Selected from TowardsDataScience
Author: Raimi Karim
Contributors: Gao Xuan, Lu
This article visually explains the attention mechanism with several animated diagrams and shares four NMT architectures that have emerged in the past five years, along with intuitive explanations of some concepts mentioned in the text.
For decades, statistical machine translation has dominated translation models [9], until the advent of neural machine translation (NMT). NMT is an emerging machine translation method that attempts to build and train a single large neural network that reads input text and outputs translations [1].
The pioneering research on NMT comes from three papers: Kalchbrenner and Blunsom (2013), Sutskever et al. (2014), and Cho et al. (2014b), among which the more familiar framework is the sequence-to-sequence (seq2seq) learning proposed in the paper by Sutskever et al. This article explains how to build attention based on the seq2seq framework.
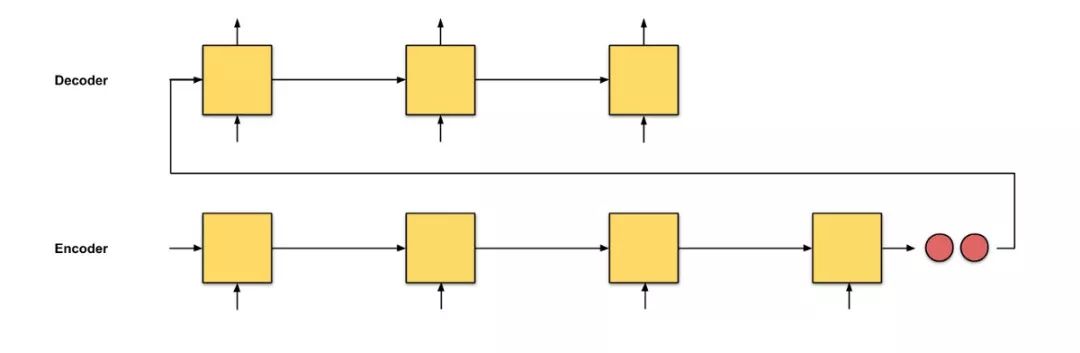
Figure 0.1: seq2seq, input sequence length is 4.
In seq2seq, the initial idea is to have two recurrent neural networks (RNNs) form an encoder-decoder architecture: the encoder reads input words one by one to obtain a fixed-dimensional vector representation, and then another RNN (the decoder) extracts output words based on these inputs one by one.

Figure 0.2: seq2seq, input sequence length is 64.
The issue with seq2seq is that the only information the decoder receives from the encoder is the “last encoder hidden state” (the two red nodes in Figure 0.1), which is a vector representation similar to a summary of the input sequence numbers. Therefore, for longer input texts (Figure 0.2), if we still expect the decoder to only use this one vector representation (hoping it “sufficiently summarizes the input sequence”) to output translations, that is unreasonable. This may lead to catastrophic forgetting. This sentence has 100 words; can you immediately translate it into another language?
If we cannot do that, then we should not be so harsh on the decoder. Would providing the decoder with vector representations for each encoder time step, rather than just one vector representation, yield better translation results?
Introducing the attention mechanism.
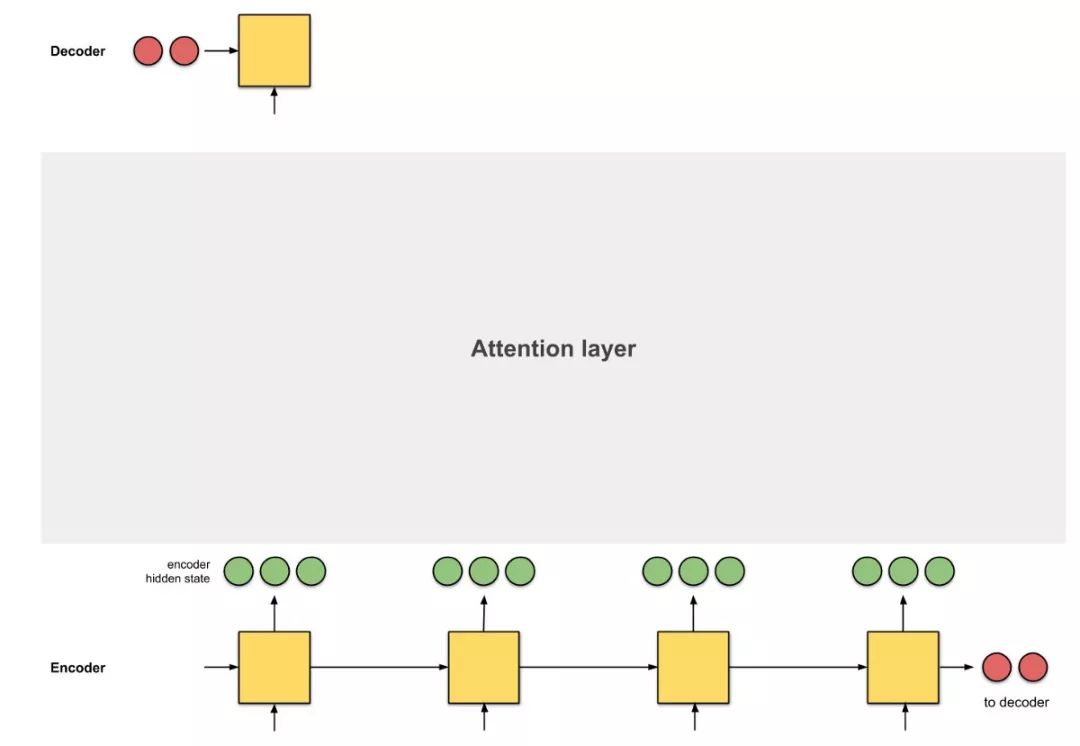
Figure 0.3: Introducing the attention mechanism as an interface between the encoder and decoder. Here, the first decoder time step receives information from the encoder before providing the first translation word.
