
Introduction This sharing focuses on the implementation path and development prospects of multimodal RAG.
The core topics cover five aspects:
1. Multimodal RAG based on semantic extraction
2. Multimodal RAG based on VLM
3. How to scale multimodal RAG based on VLM
4. Choice of technical routes
5. Q&A session
Speaker|Jin Hai Infiniflow Co-founder
Editor|Wang Hongyu
Proofreading|Li Yao
Produced by|DataFun
Multimodal RAG Based on Semantic Extraction
The development direction of multimodal RAG aims to build a highly integrated system that can seamlessly blend text, images, and other multimedia elements to provide users with a richer information interaction experience.
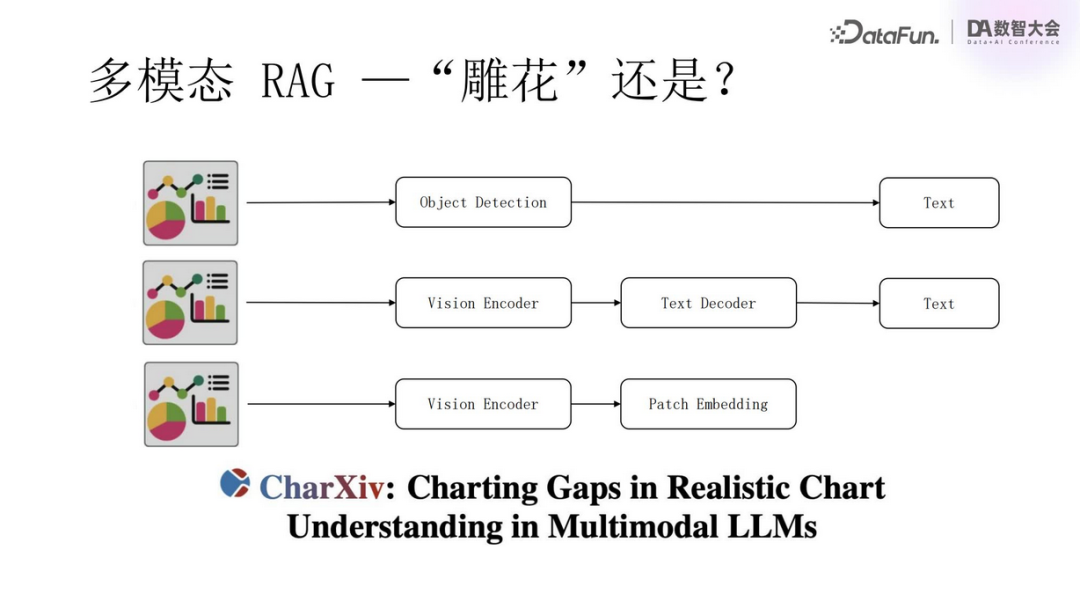
The three main technical paths to implement the multimodal RAG system are as follows:
-
Traditional object recognition and parsing (Carving route)
Traditional multimodal document processing first utilizes image recognition technologies, such as OCR (Optical Character Recognition), to extract text, tables, and images from the images. Afterward, these independent objects are further parsed and converted into text format for subsequent information retrieval and analysis.
-
Using Transformer architecture
In recent years, deep learning models, especially the Transformer architecture, have achieved great success in the field of natural language processing. In multimodal RAG, this method involves using an encoder to encode the entire document, followed by a decoder that converts the encoded information into readable text. This method is similar to the first one, except that the model differs; the first uses CNN while this one uses Transformer. The advantage of this method is its ability to better capture contextual dependencies, enhancing the coherence and consistency of information.
-
Using Visual Language Models
The third method directly utilizes visual language models (VLM) to process multimodal data. Such models can directly accept raw inputs in the form of documents, images, or videos and convert them into vectors (Patch Embedding). These vectors can be used to construct more refined document embeddings, enhancing the retrieval and generation capabilities of the RAG system. Notably, since a single vector may not fully reflect all aspects of a complex document, using multiple vectors (or tensors) has become the preferred solution to reduce information loss and more comprehensively represent the document’s meaning.
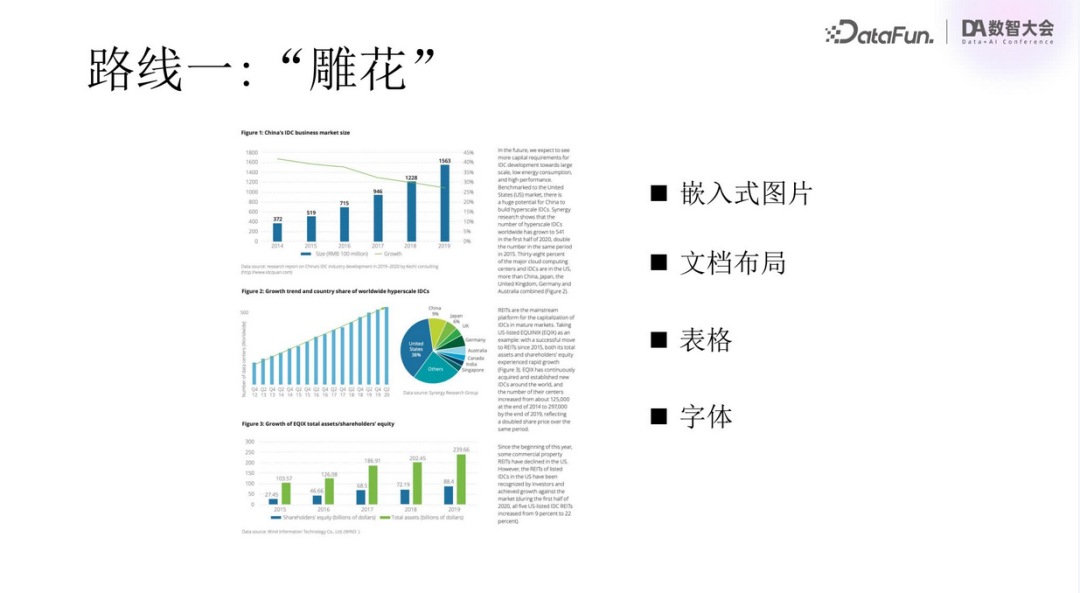
Next, let’s take a closer look at Route One, which we refer to as the “Carving” route.
As shown in the above image, documents typically contain rich graphics and tables, such as line charts, pie charts, and bar charts, and may even have complex situations like tables spanning pages and merged cells, making processing quite challenging.
