1. What is Mixture of Experts (MoE)?
In the field of deep learning, the improvement of model performance often relies on scaling up, but the demand for computational resources increases sharply. Maximizing model performance within a limited computational budget has become an important research direction. The Mixture of Experts (MoE) introduces sparse computation and dynamic routing mechanisms, providing an efficient solution. Compared to traditional dense models, MoE can significantly reduce computational resource consumption while achieving model scaling and performance enhancement.
1.1 Dense and Sparse Definitions
In neural networks, “dense” and “sparse” are terms used to describe parameter or activation patterns:
– In traditional neural networks, dense typically refers to each neuron in a layer being connected to all neurons in the previous layer, i.e., fully connected layers. This connection method is “dense” because each input affects all outputs, leading to a large number of parameters and significant computational overhead.
– In traditional Feedforward Networks (FFN), all inputs are processed through the entire network, and every neuron participates in computation, making this structure “dense”.
– Sparse means that only a portion of neurons or parameters are activated or used. In sparse MoE layers, sparsity is reflected in that only a subset of experts (i.e., a subset of neural networks) is activated and participates in computation during each forward pass, rather than all experts.
– This sparse activation strategy significantly reduces computational overhead, as only the activated experts need to be computed, rather than all experts. This mechanism allows the model to express complex patterns in a high-dimensional feature space while lowering computational costs.
Example: Restaurant Kitchen Work Mode
– Imagine a restaurant kitchen with only one chef responsible for preparing all dishes. Regardless of what customers order, the chef must handle every step of every dish personally. This means the chef’s workload is enormous, requiring knowledge of all dish preparation methods, leading to relatively low efficiency.
– This is akin to a traditional FFN where each input needs to be processed through the entire network, and all neurons participate in computation, resulting in high computational load and low efficiency.
– Now imagine another restaurant kitchen with multiple specialized chefs (experts), each adept at preparing a specific type of dish. For example, some chefs specialize in making pizza, others in sushi, and some in desserts. When customers place orders, the system automatically assigns tasks based on dish type, activating only the relevant chefs while others remain inactive.
– This is similar to the sparse MoE layer where only a subset of experts (neural networks) is activated and participates in computation, while other experts are in a “resting” state. This clear division of labor greatly reduces workload while enhancing efficiency.
– The dense mode is like a chef handling all tasks, low efficiency but comprehensive.
– The sparse mode is like multiple specialized chefs collaborating, high efficiency and specialization.
So, what exactly is the Mixture of Experts (MoE)? In simple terms, it is a model based on the Transformer architecture, primarily consisting of two core components:
2. SparseMoE Layer:
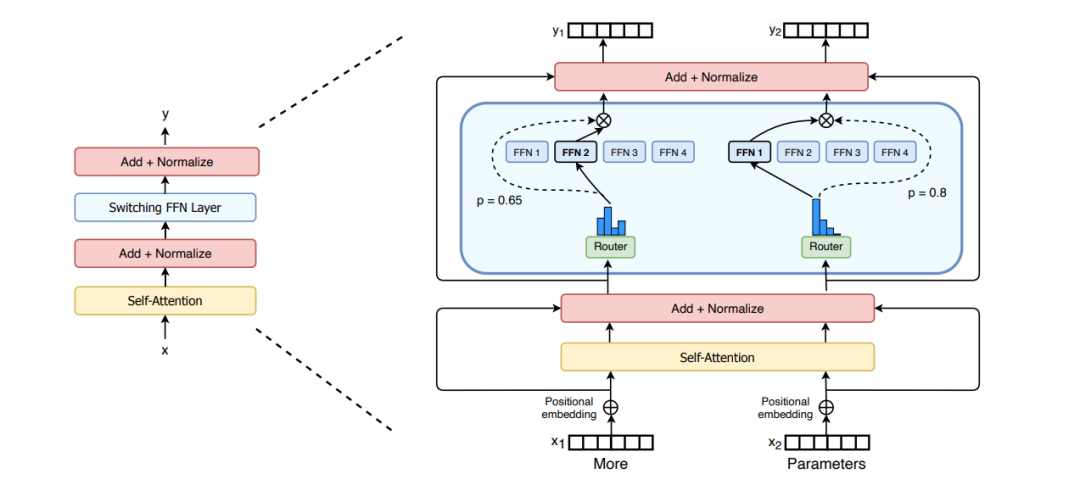
