
From | Zhihu Author | JayLou
Link | https://zhuanlan.zhihu.com/p/53682800
Editor | Deep Learning Matters public account
This article is for academic sharing only. If there is any infringement, please contact us to delete it.
This article summarizes the attention mechanism in natural language processing (NLP) in a Q&A format and provides an in-depth analysis of the Transformer.
Table of Contents
1. Analysis of Attention Mechanism 1. Why introduce the Attention mechanism? 2. What types of Attention mechanisms are there? (How to classify?) 3. What is the computational process of the Attention mechanism? 4. What variants of the Attention mechanism are there? 5. A powerful Attention mechanism: Why is the self-Attention model so powerful in long-distance sequences? (1) Can convolutional or recurrent neural networks handle long-distance sequences? (2) What methods can solve the “local encoding” problem of short-distance dependencies to establish long-distance dependencies in the input sequence? (3) What is the specific computational process of the self-Attention model?2. Detailed Explanation of Transformer (Attention Is All You Need) 1. What is the overall architecture of the Transformer? What components does it consist of? 2. What are the differences between Transformer Encoder and Transformer Decoder? 3. What are the differences between Encoder-Decoder attention and self-attention mechanism? 4. What is the specific computational process of the multi-head self-attention mechanism? 5. How is Transformer applied in pre-trained models like GPT and BERT? What changes are there?
1. Analysis of Attention Mechanism
1. Why introduce the Attention mechanism?
According to the universal approximation theorem, both feedforward networks and recurrent networks have strong capabilities. But why introduce the Attention mechanism?
-
Limitations of computational power: When needing to remember a lot of “information”, the model becomes more complex; however, current computational power remains a bottleneck limiting the development of neural networks.
-
Limitations of optimization algorithms: Although local connections, weight sharing, and pooling can simplify neural networks and effectively alleviate the conflict between model complexity and expressiveness, the information “memory” capability, such as the long-distance dependency problem in recurrent neural networks, is not high.
The Attention mechanism can help improve the neural network’s ability to process information, similar to how the human brain handles information overload.
2. What types of Attention mechanisms are there? (How to classify?)
When using neural networks to process large amounts of input information, we can also draw on the human brain’s attention mechanism to selectively process some key information to improve the efficiency of neural networks. According to cognitive neuroscience, attention can be broadly divided into two categories:
-
Focused (focus) attention: Top-down conscious attention, actively focusing—refers to attention that is purpose-driven, task-dependent, and actively focused on a certain object;
-
Saliency-based attention: Bottom-up conscious attention, passive attention—saliency-based attention is driven by external stimuli and does not require active intervention, nor is it task-dependent; max-pooling and gating mechanisms can be approximated as bottom-up saliency-based attention mechanisms.
In artificial neural networks, the attention mechanism generally refers specifically to focused attention.
3. What is the computational process of the Attention mechanism?
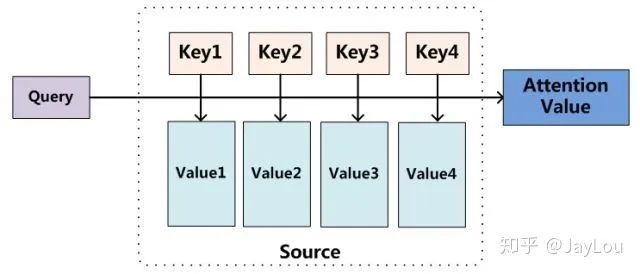
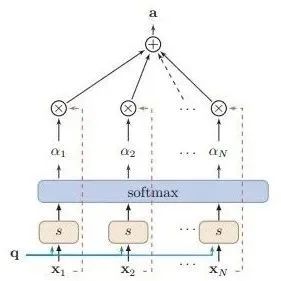
The essence of the Attention mechanism is actually an addressing process, as shown in the figure above: given a query vector Query q related to the task, the Attention distribution is calculated against Key and applied to Value, thus calculating the Attention Value. This process is actually a reflection of how the Attention mechanism alleviates the complexity of neural network models: it does not require all N input pieces of information to be fed into the neural network for computation, but only needs to select some task-related information from X to input into the neural network.