Attention is the interface between the encoder and decoder, providing the decoder with information from each encoder hidden state (except for the red hidden states in Figure 0.3). With this setup, the model can selectively focus on useful parts of the input sequence, learning the alignment between them. This helps the model effectively process long input sentences [9].
Alignment definition: Alignment refers to matching segments of the original text with their corresponding segments in the translation.
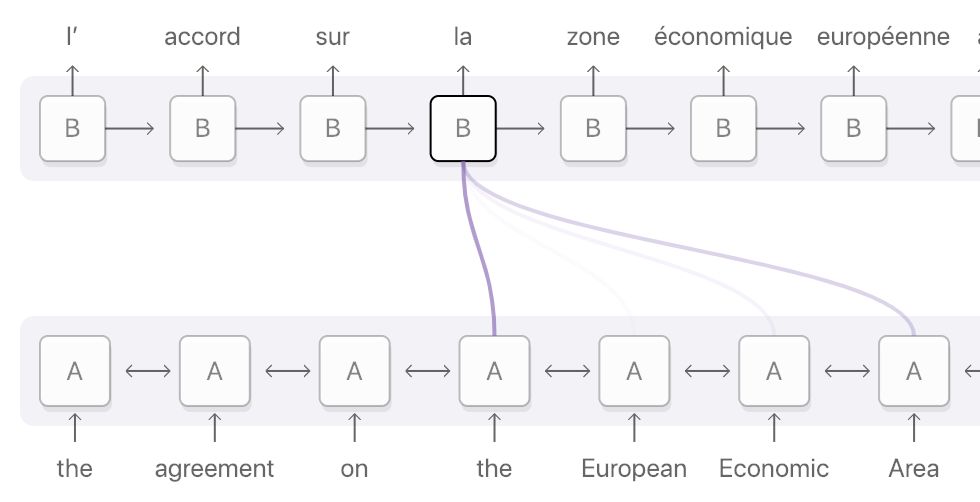
Figure 0.4: The alignment distribution of the French word “la” in the input sequence, mainly distributed over these four words: ‘the’, ‘European’, ‘Economic’, and ‘Area’. The deep purple indicates a higher attention score. (Image source: https://distill.pub/2016/augmented-rnns/#attentional-interfaces)
There are two types of attention mechanisms in [2]. The type of attention that uses all encoder hidden states is also known as global attention, while local attention only uses a subset of encoder hidden states. This article mainly discusses global attention, so any reference to “attention” in this article refers to “global attention”.
This article applies animated forms to explain the attention mechanism, so we can better understand them without comprehending the mathematical formulas. In this case, the author will share four NMT architectures that have emerged in the past five years and provide some intuitive explanations of certain concepts in this article.
1. Overview of Attention
Before understanding attention, let’s first understand the principles behind the translation tasks using the seq2seq model.
seq2seq principle: The translator reads the German text from start to finish. After reading, it begins to translate the text into English word by word. If the sentence is very long, it may have already forgotten the earlier content.
This is a simple seq2seq model. The next section will introduce the attention layer computation steps of the seq2seq+attention model. Below is the intuitive principle of this model.
seq2seq+attention principle: The translator reads the German text from start to finish and records key words, then translates the text into English. When translating each German word, the translator uses the recorded keywords.
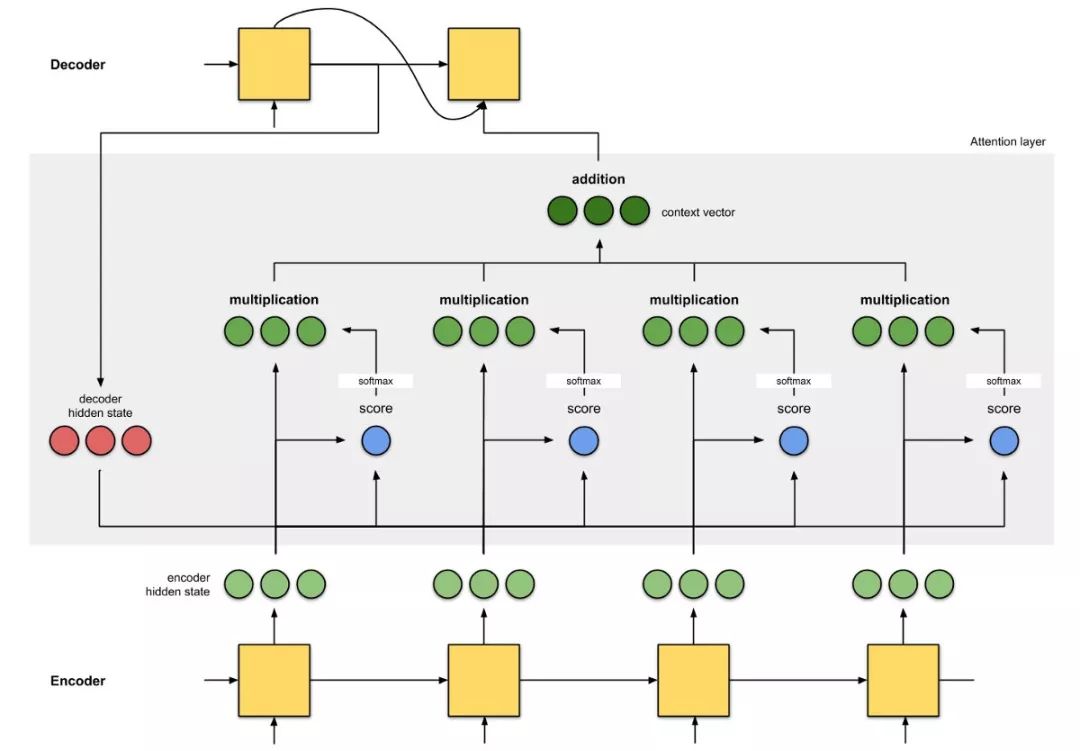
By assigning scores to each word, attention allocates different levels of focus to different words. Then, using softmax, the weighted sum of the encoder hidden states is calculated to obtain the context vector. The implementation of the attention layer can be divided into four steps.
