
Author丨Fat Cat, Yi Zhen
Zhihu Column丨Machine Learning Algorithms and Natural Language Processing
Address丨https://zhuanlan.zhihu.com/p/82477941
Natural Language Processing (NLP) is generally divided into two categories: Natural Language Understanding (NLU) and Natural Language Generation (NLG).
The former extracts or analyzes concise logical information from a piece of text, such as Named Entity Recognition (NER) which identifies keywords in a sentence, and Sentiment Analysis (SA) which classifies given text;
while the latter maps a piece of text or a data structure (like a graph or tree) to a segment of text (which can be lengthy, such as a document).
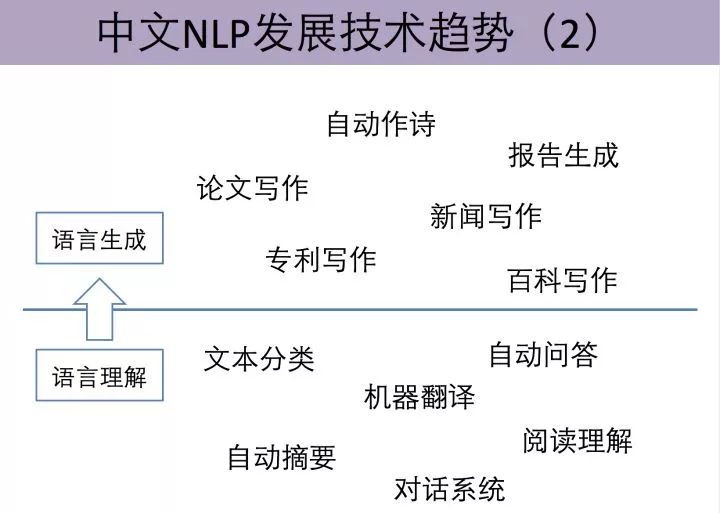 (The above image is from Liu Zhiyuan’s Zhihu Q&A)
(The above image is from Liu Zhiyuan’s Zhihu Q&A)
The specific applications of both are shown in the above image. Clearly, the task of natural language generation is much more challenging because it requires not only a precise understanding of the input but also the generation of coherent language. In industrial applications, understanding has performed better, with technologies like named entity recognition and text classification being widely used; however, many language generation scenarios, such as customer service and translation, still rely on templates and retrieval methods. This is due to numerous unresolved issues in current generation models, such as stability and consistency. These facts indicate that there are still many unexplored areas in current natural language generation tasks, such as dialogue generation and text summarization, which have significant application prospects.
In this section, we will first understand the basic concepts of the EncoderDecoder model and the Attention mechanism, and then guide you step by step to implement it using PaddlePaddle.
Part-1: EncoderDecoder Model
The full name of EncoderDecoder refers to the encoder-decoder, which is one of the most important milestones in natural language generation. The idea is to use an encoder, such as a Recurrent Neural Network (RNN) or Convolutional Neural Network (CNN), to encode a segment of input text into a continuous space vector, and then use a decoder (usually an RNN) to generate a segment of text word by word. An example is shown below:
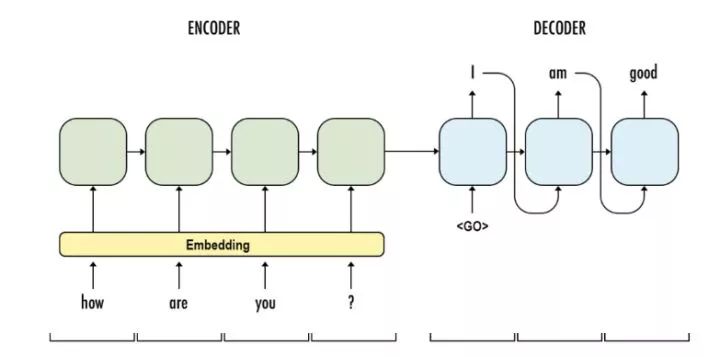
With the support of some packages, the encoder is generally quite simple and is end-to-end. The decoder is more complex; it is an autoregressive model, i.e., (yi|xi,yi-1). In natural language processing, we also refer to it as teacher forcing. A semantic vector connecting the encoder and decoder represents a certain concept of the input sentence and guides the decoding process of the decoder.