The Attention mechanism can be divided into three steps: first, information input; second, calculating the attention distribution α; third, calculating the weighted average of the input information based on the attention distribution α.
step1-Information Input: Let X = [x1, · · · , xN ] represent N pieces of input information;
step2-Calculating the attention distribution: Let Key=Value=X, then the attention distribution can be given as
We call the attention distribution (probability distribution), and
is the attention scoring mechanism, with several scoring mechanisms:
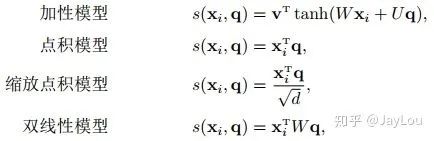
step3-Weighted average of information: The attention distribution can be interpreted as the degree of attention given to the i-th piece of information when querying context q, using a “soft” information selection mechanism to encode the input information X as:
This encoding method is called soft Attention, which has two modes: ordinary mode (Key=Value=X) and key-value pair mode (Key!=Value).
4. What variants of the Attention mechanism are there?
Compared to ordinary Attention mechanisms (the left side of the figure), what variants of the Attention mechanism are there?
Variant 1-Hard Attention: The previously mentioned attention is soft attention, which selects information based on the expected value of all input information under the attention distribution. Another type of attention focuses only on information at a specific position, called hard attention (hard attention). Hard attention has two implementation methods: (1) one is to select the input information with the highest probability; (2) the other hard attention can be implemented by randomly sampling from the attention distribution. A drawback of hard attention:
A drawback of hard attention is that it selects information based on maximum sampling or random sampling. Therefore, the final loss function is not differentiable with respect to the attention distribution, making it unsuitable for training using backpropagation algorithms. To use backpropagation, soft attention is generally used to replace hard attention. Hard attention requires reinforcement learning for training. — “Neural Networks and Deep Learning”
Variant 2-Key-Value Attention: This corresponds to the right side of the figure where Key != Value, and the attention function becomes:
Variant 3-Multi-Head Attention: Multi-head attention (multi-head attention) utilizes multiple queries Q = [q1, · · · , qM] to compute and select multiple pieces of information from the input information in parallel. Each attention head focuses on different parts of the input information and then concatenates:
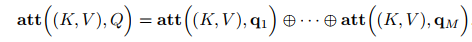
5. A powerful Attention mechanism: Why is the self-Attention model so powerful in long-distance sequences?
(1) Can convolutional or recurrent neural networks handle long-distance sequences?
When using neural networks to process a variable-length vector sequence, we can typically use convolutional or recurrent networks to encode and obtain an output vector sequence of the same length, as shown:
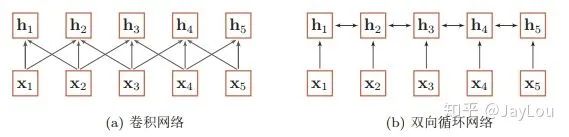
From the above figure, it can be seen that both convolutional and recurrent neural networks are essentially a form of “local encoding” for variable-length sequences: convolutional neural networks are evidently based on N-gram local encoding; for recurrent neural networks, due to issues like gradient vanishing, they can only establish short-distance dependencies.
(2) What methods can solve the “local encoding” problem of short-distance dependencies to establish long-distance dependencies in the input sequence?
To establish long-distance dependencies between input sequences, two methods can be used: one method is to increase the depth of the network to obtain long-distance information interaction through a deep network, and the other method is to use fully connected networks. — “Neural Networks and Deep Learning”
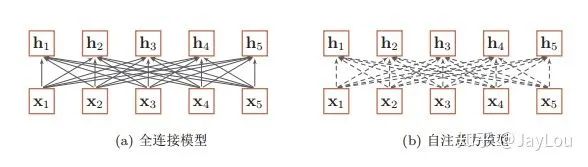
As can be seen from the above figure, while fully connected networks are a very direct modeling approach for long-distance dependencies, they cannot handle variable-length input sequences. Different input lengths will have different connection weights.