Step 0: Prepare the hidden states.
First, prepare the first decoder hidden state (in red) and all available encoder hidden states (in green). The example has four encoder hidden states and the current decoder hidden state.
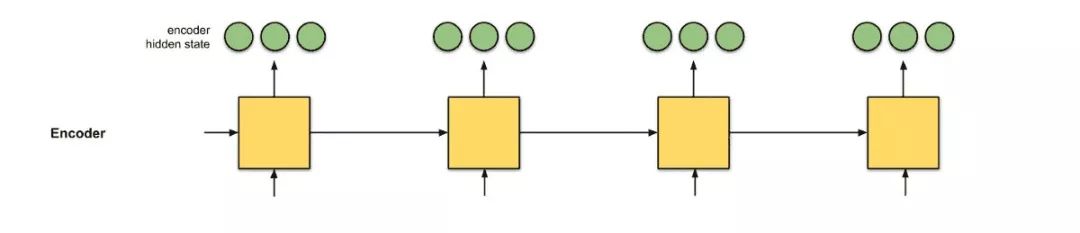
Figure 1.0: Preparing for attention.
Step 1: Obtain scores for each encoder hidden state.
Scores (scalars) are obtained via a scoring function (also known as an alignment scoring function [2] or alignment model [1]). In this example, the scoring function is the dot product between the decoder and encoder hidden states.
For various scoring functions, see Appendix A.
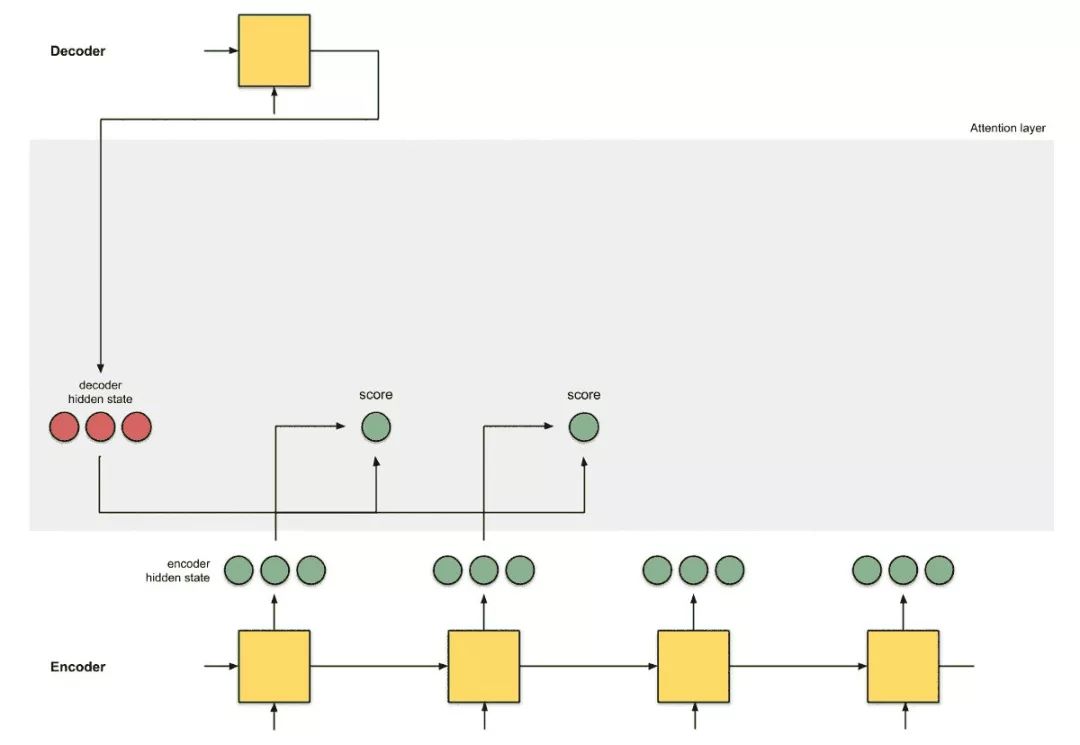
Figure 1.1: Obtaining scores.
*decoder_hidden *= [10, 5, 10]
*encoder_hidden score*
---------------------
[0, 1, 1] 15 (= 10×0 + 5×1 + 10×1, the dot product)
[5, 0, 1] 60
[1, 1, 0] 15
[0, 5, 1] 35In the example above, we obtained a high attention score of 60 for the encoder hidden state [5,0,1]. This means that the next word to be translated will be greatly influenced by this encoder hidden state.
Step 2: Run all scores through the softmax layer.
We place the scores into the softmax layer, and the softmaxed scores (scalars) sum to 1. These softmax scores represent the attention distribution [3, 10].

Figure 1.2: Obtaining softmax scores.
*encoder_hidden score score^*
-----------------------------
[0, 1, 1] 15 0
[5, 0, 1] 60 1
[1, 1, 0] 15 0
[0, 5, 1] 35 0Note that based on the softmax score score^, the attention distribution should be expected to be on [5, 0, 1]. In reality, these numbers are not binary but rather floating-point numbers between 0 and 1.
Step 3: Multiply each encoder hidden state by the softmax scores.
