
The Tongyi Qianwen team has launched the first MoE model in the Qwen series, Qwen1.5-MoE-A2.7B. It has only 2.7 billion activated parameters, but its performance can rival that of current state-of-the-art models with 7 billion parameters, such as Mistral 7B and Qwen1.5-7B. Compared to Qwen1.5-7B, which contains 6.5 billion Non-Embedding parameters, Qwen1.5-MoE-A2.7B has only 2 billion Non-Embedding parameters, about one-third of the original model size. Additionally, the training cost of Qwen1.5-MoE-A2.7B is reduced by 75% compared to Qwen1.5-7B, while the inference speed is improved by 1.74 times.
Model Structure
The Qwen1.5-MoE model adopts a specially designed MoE architecture. Typically, as shown in methods like Mixtral, the MoE layer in each transformer block is equipped with 8 experts and uses a top-2 gating strategy for routing. This configuration still has significant optimization potential. The architecture of Qwen1.5-MoE has undergone several improvements:
-
Fine-grained experts
-
Initialization
-
New routing mechanism
DeepSeek-MoE and DBRX have already demonstrated the effectiveness of fine-grained experts. When transitioning from the FFN layer to the MoE layer, it is generally just a matter of duplicating the FFN multiple times to create several experts. The goal of fine-grained experts is to generate more experts without increasing the number of parameters. To achieve this, the Qwen1.5-MoE model splits a single FFN into several parts, each serving as an independent expert. The Tongyi Qianwen team designed an MoE with a total of 64 experts, and compared to other configurations, they believe this implementation achieves optimal effectiveness and efficiency.
The model initialization phase is crucial. Initial experiments indicate that training an MoE model from scratch can be inefficient and difficult to bring to the expected optimal performance level. Therefore, the Tongyi Qianwen team first utilized the existing Qwen-1.8B and modified it into Qwen1.5-MoE-A2.7B. Furthermore, introducing randomness during the initialization phase can significantly accelerate convergence speed and lead to better overall performance during the entire pre-training process.
Currently, a clear trend is to achieve shared experts and routing experts in MoE. From a broader perspective, this is a generalized routing method because, without shared experts, it essentially degenerates into a traditional MoE routing setup. For the Qwen1.5-MoE-A2.7B model, the Tongyi Qianwen team integrated 4 always activated shared experts and 60 routing experts that activate only 4 at a time. This approach is very flexible and performs best in experiments.
Performance
To comprehensively evaluate and demonstrate the capabilities and advantages of Qwen1.5-MoE-A2.7B, assessments were conducted on both the base model and the chat model. For the base model, its language understanding, mathematical, and coding abilities were evaluated on MMLU, GSM8K, and HumanEval. Additionally, to assess its multilingual capabilities, it was tested on multilingual benchmark tests across various fields such as mathematics, comprehension, exams, and translation, using the evaluation methods of Qwen1.5, with comprehensive scores provided in the “Multilingual” column. For the chat model, traditional benchmark tests were not used; instead, MT-Bench was used for testing.
|
Model |
MMLU |
GSM8K |
HumanEval |
Multilingual |
MT-Bench |
|
Mistral-7B |
64.1 |
47.5 |
27.4 |
40.0 |
7.60 |
|
Gemma-7B |
64.6 |
50.9 |
|
||
|
Qwen1.5-7B |
61.0 |
62.5 |
36.0 |
45.2 |
7.60 |
|
DeepSeekMoE 16B |
45.0 |
18.8 |
26.8 |
6.93 |
|
|
Qwen1.5-MoE-A2.7B |
62.5 |
61.5 |
34.2 |
40.8 |
7.17 |
Qwen1.5-MoE-A2.7B achieved performance very close to the best 7B models. At the same time, it was also found that there is still room for improvement in the chat model aspect. The Tongyi Qianwen team will continue to research how to fine-tune the MoE model more effectively.
Training Costs and Inference Efficiency
The training costs of MoE models differ significantly from dense models. Although MoE models typically have more parameters, their training overhead can be significantly reduced due to their sparsity. First, let’s compare the three key parameters of each model, which are total parameter count, activated parameter count, and Non-embedding parameter count:
|
Model |
Parameters |
(Activated) Parameters |
(Activated) Non-embedding parameters |
|
Mistral-7B |
7.2 |
7.2 |
7.0 |
|
Gemma-7B |
8.5 |
7.8 |
7.8 |
|
Qwen1.5-7B |
7.7 |
7.7 |
6.4 |
|
DeepSeekMoE 16B |
16.4 |
2.8 |
2.4 |
|
Qwen1.5-MoE-A2.7B |
14.3 |
2.7 |
2.0 |
It is evident that although Qwen1.5-MoE has a larger total parameter count, the number of activated Non-embedding parameters is much lower than that of the 7B models. In practice, it has been observed that using Qwen1.5-MoE-A2.7B significantly reduced training costs by 75% compared to Qwen1.5-7B. Additionally, due to the initialization method of Qwen1.5-MoE, it does not require training the same number of tokens to achieve good model performance, which also significantly reduces training costs.