At this point, we can utilize the attention mechanism to “dynamically” generate different connection weights, which is the self-attention model. Because the weights of the self-attention model are dynamically generated, it can handle variable-length information sequences.
In summary, why is the self-Attention model so powerful: it utilizes the attention mechanism to “dynamically” generate different connection weights to handle variable-length information sequences.
(3) What is the specific computational process of the self-Attention model?
Similarly, given the input information: let X = [x1, · · · , xN ] represent N pieces of input information; through linear transformations, obtain the query vector sequence, key vector sequence, and value vector sequence:
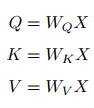
The formula above shows that Q in self-Attention is a transformation of its own (self) input, while in traditional Attention, Q comes from external.
The attention computation formula is:

2. Detailed Explanation of Transformer (Attention Is All You Need)
From the title of the Transformer paper, it can be seen that the core of the Transformer is Attention, which is why this article introduces the Transformer after analyzing the Attention mechanism. If you understand the above Attention mechanism, especially the self-Attention model, the Transformer will be easy to understand.
1. What is the overall architecture of the Transformer? What components does it consist of?
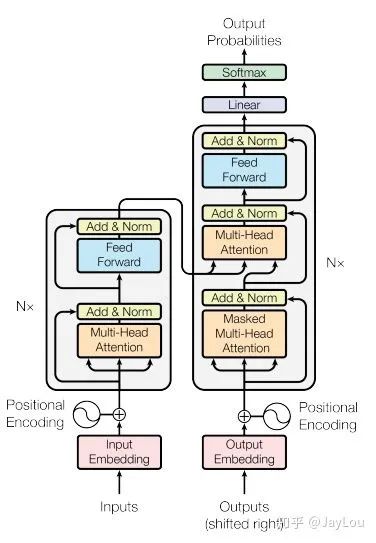
Transformer is essentially a Seq2Seq model, with an encoder on the left reading the input and a decoder on the right producing the output:
Transformer=Transformer Encoder+Transformer Decoder
(1) Transformer Encoder (N=6 layers, each layer includes 2 sub-layers):
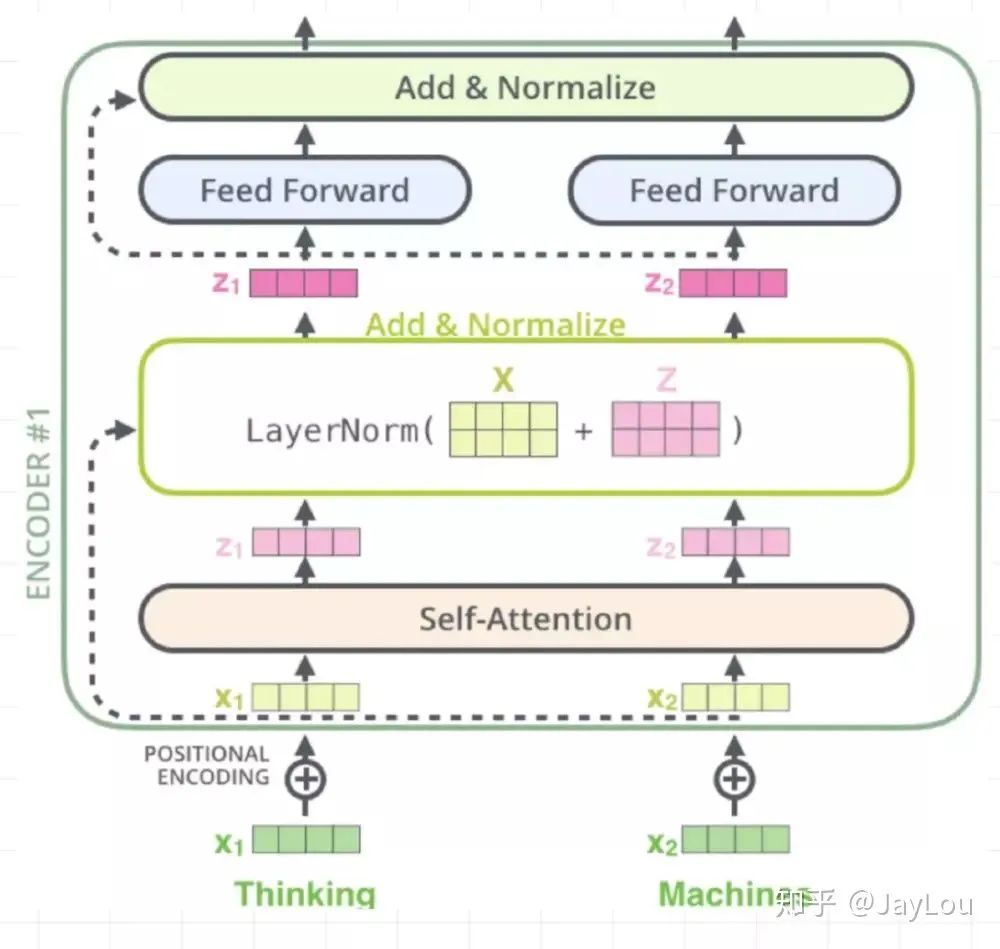
-
sub-layer-1: multi-head self-attention mechanism, used for self-attention. -
sub-layer-2: Position-wise Feed-forward Networks, a simple fully connected network that performs the same operation on each position’s vector, including two linear transformations and a ReLU activation output (input and output layer dimensions are both 512, with a hidden layer of 2048):
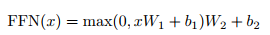
Each sub-layer uses a residual network:
(2) Transformer Decoder (N=6 layers, each layer includes 3 sub-layers):
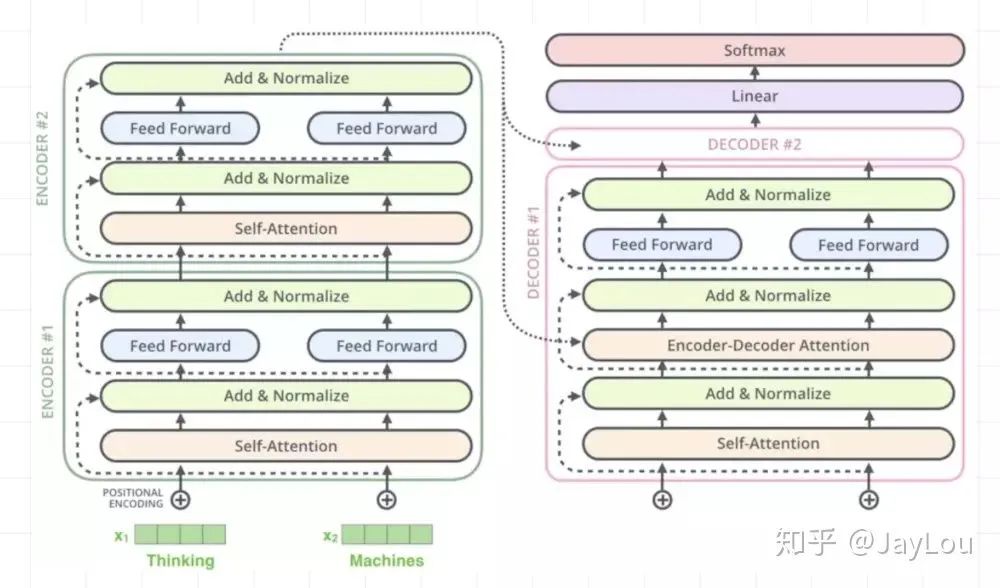
-
sub-layer-1: Masked multi-head self-attention mechanism, used for self-attention; different from the Encoder: since it is a sequence generation process, at time i, results from times greater than i are not available, so only results from times less than i are available, thus requiring a Mask.