By multiplying each encoder hidden state by its softmax score (scalar), we obtain the alignment vector [2] or annotation vector [1]. This is precisely how alignment occurs.
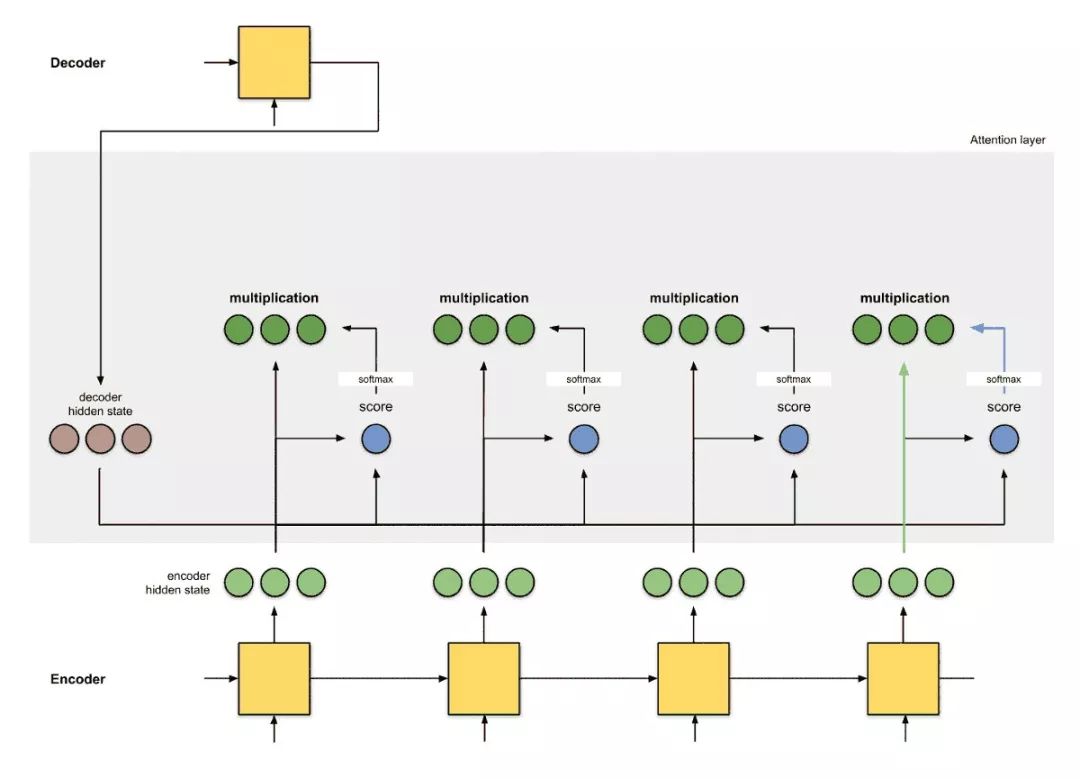
Figure 1.3: Obtaining the alignment vector.
*encoder_hidden score score^ alignment*
----------------------------------------
[0, 1, 1] 15 0 [0, 0, 0]
[5, 0, 1] 60 1 [5, 0, 1]
[1, 1, 0] 15 0 [0, 0, 0]
[0, 5, 1] 35 0 [0, 0, 0]Here, we see that all encoder hidden states except [5, 0, 1] have their alignment reduced to 0 due to low attention scores. This means that the first translated word should match the input word corresponding to the embedding [5, 0, 1].
Step 4: Sum the alignment vectors.
By summing the alignment vectors, we generate the context vector [1,2]. The context vector is a collection of information from the previous alignment vectors.

Figure 1.4: Obtaining the context vector.
*encoder_hidden score score^ alignment*
----------------------------------------
[0, 1, 1] 15 0 [0, 0, 0]
[5, 0, 1] 60 1 [5, 0, 1]
[1, 1, 0] 15 0 [0, 0, 0]
[0, 5, 1] 35 0 [0, 0, 0]
*context *= [0+5+0+0, 0+0+0+0, 0+1+0+0] = [5, 0, 1]Step 5: Input the context vector into the decoder.
The method depends on the architecture design. Different architectures will be seen in examples in sections 2a, 2b, and 2c on how they utilize the context vector in the decoder.