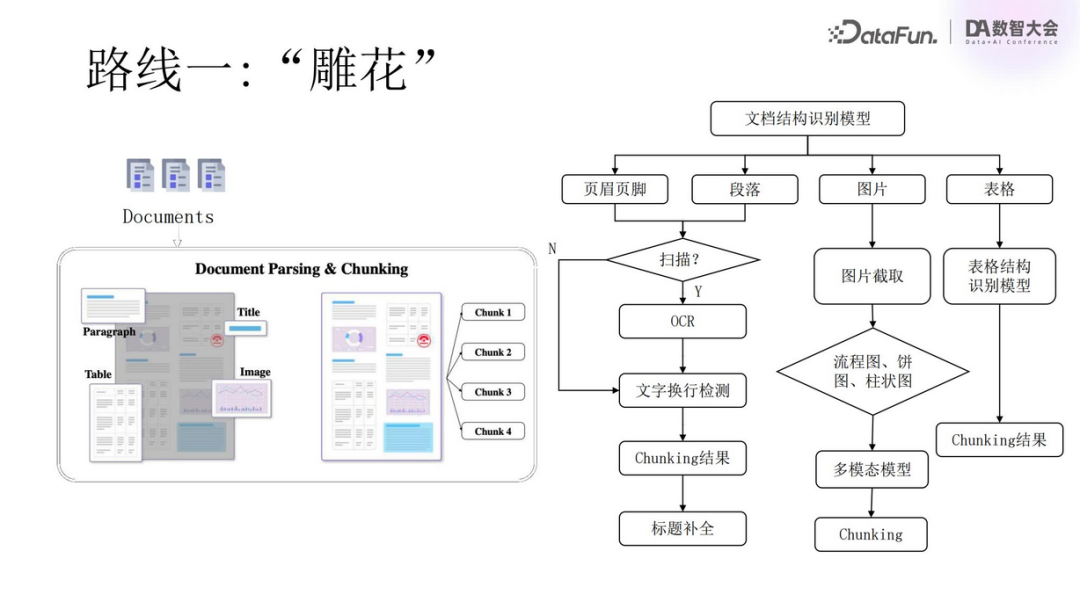
The core steps of this route are illustrated in the above image. First, document structure recognition is performed to distinguish the various components, clarifying which are paragraphs, which are tables, and which are charts, etc. Each identified object is further parsed; for text portions, OCR technology is used to transcribe the text; for charts, specialized models are required to recognize and parse them, understanding their content and significance.
The characteristic of the “Carving” route lies in its depth and breadth, covering almost every detail within the document. It is time-consuming and labor-intensive, but it plays an irreplaceable role in ensuring the comprehensiveness and accuracy of information. However, its processing efficiency is relatively low, and the degree of automation is limited, especially when facing large-scale datasets, where challenges become more pronounced.
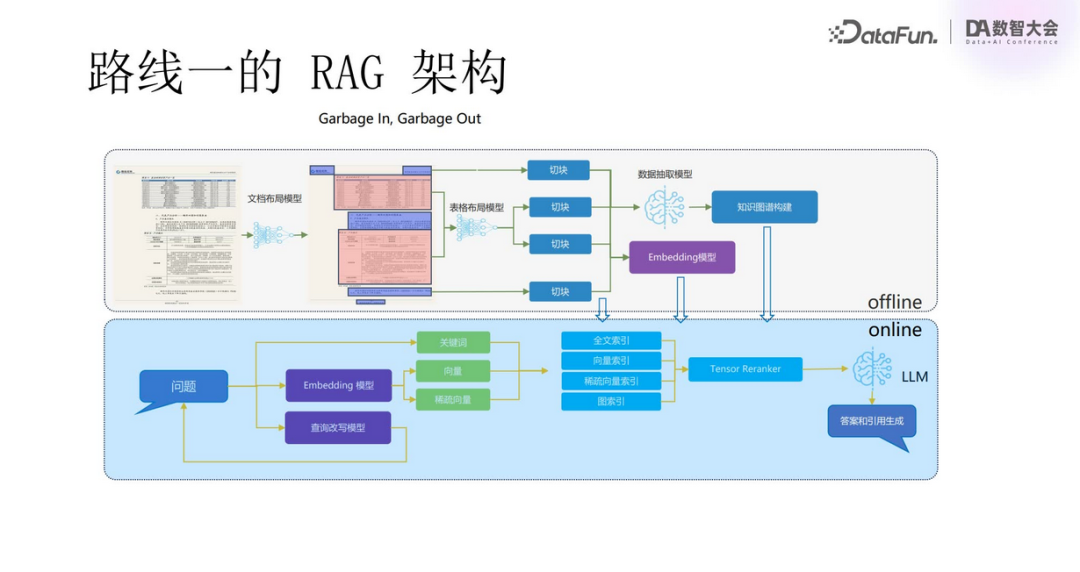
The RAG architecture of Route One is the most basic RAG: documents are segmented into chunks, each containing independently processable content segments, which are converted into vectors through embedding models for similarity retrieval in a vector database, with the retrieval results provided as prompts to the large model.
In practical application scenarios, the complexity increases, requiring deeper RAG architectures. After the document layout model identifies different layouts, it separates different types of chunks. Retrieval will involve full-text indexing, vector indexing, sparse vector indexing, and graph indexing, among others. After retrieval, Tensor Reranker is used for reordering to improve retrieval effectiveness. Finally, the large model is tasked with generating answers.
In this process, when faced with complex documents, without the “Carving” process, there would certainly be information chaos, leading to “Garbage in, garbage out.”
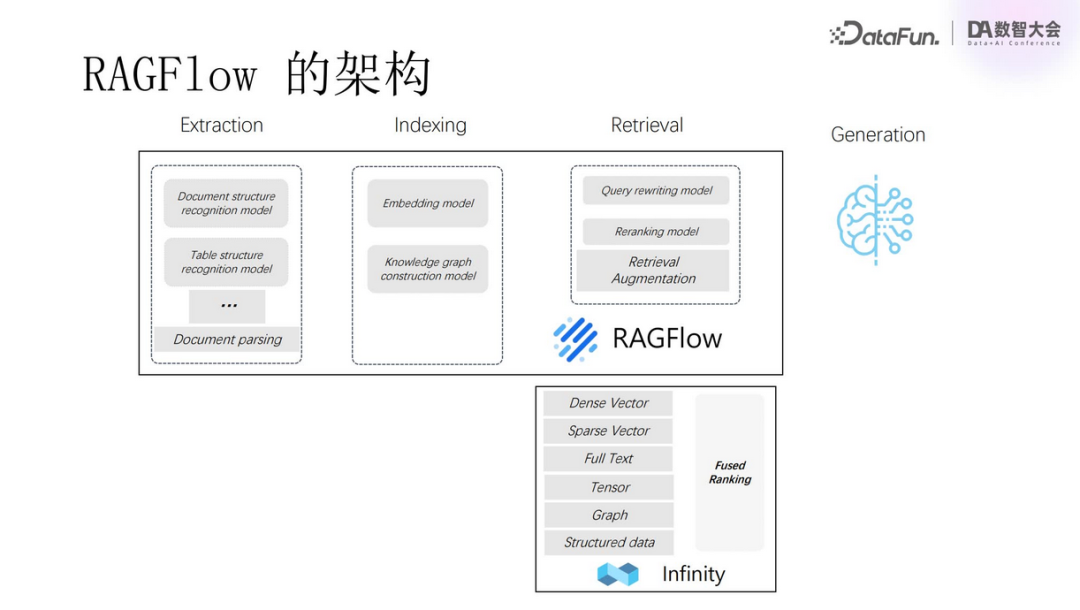
Based on the first route, we designed the functional modules of RAGFlow and provided vector processing through the Infinity database.
In the “Carving” process, table recognition is a significant challenge.
