
Alibaba Sister’s Guide
1. About DeepSeek Company and Its Large Model
1.1 Company Overview
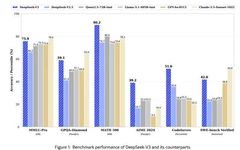
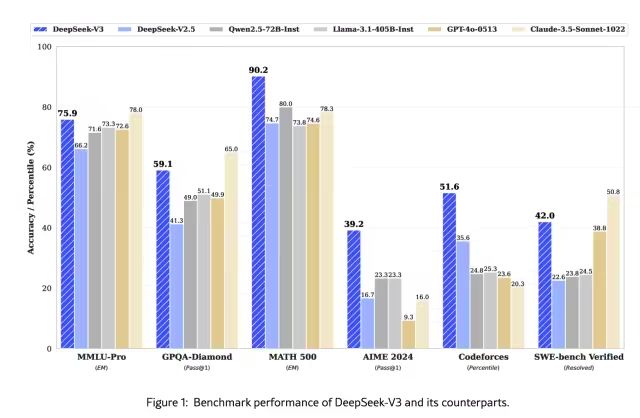
1.2 Model Capabilities
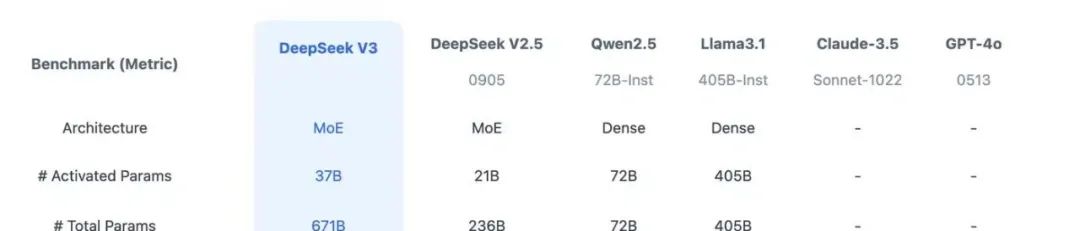
1.3 Training and Inference Costs
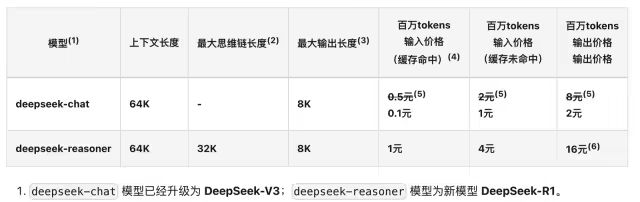
1. In the pre-training phase, to train V3 with one trillion tokens, 2048 H800 GPU clusters are used, requiring only 180k H800 GPU hours, approximately 3.7 days (180000/2048/24)
2. The total pre-training time is 2664K GPU hours (less than 2 months), and with context expansion and post-training, the total time is approximately 2788K GPU hours.
3. Based on H800’s rental cost of 2 USD per hour, the total training cost does not exceed 6 million USD.

2. Core Technologies for DeepSeek Training and Inference
2.1 DeepSeek-V3 Model Network Architecture
DeepSeek V3 used 148 trillion high-quality tokens for overall pre-training, and later conducted SFT and RL, achieving a model parameter count of 671B, but only activating 37B parameters for each token. To achieve efficient inference and training, DeepSeek V3 has self-developed the MLA attention mechanism and the MoE architecture with no auxiliary loss load balancing strategy.
From the technical report, it is evident that it uses the classic Transformer architecture, with notable features being the use of DeepSeek MoE architecture for the feedforward network and the MLA architecture for the attention mechanism, both of which had been validated in the DeepSeek V2 model.
Compared to DeepSeek-V2, V3 additionally introduces a no auxiliary loss load balancing strategy to DeepSeek MoE, to alleviate performance degradation caused by the need to ensure expert load balancing.
