
Today, we share with you the latest paper from Alibaba Cloud Tongyi Qianwen team – Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models
(Original paper link: https://arxiv.org/abs/2501.11873)
This paper focuses on improving the training method of Mixture-of-Experts (MoEs) by relaxing local balance to global balance through lightweight communication, significantly enhancing both the performance of MoE models and the specificity of experts.
Key Issues in MoE Model Training
Mixture-of-Experts (MoEs) dynamically and sparsely activate model parameters through a routing mechanism, enabling efficient scaling of model parameters. The sparse activation based on the TopK mechanism encounters the problem of imbalanced expert activation during training: a few frequently selected experts get optimized more, leading to their more frequent selection, ultimately resulting in only a few experts being chosen and causing redundancy in the remaining experts. Therefore, MoE requires the introduction of an additional auxiliary load balancing loss (LBL) during training to encourage a more balanced selection of experts.
The mainstream MoE training frameworks currently implement LBL with the optimization goal of local (micro-batch) load balancing, which requires the model to evenly distribute the inputs of a micro-batch across different experts. However, the inputs of a micro-batch often come from a specific domain, and local load balancing causes the model to evenly distribute inputs from each domain. This uniform distribution hinders certain experts from processing more data from specific domains, thereby preventing experts from developing domain-specific features. We found that relaxing local load balancing to global load balancing can significantly enhance expert specialization and improve model performance.
Background
Mixture-of-Experts (MoE) is an efficient technique for scaling model parameters during training. Typically, an MoE layer consists of a router (usually a linear layer) and a set of experts (for Transformer models, each expert is a feedforward neural network). Given an input, only a subset of experts will be activated, and their outputs will be aggregated based on the weights assigned by the router. Specifically:
Load Balancing Loss
Load balancing loss is an important regularization technique in training MoE networks, and its core idea is to encourage balanced activation across all experts. It can be calculated using the following formula:
Where fi is the activation frequency of expert i, and si is the average routing score assigned to expert i.
However, most existing MoE training frameworks (e.g., Megatron-core) implement local (micro-batch) level balancing, meaning that LBL is computed within each micro-batch and then averaged at the global (global-batch) level, i.e.:
Where N is the number of micro-batches, LBLj is the load balancing loss calculated on the j-th micro-batch, and fi,j and si,j are the activation frequencies and routing scores computed in the j-th micro-batch.
The key point we focus on is that if the data in a micro-batch is not diverse enough, this implementation may hinder expert specialization. For example, if a micro-batch contains only code data, the above load balancing loss will still push the router to evenly distribute these code inputs across all experts. Ideally, the expert network that processes code data should have a higher activation frequency for code data. This situation is more common when training large language models based on MoE: the data in a smaller micro-batch (usually size 1) often comes from the same domain. This partly explains why no significant domain-level expert specialization has been observed in most current large language models based on MoE.
This drawback prompts us to find ways to extend the current local balancing method to global (global-batch) balancing.
From Local Balancing to Global Balancing
Thanks to the format of LBL computation, we can transform local fi into global fi by communicating between different nodes: 1) synchronize expert selection frequencies across all micro-batches; 2) compute load balancing loss on each GPU; 3) aggregate losses across all micro-batches. Specifically:
Where fglobal is the globally aggregated activation frequency and gating score, the first equation represents how fi is computed, the second equation shows that the global routing score can be derived from the average of local routing scores, and the third equation indicates that averaging the local computations with global activation frequencies is equivalent to global load balancing loss. Since fi is just a vector of size equal to the number of experts, it does not introduce significant overhead even in the case of global communication. Additionally, since the computation of LBL is relatively independent of other parts of the model, strategies such as computation masking can further eliminate the communication overhead of synchronization.
Moreover, for scenarios that require gradient accumulation, we also propose a caching mechanism to accumulate the expert activation frequencies from various accumulation steps, allowing for a gradual approximation of the global statistical activation frequencies even when the equilibrium range achieved with fewer computation nodes and only one communication is limited.
