
In the previous lecture, we discussed the seq2seq model. Although the seq2seq model is powerful, its effectiveness can be significantly reduced if used in isolation. This section introduces the attention model, which simulates the human attention intuition within the encoder-decoder framework.
Principle of Attention Mechanism
The attention mechanism in the human brain is essentially a model for allocating attention resources. For instance, when we read a paper, our attention at any given moment is likely to be focused on a specific line of text. When we see an image, our attention is concentrated on a particular part of it. As our gaze moves, our attention shifts to another line of text or another part of the image. Therefore, at any moment, our attention distribution varies across a paper or an image. This is the origin of the famous attention mechanism model. We have previously mentioned the idea of attention mechanisms in the context of computer vision target detection, where Fast R-CNN utilizes Regions of Interest (RoI) to perform detection tasks more effectively; RoI is an application of the attention model in computer vision.
The attention model is more commonly used in the field of natural language processing, particularly in applications such as machine translation. In natural language processing, the attention model is typically applied within the classic Encoder-Decoder framework, which is the well-known N vs M model in RNNs. The seq2seq model is a typical example of an Encoder-Decoder framework.
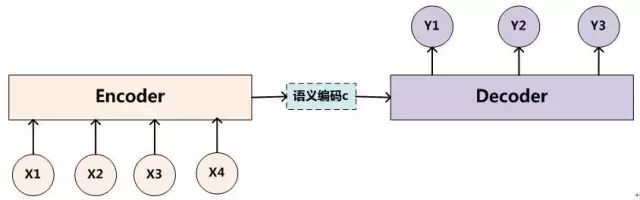
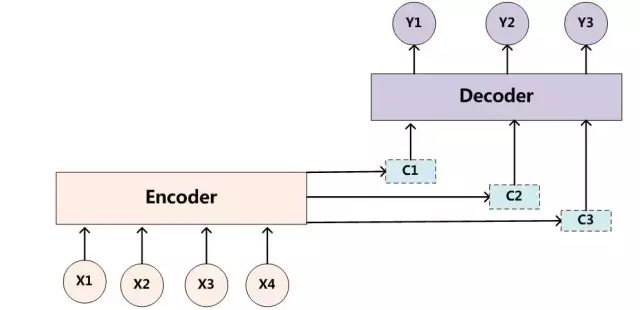
The Encoder-Decoder framework, as a general framework, is not sufficiently refined for specific natural language processing tasks. In other words, the pure Encoder-Decoder framework does not effectively focus on the input targets, which means that models like seq2seq cannot achieve their maximum effectiveness when used alone. For example, in the image above, the encoder encodes the input into a context variable c, and during decoding, each output Y indiscriminately uses this c for decoding. The attention model aims to encode different c for each time step of the sequence, combining each different c during decoding to produce more accurate results.