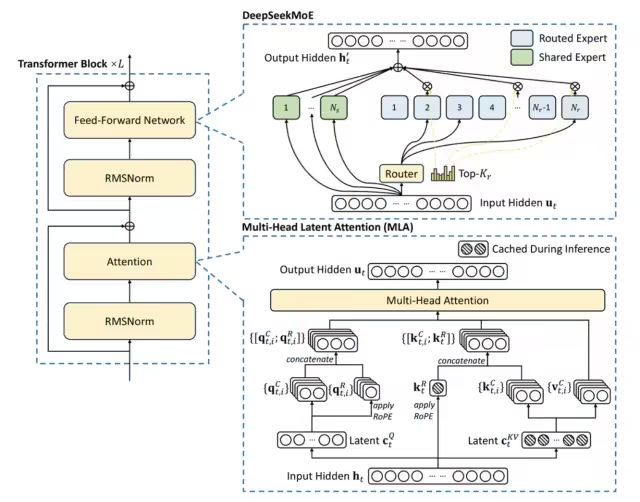
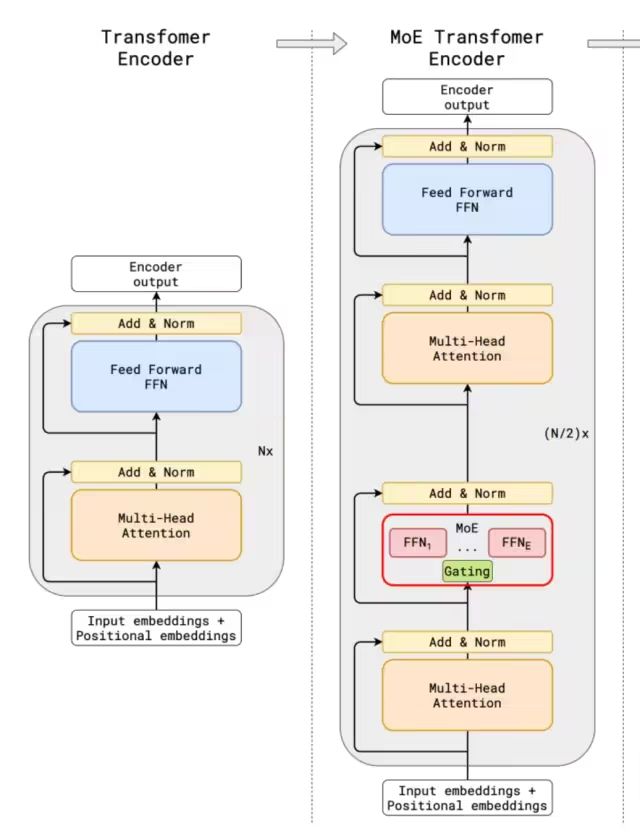
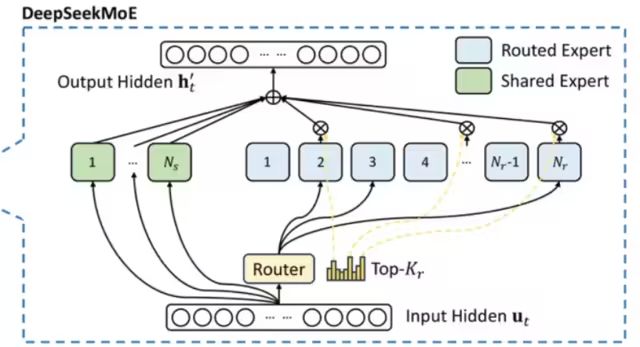
2.1.1 DeepSeek MoE
●Sparse MoE Layer: These layers replace the feedforward network (FFN) layers in traditional Transformer models. The MoE layer contains several “experts” (for example, 8), each expert being an independent neural network. In practical applications, these experts are usually feedforward networks (FFN), but they can also be more complex network structures or even the MoE layer itself, forming a hierarchical MoE structure.