Expanding the Range of Balance Brings Stable Improvements
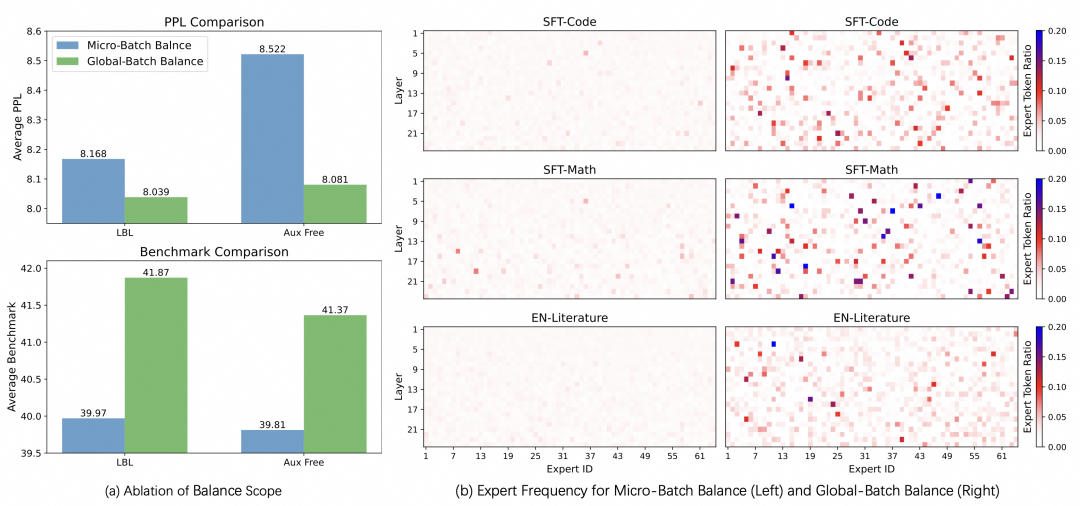
We trained both 120B and 400B tokens at three parameter scales (3.4B active 0.6B, 15B active 2.54B, 43B active 6.6B) and compared the effects of different balance ranges (Balance BSZ) on model performance. All models employed fine-grained experts, shared experts, and dropless strategies (experts do not discard tokens exceeding capacity). It can be seen that increasing the balance range from the typical framework implementations of 4, 8, or 16 to above 128 results in significant improvements in Benchmark metrics and PPL.
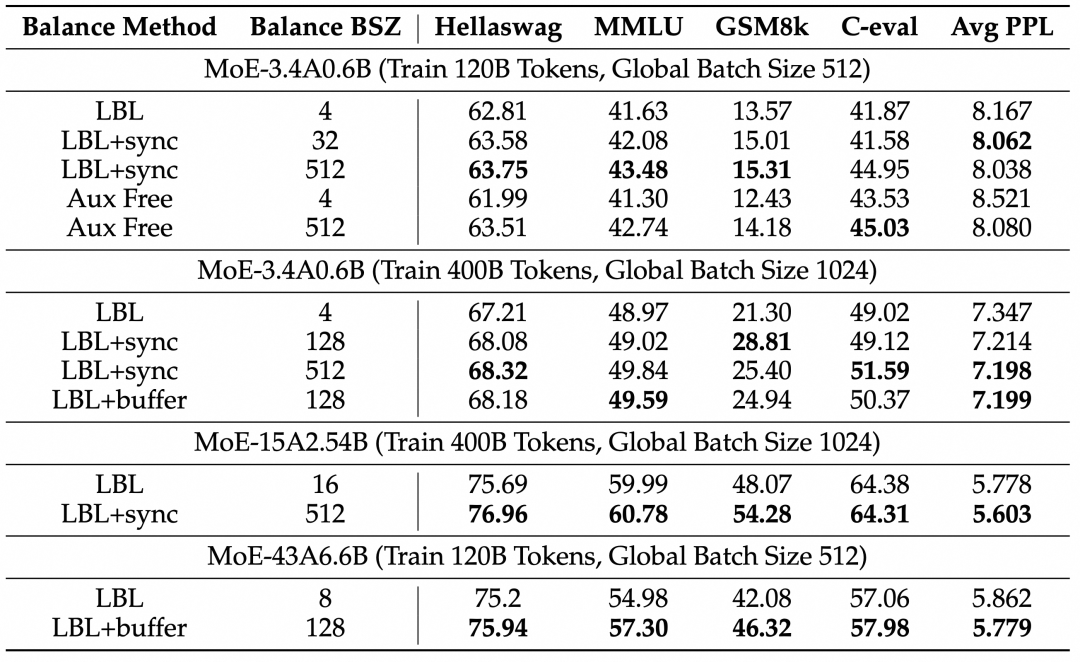
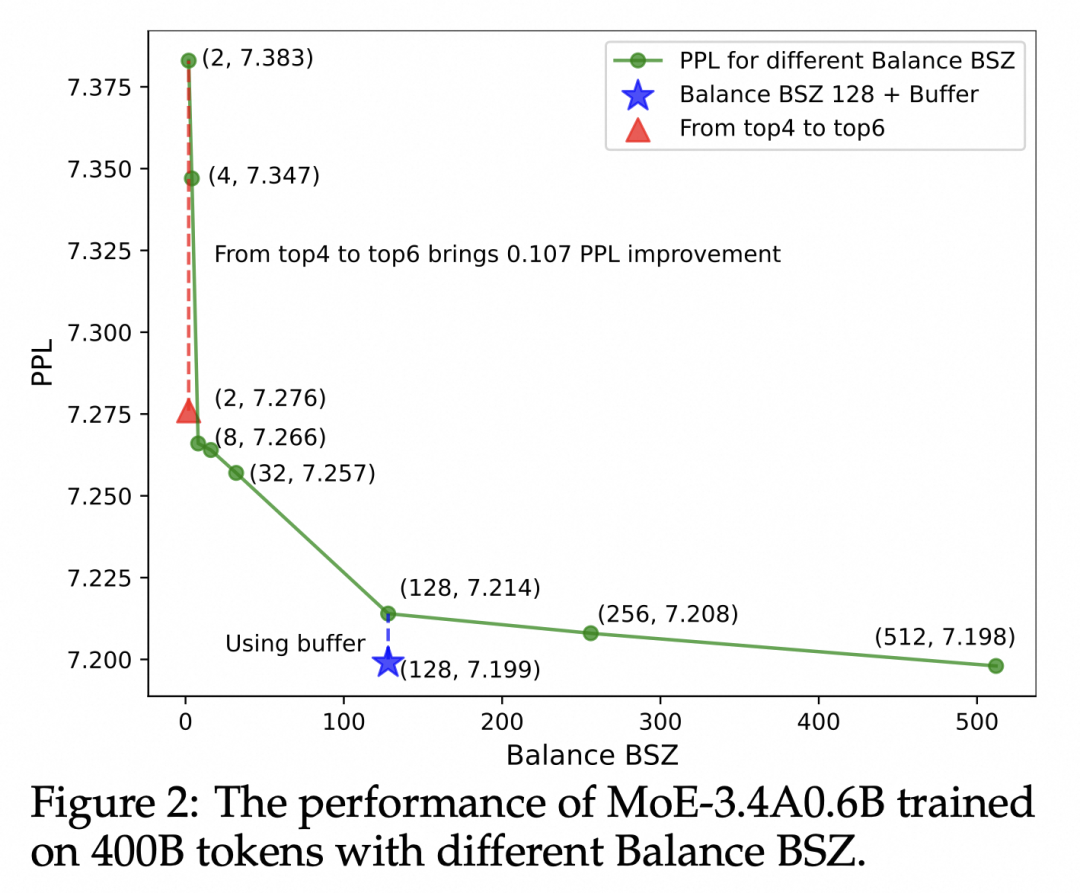
We further compared the model effects with the balance range changes during the training of 400B tokens on the 3.4B active 0.6B model, observing that as Balance BSZ increased from 2 to 128, the model’s PPL rapidly decreased, gradually saturating after 128. Currently, even with in-node communication, mainstream MoE frameworks generally have a balance BSZ of 8 to 16 for larger models, further illustrating the significance of our communication method.
Analysis Experiments
Hypothesis Verification
As mentioned earlier, the starting point of this work is that in a micro-batch, the data source is relatively singular, leading to the MoE model needing to evenly distribute similarly sourced data among all experts, and we improved this to achieve enhancement. However, we can also hypothesize that the global batch reduces variance by using more tokens to compute expert activation frequencies, making the load balancing loss more stable, thus improving training efficiency. To rigorously compare these two hypotheses, we introduced a comparative experimental setup: Shuffled batch balance, where we randomly extract a subset from the global batch (this subset is equal to the size of the micro-batch) to calculate expert activation frequencies and subsequently compute load balancing loss. Shuffled batch balance and micro-batch balance have the same number of tokens, and global-batch balance has the same token distribution.