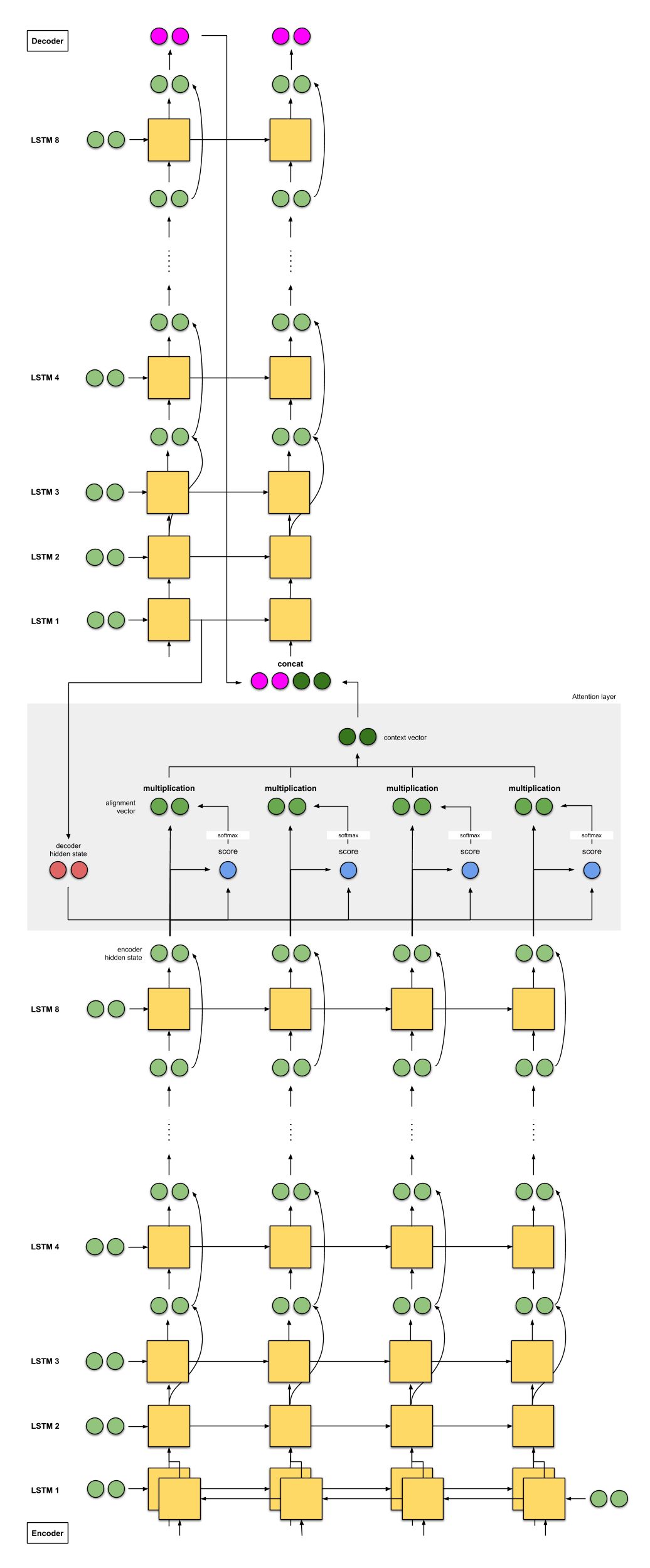
Figure 1.5: Inputting the context vector into the decoder.
At this point, all steps are complete. An animated example is shown in the figure:
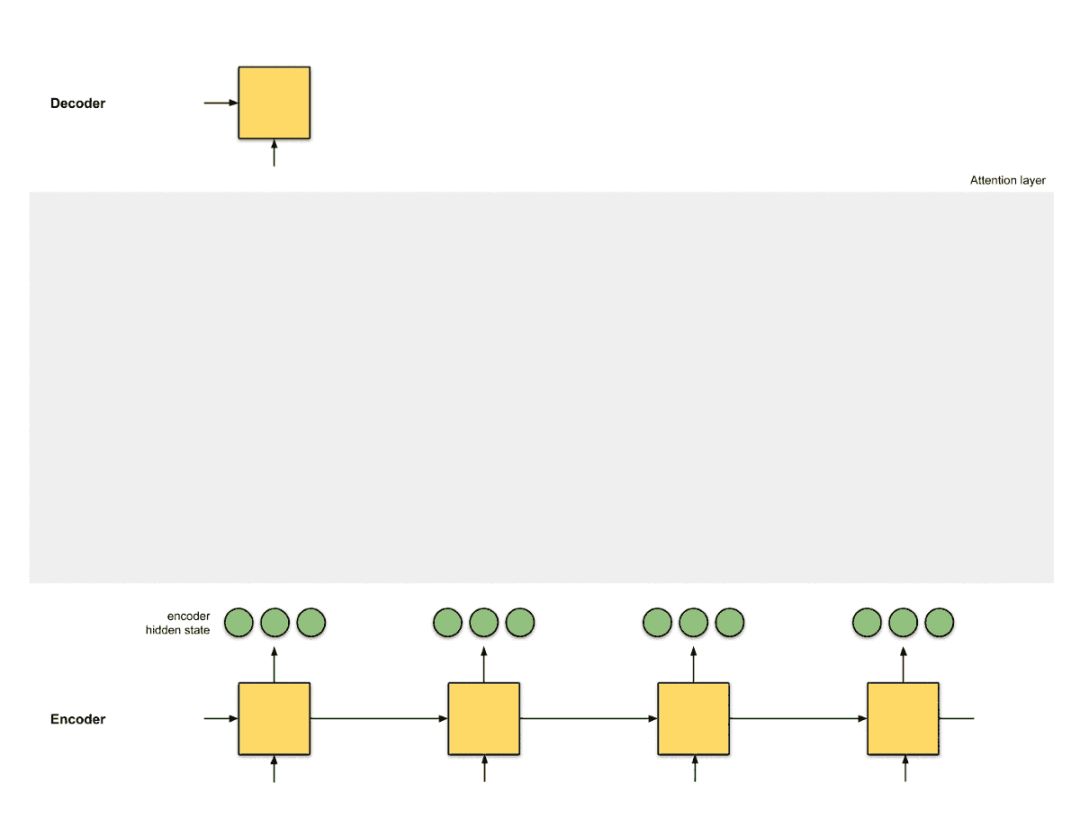
Figure 1.6: The Attention Mechanism
How does the attention mechanism work?
Answer: Backpropagation, that’s right, backpropagation! Backpropagation will do everything possible to ensure that the output matches the ground truth. This is achieved by changing the weights in the RNN and the scoring function (if any). These weights will affect both the encoder hidden states and the decoder hidden states, thereby affecting the attention scores.
2. Attention Examples
In the previous section, we have learned about the seq2seq and seq2seq+attention architectures. In the following subsections, we will explore three other attention-based NMT architectures based on seq2seq. For completeness, this article also includes their BLEU scores—a standard for evaluating generated sentences against reference sentences.