●Gating Network or Routing: This part is used to determine which tokens are sent to which experts. The routing of tokens is a key point in the use of MoE, as the router consists of learned parameters and is pre-trained together with the rest of the network.
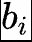 , and adding it to the corresponding affinity scores
, and adding it to the corresponding affinity scores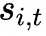 to determine top-K routing. Specifically, if the corresponding expert is overloaded, we reduce the bias term by γ; if the corresponding expert is underloaded, we increase the bias term by γ, where γ is a hyperparameter known as the bias update speed.
to determine top-K routing. Specifically, if the corresponding expert is overloaded, we reduce the bias term by γ; if the corresponding expert is underloaded, we increase the bias term by γ, where γ is a hyperparameter known as the bias update speed.The gating network is essentially a softmax layered on top of a classification network, and the auxiliary loss is often just a penalty term added to large logits outputs to encourage the model to generate more moderate logits values, preventing the model from generating overly extreme outputs.
2.1.2 MLA Multi-Head Latent Attention
The KV cache mechanism in large model inference processes is generally a major bottleneck in inference efficiency, while the MHA architecture in the standard Transformer architecture produces a large amount of KV cache. To reduce the corresponding KV cache, the industry has experimented with various solutions such as Paged Attention, Multi-query Attention (MQA), and Grouped Query Attention (GQA), but their performance lags behind the native MHA.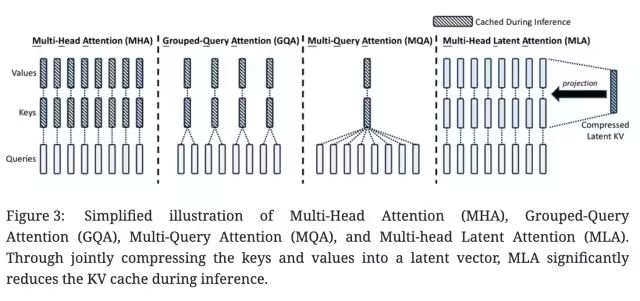
In DeepSeek-V2, an innovative attention mechanism was proposed: Multi-Head Latent Attention (MLA).
Compared to MQA’s shared KV and GQA’s grouped KV, the core of MLA is the low-rank joint compression of attention keys and values to reduce the KV cache during the inference process. MLA has better performance compared to MHA, but requires much less KV cache.

Low-rank matrices are those whose rank is far less than their number of rows and columns.
Suppose we have a matrix whose actual structure allows it to be expressed as the product of two smaller matrices. This usually indicates that the original matrix is low-rank.
Assuming we have a
<span>4×5</span>matrix<span>A</span>, this matrix can be represented as the product of two smaller matrices, such as a<span>4×2</span>matrix<span>B</span>and a<span>2×5</span>matrix<span>C</span>. This means that the information of the original matrix<span>A</span>can be captured through these two smaller matrices, indicating that<span>A</span>is a low-rank matrix.