Unified encoding as c:
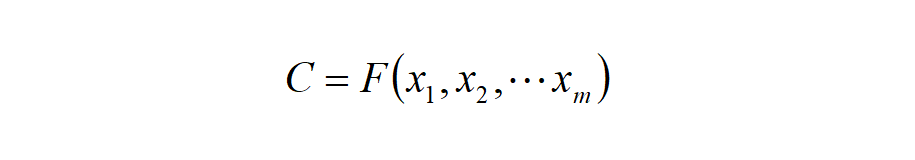
Using unified c for decoding: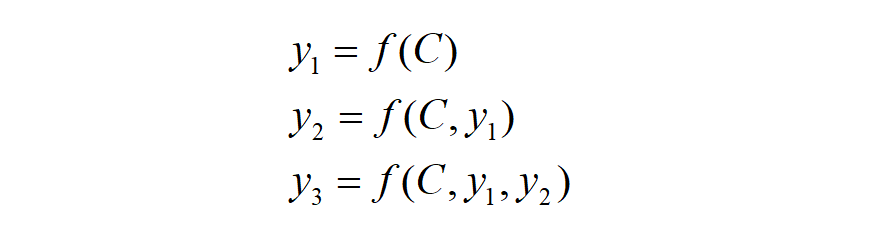
After applying the attention model, each input is independently encoded, and during decoding, there will be corresponding c for each input, rather than a one-size-fits-all approach:
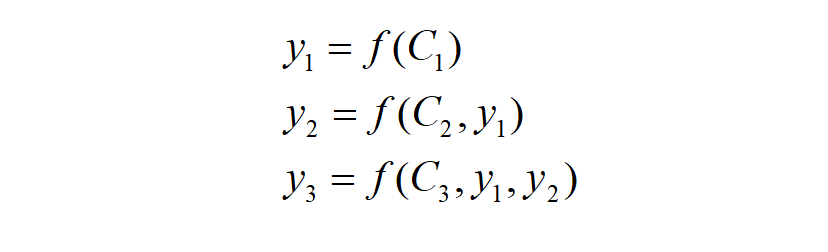 Consequently, the original Encoder-Decoder framework transforms into the following structure after introducing the attention mechanism:
Consequently, the original Encoder-Decoder framework transforms into the following structure after introducing the attention mechanism:
The above is a diagram of the attention model. Next, let’s see how the attention model can be described using formulas. The formula description is as follows:

A simple attention model is usually described by the following three formulas: 1) Calculate the attention score 2) Normalize 3) Combine the attention score and hidden state value to calculate the context state c. Here, u is the state value at a certain time step in decoding, which is the feature vector matching the current task, vi is the state value at the i-th time step in encoding, and a() is the function that calculates u and vi. a() can typically take the following forms:
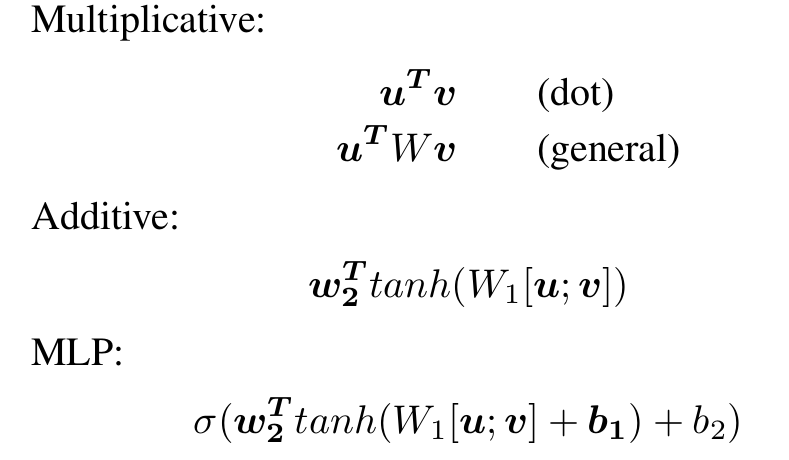
For example, in machine translation, a diagram of calculating an attention score:
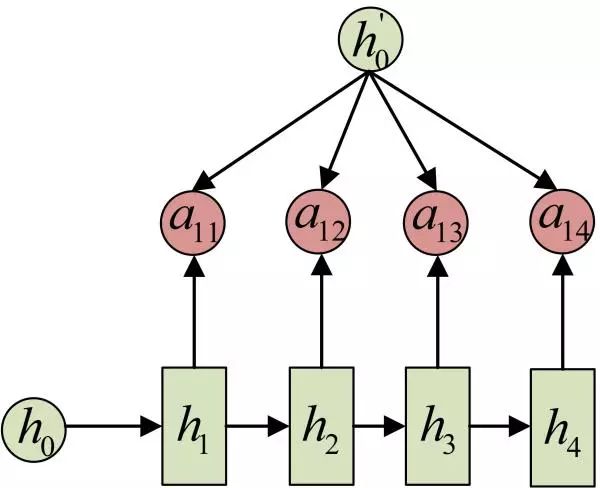
The attention score is calculated from the hidden state h in encoding and the hidden state h’ in decoding. Therefore, each context variable c will automatically select the most suitable contextual information corresponding to the current output y. Specifically, we use aij to measure the relevance between the j-th stage of the encoder’s hj and the i-th stage of the decoder, and ultimately, the contextual information ci for the i-th stage of input in the decoder comes from the weighted sum of all hj based on aij.