2a. Bahdanau et al. (2015)[1]
This article on attention implementation is a pioneering work in the field of attention. The authors used the term “align” in their paper “Neural Machine Translation by Learning to Jointly Align and Translate”, indicating that the weights adjusted during model training directly affect the scores. Below are the details of this architecture:
The encoder is a bidirectional (forward + backward) gated recurrent unit (BiGRU). The decoder is a GRU whose initial hidden state is derived from the last hidden state of the backward encoder GRU (not shown in the diagram below).
The scoring function in the attention layer is additive/concat.
The input to the next decoder step is the concatenation of the output from the previous decoder time step (in pink) and the context vector from the current time step (in deep green).
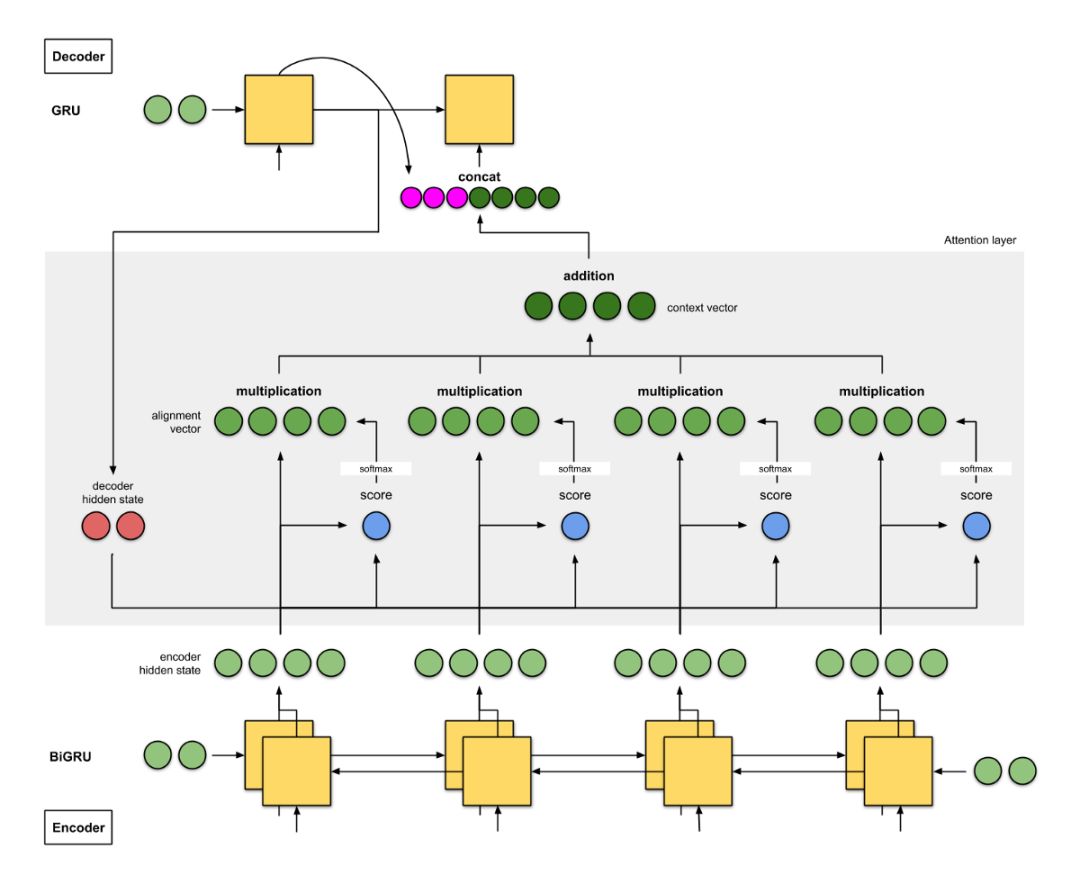
Figure 2a: NMT by Bahdanau et al. The encoder is BiGRU, and the decoder is GRU.
This architecture achieved a BLEU score of 26.75 on the WMT’14 English-French dataset.
seq2seq + attention architecture with a bidirectional encoder:
Translator A records keywords while reading the German text. Translator B (playing a more advanced role because it can read backward) reads the same German text from back to front while noting keywords. The two translators periodically “share” each word they read. After reading the entire German text, Translator B is responsible for translating the German sentence word by word based on the “shared results” and the comprehensive keywords they jointly selected.
Translator A is the forward RNN, and Translator B is the backward RNN.
2b. Luong et al. (2015)[2]
The authors of “Effective Approaches to Attention-based Neural Machine Translation” simplified and generalized Bahdanau’s architecture:
-
The encoder consists of two layers of long short-term memory (LSTM) networks. The decoder also has the same architecture, with its initial hidden state being the last encoder hidden state.
-
The scoring functions they used in their experiments are (i) additive/concat, (ii) dot product, (iii) location-based, and (iv) “general”.
-
The output from the current decoder time step is input into a feedforward neural network, concatenated with the context vector from the current time step, to obtain the final output of the current decoder time step (in pink).