The following shows the performance test using a single NVIDIA A100-80G GPU for the Qwen1.5-7B and Qwen1.5-MoE-A2.7B models deployed with vLLM. In the experimental setup, the input token count is set to 1000 and the output token count is set to 1000, measuring performance through throughput (requests processed per second) and tokens per second (TPS):
|
Model |
Throughput |
TPS |
|
Qwen2-7B-Chat |
1.15 |
2298.89 |
|
Qwen1.5-MoE-A2.7B-Chat |
2.01 |
4010.27 |
Qwen1.5-MoE-A2.7B achieved a speed increase of about 1.74 times compared to Qwen1.5-7B. This acceleration is mainly due to the fact that MoE activates only a small portion of its total parameters during the forward process, thus reducing computational demands. Additionally, shared experts also enhance the inference efficiency of the model. Therefore, although MoE models increase memory requirements, they show significant advantages in throughput performance and inference speed.
English Common Sense & Inference Q&A Ability:
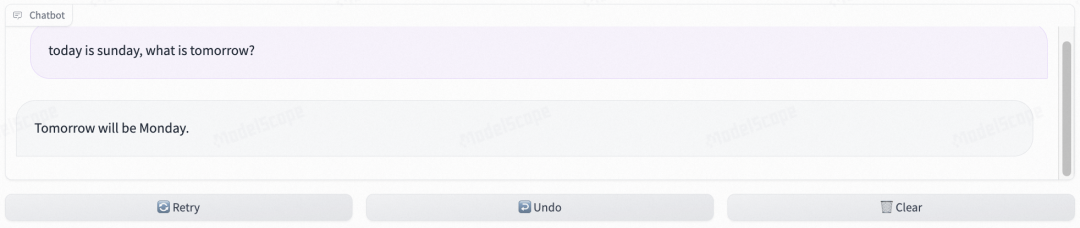
Chinese Writing Q&A Ability:

Mathematics: Can correctly answer both arithmetic and Chinese application problems
Arithmetic

Application Problems
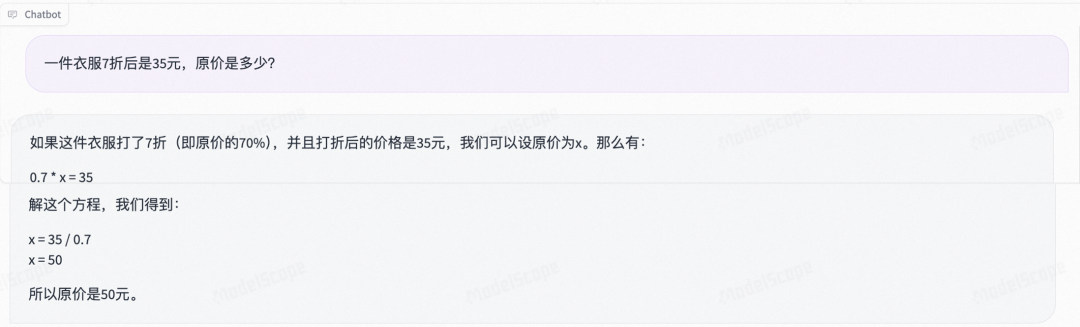
Qwen1.5-MoE Experience Link:
https://modelscope.cn/studios/qwen/qwen1.5-MoE-A2.7B-Chat-GPTQ-Int4-demo
-
Python version 3.8 and above
-
Pytorch version 1.12 and above, recommended 2.0 and above
-
It is recommended to use CUDA 11.4 and above
-
Depend on the latest Transformers code
Usage Steps
This article mainly demonstrates the Qwen1.5-MoE dialogue model, used in the free computing power PAI-DSW of Modao
The Qwen1.5-MoE model series is now open source in the ModelScope community, including:
Qwen1.5-MoE-A2.7B-Chat:https://modelscope.cn/models/qwen/Qwen1.5-MoE-A2.7B-Chat
Qwen1.5-MoE-A2.7B-Chat-GPTQ-Int4:https://modelscope.cn/models/qwen/Qwen1.5-MoE-A2.7B-Chat-GPTQ-Int4
Qwen1.5-MoE-A2.7B:https://modelscope.cn/models/qwen/Qwen1.5-MoE-A2.7B
The community supports direct download of the model’s repo:
from modelscope import snapshot_download
model_dir = snapshot_download("qwen/Qwen1.5-MoE-A2.7B-Chat")The inference code for Qwen1.5-MoE-A2.7B-Chat-GPTQ-Int4, Qwen1.5-MoE has been integrated into the latest official code of HuggingFace’s transformers
from modelscope import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained( "qwen/Qwen1.5-MoE-A2.7B-Chat-GPTQ-Int4", torch_dtype="auto", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("qwen/Qwen1.5-MoE-A2.7B-Chat-GPTQ-Int4")
prompt = "Give me a short introduction to large language model."
