Author丨Tianyu Su
Zhihu Column丨Machines Don’t Learn
Address丨https://zhuanlan.zhihu.com/p/27769286
In the previous column, we implemented a basic version of the Seq2Seq model. This model performs sorting of letters, taking an input sequence of letters and returning the sorted sequence. Through the implementation in the last article, we have gained an understanding of the Seq2Seq model, which mainly consists of two components—Encoder and Decoder. The Encoder encodes the input into a fixed-size Context Vector and passes it to the Decoder, which decodes the vector to produce the output.
Of course, the basic Seq2Seq model has many bottlenecks. This article will introduce improvements on the basic Seq2Seq model in the context of language translation, specifically the Attention mechanism and BiRNN.
RNN Encoder-Decoder
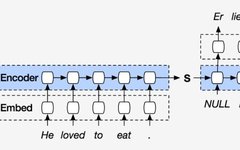
We will first look at the basic Encoder-Decoder model. The following diagram illustrates an Encoder-Decoder in the application of language translation.
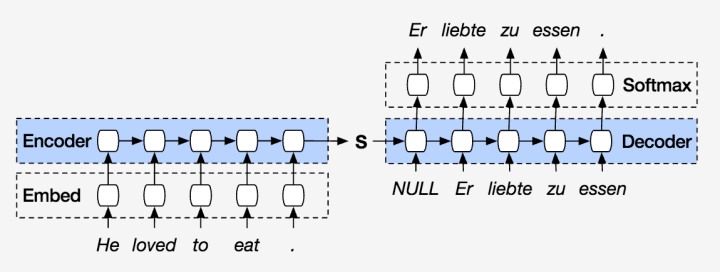
Image source:Peeking into the neural network architecture used for Google’s Neural Machine Translation
In this diagram, the Encoder first compresses our input sequence into a fixed-size vector s using RNN (usually LSTM or GRU), which we call the context vector. The Decoder then generates the translation result after receiving this vector.
Although this model can yield relatively good translation results, it has its shortcomings.
-
Lossy compression of information. Although the Decoder receives information from the input sequence, it cannot grasp all the information. This is because our Encoder performs lossy compression of the input sequence. This means that there is a certain loss of information during the transmission process. Moreover, the longer the input sentence, the greater the amount of information lost during compression, which results in poorer predictions from the Decoder.
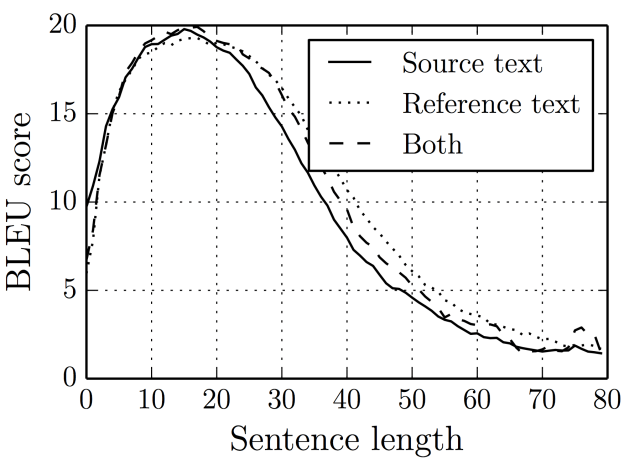
Image source:[1409.0473] Neural Machine Translation by Jointly Learning to Align and Translate
The above diagram illustrates this problem; as the length of the sentence increases, BLEU initially increases and then decreases. This means that for average sentence lengths (between 10-20 words), the model’s translation performance is quite good, but as the sentences get longer, the results only worsen.
-
The time dimension of RNN is too large. When the sentence sequence is long, it means the time dimension of the RNN is deep. For example, if a sentence is 50 words long, this means the RNN training process needs to recurse 50 times for computation. This can lead to the phenomenon of gradient vanishing during BPTT. Even if we use models like LSTM to address this issue, gradient vanishing remains a concern.