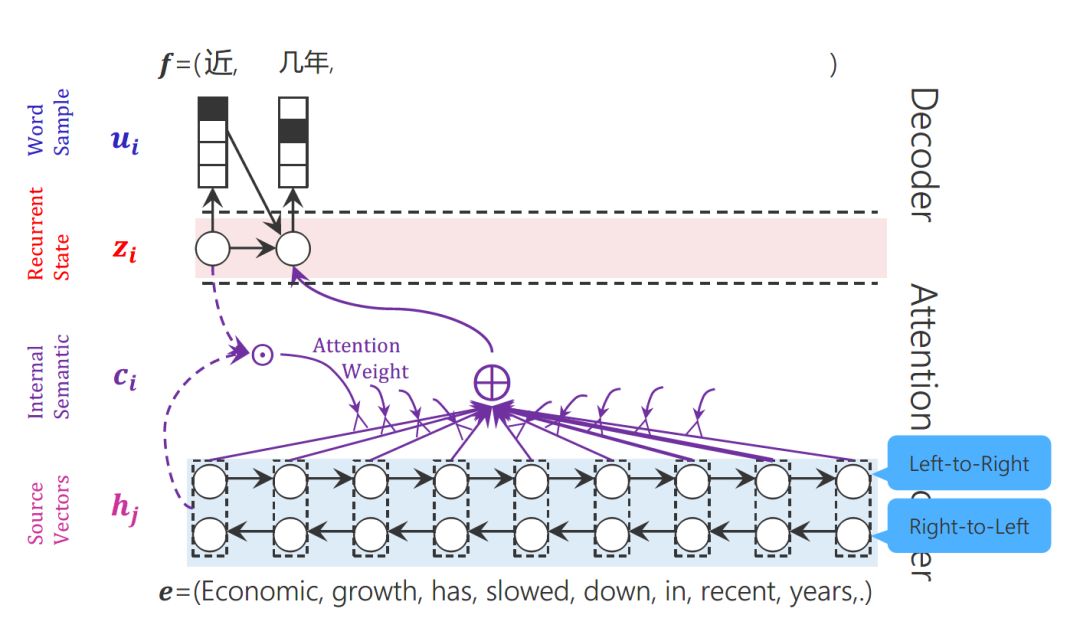
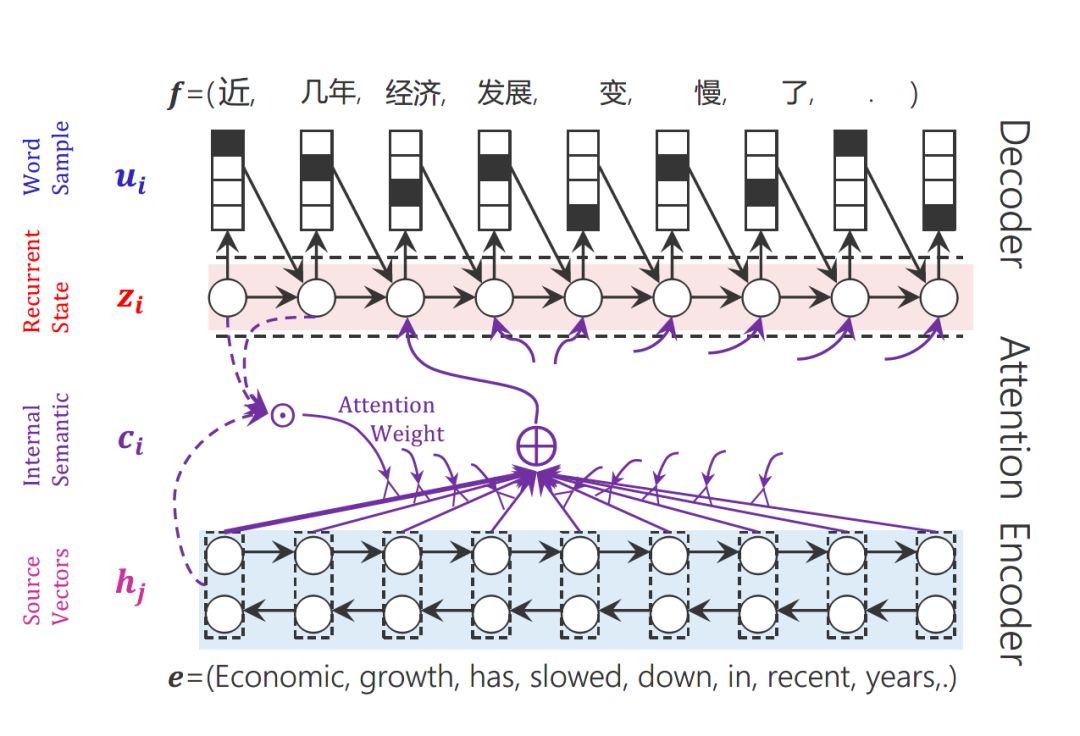
Machine Translation Based on Attention Model
Assuming we want to translate a time text expressed in English into a numerical time format using an RNN model with an attention mechanism. The input and output format examples are as follows:

Import task-related packages:
from keras.layers import Bidirectional, Concatenate, Permute, Dot, Input, LSTM, Multiply, Reshape
from keras.layers import RepeatVector, Dense, Activation, Lambda
from keras.optimizers import Adam
from keras.utils import to_categorical
from keras.models import load_model, Model
from keras.callbacks import LearningRateScheduler
import keras.backend as K
import matplotlib.pyplot as plt
import numpy as np
import random
import math
import jsonRead input and output related text data:
with open('data/Time Dataset.json','r') as f:
dataset = json.loads(f.read())
with open('data/Time Vocabs.json','r') as f:
human_vocab, machine_vocab = json.loads(f.read())
human_vocab_size = len(human_vocab)
machine_vocab_size = len(machine_vocab)
# Number of training samples
m = len(dataset)Tokenize the input time text and preprocess it, perform one-hot preprocessing on the output time, and define the preprocessing function:
def preprocess_data(dataset, human_vocab, machine_vocab, Tx, Ty): """
A method for tokenizing data.
Inputs:
dataset - A list of sentence data pairs.
human_vocab - A dictionary of tokens (char) to id's.
machine_vocab - A dictionary of tokens (char) to id's.
Tx - X data size
Ty - Y data size
Outputs:
X - Sparse tokens for X data
Y - Sparse tokens for Y data
Xoh - One hot tokens for X data
Yoh - One hot tokens for Y data
"""
# Metadata
m = len(dataset)
# Initialize
X = np.zeros([m, Tx], dtype='int32')
Y = np.zeros([m, Ty], dtype='int32')
# Process data
for i in range(m):
data = dataset[i]
X[i] = np.array(tokenize(data[0], human_vocab, Tx))
Y[i] = np.array(tokenize(data[1], machine_vocab, Ty))
# Expand one hots
Xoh = oh_2d(X, len(human_vocab))
Yoh = oh_2d(Y, len(machine_vocab))
return (X, Y, Xoh, Yoh)
def tokenize(sentence, vocab, length):
"""
Returns a series of id's for a given input token sequence.
It is advised that the vocab supports <pad> and <unk>.
Inputs:
sentence - Series of tokens
vocab - A dictionary from token to id
length - Max number of tokens to consider
Outputs:
tokens -
"""
tokens = [0]*length
for i in range(length):
char = sentence[i] if i < len(sentence) else "<pad>"
char = char if (char in vocab) else "<unk>"
tokens[i] = vocab[char]
return tokens
def ids_to_keys(sentence, vocab):
"""
Converts a series of id's into the keys of a dictionary.
"""
return [list(vocab.keys())[id] for id in sentence]
def oh_2d(dense, max_value):
"""
Create a one hot array for the 2D input dense array.