messages = [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate( model_inputs.input_ids, max_new_tokens=512)
generated_ids = [ output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
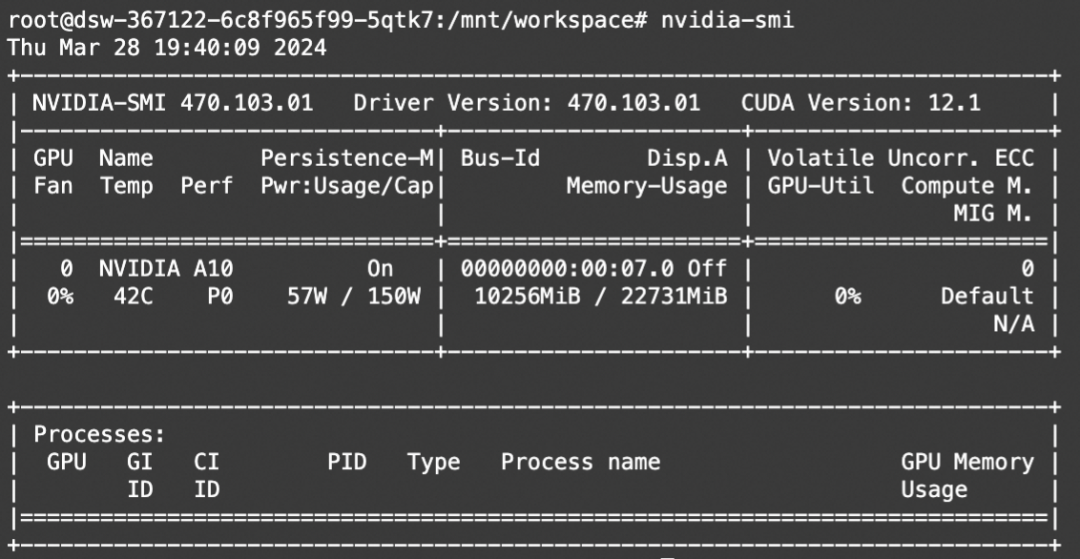
print(response)Resource Consumption (10G):
Qwen1.5-MoE-A2.7B-Chat using vLLM to accelerate inference:
To use vLLM to accelerate model inference, install vLLM from the source code:
git clone https://github.com/wenyujin333/vllm.git
cd vllm
git checkout add_qwen_moe
pip install -e .Set the environment variable VLLM_USE_MODELSCOPE to True, and download the model from ModelScope:
export VLLM_USE_MODELSCOPE=TrueThe following example illustrates how to use vLLM to build an OpenAI-API interface compatible with Qwen-MoE:
python -m vllm.entrypoints.openai.api_server --model qwen/Qwen1.5-MoE-A2.7B-Chatcurl http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "qwen/Qwen1.5-MoE-A2.7B-Chat", "messages": [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Tell me something about large language models."} ] }'The Qwen1.5-MoE model will continue to update support for third-party frameworks, including llama.cpp, MLX, etc.
We use SWIFT to fine-tune the model, which is the official LLM & AIGC model fine-tuning inference framework provided by the Modao community.