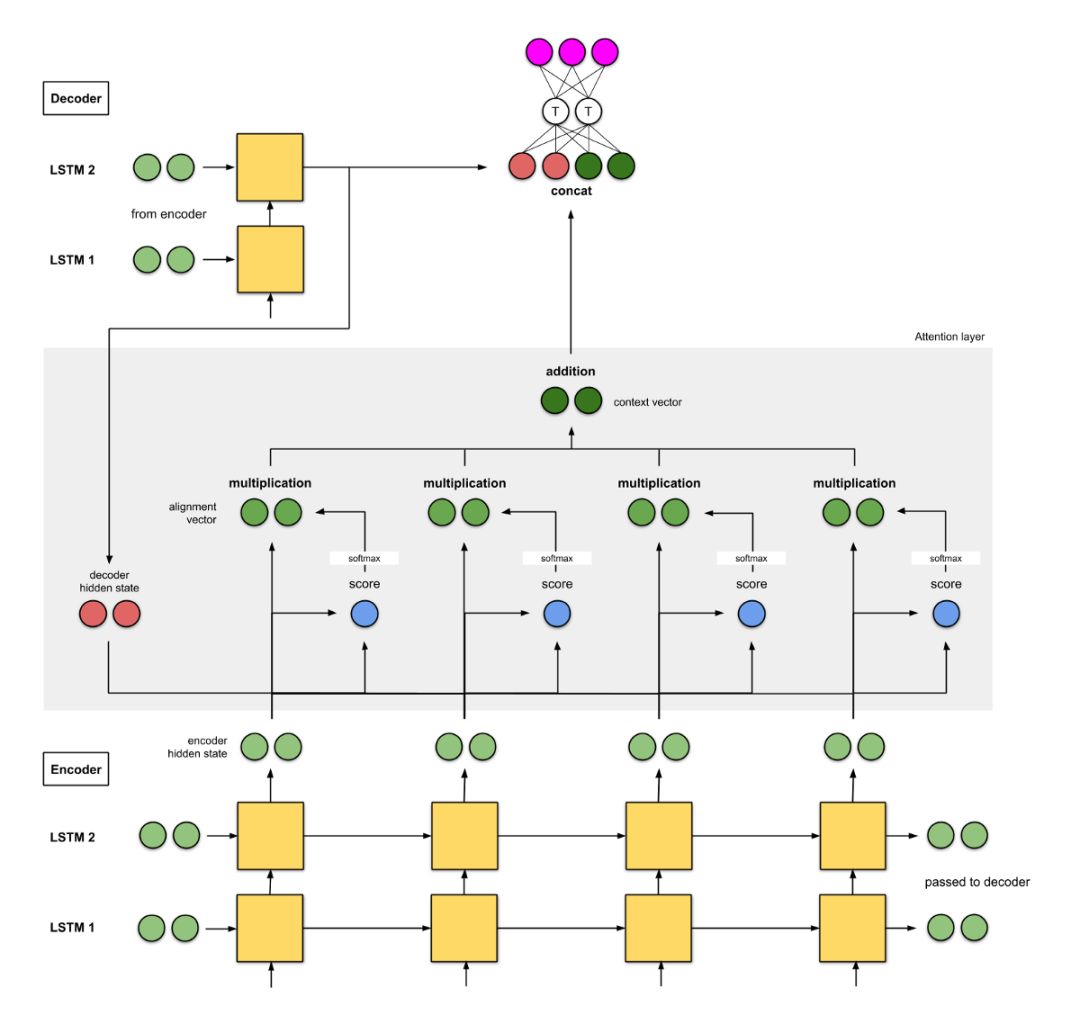
Figure 2b: NMT by Luong et al. The encoder and decoder are both 2-layer LSTM.
This model achieved a BLEU score of 25.9 on the WMT’15 English-German dataset.
seq2seq + attention architecture with a two-layer stacked encoder:
Translator A records keywords while reading the German text. Similarly, Translator B (more advanced than A) also reads the same German text while noting keywords. The lower-level Translator A reports to Translator B each word it reads. After finishing reading, they will translate the sentence word by word based on the comprehensive keywords they jointly selected.
2c. Google Neural Machine Translation (GNMT) [9]
Most of us have used Google Translate to some extent, so we must discuss GNMT, which Google implemented in 2016. GNMT is a combination of the first two examples (mainly inspired by the first example [1]).
The encoder consists of 8 LSTMs, the first of which is bidirectional (its output is concatenated), with residual connections between the outputs of consecutive layers (starting from the 3rd layer). The decoder is a stack of 8 unidirectional LSTMs.
The scoring function used is additive/concat, the same as in [1].
Similarly, as in [1], the input to the next decoder step is the concatenation of the output from the previous decoder time step (in pink) and the context vector from the current time step (in deep green).
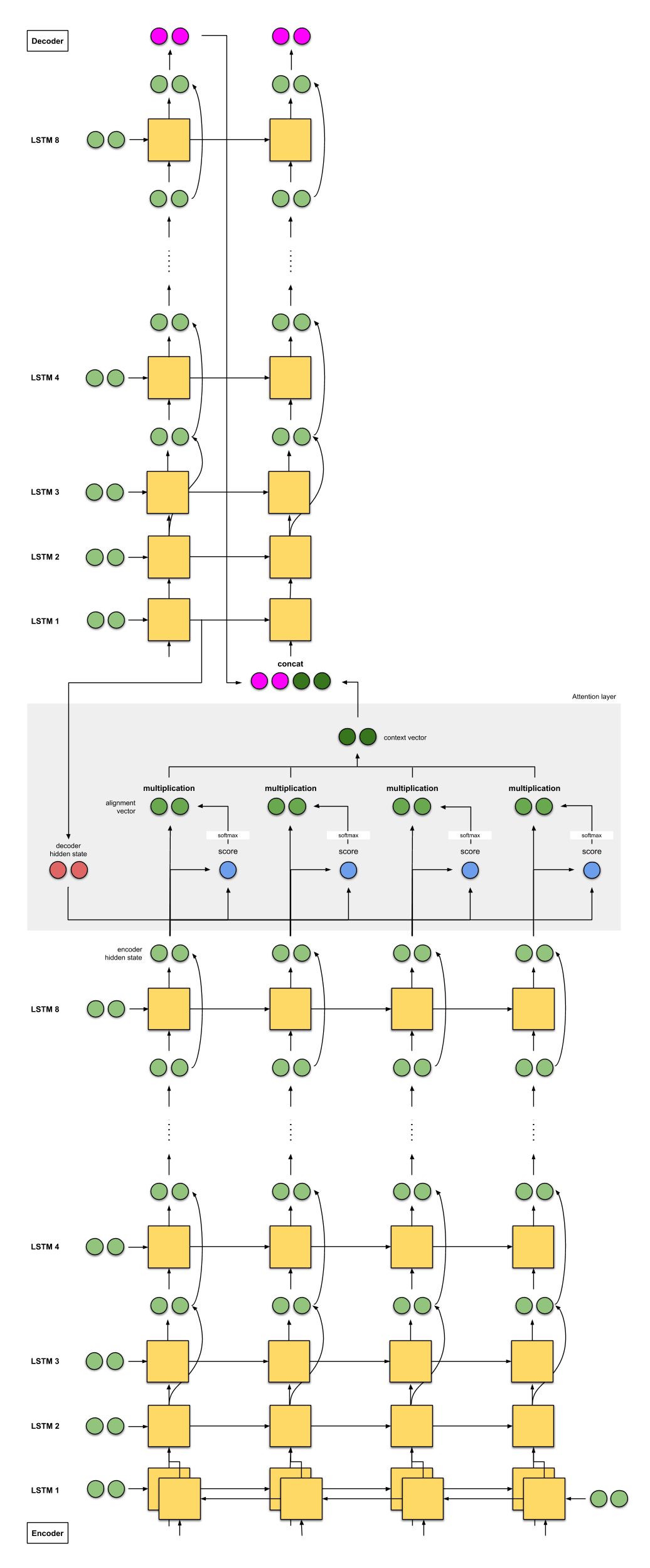
Figure 2c: NMT by Google. Skip connections are represented by curved arrows. Note: LSTM units only show hidden states and inputs, not cell state inputs.