"""
# Initialize
oh = np.zeros(np.append(dense.shape, [max_value]))
# Set correct indices
ids1, ids2 = np.meshgrid(np.arange(dense.shape[0]), np.arange(dense.shape[1]))
oh[ids1.flatten(), ids2.flatten(), dense.flatten('F').astype(int)] = 1
return ohPreprocess the data and split the dataset:
# Max x sequence length
Tx = 41
# y sequence length
Ty = 5
X, Y, Xoh, Yoh = preprocess_data(dataset, human_vocab, machine_vocab, Tx, Ty)
# Split into training and testing sets
train_size = int(0.8*m)
Xoh_train = Xoh[:train_size]
Yoh_train = Yoh[:train_size]
Xoh_test = Xoh[train_size:]
Yoh_test = Yoh[train_size:]View examples of data before and after preprocessing: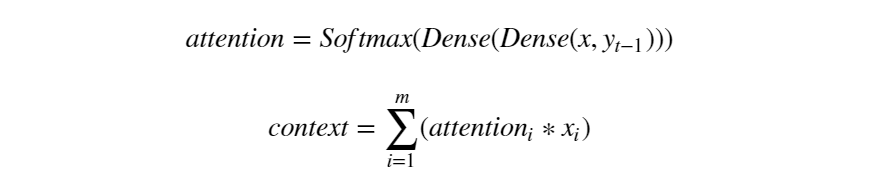 Once the data is ready, we can begin modeling. In this example, the formulas for calculating the attention score and context vector are as follows:
Once the data is ready, we can begin modeling. In this example, the formulas for calculating the attention score and context vector are as follows:
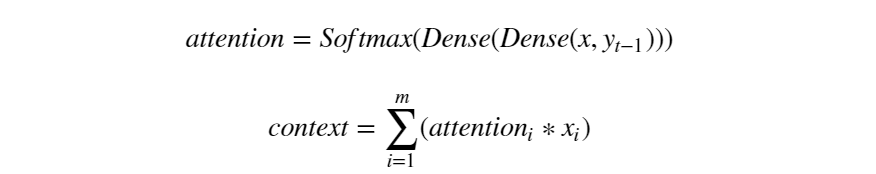 Define the attention mechanism process for one time step:
Define the attention mechanism process for one time step:
# Define part of the attention layer globally so as to
# share the same layers for each attention step.
def softmax(x):
return K.softmax(x, axis=1)
layer1_size = 32
# Attention layer
layer2_size = 64
at_repeat = RepeatVector(Tx)
at_concatenate = Concatenate(axis=-1)
at_dense1 = Dense(8, activation="tanh")
at_dense2 = Dense(1, activation="relu")
at_softmax = Activation(softmax, name='attention_weights')
at_dot = Dot(axes=1)
def one_step_of_attention(h_prev, a):
"""
Get the context.
Input:
h_prev - Previous hidden state of a RNN layer (m, n_h)
a - Input data, possibly processed (m, Tx, n_a)
Output:
context - Current context (m, Tx, n_a)
"""
# Repeat vector to match a's dimensions
h_repeat = at_repeat(h_prev)
# Calculate attention weights
i = at_concatenate([a, h_repeat])
i = at_dense1(i)
i = at_dense2(i)
attention = at_softmax(i)
# Calculate the context
context = at_dot([attention, a])
return contextThen, define an attention network layer based on the attention process for one time step:
def attention_layer(X, n_h, Ty):
"""
Creates an attention layer.
Input:
X - Layer input (m, Tx, x_vocab_size)
n_h - Size of LSTM hidden layer
Ty - Timesteps in output sequence
Output:
output - The output of the attention layer (m, Tx, n_h)
"""
# Define the default state for the LSTM layer
h = Lambda(lambda X: K.zeros(shape=(K.shape(X)[0], n_h)))(X)
c = Lambda(lambda X: K.zeros(shape=(K.shape(X)[0], n_h)))(X) # Messy, but the alternative is using more Input()
at_LSTM = LSTM(n_h, return_state=True)
output = []
# Run attention step and RNN for each output time step
for _ in range(Ty):
context = one_step_of_attention(h, X)
h, _, c = at_LSTM(context, initial_state=[h, c])
output.append(h)
return output### Then, build the LSTM network with attention mechanism
layer3 = Dense(machine_vocab_size, activation=softmax)
def get_model(Tx, Ty, layer1_size, layer2_size, x_vocab_size, y_vocab_size):
"""
Creates a model.
input:
Tx - Number of x timesteps
Ty - Number of y timesteps
size_layer1 - Number of neurons in BiLSTM
size_layer2 - Number of neurons in attention LSTM hidden layer
x_vocab_size - Number of possible token types for x
y_vocab_size - Number of possible token types for y
Output:
model - A Keras Model.