-
sub-layer-2: Position-wise Feed-forward Networks, same as Encoder.
-
sub-layer-3: Encoder-Decoder attention calculation.
2. What are the differences between Transformer Encoder and Transformer Decoder?
(1) The multi-head self-attention mechanism differs; masking is not needed in the Encoder, while it is needed in the Decoder;
(2) The Decoder has an additional layer for Encoder-Decoder attention, which differs from the self-attention mechanism.
3. What are the differences between Encoder-Decoder attention and self-attention mechanism?
Both use multi-head calculations, but Encoder-Decoder attention adopts the traditional attention mechanism where the Query comes from the encoding value computed from the self-attention mechanism at the previous time step i, while both Key and Value are outputs from the Encoder, differing from the self-attention mechanism. This is specifically reflected in the code:
## Multihead Attention ( self-attention)
self.dec = multihead_attention(queries=self.dec,
keys=self.dec,
num_units=hp.hidden_units,
num_heads=hp.num_heads,
dropout_rate=hp.dropout_rate,
is_training=is_training,
causality=True,
scope="self_attention")
## Multihead Attention ( Encoder-Decoder attention)
self.dec = multihead_attention(queries=self.dec,
keys=self.enc,
num_units=hp.hidden_units,
num_heads=hp.num_heads,
dropout_rate=hp.dropout_rate,
is_training=is_training,
causality=False,
scope="vanilla_attention")4. What is the specific computational process of the multi-head self-attention mechanism?
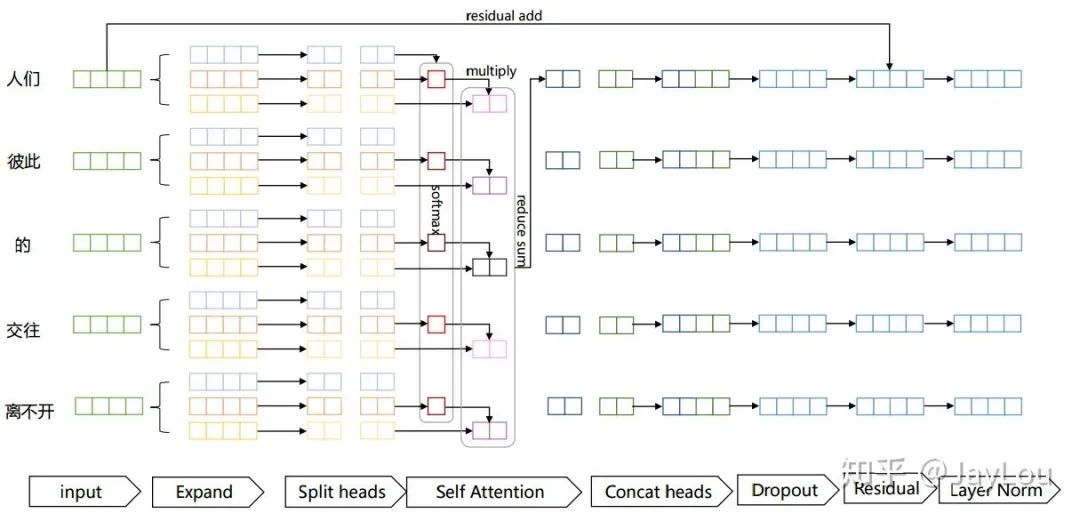
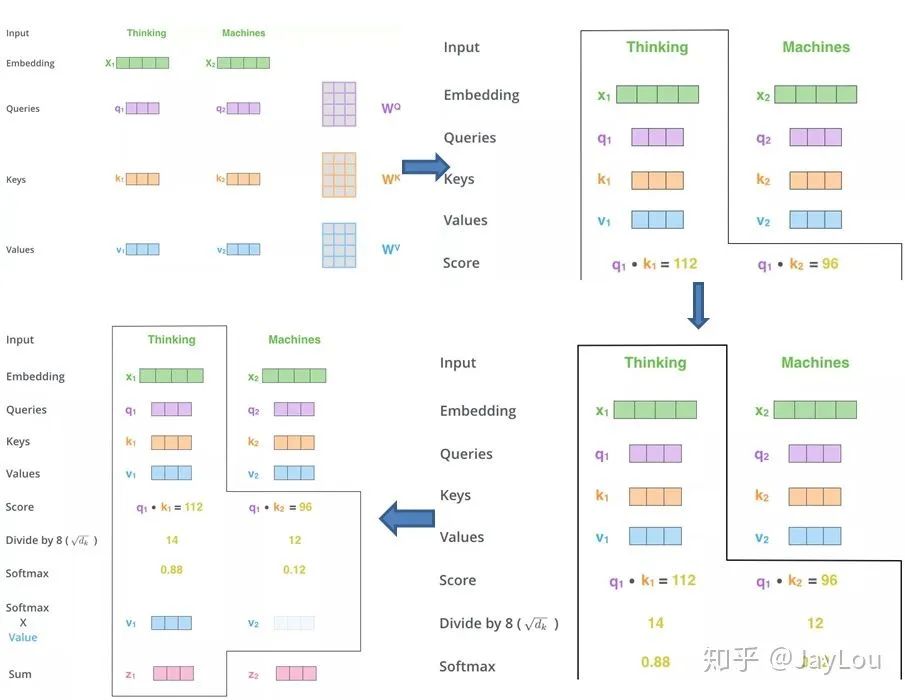
The Attention mechanism in Transformer consists of Scaled Dot-Product Attention and Multi-Head Attention, as shown in the figure above. Below is a detailed introduction to each step:
-
Expand: This is actually a linear transformation that generates the Q, K, V vectors; -
Split heads: perform head splitting; in the original paper, each position of 512 dimensions is split into 8 heads, with each head dimension becoming 64; -