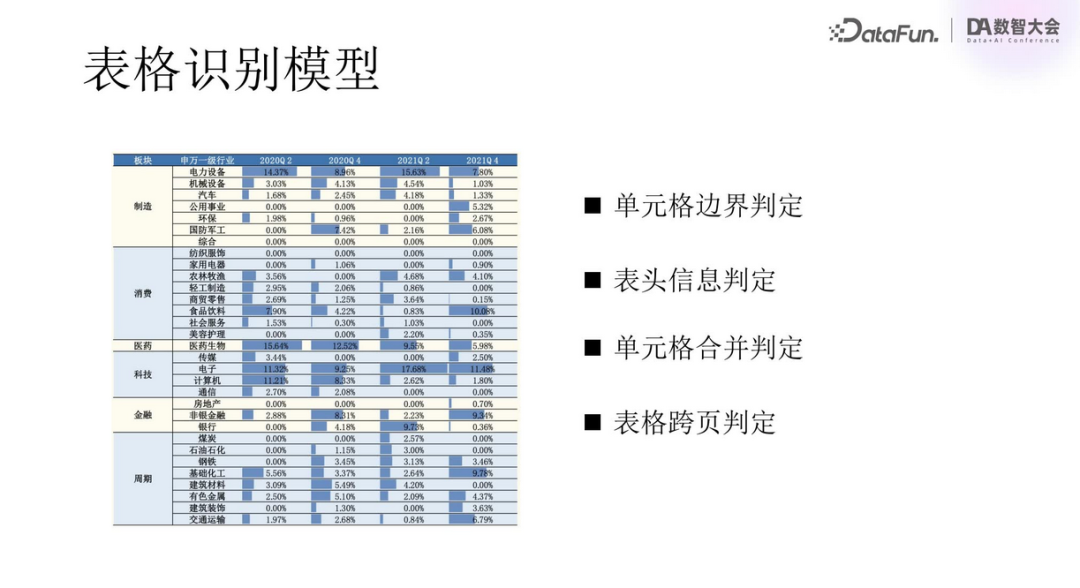
Tables often have complex layouts, requiring determination of cell boundaries, recognition of headers and merged cells, and assessment of cross-page structures, along with identification of color markings and embedded charts, making processing very difficult.
We have implemented the use of the Transformer architecture to parse table content.
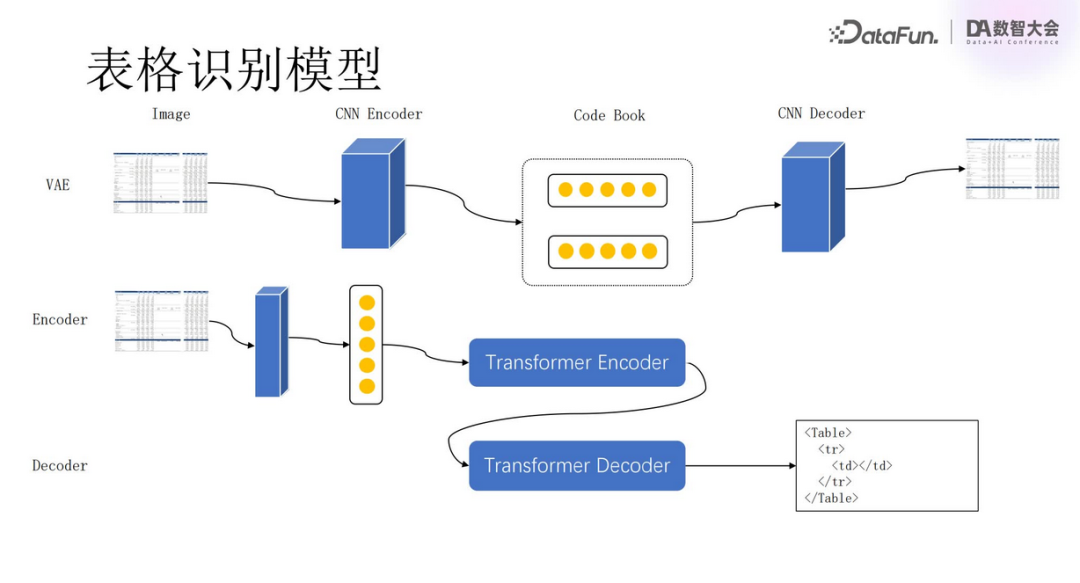
Using VAE (Variational Auto Encoder) to extract image features, an Encoder generates a Code Book, which is then processed by a Decoder to obtain the final result. If the results are consistent, it proves that the Code Book can accurately express the table structure and content. We then train the Encoder and Decoder, ultimately generating HTML tables. The generated tables are rigorously compared with the original tables, and once confirmed accurate, we consider the Transformer model to be precise and effective.
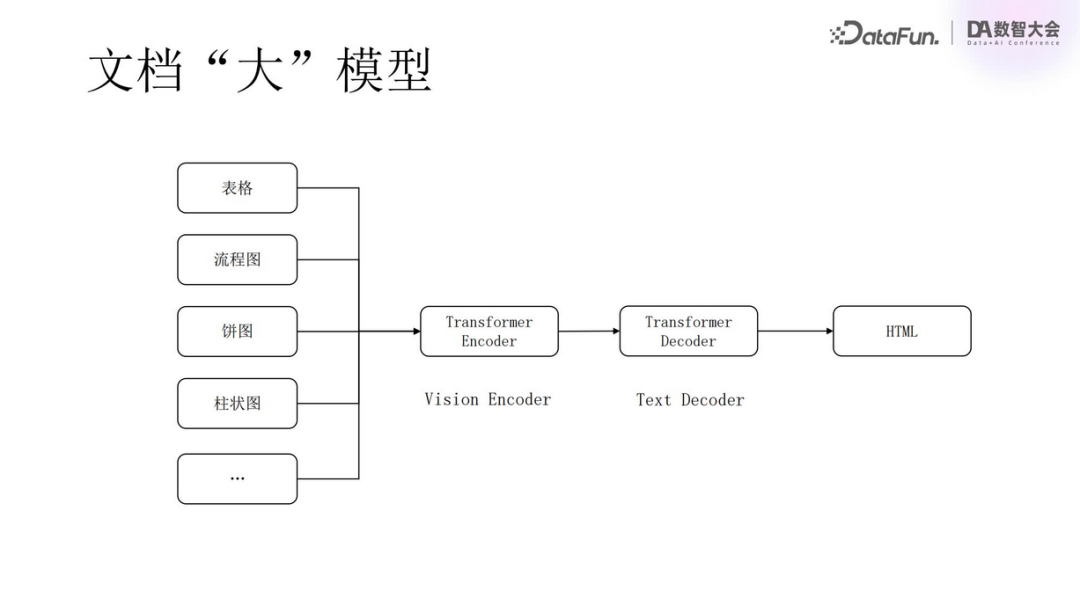
This process is not only applicable to table recognition but can also be used for parsing flowcharts, pie charts, bar charts, and other types of charts.
Multimodal RAG Based on VLM
Next, we introduce another route—multimodal RAG based on visual language models.