The sparse MoE layer is the core component of the Mixture of Experts model, typically used to replace the feedforward network (FFN) layers in traditional Transformers. These layers consist of multiple “experts,” each essentially an independent neural network. In typical implementations, these experts are simple feedforward networks, but they can also adopt more complex structures or even nested MoE layers, forming a multi-level expert system based on actual needs. Notably, each expert’s FFN structure is simpler than traditional FFNs since a single expert only needs to handle specific types of inputs, while traditional FFNs must handle all cases. This specialization allows each expert to use fewer parameters to accomplish its specific tasks. The MoE layer operates based on a sparse activation strategy: during each forward pass, only a subset of experts is activated and participates in computation. This mechanism significantly reduces computational overhead while retaining the model’s ability to express complex patterns in high-dimensional feature space.
– Structural Characteristics:
– Contains multipleFFN expert networks (as shown in the figure, each group has4 FFN experts)
– Each expert is an independent feedforward neural network
– Uses a sparse activation mechanism, where eachtoken activates only a few experts
– Sparsity reflects:
– Not all experts will be used simultaneously
– Eachtoken will route to the most relevant expert
– Two groups of expert systems are shown in the figure, each group has4 FFN experts (FFN 1-4)
– Experts are independent of each other and can compute in parallel
3. Gating Network / Routing Mechanism (Router):
The gating network (or routing mechanism) is responsible for dynamically assigning inputtokens to specific experts. The goal of this mechanism is to select the experts best suited to handle the input features. For example, in the above figure, the token “More” might be routed to the second expert, while “Parameters” could be assigned to the second expert. In some cases, a token could even be assigned to multiple experts to improve robustness.
The routing mechanism relies on a router driven by parameterized learning. This router is typically a small neural network or logic module whose output is a set of probabilities or allocation weights that guide the token distribution process. The router’s parameters are optimized alongside the main model, allowing it to dynamically adapt to data distributions and task requirements during various training phases.
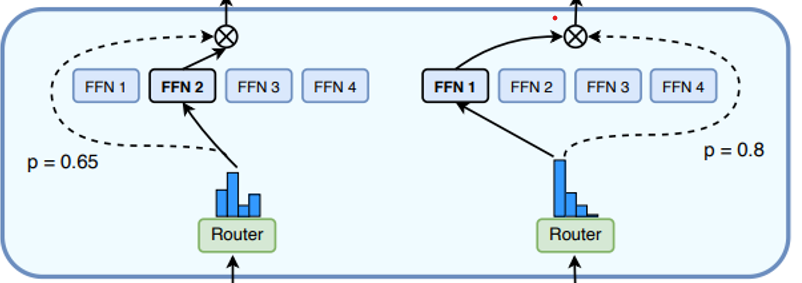
1. As shown in the figure, the complete workflow of the gating network/routing mechanism:
– First, compute the routing probabilities p (e.g., 0.65 and 0.8) to select FFN experts
– Then generate a gating value (represented by a dashed line in the figure)
– This gating value is multiplied by the output of the selected FFN expert
2. Role of the Gating Value:
– Used to adjust the strength of the FFN expert’s output
– Can be seen as a weighting factor for the expert’s output
– The gating mechanism can achieve smoother outputs
3. Overall Workflow of the Gating Network/Routing Mechanism:
Final Output = Output of Selected FFN Expert × Gating Value (value represented by a dashed line)
This dual mechanism (routing probability + gating value) enables the model to select appropriate experts while flexibly controlling the impact of expert outputs.