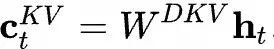
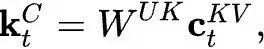
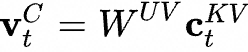
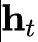 represents the input of the t-th token,
represents the input of the t-th token,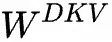 represents the down-projection matrix of KV, which compresses
represents the down-projection matrix of KV, which compresses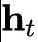 to obtain
to obtain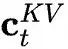 which is the KV compressed latent vector to be cached;
which is the KV compressed latent vector to be cached;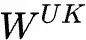 and
and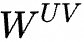 is the up-projection matrix that restores the compressed latent vector of the token
is the up-projection matrix that restores the compressed latent vector of the token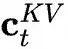 back to the original KV matrix;
back to the original KV matrix;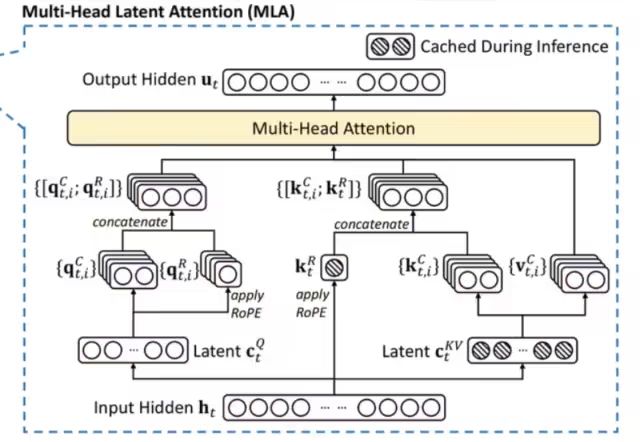
MLA Module Architecture Diagram
For specific attention calculation derivation processes, please refer to: MLA Derivation Details
2.2 Core Technologies for Training and Inference
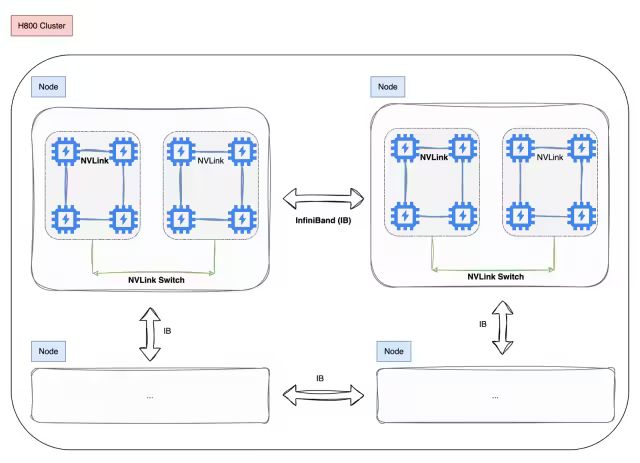
DeepSeek-V3 is trained on a cluster equipped with 2048 NVIDIA H800 GPUs, using a self-developed HAI-LLM framework, which implements four types of parallel training methods: Data parallelism supported by ZeRO, pipeline parallelism, tensor slicing model parallelism, and sequence parallelism.
This parallel capability supports the demands of different workloads, accommodating ultra-large models on the scale of trillions and scaling up to thousands of GPUs. It has also developed some high-performance operators called haiscale, which greatly optimize the memory efficiency and computational efficiency of large model training.
i. Communication-computation overlap optimization
DeepSeek-V3 applied 16-way pipeline parallelism (PP), 64-way expert parallelism (EP) across 8 nodes, and ZeRO-1 data parallelism (DP).
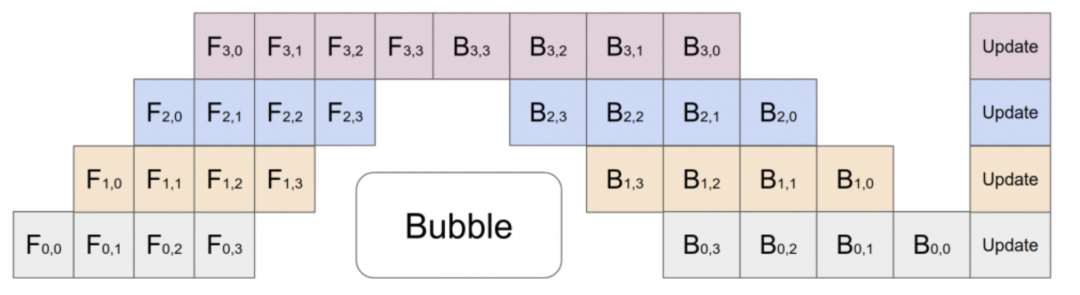
Compared to existing pipeline parallel methods, DualPipe has fewer pipeline bubbles. It also overlaps the computation and communication phases in the forward and backward processes, addressing the heavy communication overhead challenges introduced by cross-node expert parallelism.