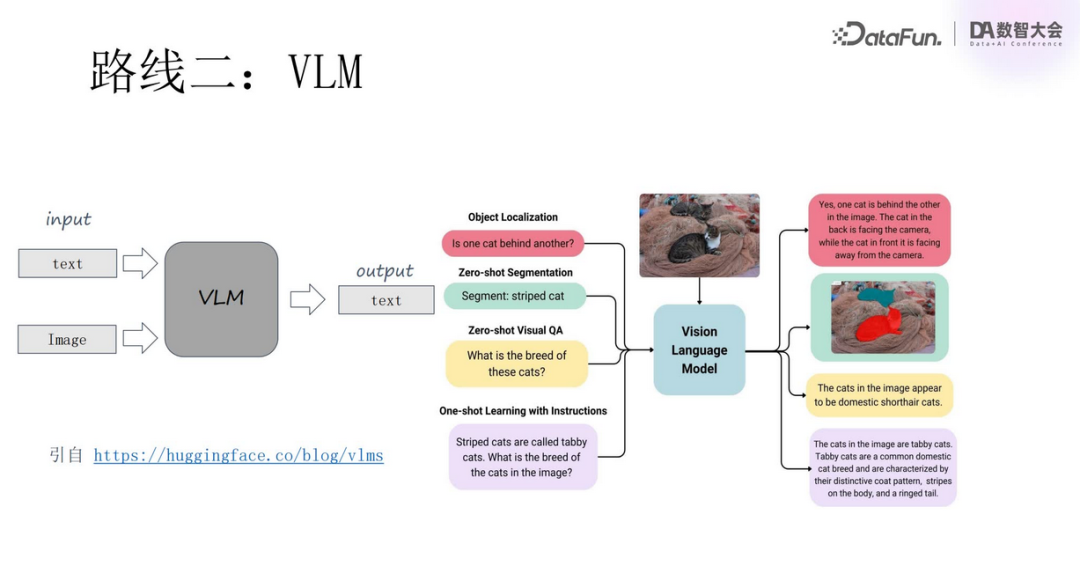
VLM can simultaneously process both image and text information, providing comprehensive analysis of composite media materials. As shown in the above image, the model can not only identify the position of the cat in the image and accurately locate its outline but can also answer questions about the content of the image, demonstrating its powerful multimodal cognitive ability. Let’s take a look at the progress of VLM.

The year 2024 witnessed the rapid rise of multimodal language models, with various open-source and closed-source models represented by GPT-4o, marking significant progress in the multimodal field. This year is the explosive year for multimodal models; will next year be the explosive year for multimodal RAG? Let’s look at some related examples.
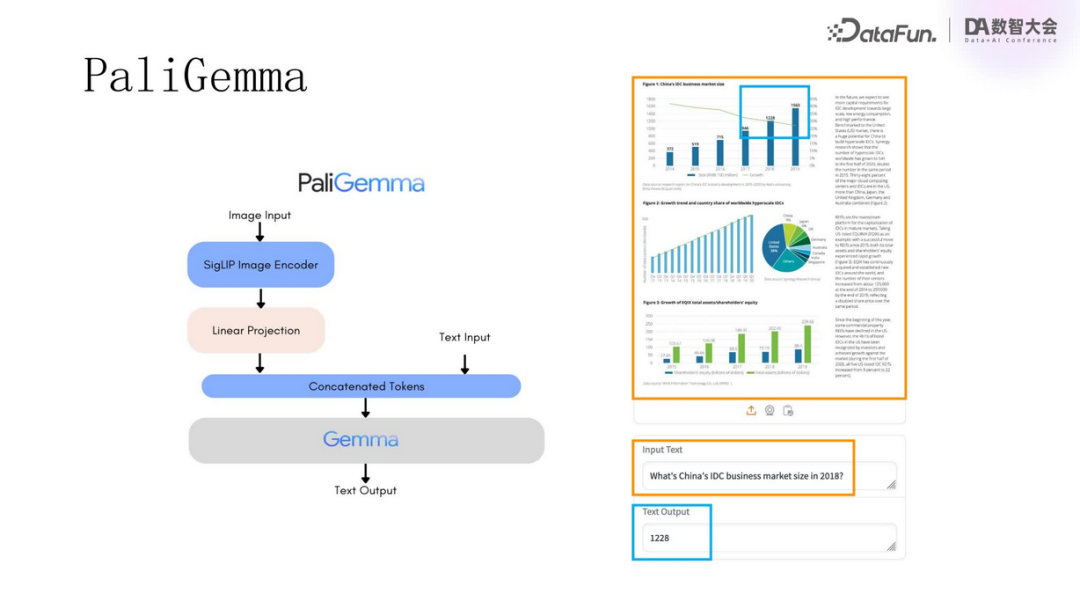
Using the PaliGemma model for Q&A on PDF documents, for example, asking about the market size of China IDC in 2018, the model directly provided the specific numbers from the bar chart, very accurately.
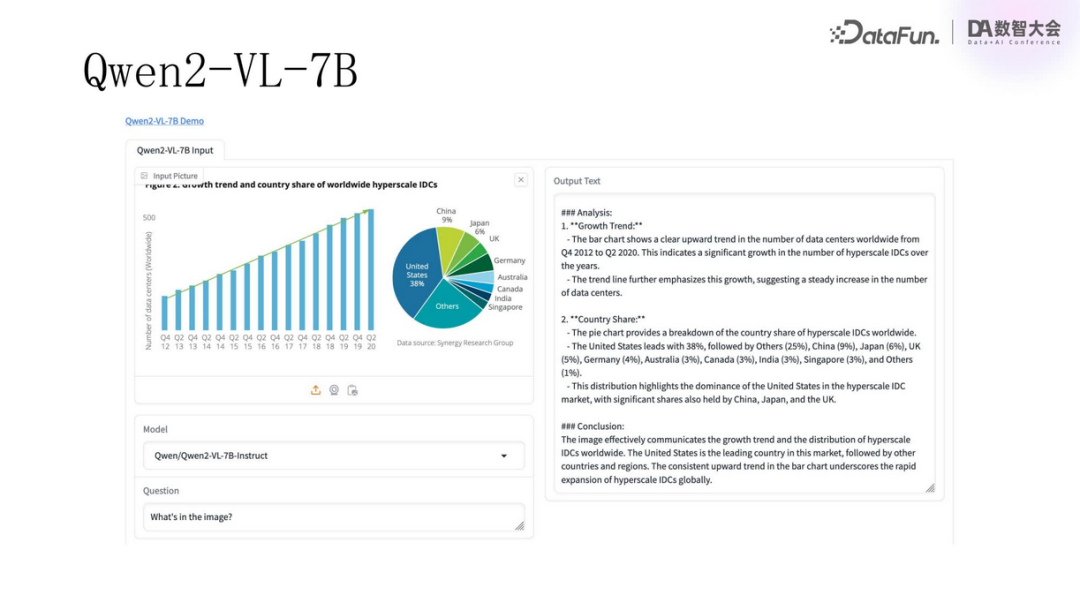
Similarly, when asking the Qwen2 model about the contents of a chart, the model also provided accurate and detailed analysis.