-
Homogeneity of the Context Vector. After the Encoder transforms the input sequence into a Context Vector, the Decoder relies on this constant Context Vector for translating each word. In practical scenarios, when translating a sentence, we do not focus too much on words that are not directly relevant to the current word being translated. For example, when translating “I love machine learning,” when we reach “machine learning,” we do not care whether it was “I love” or “He loves”; we only focus on translating “machine learning” to “机器学习.” Therefore, using the same Context Vector for translation can introduce interference information, resulting in less accurate outcomes.
Attention-Based Encoder-Decoder Model
Having discussed the drawbacks of the traditional Encoder-Decoder, how can we improve it? First, let’s return to practical scenarios. When we translate a long sentence, we repeatedly look back at the source sentence to grasp all the detailed information. In the original Encoder-Decoder model, we only used the last state output of the Encoder as the information for the source sentence, which leads to significant information loss. Moreover, as illustrated in the previous example, when we translate a certain part of a sentence, we may be completely uninterested in other parts. The Attention mechanism serves as a “shortcut” that allows us to focus only on certain states of the input sequence. Let’s understand its working principle through diagrams and mathematical formulas.
First, we define the following variables:

In the original Encoder-Decoder model, we actually maximize the joint probability distribution:
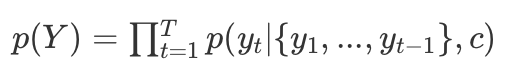
Where each conditional probability can be expressed as:
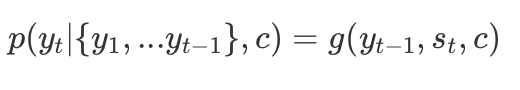
Where g is a nonlinear function, which is our RNN.
In the Attention model, our conditional probability becomes:
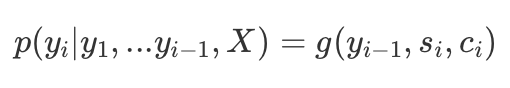
Where the state at the i-th stage is a function of the previous stage state, the previous output, and the i-th Context Vector.

From the new model, we can see that when predicting the i-th target value, the probability function starts utilizing all the information from the X inputs, meaning that for the Decoder, there will be a unique Context Vector corresponding to each word being translated, thus solving the problem of Context Vector homogeneity.