3. Complete Workflow of the MoE Layer:
Input Token → Router Evaluation → Expert Selection → Expert Processing → Gating Weighting → Output
Example (just a rough example):
Assume we have an MoE model for sentiment analysis with three experts:
– Expert 1: Specializes in processing positive sentiment text
– Expert 2: Specializes in processing negative sentiment text
– Expert 3: Specializes in processing neutral sentiment text
– Input Text: “The plot of this movie is complex, but the actors’ performances are outstanding.”
The input text is first tokenized and converted into a model-processable token representation. Assuming we use a simple tokenizer to split the text by words:
– Tokenization Result: [“This”, “movie”, “plot”, “is”, “complex”, “,”, “but”, “the”, “actors”, “performance”, “is”, “outstanding”, “.”]
Then, these tokens are converted into vector representations that the model can process (e.g., through an embedding layer):
– Token Vectors: [T1, T2, T3, T4, T5, T6, T7, T8, T9, T10, T11, T12, T13, T14, T15]
The router evaluates the features of each token, generating a probability distribution indicating the likelihood of each expert being selected. For example:
– Expert 1 (positive sentiment): 0.6
– Expert 2 (negative sentiment): 0.2
– Expert 3 (neutral sentiment): 0.2
– Expert 1 (positive sentiment): 0.1
– Expert 2 (negative sentiment): 0.7
– Expert 3 (neutral sentiment): 0.2
– For Token “outstanding”:
– Expert 1 (positive sentiment): 0.8
– Expert 2 (negative sentiment): 0.1
– Expert 3 (neutral sentiment): 0.1
Assuming we choose the Top-1 expert (i.e., each token selects only one expert):
– For Token “movie”, select Expert 1 (positive sentiment).
– For Token “complex”, select Expert 2 (negative sentiment).
– For Token “outstanding”, select Expert 1 (positive sentiment).
Each selected expert processes the corresponding token and outputs a sentiment score:
– Expert 1 (positive sentiment) processes Token “movie”: Output = 0.7
– Expert 2 (negative sentiment) processes Token “complex”: Output = 0.6
– Expert 1 (positive sentiment) processes Token “outstanding”: Output = 0.9
The router’s output (expert weights) is combined with the expert’s outputs for a weighted sum:
– Expert 1 weight = 0.6, output = 0.7 → Contribution = 0.6 * 0.7 = 0.42
– Expert 2 weight = 0.7, output = 0.6 → Contribution = 0.7 * 0.6 = 0.42
– For Token “outstanding”:
– Expert 1 weight = 0.8, output = 0.9 → Contribution = 0.8 * 0.9 = 0.72
The final output is an aggregation of the contribution values for all tokens (e.g., averaging):
– Final Output: (0.42 + 0.42 + 0.72) / 3 = 0.52
The final output is a sentiment score representing the input text’s sentiment tendency. For example:
– Output: Sentiment Score = 0.52
Based on a set threshold (e.g., 0.5 for neutral), the model can determine that the input text’s sentiment tendency is neutral to slightly positive.
2. DeepSeekMoE: The Core Architecture of DeepSeek-V3
Having understood the basic principles and mechanisms of MoE, let’s delve into the specific implementation in DeepSeek-V3—DeepSeekMoE. As one of the core architectures of DeepSeek-V3, DeepSeekMoE plays a crucial role in efficient training and inference. By introducing the sparse computational mechanism of the Mixture of Experts (MoE), DeepSeekMoE significantly reduces computational overhead while maintaining robust performance. Compared to traditional MoE architectures, DeepSeekMoE has made several innovations in expert partitioning, load balancing, and routing mechanisms, making the model more efficient and stable during training and inference. Specifically, DeepSeekMoE not only inherits the advantages of the MoE architecture but also achieves a better balance between efficiency and performance through efficient design. In DeepSeek-V3, except for the first three layers retaining the traditional FFN structure, all other FFN layers are replaced with DeepSeekMoE layers, resulting in a massive network structure with a total parameter count of 671B, where each token activates 37B parameters. This innovative design allows DeepSeekMoE to excel in handling complex tasks, greatly enhancing computational efficiency and task processing capability.