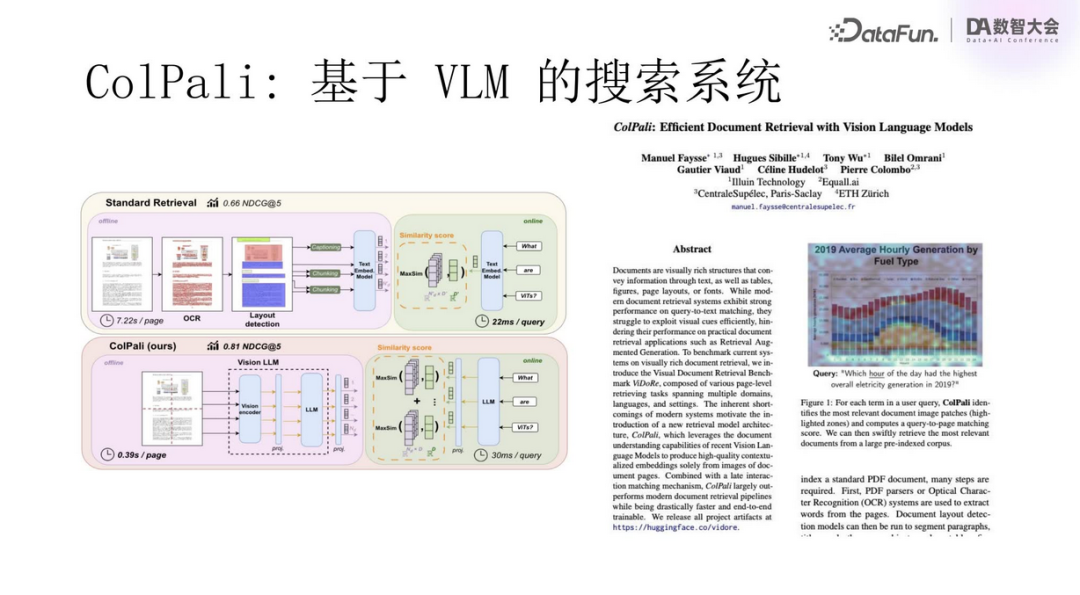
The above image shows a paper that implements multimodal search using VLM, which employs the ColPali method, or context-based delayed interaction. Its core idea is to convert multimodal documents into multidimensional vectors, then use similarity matching to allow large models to generate answers. This process is similar to modern RAG. The most important point is how multimodal information is expressed. Traditional search engines use full-text indexing, extracting keywords for retrieval, and then scoring using inverted indexing. In the AI era, text is expressed in vector form, significantly enhancing information processing efficiency.
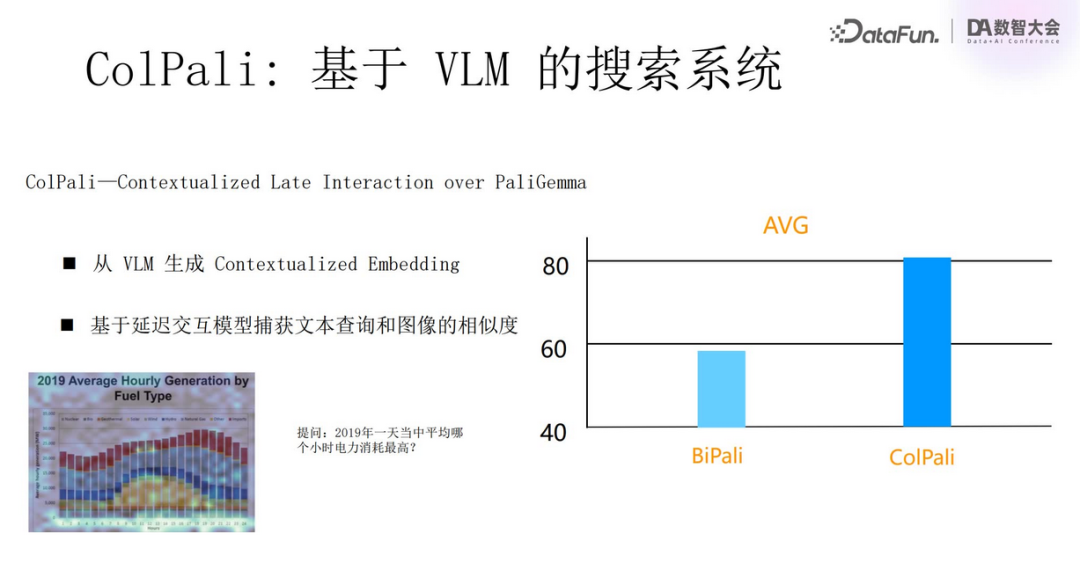
The evaluation standard for the ColPali system is nDCG (normalized discounted cumulative gain), showing a qualitative leap in accuracy compared to previous methods, reaching over 80%, significantly improved from previous results below 60%. Experiments have shown that the performance on specific datasets (such as MLDR) is also outstanding, achieving nearly 70% accuracy, fully proving the effectiveness of the technology.
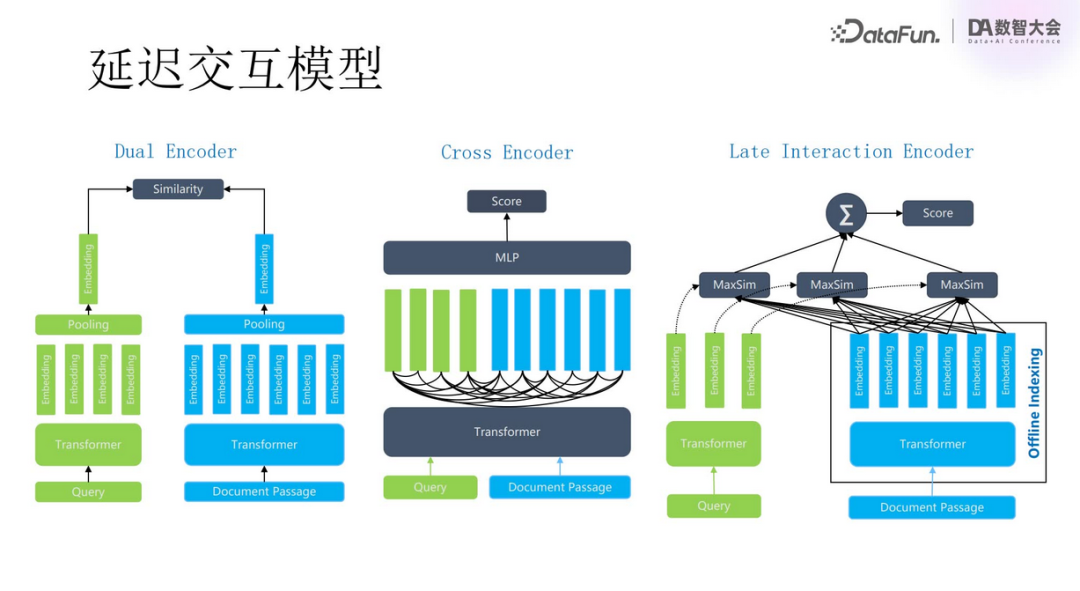
As mentioned earlier, ColPali employs context-based delayed interaction, which is one of the models on the far right in the above image. The first type, Dual Encoder, is a commonly used method for similarity matching using vector databases. Documents are converted into a series of vectors by the model, then aggregated and simplified into a single vector for quick querying and matching. The advantage of this method is its speed and efficiency. Its limitation is that it loses a lot of information and is difficult to precisely locate the relationship between documents and queries.