"""
# Create layers one by one
X = Input(shape=(Tx, x_vocab_size))
a1 = Bidirectional(LSTM(layer1_size, return_sequences=True), merge_mode='concat')(X)
a2 = attention_layer(a1, layer2_size, Ty)
a3 = [layer3(timestep) for timestep in a2]
# Create Keras model
model = Model(inputs=[X], outputs=a3)
return modelThen pass the data, compile the model, and train it:
# Obtain a model instance
model = get_model(Tx, Ty, layer1_size, layer2_size, human_vocab_size, machine_vocab_size)
# Create optimizer
opt = Adam(lr=0.05, decay=0.04, clipnorm=1.0)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
# Group the output by timestep, not example
outputs_train = list(Yoh_train.swapaxes(0, 1))
# model train
model.fit([Xoh_train], outputs_train, epochs=30, batch_size=100)Training example is as follows:
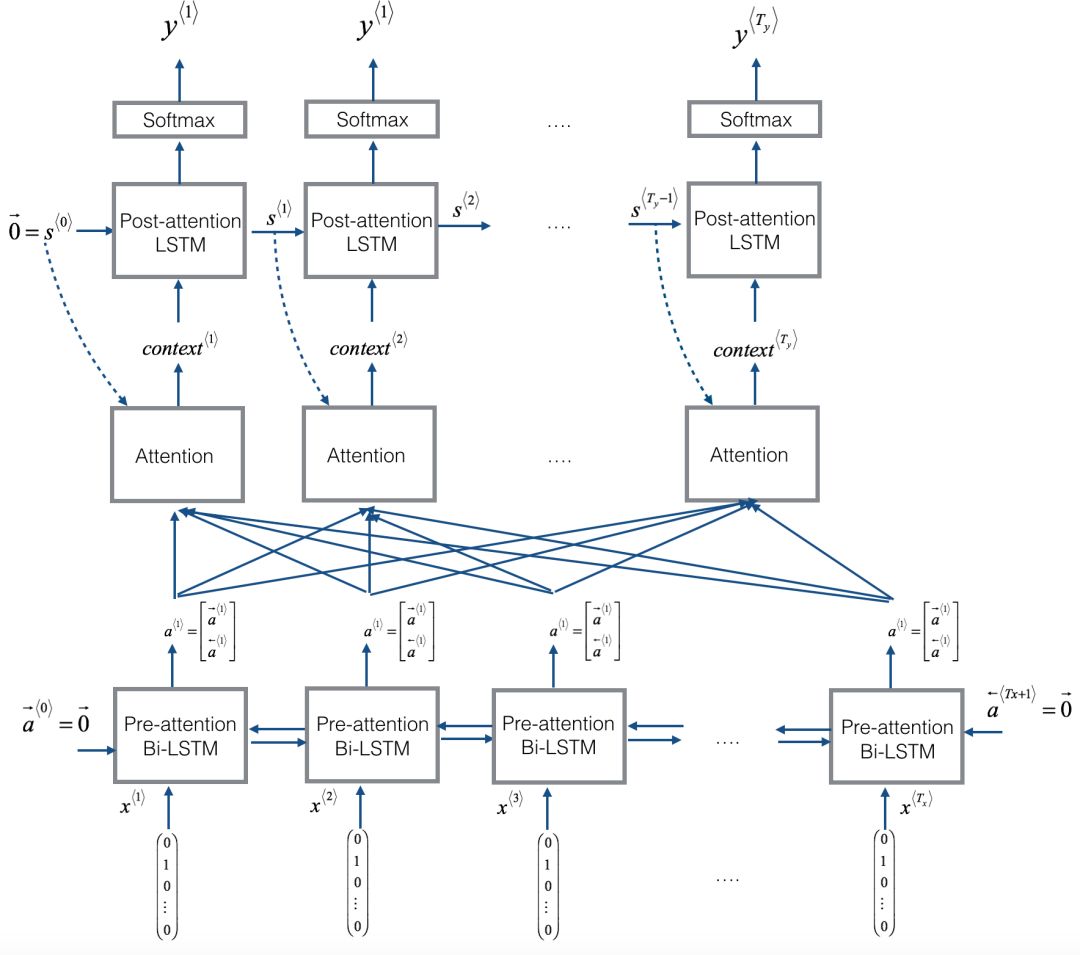
The model structure containing the attention layer is as follows:
 The overall structure of the model is illustrated in the following diagram (not entirely consistent, for illustration only):
The overall structure of the model is illustrated in the following diagram (not entirely consistent, for illustration only):
Next, evaluate the trained model on the test set: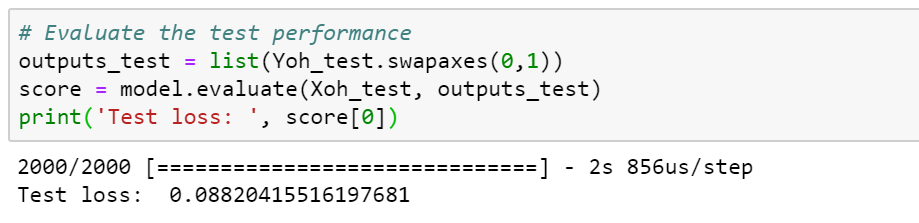