1. Basic Architecture of DeepSeekMoE
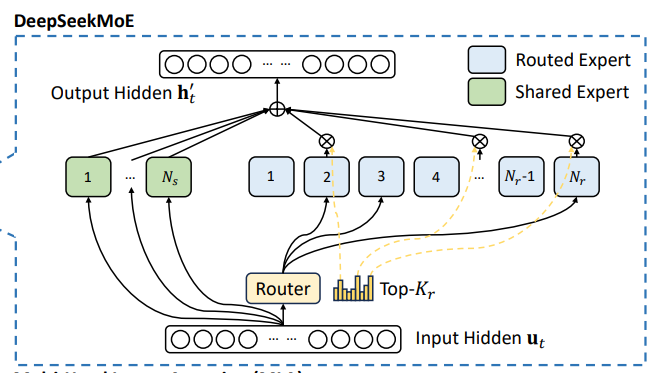
The basic architecture of DeepSeekMoE is built on the Transformer framework, introducing the innovative MoE mechanism in the feedforward network (FFN) layer. Unlike traditional MoE that uses coarse-grained expert partitioning, DeepSeekMoE adopts a finer-grained expert partitioning approach, allowing each expert to handle more specific tasks, thereby enhancing the model’s flexibility and expressiveness. Specifically, each MoE layer in DeepSeekMoE consists of 1 shared expert and 256 routing experts, with each token activating 8 routing experts. This design enables the model to significantly reduce computational resource consumption while maintaining high performance.
In the design of the expert mechanism, DeepSeekMoE has also made innovations:
-
Shared Experts and Routing Experts: Unlike traditional MoE where experts are independently designed, DeepSeekMoE introduces the concept of shared experts. Shared experts are responsible for handling general features of all tokens, while routing experts dynamically allocate based on specific features of the tokens. This division not only reduces redundancy in the model and improves computational efficiency but also allows the model to better handle tasks across different domains.
-
Sparse Activation Mechanism: Unlike traditional dense models, DeepSeekMoE adopts a sparse activation mechanism, where each token activates only a few experts. This mechanism not only reduces computational overhead but also enables the model to flexibly handle different types of inputs, especially in scenarios requiring highly specialized knowledge.
Example: Assume the model is processing a piece of mathematical reasoning text: “To solve this quadratic equation, we first need to calculate the discriminant and then use the root formula.” In traditional MoE, the entire mathematical content might be handled by a single “math expert.” In DeepSeekMoE:
Shared experts handle the basic grammatical structure and general language features of the sentence
Different routing experts specialize in handling:
-
Features related to equation recognition
-
Features related to discriminant calculation
-
Features related to root formula
This fine-grained expert partitioning and the combination of shared expert mechanisms enable the model to handle specialized tasks more accurately while maintaining computational efficiency.
2. Dynamic Load Balancing: No Auxiliary Loss Strategy
In traditional MoE models, load balancing is a key issue. Since each token activates only a few experts, some experts may become overloaded by processing too many tokens, while others may become underutilized. This imbalance can lead to wasted computational resources and may even cause routing failures, where all tokens are routed to a few experts, preventing others from functioning. Traditional MoE often uses auxiliary loss to encourage load balancing, but this strategy may negatively impact model performance. DeepSeekMoE proposes a no auxiliary loss load balancing strategy that dynamically adjusts the bias terms of each expert to achieve load balancing.
The no auxiliary loss strategy means that during training, there is no need to introduce an additional loss function to enforce load balancing; instead, it achieves load balancing naturally by dynamically adjusting the bias terms of the experts.
– Dynamic Bias Adjustment: During training, DeepSeekMoE monitors the load conditions of each expert. If an expert becomes overloaded, the system will automatically lower its bias term, reducing the activation frequency of that expert; conversely, if an expert is underloaded, the system will increase its bias term, making it easier to activate.