Fine-tuning code open source address: https://github.com/modelscope/swift
We use the blossom-math-zh dataset for fine-tuning, with the task being: solve math problems
Environment Preparation:
git clone https://github.com/modelscope/swift.git
cd swift
pip install .[llm]Fine-tuning Script: LoRA
# https://github.com/modelscope/swift/blob/main/examples/pytorch/llm/scripts/qwen1half-moe-a2_7b-chat/lora/sft.sh
# Experimental environment: A100
# 42GB GPU memory
PYTHONPATH=../../.. \CUDA_VISIBLE_DEVICES=0 \python llm_sft.py \ --model_type qwen1half-moe-a2_7b-chat \ --sft_type lora \ --tuner_backend swift \ --dtype AUTO \ --output_dir output \ --dataset dureader-robust-zh \ --train_dataset_sample 10000 \ --num_train_epochs 1 \ --max_length 1024 \ --check_dataset_strategy warning \ --lora_rank 8 \ --lora_alpha 32 \ --lora_dropout_p 0.05 \ --lora_target_modules ALL \ --gradient_checkpointing true \ --batch_size 1 \ --weight_decay 0.1 \ --learning_rate 1e-4 \ --gradient_accumulation_steps 16 \ --max_grad_norm 0.5 \ --warmup_ratio 0.03 \ --eval_steps 100 \ --save_steps 100 \ --save_total_limit 2 \ --logging_steps 10 \ --use_flash_attn true \ --self_cognition_sample 1000 \ --model_name 卡卡罗特 \ --model_author 陶白白 \ The training process also supports local datasets, requiring the following parameters to be specified:
--custom_train_dataset_path xxx.jsonl \--custom_val_dataset_path yyy.jsonl \The format for custom datasets can refer to:
https://github.com/modelscope/swift/blob/main/docs/source/LLM/%E8%87%AA%E5%AE%9A%E4%B9%89%E4%B8%8E%E6%8B%93%E5%B1%95.md#%E6%B3%A8%E5%86%8C%E6%95%B0%E6%8D%AE%E9%9B%86%E7%9A%84%E6%96%B9%E5%BC%8F
Post-fine-tuning Inference Script:
(Here, the ckpt_dir needs to be modified to the checkpoint folder generated during training)
# Experimental environment: A100
# 3GB GPU memory
PYTHONPATH=../../.. \CUDA_VISIBLE_DEVICES=0 \python llm_infer.py \ --ckpt_dir "output/qwen1half-moe-a2_7b-chat/vx-xxx/checkpoint-xxx" \ --load_dataset_config true \ --use_flash_attn true \ --max_new_tokens 2048 \ --temperature 0.1 \ --top_p 0.7 \ --repetition_penalty 1. \ --do_sample true \ --merge_lora false \Visualization Results of Fine-tuning
Training loss:
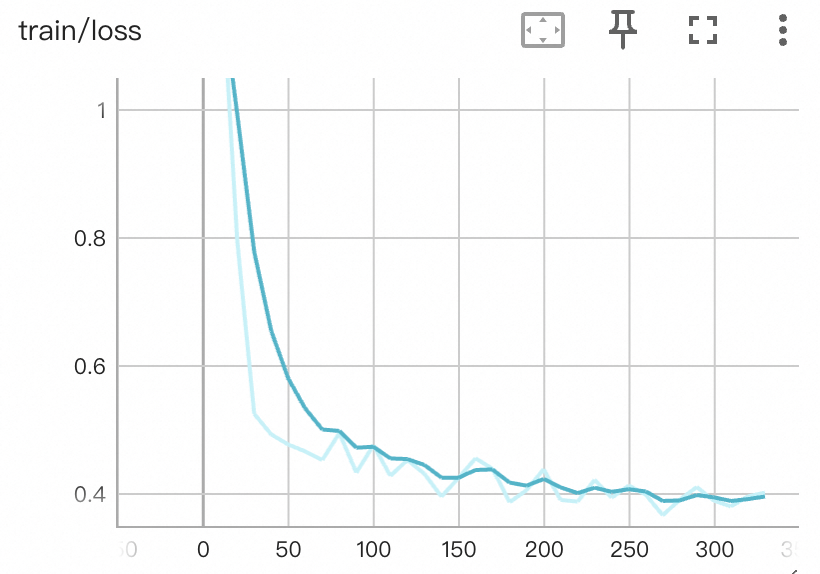
Sample Outputs after Training:
[PROMPT]<|im_start|>systemYou are a helpful assistant.<|im_end|><|im_start|>user学校需新添28套课桌椅,共付款1820元,椅子每把17元,课桌每张多少元?<|im_end|><|im_start|>assistant[OUTPUT]设课桌每张x元。根据题意,椅子每把17元,课桌每张x元。则椅子的总费用为17元/把 × 28把 = 476元。课桌的总费用为x元/张 × 28张 = 28x元。根据题意,课桌和椅子的总费用为1820元。所以,28x + 476 = 1820。解方程得:28x = 1820 - 476 = 1344。x = 1344 / 28 = 48。所以,课桌每张48元。
Answer: 48<|im_end|>
[LABELS]假设课桌的价格为x元每张。根据题意可得方程:28(17+x) = 1820化简得:476 + 28x = 1820移项得:28x = 1820 - 476化简得:28x = 1344将等式两边同时除以28,得:x = 1344 / 28化简得:x = 48所以,每张课桌的价格为48元。
Answer: 48--------------------------------------------------[PROMPT]<|im_start|>systemYou are a helpful assistant.<|im_end|><|im_start|>user甲数是18,乙数比甲数的2倍少5,乙数=.<|im_end|><|im_start|>assistant[OUTPUT]设乙数为x,则根据题意可得:x = 2 * 18 - 5x = 36 - 5x = 31所以乙数为31。
Answer: 31<|im_end|>
[LABELS]首先,让我们用变量来表示甲数和乙数。甲数 = 18乙数 = 2 * 甲数 - 5将甲数的值代入乙数的表达式中,我们得到:乙数 = 2 * 18 - 5 = 36 - 5 = 31所以,乙数=31。
Answer: 31Resource Consumption
Fine-tuning

Click Read Full Text to reach the creative space directly