The Technological Foundation Behind DeepSeek: A Large-Scale Language Model Architecture Based on Mixture of Experts
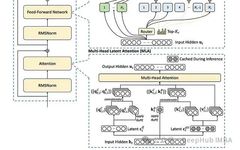
Source: Deephub Imba This article is about 1400 words long and is recommended to be read in 5 minutes. This article will delve into the architectural design, theoretical basis, and experimental performance of DeepSeekMoE from a technical perspective, exploring its application value in scenarios with limited computational resources. DeepSeekMoE is an innovative large-scale language model … Read more