Self Attention: perform Self Attention on each head, the specific process is consistent with what was introduced in the first part; -
Concat heads: concatenate each head after performing Self Attention;
The formula for the above process is:

5. How is Transformer applied in pre-trained models like GPT and BERT? What changes are there?
-
In GPT, a unidirectional language model is trained, which directly applies Transformer Decoder;
-
In BERT, a bidirectional language model is trained, which applies the Transformer Encoder part, but also performs Masked operations on top of the Encoder;
BERT Transformer uses bidirectional self-attention, while GPT Transformer uses restricted self-attention, where each token can only process its left context. Bidirectional Transformer is usually referred to as “Transformer encoder”, while left context is referred to as “Transformer decoder”, where the decoder cannot access the information to be predicted.
Reference
“Neural Networks and Deep Learning”
https://nndl.github.io/
Attention Is All You Need
Google BERT Analysis – Get Started with the Strongest NLP Training Model in 2 Hours
Detailed Explanation | Attention Is All You Need
Attention Models in Deep Learning (2017 Edition)
https://zhuanlan.zhihu.com/p/37601161
Heavy! The YiZhen NLP Academic WeChat Group has been established.
You can scan the QR code below, and the assistant will invite you to join the group for communication.
Note: Please modify your remarks when adding, such as [School/Company + Name + Direction].
For example - Harbin Institute of Technology + Zhang San + Dialogue System.
The account owner and WeChat merchants should consciously avoid this. Thank you!
Recommended Reading:
PyTorch Cookbook (Collection of Common Code Snippets)
Easy to understand! Implementing Transformer using Excel and TF!
Multi-task Learning in Deep Learning - keras implementation