So how is the Context Vector calculated? It is actually a weighted result of each stage state h from the Encoder:
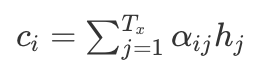
Where the weight α is defined as follows:

The calculation of the weights is somewhat similar to the softmax calculation. Here, e is referred to as the alignment model, which evaluates the degree of matching between the j-th word in the input statement and the i-th word in the output statement. The calculation methods for these e’s may vary across different papers.
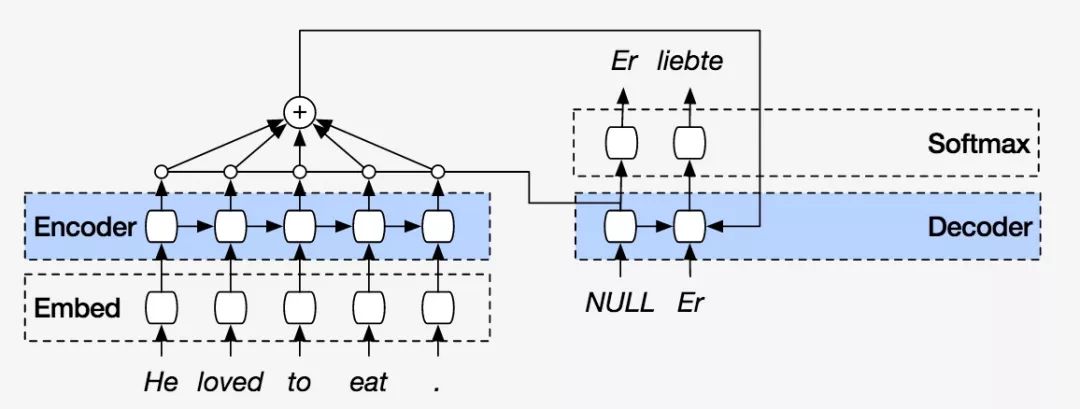
To understand alignment, let’s look at an example. Suppose we are still translating the sentence “I love machine learning,” and our translation result is “我爱机器学习,” where “我” comes from “I,” “爱” comes from “love,” and “机器学习” comes from “machine learning,” which cannot come from “I.” Therefore, we can consider that “我,” “爱,” and “机器学习” are aligned with “I,” “love,” and “machine learning” respectively. Thus, when calculating e, the probability of “我” coming from “I” is the highest, while the probabilities for “love” or “machine learning” are very low. Consequently, the e corresponding to “我” and “I” becomes larger, leading to a greater weight, so when translating “我,” the contribution from “I” is emphasized, meaning the model will pay more attention to “I” at this stage. When we plot the weights α, we can see a more intuitive result:
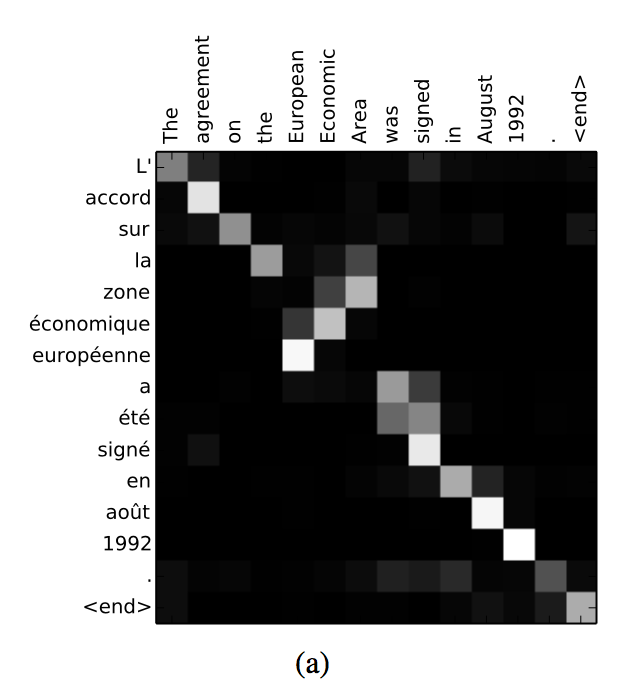
Image source:[1409.0473] Neural Machine Translation by Jointly Learning to Align and Translate
The above is an example of English to French translation, where the vertical axis represents the input statement (French), and the horizontal axis represents the target statement (English). We can see that the alignments are not completely linear, which is due to different languages having different word orders, so the input and output are not aligned one-to-one in order. The above diagram shows that it successfully aligns the French word “zone” with the English word “area,” and the French word “économique” with the English word “Economic,” etc.
After introducing these defined formulas, let’s further examine the intuitive results from the diagrams:
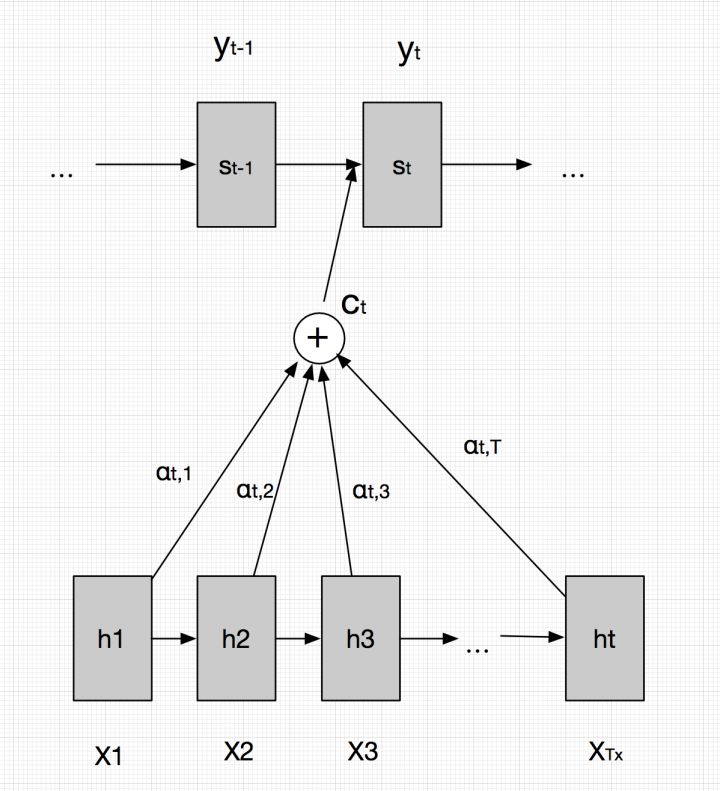
The above diagram shows the structure when predicting the output y at stage t. By weighting the states of the Encoder layer, we can grasp all the detailed information in the input statement.