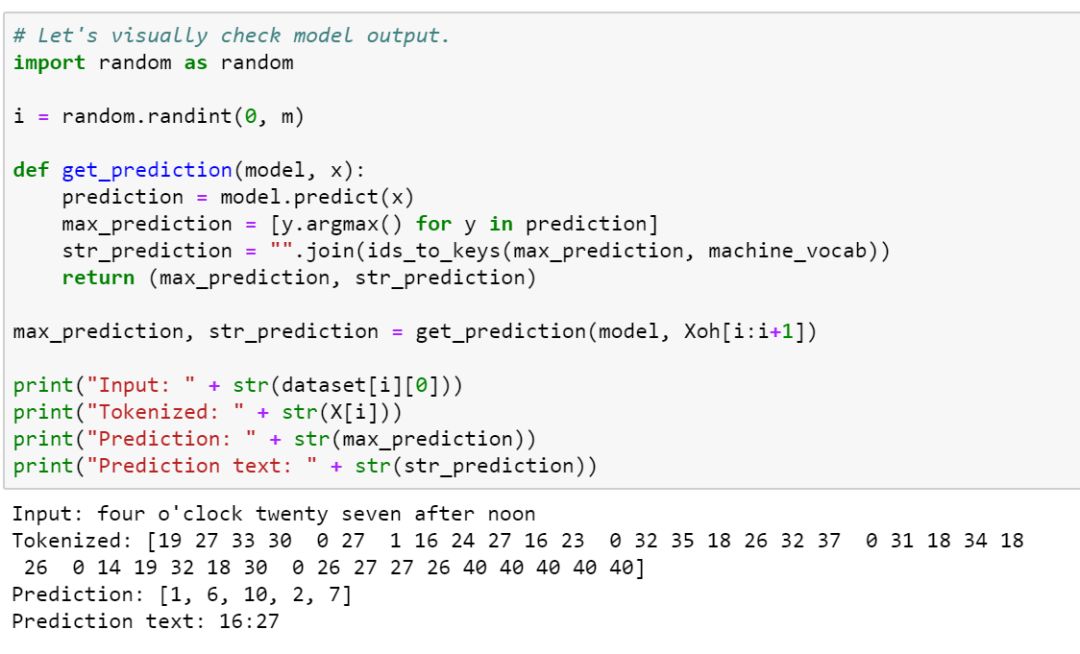
Finally, let’s take a brief look at what the attention model expresses during the translation process, using a visualization method to showcase the attention model: It can be seen that in the above test example, the attention mechanism allows the model to focus on the corresponding input characters.
It can be seen that in the above test example, the attention mechanism allows the model to focus on the corresponding input characters.
References:
deeplearningai.com
https://github.com/luwill/Attention_Network_With_Keras
https://zhuanlan.zhihu.com/p/28054589
Previous Highlights:
Lecture 46: seq2seq Model
Lecture 45: GloVe Word Vectors and Related Applications
Lecture 44: Training a word2vec Word Vector
Lecture 43: Word2vec in Natural Language Processing
Lecture 42: Word Embedding and Word Vectors in Natural Language Processing
Lecture 41: Implementation of LSTM in numpy and keras
Lecture 40: RNNs and Long Short-Term Memory Networks (LSTM)
Lecture 39: RNNs and Gated Recurrent Units (GRU)
Lecture 38: Four Types of RNNs
A data scientist’s learning journey


Long press the QR code. Follow the Machine Learning Laboratory