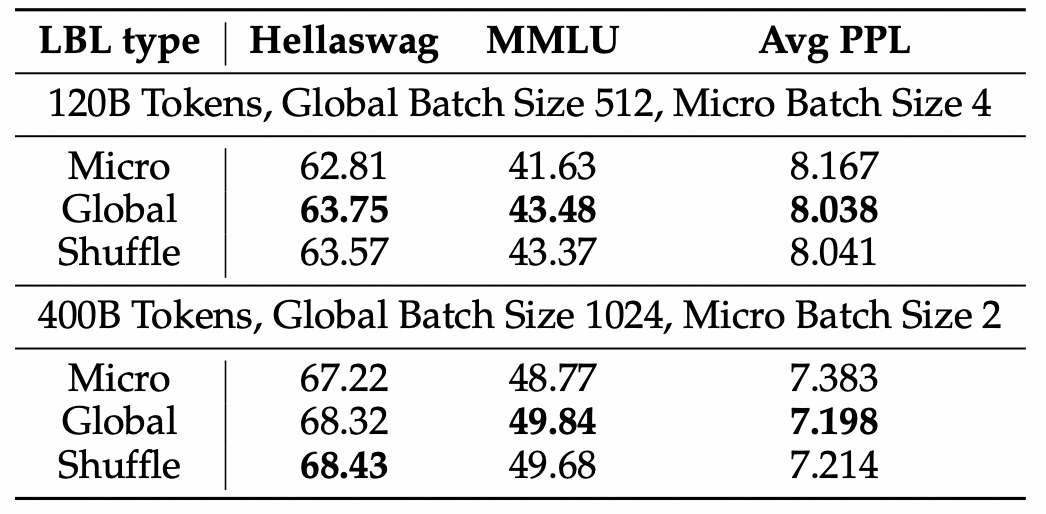
We found that the performance of shuffled batch balance and global batch balance is nearly identical, both significantly outperforming micro batch balance. This indicates that the primary reason for the improvement gained from introducing global-batch is the calculation of loss across a more general and diverse token set. Thus, validating our starting point and hypothesis.
Adding a Small Amount of Local Load Balancing Loss
Can Improve Model Efficiency
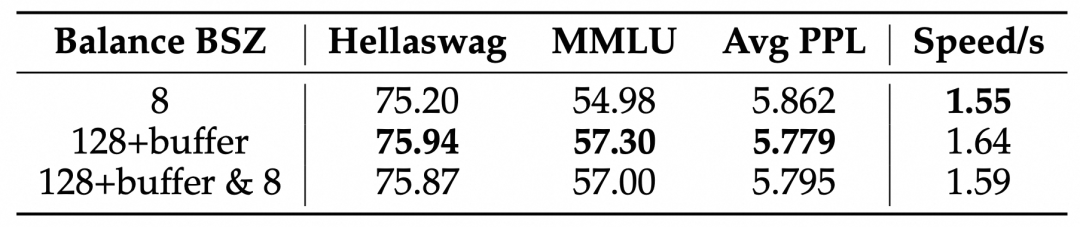
Using only global balancing can lead to a decrease in local balancing status, which may affect MoE’s computational efficiency to some extent. We further experimented with adding local balancing (default implementation of LBL, loss weight is 1% of global LBL) during the training process under the primary use of global balancing to limit the impact on model performance and efficiency. It can be seen that adding local balancing can improve the model’s speed (the time per update step increased from 1.64 seconds to 1.59 seconds), while the model’s performance is almost unaffected.
Related Work and Discussion
Existing work GRIN also proposed Global Load Balance Loss Adaptations, but more focused on using this balancing method as a training framework that only utilizes tensor parallelism without expert parallelism advantages. GRIN does not discuss the motivation for using Global Load Balance in terms of specialization or its impact on model performance, nor does it demonstrate the effect of using Global Load Balance alone.
Wang et al. proposed that in the training of large language models based on MoE, the load balancing loss and language model loss need to be balanced like a lever, as their optimization goals are inconsistent. Therefore, they proposed a bias term based on expert selection frequency updates to balance expert selection without changing routing scores, thus eliminating the auxiliary load balancing loss. However, they did not compare the performance differences when expert selection frequency is computed based on micro-batch versus global-batch.
This work has also been applied to the training of deepseek-v3. The technical report of deepseek-v3 (related work) emphasizes that the expert selection frequency is calculated based on global-batch and discussed on a small scale the results of using LBL based on global batch, finding similar results for both methods.
Our work not only systematically verifies the effectiveness of this method on a large scale, but also analyzes in detail the impact of balance range on performance and provides ablation evidence that global-batch significantly improves performance by incorporating more diverse domain information.
Conclusion
We reviewed the balancing loss in current MoE training frameworks and found that the existing implementation evenly distributes all local inputs from the same domain, limiting the differentiation of experts. By relaxing local balancing to global balancing through lightweight communication, the performance of MoE models and expert specificity has been significantly improved. We believe this advancement addresses a key issue in current MoE training, providing new insights for optimizing MoE models and helping to build more interpretable models. Although our experiments primarily focus on language-based tasks, we hope our work can assist in training larger and more effective MoE models in different domains.
👇 Click to read the original text and learn more on the Qwen technical blog.