Thus, the Reranker was introduced, which is the second method shown in the image, Cross Encoder. After obtaining candidate chunks through initial screening, this method reorders them based on relevance, serving as prompts. The issue with this method is that it requires GPU operation and is limited by the number of documents.
Therefore, delayed interaction models emerged. Initially, documents are generated into multiple vectors (or tensors) for storage. When users query, the same is converted into tensor form, calculating the inner product MaxSim score, rather than relying on model computation. This can significantly reduce computational load, allowing for an increase in the number of candidate documents and ultimately improving recall rates.
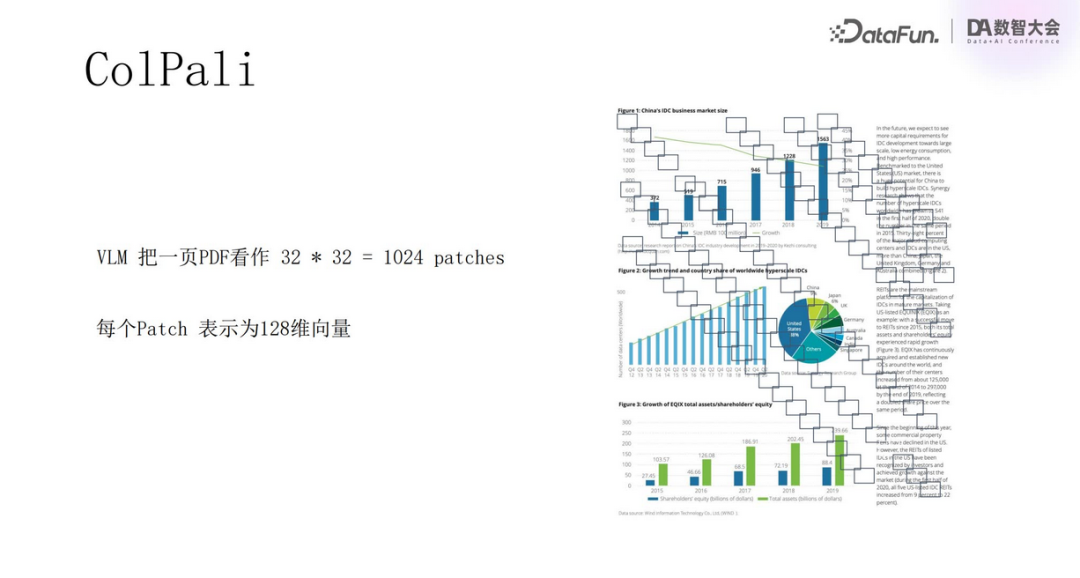
ColPali employs this method. It divides a PDF document into 1024 patches, with each patch represented by a 128-dimensional vector, thus transforming a PDF document into a tensor containing 1024 vectors.
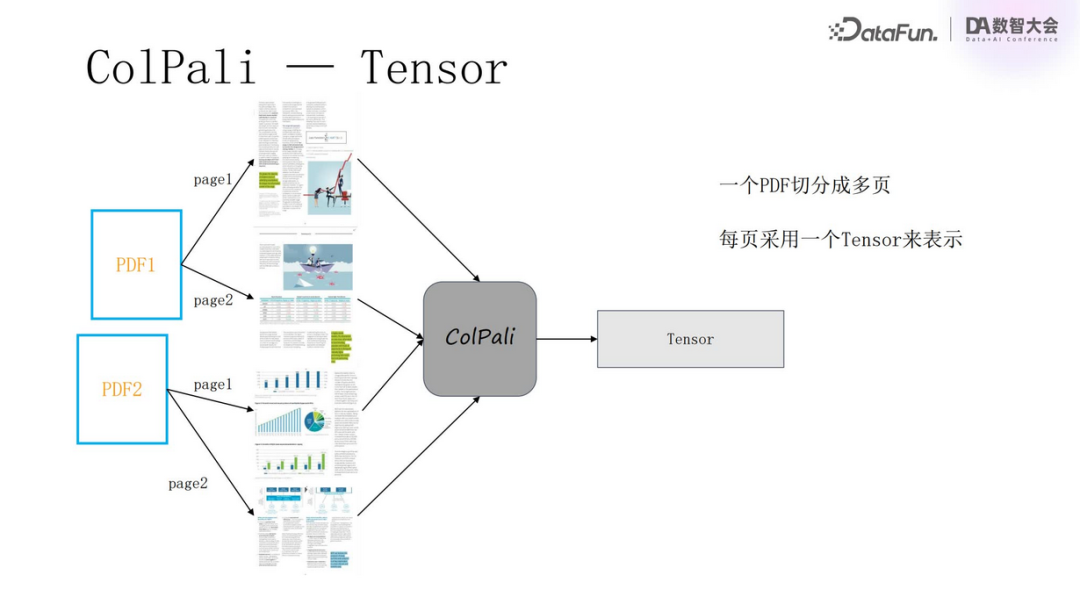
A PDF is divided into multiple pages, with each page represented by a tensor.
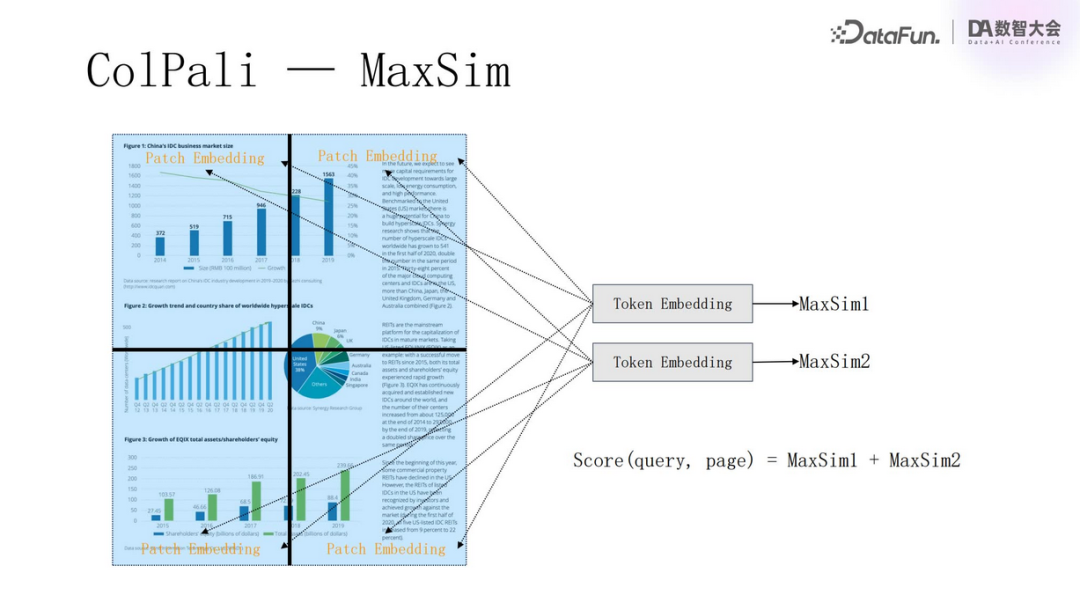
Calculating MaxSim scores.