– Advantages of No Auxiliary Loss: Compared to traditional auxiliary loss, the no auxiliary loss load balancing strategy does not negatively impact model performance while effectively avoiding routing failure.
Example: Assume during training, a certain expert becomes overloaded due to processing too many tokens; DeepSeekMoE will automatically lower that expert’s bias term, allowing other experts to share some of the load. This dynamic adjustment ensures load balancing for each expert, thereby improving the training efficiency of the model.
3. Sequence-Level Load Balancing: Preventing Extreme Imbalance
In MoE models, load balancing can be controlled at different granularities. In addition to global load balancing (i.e., the expert allocation situation for the entire dataset) and local load balancing (i.e., the expert allocation situation for a single batch or node), DeepSeekMoE also introduces sequence-level load balancing as one of its innovative designs. Sequence-level load balancing specifically optimizes the allocation of tokens within a single input sequence to prevent tokens from being overly concentrated on a few experts, thus avoiding extreme imbalance. This fine-grained balancing strategy complements global and local load balancing, ensuring that even within a single sequence, the load among experts remains relatively balanced. These different levels of load balancing strategies work together to ensure that the model operates efficiently across different granularities.
– Sequence-Level Balance Loss: This loss function encourages load balancing among experts within each sequence, preventing tokens in certain sequences from being overly concentrated on a few experts.
– Minimal Balance Factor: DeepSeekMoE sets a minimal balance factor for the sequence-level balance loss to ensure that it does not significantly impact model performance during overall training.
Example: Assume in a sequence, a certain token is overly assigned to a specific expert, leading to that expert becoming overloaded. The sequence-level balance loss will adjust the routing mechanism so that other tokens in that sequence can be more evenly distributed to other experts, thus avoiding load imbalance.
4. Node-Limited Routing: Optimizing Cross-Node Communication
In distributed training environments, cross-node communication costs can be high, especially in expert parallelism. To reduce communication overhead during training, DeepSeekMoE adopts a node-limited routing mechanism. Each token is sent to a maximum of 4 nodes, which are selected based on the affinity scores of experts on each node.
– Advantages of Node Limitation: By limiting the number of routing nodes for each token, DeepSeekMoE can significantly reduce cross-node communication overhead, thus improving training efficiency.
– Overlapping Communication and Computation: DeepSeekMoE’s routing mechanism ensures that communication and computation overlap, making the communication overhead almost negligible as the model scales further.
Example: Assume in a distributed training environment, a token needs to be assigned to multiple experts for processing. DeepSeekMoE’s routing mechanism will prioritize selecting experts with the highest affinity on the current node, thereby reducing cross-node communication overhead.
5. No Token Dropping: Ensuring Inference Load Balancing
In traditional MoE models, load imbalance may lead to certain tokens being dropped (experts have a processing capacity limit), affecting the model’s performance. DeepSeekMoE ensures that no tokens are dropped during training and inference through effective load balancing strategies.
– Load Balancing During Inference: During the inference phase, DeepSeekMoE ensures load balancing for each GPU through a redundant expert deployment strategy. Specifically, the system detects high-load experts and redundantly deploys them across different GPUs, thereby balancing the load on each GPU.
– Dynamic Redundancy Strategy: DeepSeekMoE also explores a dynamic redundancy strategy, which dynamically selects activated experts at each inference step to further optimize inference efficiency.
Example: Assume during inference, a certain expert becomes overloaded due to processing too many tokens; DeepSeekMoE will automatically transfer part of that expert’s load to redundant experts on other GPUs, ensuring a smooth inference process.
DeepSeekMoE, as the core architecture of DeepSeek-V3, achieves efficient training and inference through no auxiliary loss load balancing strategies, node-limited routing mechanisms, and FP8 training support. DeepSeekMoE not only demonstrates outstanding performance but also exhibits significant advantages in training costs and inference efficiency. By dynamically adjusting expert loads and optimizing routing mechanisms, DeepSeekMoE provides an efficient solution for training and deploying large-scale language models.