This model achieved a BLEU score of 38.95 on the WMT’14 English-French dataset and 24.17 on the WMT’14 English-German dataset.
GNMT: seq2seq + attention with 8 stacked encoders (+ bidirectional + residual connections)
8 translators from A to H are lined up from top to bottom. Each translator reads the same German text. For each word, Translator A “shares” its findings with Translator B, which refines the answer and shares it with Translator C—this process repeats until it reaches Translator H. Additionally, while reading the German text, Translator H records relevant keywords based on what it knows and the information received.
Once each translator has finished reading the German text, Translator A will begin translating the first word. First, it recalls the original memory, then shares the answer with B, who improves the answer and shares it with C—this process continues until it reaches Translator H. Translator H writes the first translated word based on the keywords it recorded and the answers it received. This process repeats until all translations are completed.
3. Summary
This article introduced the following architectures:
-
seq2seq
-
seq2seq + attention
-
seq2seq + attention with a bidirectional encoder
-
seq2seq + attention with two-layer stacked encoders
-
GNMT: seq2seq + attention with 8 stacked encoders (+ bidirectional + residual connections)
Appendix: Scoring Functions
Below are some scoring functions written by Lilian Weng. This article mentions additive/concat and dot product. The idea behind scoring functions involving dot products (dot product, cosine similarity, etc.) is to measure the similarity between two vectors. For feedforward neural network scoring functions, the idea is to let the model learn alignment weights and translations.
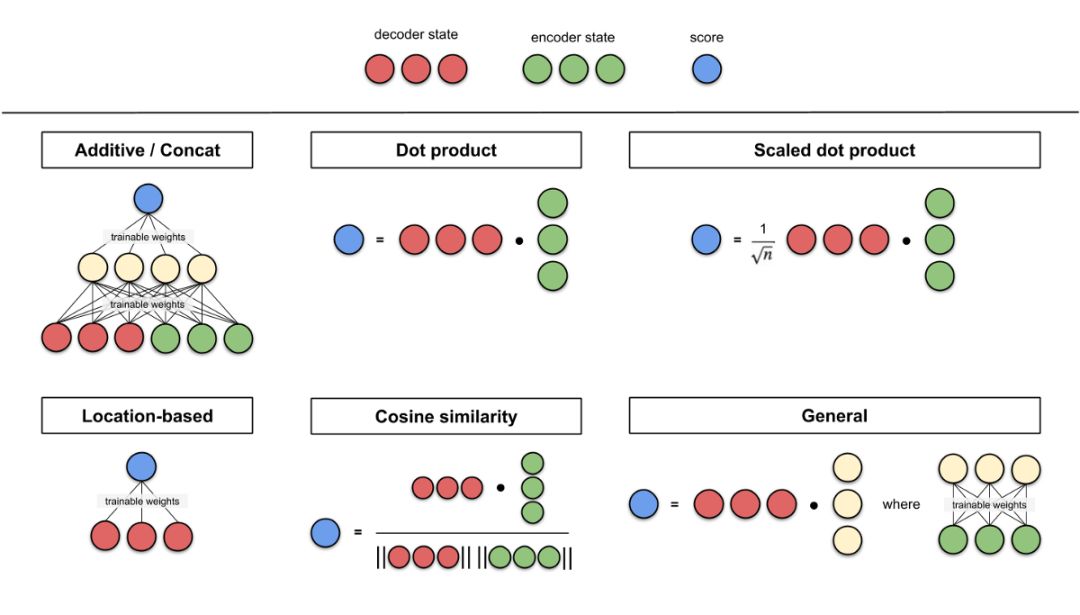
Figure A0: Summary of scoring function diagrams.

Figure A1: Summary of scoring function formulas.
Original link: https://towardsdatascience.com/attn-illustrated-attention-5ec4ad276ee3
This article is translated by Machine Heart, please contact this public account for authorization to reprint..
✄————————————————
Join Machine Heart (full-time reporter/intern): [email protected]
Submit articles or seek coverage: content@jiqizhixin.com
Advertising & business cooperation: [email protected]