Thus, we have introduced the basic idea of the Attention mechanism and the objectives it aims to solve. The Context Vector in the RNN Encoder-Decoder model has been replaced by a more efficient Attention mechanism. The Attention mechanism does have a drawback in terms of time complexity. Assuming our source sentence length is N and the target sentence length is M, then in the RNN Encoder-Decoder model, the time complexity at the Decoder end is only O(M), as they use the same Context Vector, which is independent of the length of the input sentence. However, in the model with Attention, the prediction at the Decoder is related to the length of the input sentence, as it needs to focus on every detail of the input, thus increasing the time complexity to O(MN). But this drawback is negligible compared to the improvement in translation accuracy brought by Attention.
Bidirectional RNN
Suppose we now need to translate “IU is an outstanding singer whom I want to see.” into Chinese. Since relative clauses in English come after the antecedent, this means we cannot translate word-for-word. We need to adjust the word order. In such cases, we definitely read through the entire sentence to grasp all the information before translating.
However, for RNN, the state information at stage t only contains information from the past t-1 stages, which is insufficient to grasp the entirety of the sentence with different word orders. Therefore, we hope that the state information at stage t not only contains past information but also future information, allowing the model to have a more complete understanding of the input sentence.
Based on this idea, the Bidirectional RNN comes into play. It consists of a forward RNN and a backward RNN, where the former reads the input from front to back, and the latter reads the input sentence in reverse order. This way, the state at stage t can contain both historical and future information. BiRNN is very helpful for translations between languages with different word orders.
The following diagram shows the structure of a BiRNN:
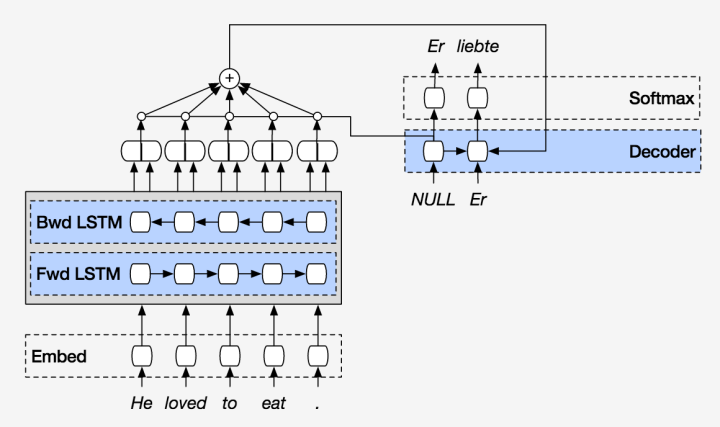
Image source:Peeking into the neural network architecture used for Google’s Neural Machine Translation
In the forward RNN, we obtain a forward state sequence:
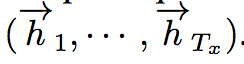
In the backward RNN, we obtain a backward state sequence:
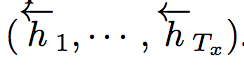
At stage t, we concatenate the corresponding two parts of the states to compute the Context Vector. Intuitively, when translating a word y, it will pay more attention to the words x that are related to y and their vicinity (including words before and after x).
Thus, we have introduced the basic ideas of the Attention Mechanism and BiRNN. Overall, they both enhance the Decoder’s grasp and understanding of the information in the input sentence. Of course, there are many other improvements to translation models, including multi-layer stacking, etc. Interested readers can look for more materials. If there are any errors in the text, I appreciate your corrections!
Recommended Reading:
Practical | Pytorch BiLSTM + CRF for NER
How to evaluate the fastText algorithm proposed by the author of Word2Vec? Does deep learning have no advantages in simple tasks like text classification?
From Word2Vec to Bert, talking about the past and present of word vectors (1)
