consider due to the processing through many layers of the network.
3. Self-attention can be computed in parallel, while RNNs have a sequential order between different layers.
1. Self-attention can consider all inputs, while RNN seems to only consider previous inputs (left). However, this issue can be avoided using bidirectional RNNs.
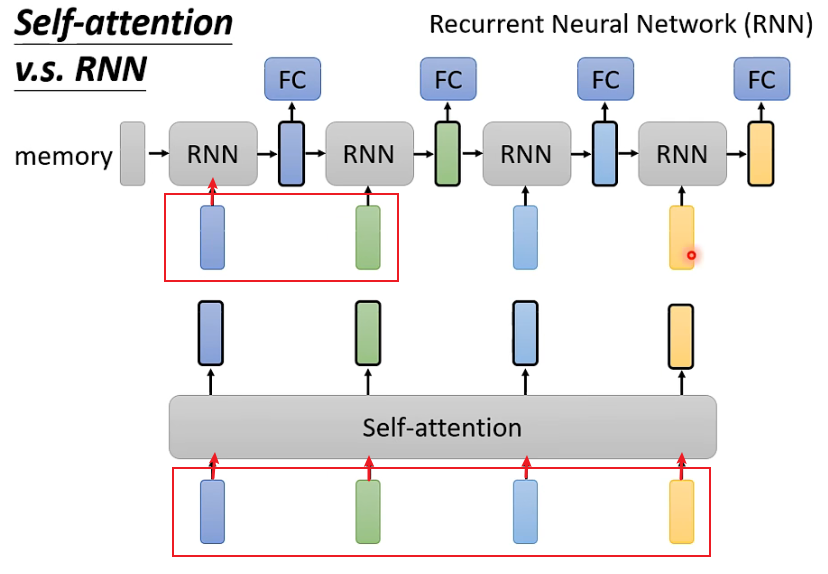
For example, the first RNN only considers the deep blue input, while the green and subsequent inputs are not considered, whereas Self-Attention considers all four inputs.
2. Self-attention can easily consider inputs from a long time ago, while the earliest inputs in RNNs become difficult to consider due to the processing through many layers of the network.
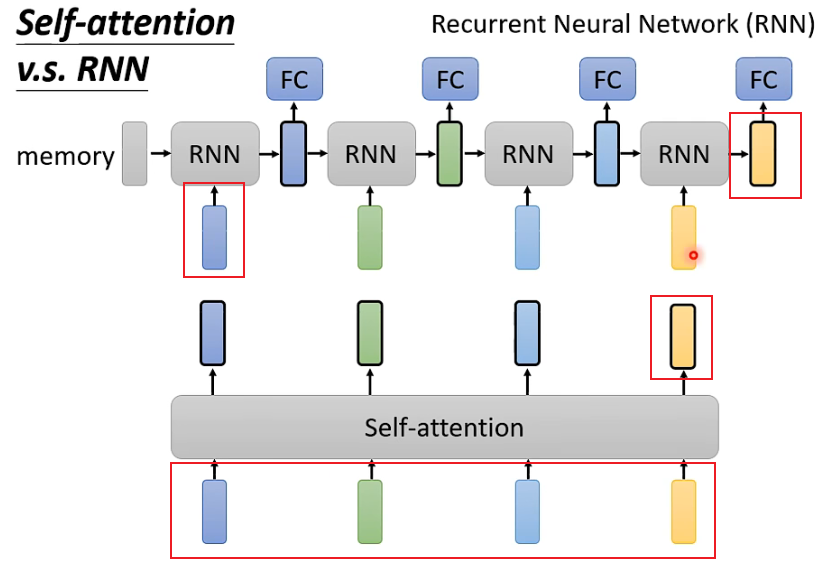
For example, for the last RNN’s yellow output, if we want to include the initial blue input, we must ensure that the blue input does not lose information through each layer. However, if a sequence is very long, it becomes difficult to guarantee this. In contrast, each output in Self-attention is directly related to all inputs.