The key idea of DualPipe is to overlap the computations and communications in a pair of separate forward and backward blocks: dividing each block into four components: attention, all-to-all scheduling, MLP, and all-to-all combination
For example, suppose we have two computation blocks, A and B:
1. While performing forward propagation computations in block A, the backward propagation communication process of block B can occur simultaneously.
2. When block A completes its forward propagation computation, it starts its communication process; while block B begins its forward propagation computation.


● Computation-Communication Overlap
In large-scale distributed training processes in deep learning, the speed of communication often lags behind that of computation. How to perform some computations during the communication gap is a key factor for achieving efficient training.
● Pipeline Parallel Bubble Problem
Some large models adopt a pipeline parallel strategy, placing different layers of the model on different GPUs. However, dependencies exist between different layers, and later layers must wait for earlier computations to finish, causing GPUs to be idle for a period of time, as shown in the figure below:
During the scheduling process, (1) IB sending, (2) IB to NVLink forwarding, and (3) NVLink receiving are handled by their respective warps. The number of warps allocated to each communication task is dynamically adjusted based on the actual workload across all SMs.
During the merging process, (1) NVLink sending, (2) NVLink to IB forwarding and accumulation, and (3) IB receiving and accumulation are also handled by dynamically adjusted warps.
DSV3 adopts a MoE architecture with 1 shared expert and 256 routing experts, where each token activates 8 routing experts.
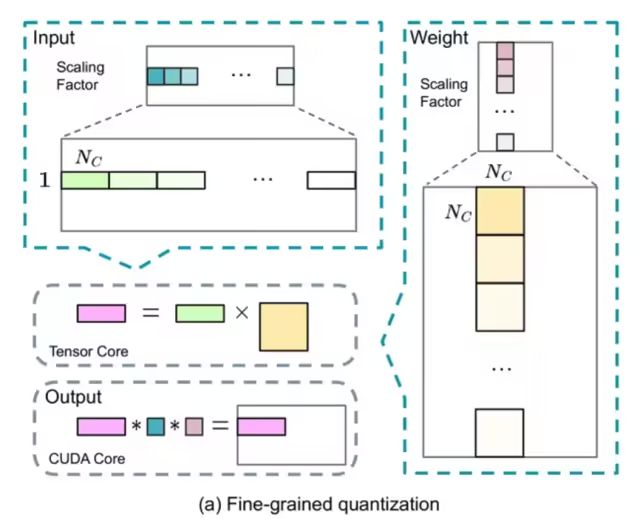
2.2.3 Mixed Precision Framework for FP8 Training
For activations, group-wise quantization is adopted on the token dimension (1*128); for weights, block-wise quantization of 128*128 is used.
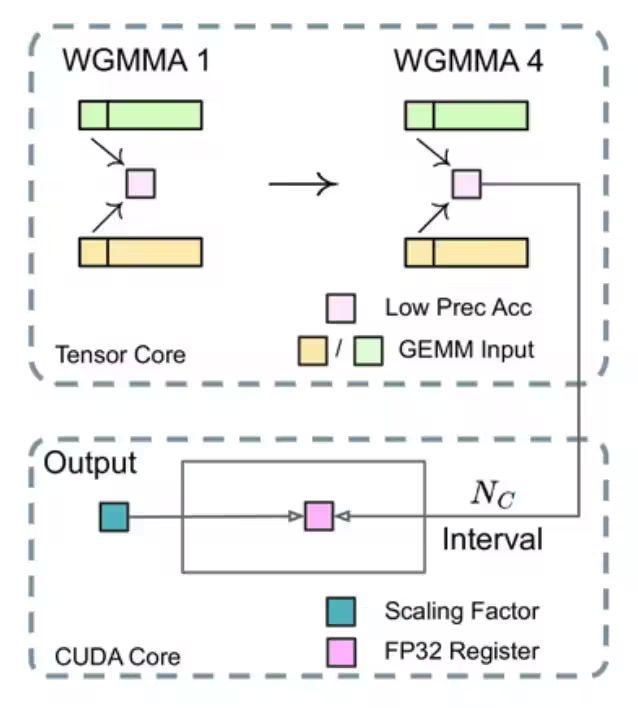
When executing matrix MMA (matrix multiplication accumulation) operations on TensorCore, whenever accumulation reaches an interval, these partial results are transferred to FP32 registers on CUDA Cores and accumulated there in FP32 precision.