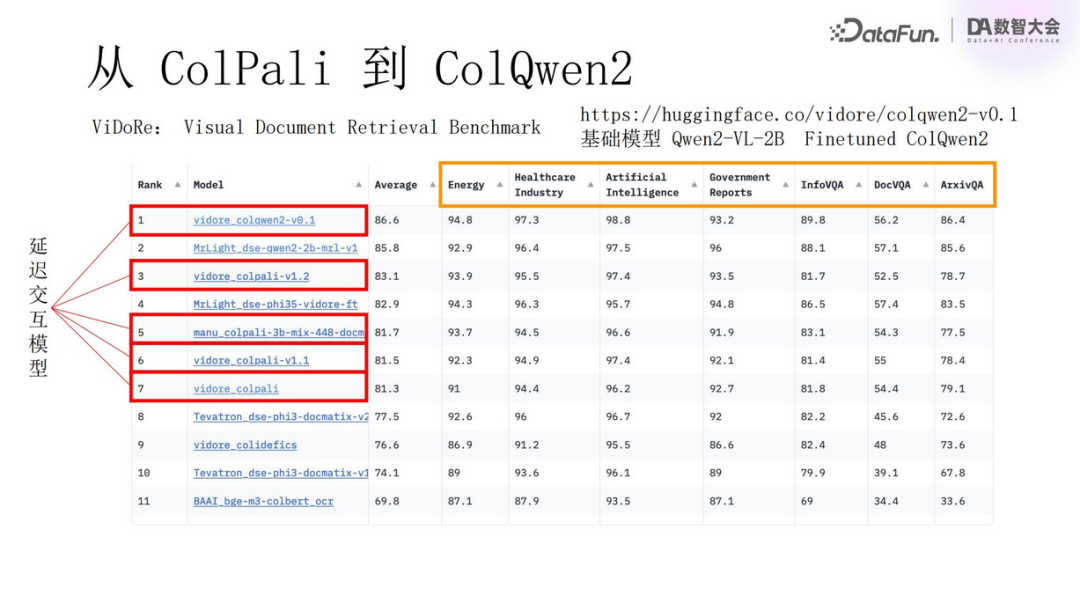
The above image lists the performance of several related models. They are all versions that include “Col” in their names, showing significant improvements compared to previous traditional versions.
How to Scale VLM-Based Multimodal RAG
Next, we explore how to apply VLM-based multimodal RAG.

The first challenge is the increase in data scale and the complexity of tensors. For example, as previously mentioned, using 1024 vectors to represent a document significantly raises both storage and computational complexity.
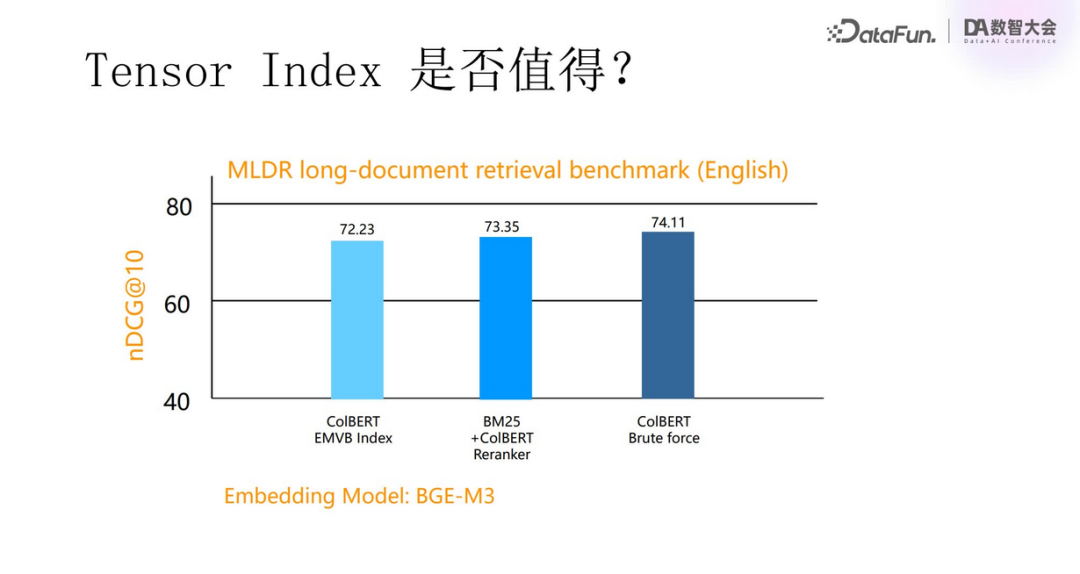
Is it still necessary to build indexes on top of tensors? The role of indexes in reducing computational scale is limited. Therefore, we adopt methods such as binarizing tensors to reduce data scale. We also found that using tensors for reordering and directly using tensors for first search ordering yield similar accuracy.
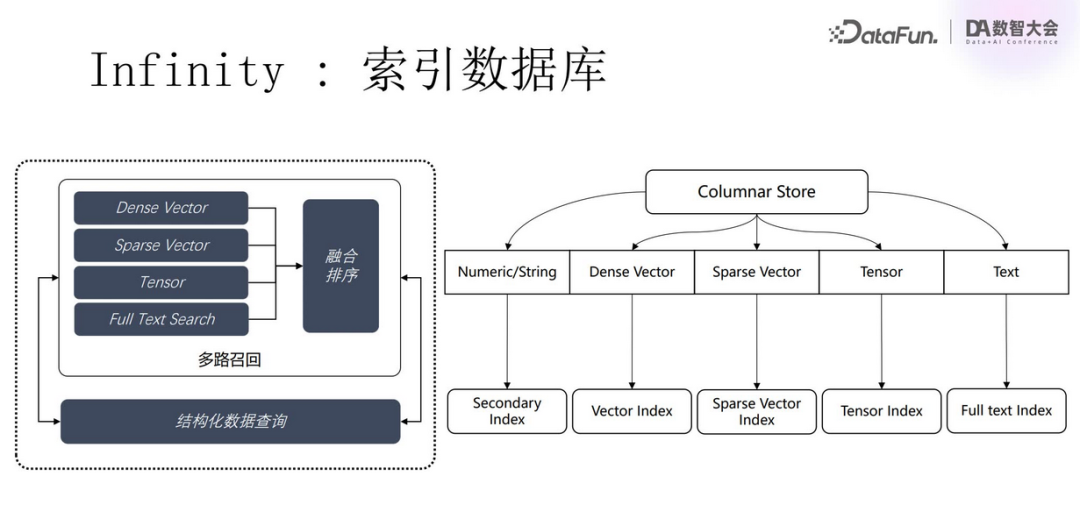
Thus, using the Infinity database, the first round of searches employs full-text search, dense vector search, and sparse vector search, with the results obtained from the search then reordered using Tensor Reranker.