3. Self-attention can be computed in parallel, while RNNs have a sequential order between different layers.
Self-attention inputs are processed simultaneously, and outputs are also produced simultaneously.
Machine Learning Algorithms AI Big Data Technology
Search for the public account to add: datanlp

Long press the image to recognize the QR code
People who have read this article have also looked at the following articles:
TensorFlow 2.0 Deep Learning Case Practical
Based on the 400,000 table dataset TableBank, using MaskRCNN for table detection
《Natural Language Processing Based on Deep Learning》 Chinese/English PDF
Deep Learning Chinese Version First Edition – Zhou Zhihua Team
[Complete Video Course] The Most Comprehensive Series of Object Detection Algorithm Explanations, Easy to Understand!
《Meituan Machine Learning Practice》_Meituan Algorithm Team.pdf
《Introduction to Deep Learning: Theory and Implementation Based on Python》 High Definition Chinese PDF + Source Code
《Deep Learning: Python Practice Based on Keras》 PDF and Code
Feature Extraction and Image Processing (Second Edition).pdf
Python Employment Class Learning Video, From Entry to Practical Projects
2019 Latest 《PyTorch Natural Language Processing》 English and Chinese Version PDF + Source Code
《21 Projects to Master Deep Learning: Detailed Explanation Based on TensorFlow》 Full Version PDF + Attached Book Code
《Deep Learning with PyTorch》 PDF + Attached Book Source Code
PyTorch Deep Learning Quick Practical Introduction 《pytorch-handbook》
[Download] Douban Rating 8.1, 《Machine Learning Practical: Based on Scikit-Learn and TensorFlow》
《Python Data Analysis and Mining Practical》 PDF + Complete Source Code
Complete Knowledge Graph Project Practice Video in the Automotive Industry (All 23 Lessons)
Li Mu’s Open Source 《Hands-On Deep Learning》, UC Berkeley Deep Learning (Spring 2019) Teaching Material
Notes and Code Clear and Easy to Understand! Li Hang’s 《Statistical Learning Methods》 Latest Resource Full Set!
《Neural Networks and Deep Learning》 Latest 2018 Edition Chinese and English PDF + Source Code
Deploy Machine Learning Models as REST API
FashionAI Clothing Attribute Tag Image Recognition Top 1-5 Solutions Sharing
Important Open Source! CNN-RNN-CTC Implementation of Handwritten Chinese Character Recognition
YOLO3 Detecting Irregular Chinese Characters in Images
As a Machine Learning Algorithm Engineer, why can’t you pass the interview?
Qianhai Credit Big Data Algorithm: Risk Probability Prediction
[Keras] Complete Implementation of ‘Traffic Sign’ Classification and ‘Receipt’ Classification Projects to Master Deep Learning Image Classification
VGG16 Transfer Learning, Implementing Medical Image Recognition Classification Engineering Project
Feature Engineering (One)
Feature Engineering (Two): Expansion, Filtering, and Chunking of Text Data
Feature Engineering (Three): Feature Scaling, From Bag of Words to TF-IDF
Feature Engineering (Four): Categorical Features
Feature Engineering (Five): PCA Dimensionality Reduction
Feature Engineering (Six): Non-linear Feature Extraction and Model Stacking
Feature Engineering (Seven): Image Feature Extraction and Deep Learning
How to Use the New Decision Tree Ensemble Cascade Structure gcForest for Feature Engineering and Scoring?
Machine Learning Yearning Chinese Translation Draft
Ant Financial 2018 Fall Recruitment – Algorithm Engineer (Four Interviews) Passed
Global AI Challenge – Scene Classification Competition Source Code (Multi-Model Fusion)
Stanford CS230 Official Guide: CNN, RNN, and Usage Tips Quick Reference (Print and Collect)
Python + Flask to Build an Online Recognition Website for Handwritten Chinese
Chinese Academy of Sciences Kaggle Global Text Matching Competition Chinese Team 1st Place – Deep Learning and Feature Engineering
Continuously Updated Resources
Deep Learning, Machine Learning, Data Analysis, Python
Search for the public account to add: datayx