It is worth mentioning that many models have recently emerged that challenge these traditional structures. For example, Convolutional Seq2Seq which completely uses CNNs, and Transformers which completely use Self Attention. Furthermore, the so-called EncDec is no longer solely used for generation tasks; other tasks such as classification and sequence labeling also separate the model into encoder and decoder parts, including the Transformer paper.
Part-2: Attention Mechanism
The attention mechanism is not only crucial for generation tasks but also significantly impacts the entire NLP field. Variants such as Transformer and Copy Mechanism are examples of it, as shown in the figure below:
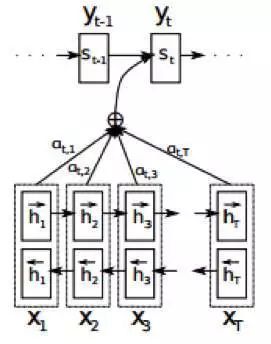

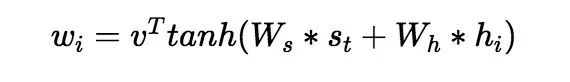

Part-3: Implementation
After discussing so much, what’s the use if we don’t implement it?! The following content will teach you step by step how to implement a machine translation model using PaddlePaddle.
# Import PaddlePaddle computing framework.
import paddle
from paddle import fluid
from paddle.fluid.optimizer import Adam
VOCAB_SIZE = 30000 # Bilingual dictionary capacity.
HIDDEN_DIM = 64 # Network hidden layer size.
BATCH_SIZE = 16 # Calculation batch size.
EPOCH_NUM = 20 # Total number of iterations.
def build_encoder(src_word):
# Define input word sequence and map to embedding layer.
src_embedding = fluid.layers.embedding(input=src_word, size=[VOCAB_SIZE, HIDDEN_DIM * 3],
dtype='float32', is_sparse=True)
# Pass through a bidirectional GRU to enhance contextual representation.
src_forward = fluid.layers.dynamic_gru(input=src_embedding, size=HIDDEN_DIM)
src_backward = fluid.layers.dynamic_gru(input=src_embedding, size=HIDDEN_DIM, is_reverse=True)
return fluid.layers.concat(input=[src_forward, src_backward], axis=1)
def make_attn(x, decoder_state, encoder_vec, encoder_proj):
"""Define attention mechanism and perform forward computation."""
# Below is the process of calculating attention, referring to the above formula.
decoder_state_proj = fluid.layers.fc(
input=decoder_state, size=HIDDEN_DIM, bias_attr=False)
decoder_state_expand = fluid.layers.sequence_expand(
x=decoder_state_proj, y=encoder_proj)
mixed_state = fluid.layers.elementwise_add(encoder_proj, decoder_state_expand)
attention_weights = fluid.layers.fc(
input=mixed_state, size=1, bias_attr=False)
attention_weights = fluid.layers.sequence_softmax(
input=attention_weights)
weigths_reshape = fluid.layers.reshape(x=attention_weights, shape=[-1])
scaled = fluid.layers.elementwise_mul(x=encoder_vec, y=weigths_reshape, axis=0)
context = fluid.layers.sequence_pool(input=scaled, pool_type='sum')
# Combine decoder state and context for single-step decoding update.
out = fluid.layers.fc(input=[x, context], size=HIDDEN_DIM * 3, bias_attr=False)
out = fluid.layers.gru_unit(input=out, hidden=decoder_state, size=HIDDEN_DIM * 3)[0]
return out, out
def build_decoder(encoder_out):
# Get the last encoding vector for initialization.
encoder_last = fluid.layers.sequence_last_step(input=encoder_out)
last_reduce = fluid.layers.fc(input=encoder_last, size=HIDDEN_DIM, act='tanh')
# Save the encoder encoding for the attention mechanism.
out_reduce = fluid.layers.fc(input=encoder_out, size=HIDDEN_DIM, bias_attr=False)