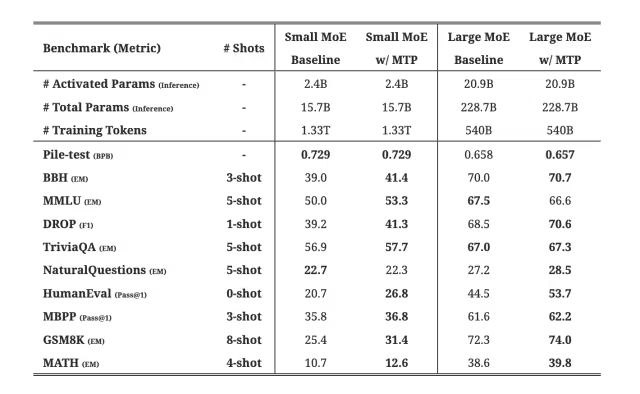
2.2.4 MTP Training Objectives
DeepSeek V3 sets a multi-token prediction objective during the training process. According to the ablation experiments in the technical report, this indeed improves the model’s performance on most evaluation benchmarks, and the MTP module can also be used for inference acceleration.
2.2.5 Inference Deployment Scheme
DeepSeek-V3 has a total parameter count of 671B. Let’s take a look at one of its deployment schemes:
The inference deployment adopts a strategy of separating pre-filling (Prefilling) and decoding (Decoding), ensuring high throughput and low latency for online services. Through redundant expert deployment and dynamic routing strategies, the model maintains efficient load balancing during inference.
The entire deployment scheme is essentially cross-machine distributed inference.
2.2.5.1 Prefill Phase
This phase simply processes user prompts in parallel, converting them into KV Cache.
The minimum deployment unit of the prefill phase consists of 4 nodes, each equipped with 32 GPUs. The attention part adopts 4-way tensor parallelism (TP4) and sequence parallelism (SP), combined with 8-way data parallelism (DP8). Its smaller TP scale (4-way) limits the communication overhead of TP. For the MoE part, we use 32-way expert parallelism (EP32).
2.2.5.2 Decoder Phase
This phase performs autoregressive output for each token..
The minimum deployment unit of the decoding phase consists of 40 nodes and 320 GPUs. The attention part adopts TP4 and SP, combined with DP80, while the MoE part uses EP320. For the MoE part, each GPU carries only one expert, and 64 GPUs are responsible for carrying redundant and shared experts.
Conclusion: Why is DeepSeek V3’s Training Cost So Low?
3. Why DeepSeek?
In Silicon Valley, innovations like DeepSeek are not uncommon; however, this time it is a Chinese company making this move, which is particularly exciting compared to the traditional ‘American innovation, Chinese application’ model.
1. Large models are a knowledge-intensive industry; how to organize high-density talent? Clearly, DeepSeek has achieved this.
2. Large model technology is not magic; more often, it tests foundational skills and drive.
3. Not prioritizing commercialization allows for a lighter approach.
4. Some Personal Thoughts
1. In the long run, there may be dedicated chips tailored for Transformer architectures, just like ASIC chips designed for convolution.
2. Multi-token prediction and MoE architecture may remain popular research directions for large model training and inference for a long time.
3. In China, AI applications will always have more market presence than fundamental research, but the gap in foundational innovation with overseas will continue to narrow.
4. Large model training and inference represent a collaborative ecosystem of software and hardware; the emergence of DeepSeek will promote faster and lower-cost iterations across the entire AI industry.
5. Time is quite tight, and many technical details are worth studying deeply; if there are errors, please don’t criticize~