
 Click the top to follow me
Click the top to follow meBefore reading this article, we sincerely invite you to click the “Follow” button, so that we can conveniently push similar articles to you in the future, and also facilitate your discussions and sharing. Your support is our motivation to keep creating~
Today, we will learn about a powerful technology released by Qwen yesterday, which can significantly improve the efficiency of training the Mixture of Experts (MoE).
First, let me explain what MoE is. In simple terms, MoE is like a team, consisting of a router responsible for “task allocation” and many “specialists”, also known as experts. In a Transformer-based model, each expert is a feed-forward layer.
When data comes in, the router selects a portion of the experts to process this data, and then aggregates the results from these experts, like this:
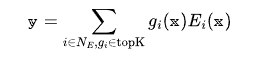
This formula may look a bit complex, but just remember that the router allocates tasks, the experts do the work, and then the results are aggregated.
When training MoE, there is an important concept called load balancing loss.
Its purpose is to ensure that each expert in the team can work “evenly”, so that some experts are not too busy while others are too idle. The formula for calculating it is:
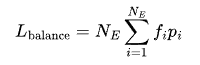
Here, fi is the frequency that expert Ei is “called to work”, and pi is a score assigned to expert Ei when allocating tasks. Many training frameworks currently calculate this load balancing loss within small “data groups”, also known as micro-batches, and then average it globally.
However, if the data in this small “data group” is quite similar, for instance, if all the data is related to code, this calculation method can lead to problems! It will still cause the router to distribute this data evenly among all experts, which not only fails to allow experts to leverage their specialties but also affects the overall model’s performance.
This problem is even more pronounced when training LLMs, as often the data in a small “data group” comes from the same domain.
So what can be done? The technology released by Qwen solves this problem by extending the calculation method to global batch balancing. The specific approach is as follows:
First, let all “working groups” (parallel groups) know how many times each expert has been selected, which means synchronizing the expert selection frequency fi;
Then, each “working group” (for example, each GPU) calculates the load balancing loss independently; finally, add up the losses from all small “data groups”.
In formula form, it is represented as:
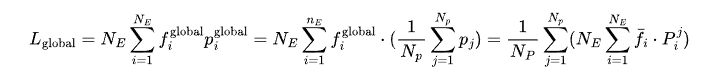
This synchronization process is like everyone communicating with each other, and it is very low-cost.
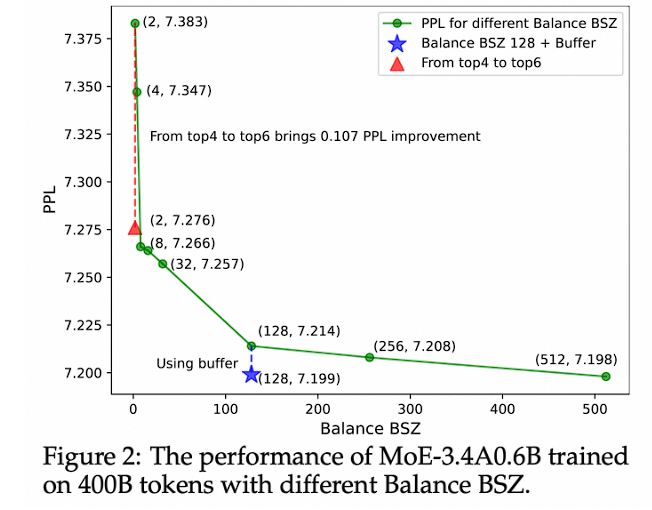
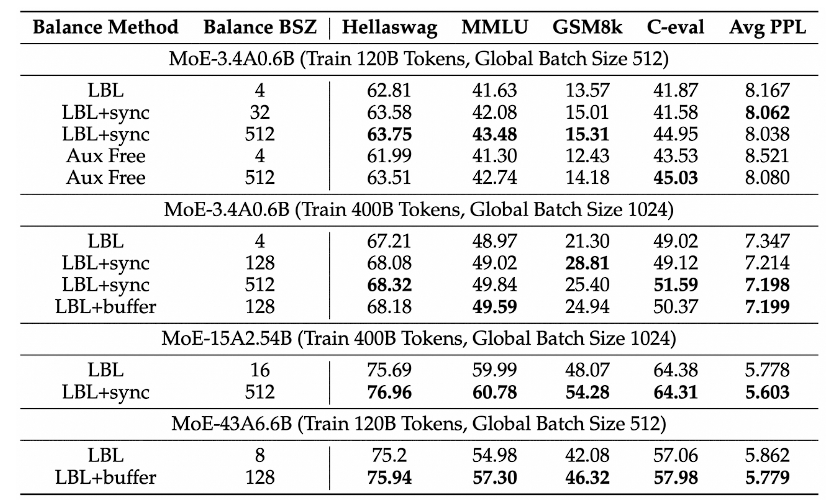
Researchers conducted many experiments to validate the effectiveness of this technology. They used different scales of MoE configurations, such as 3.4B with 0.6B activations, 15B with 2.54B activations, 43B with 6.6B activations, and different amounts of data, 120B and 400B tokens.
In the left side of the figure, almost all experts are evenly activated across different domains. However, on the right side, some experts are frequently activated in specific domains, demonstrating their specialization.
As a result, it was found that after using this global batch balancing technology, the model performed better under various conditions! Moreover, the experts could focus more on their areas of expertise. For example, previously, regardless of the data, the frequency of expert usage was similar; now, certain experts are more frequently “called to work” when encountering data from specific domains.
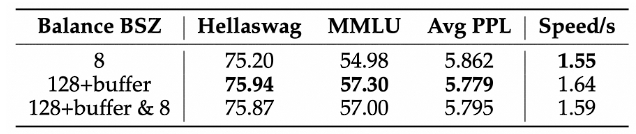
Additionally, researchers also found that by using this global batch balancing technology and adding a slight amount of micro-batch balancing loss (only accounting for 0.01 of the global batch loss), the model not only ran faster, reducing the update time from 1.64 seconds per step to 1.59 seconds per step, but the performance was almost unaffected.
Therefore, this technology is truly impressive as it addresses significant issues encountered in training MoE models, making the models stronger. Although experiments have mainly been conducted on language-related tasks, it may potentially have a great impact in many other fields in the future!
References:
https://qwenlm.github.io/blog/global-load-balance/
HAPPY LABOR DAY

Click the card below to follow us