# Define the next word for teacher forcing.
next_word = fluid.layers.data(name="tgt_wod", shape=[1], dtype='int64', lod_level=1)
tgt_embedding = fluid.layers.embedding(input=next_word, size=[VOCAB_SIZE, HIDDEN_DIM],
dtype='float32', is_sparse=True)
rnn = fluid.layers.DynamicRNN()
with rnn.block():
dec_state = rnn.step_input(tgt_embedding)
pre_state = rnn.memory(init=last_reduce, need_reorder=True)
encoder_out = rnn.static_input(encoder_out)
hidden_proj = rnn.static_input(out_reduce)
# Combine with attention mechanism for single-step update.
out, current_state = make_attn(dec_state, pre_state, encoder_out, hidden_proj)
prob = fluid.layers.fc(input=out, size=VOCAB_SIZE, act='softmax')
# Save predicted probabilities to RNN.
rnn.update_memory(pre_state, current_state)
rnn.output(prob)
return rnn()
# Prepare PaddlePaddle computation engine.
train_prog = fluid.Program()
startup_prog = fluid.Program()
place = fluid.CPUPlace()
exe = fluid.Executor(place)
with fluid.program_guard(train_prog, startup_prog):
with fluid.unique_name.guard():
# Define input and next word correct prediction.
input_word = fluid.layers.data(name="src_word", shape=[1], dtype='int64', lod_level=1)
label = fluid.layers.data(name="nxt_word", shape=[1], dtype='int64', lod_level=1)
# Get predictions through encdec mechanism.
enc_hidden = build_encoder(input_word)
predict_out = build_decoder(enc_hidden)
# Define loss function and perform Adam optimization.
cost = fluid.layers.cross_entropy(input=predict_out, label=label)
avg_cost = fluid.layers.mean(cost)
Adam().minimize(avg_cost)
# Here we use the built-in WMT16 dataset.
dataset = paddle.dataset.wmt16.train(VOCAB_SIZE, VOCAB_SIZE)
train_data = paddle.batch(paddle.reader.shuffle(dataset,
buf_size=10000), batch_size=BATCH_SIZE)
# Define the input-output interface types of the network.
feeder = fluid.DataFeeder(feed_list=['src_word', 'tgt_wod', 'nxt_word'],
place=place, program=train_prog)
exe.run(startup_prog)
# Import data to iteratively update the network and print intermediate results.
for epoch in range(EPOCH_NUM):
for data in train_data():
cost = exe.run(train_prog, feed=feeder.feed(data), fetch_list=[avg_cost])[0]
print('Epoch: %d, Loss: %f' % (epoch, cost))Epoch:0, Loss: 10.308955
Epoch:0, Loss:10.307491
Epoch:0, Loss:10.305926
Epoch:0, Loss:10.304086
Epoch:0, Loss:10.300835
Epoch:0, Loss:10.297029
Epoch:0, Loss:10.294180
Epoch:0, Loss:10.289069
Epoch:0, Loss:10.281763
Epoch:0, Loss:10.276464
Epoch:0, Loss:10.264387
Epoch:0, Loss:10.249886
Epoch:0, Loss: 10.235321
Epoch:0, Loss:10.215168
Epoch:0, Loss:10.189552
Epoch:0, Loss:10.147161
Epoch:0, Loss:10.112047
Epoch:0, Loss:10.050254
Epoch:0, Loss:9.973387
Epoch:0, Loss:9.862699
Epoch:0, Loss:9.745776
Epoch:0, Loss:9.628855
Epoch:0, Loss:9.548506
Epoch:0, Loss:9.255364
Epoch:0, Loss:9.202472
Epoch:0, Loss:8.982078
From the results, we can see that the loss is continuously decreasing, indicating that the model is learning properly.
If you want to learn more about NLP-related models, scan the QR code below to read more.

Recommended Reading:
Step-by-step Guide to Building Word Vector Model SkipGram with PaddlePaddle
PaddlePaddle Practical NLP Classic Model BiGRU + CRF Detailed Explanation
Geometric Interpretation of Systems of Equations [Download MIT Linear Algebra First Course PDF]
