

Introduction
Official Documentation: Qwen1.5-MoE: Achieving the Performance of 7B Models with 1/3 Activation Parameters | Qwen
On March 28, Alibaba announced the open-source MoE technology large model Qwen1.5-MoE-A2.7B for the first time. This model is based on the existing Qwen-1.8B model. The activation parameters of Qwen1.5-MoE-A2.7B are 270 million, but it can achieve the performance of the 7B model in a series of benchmark evaluations. Additionally, it has significant advantages in training costs and inference speed compared to the 7B model. According to official evaluations, Qwen1.5-MoE-A2.7B achieved performance very close to the best 7B model. This article will interpret Qwen1.5-MoE-A2.7B based on official blog content and open code.
The structure of the article is as follows:
Parameter Count
Qwen1.5-MoE-A2.7B has only 270 million activation parameters, yet its performance rivals that of the current state-of-the-art 700 million parameter models, such as Mistral 7B and Qwen1.5-7B. Compared to Qwen1.5-7B, which has 6.5 billion Non-Embedding parameters, Qwen1.5-MoE-A2.7B has only 2 billion Non-Embedding parameters, about one-third of the original model size. Furthermore, compared to Qwen1.5-7B, the training cost of Qwen1.5-MoE-A2.7B is reduced by 75%, and inference speed is improved by 1.74 times.
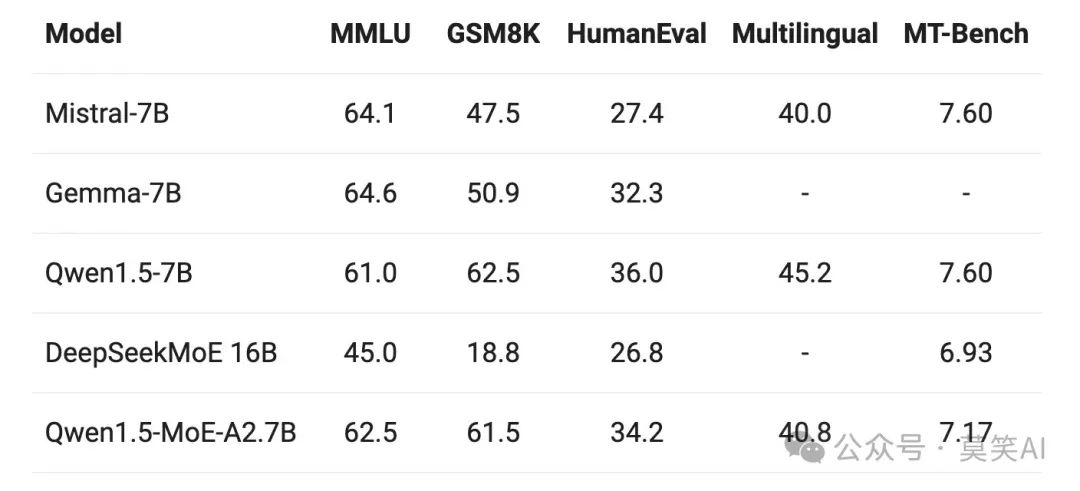
Qwen1.5-MoE-A2.7B achieved performance very close to the best 7B model.
Model Structure
The Qwen1.5-MoE model employs a specially designed MoE architecture. Typically, as shown in methods like Mixtral, the MoE layer in each transformer block is equipped with 8 experts and uses a top-2 gating strategy for routing. This configuration still has significant optimization potential. Qwen1.5-MoE has made several improvements to this architecture:
-
Fine-grained experts -
Initialization -
New routing mechanism
DeepSeek-MoE and DBRX have proven the effectiveness of fine-grained experts. When transitioning from the FFN layer to the MoE layer, we generally just replicate the FFN multiple times to achieve multiple experts. The goal of fine-grained experts is to generate more experts without increasing the number of parameters. To achieve this, we split a single FFN into several parts, each part acting as an independent expert. We designed an MoE with a total of 64 experts, and compared to other configurations, we believe this implementation achieves optimal effectiveness and efficiency.
The model initialization phase is crucial. Preliminary experiments indicate that training an MoE model from scratch can be inefficient and difficult to reach the expected optimal performance level. Therefore, we initially used the existing Qwen-1.8B and modified it into Qwen1.5-MoE-A2.7B. Furthermore, introducing randomness during the initialization phase can significantly accelerate convergence speed and improve overall performance during the entire pre-training process.
Currently, a noticeable trend is to implement shared experts and routing experts in MoE. From a broader perspective, this is a generalized routing method, as without shared experts, it effectively degenerates into traditional MoE routing settings. For the Qwen1.5-MoE-A2.7B model, we integrated 4 shared experts that are always activated and 60 routing experts that activate only 4 at a time. This method is highly flexible and has shown the best efficiency in our experiments.
-
“Similar” 8*1.8B TOP2 activation MOE: The term