The Infinity database has corresponding indexes for structured data, dense vectors, sparse vectors, tensors, and full-text searches, and can perform fusion searches.
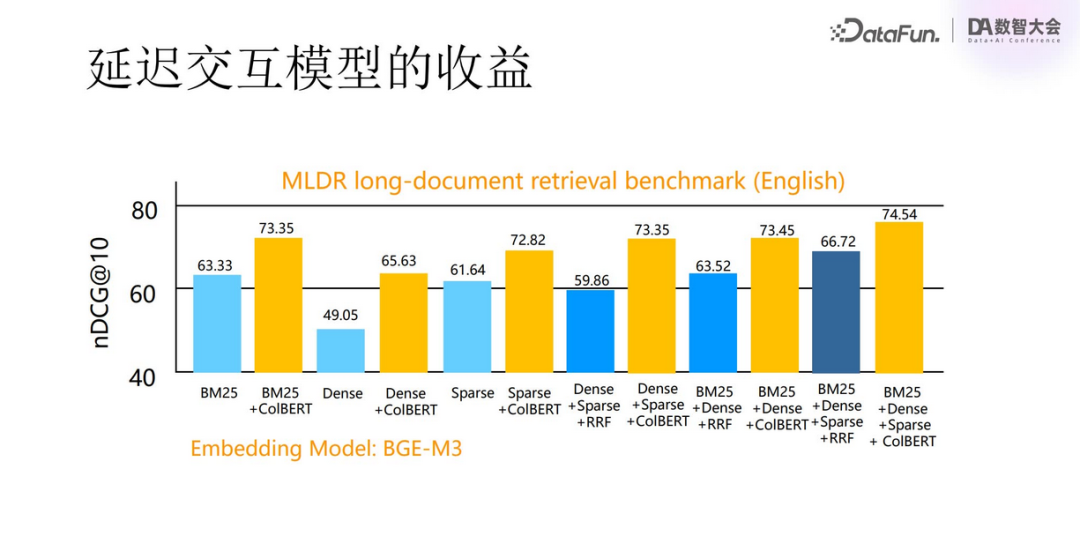
From the test results displayed in the above image, the blue part represents searches that did not use tensor methods, with BM25 being full-text search yielding better results, while the currently commonly used dense vector search yielded the worst results. We also paired and combined different search methods, finding that the more combinations and types, the higher the search accuracy. The yellow part represents searches that included tensor reordering, showing a significant improvement in accuracy.
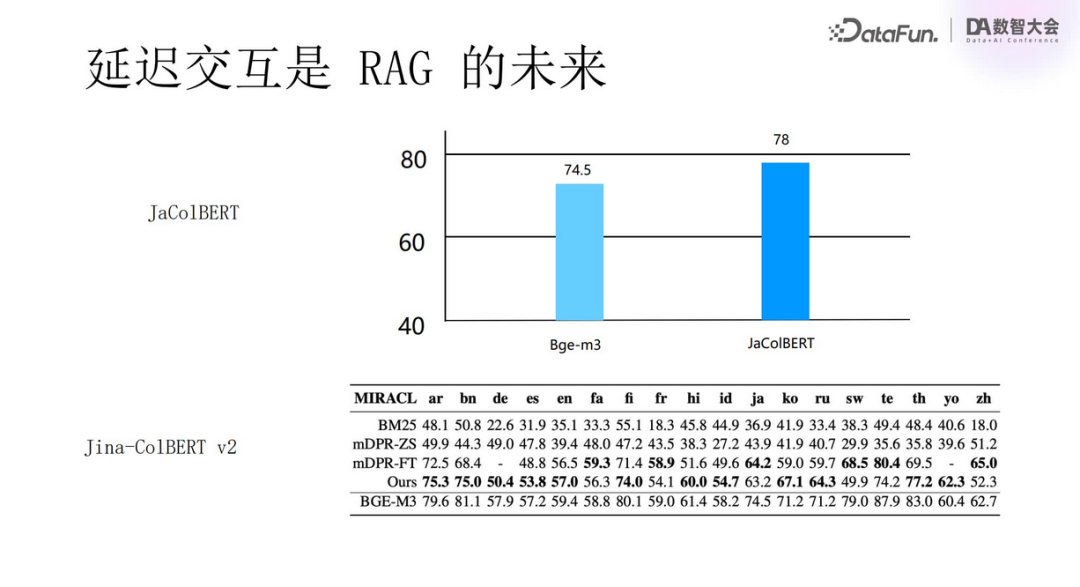
Delayed interaction will be the future development trend of RAG. Both JaColBERT and Jina-ColBERT v2 have shown positive progress.
How to Choose a Technical Route

The work shown in the image suggests that the visual language model route has advantages. However, we believe that both the carving route and the visual language model each have their strengths; documents with more abstract images are more suitable for the VLM approach, whereas traditional methods are more suitable otherwise.
Both routes will coexist for a long time:
-
The next-generation OCR based on Transformer will be more accurate in extracting multimodal documents.
-
OCR and VLM can coexist in the long term.
-
Support for tensor-based delayed interaction will be a standard choice for future multimodal RAG.
Finally, everyone is welcome to follow RAGFlow.
Q&A Session
Q1: How to cope with the challenge that multimodal may have a larger state space than natural language? Is there any attempt to standardize processing?
A1: Mapping charts to Excel is an idealized processing method, but it is very difficult. First, a large number of existing documents cannot all be converted to Excel, and secondly, Excel’s aesthetics and presentation effects are still lacking.
Q2: Why choose tensor computation over vector computation?
A2: The dimensions of vectors are fixed, while the size of tensors is flexible and adapts to variable-length data. Vector databases cannot directly handle variable-length data, hence the shift to tensor computation.
Thank you for attending this sharing session.
Expert in database systems and AI systems, co-founder of Infiniflow, responsible for the company’s R&D work. Before founding Infiniflow, served as the head of R&D at Zilliz, leading the team to create the Milvus vector database; VP of Matrix Origin R&D, responsible for the design and development of the MatrixOne database kernel.
Apache Doris Founder: What is a “Modern” Data Warehouse?
SuperSonic: The Next Generation Data Analysis Platform Practice of Chat BI and Headless BI
Innovative Practice of Management Analysis Agent Based on Metrics + Tags
Data Value Maximization with Shushi Technology Indicator Platform
RisingWave x Feature Engineering: Unlocking New Paradigms of Real-Time Features
Magic Space Creates New Levels of Experience, Various Templates Help You Quickly Generate Usable Spaces
Google CEO: The Low-Hanging Fruit of Large Models Has Been Picked, How to Dig Out Remaining Value from Large Models?
Understanding OpenAI’s 12 Days, 12 Steps of AGI Leap
Academician Sun Ninghui of the Chinese Academy of Engineering Lectures on Artificial Intelligence and Intelligent Computing Development
Ping An Life Data Management Practice and Outlook







