
The key to the success of Transformer in the field of deep learning is the attention mechanism. The attention mechanism allows Transformer-based models to focus on parts of the input sequence that are relevant, achieving better context understanding. However, the drawback of the attention mechanism is its high computational cost, which grows quadratically with the input size, making it difficult for Transformers to handle very long texts.
Recently, the emergence of Mamba has broken this situation, allowing for linear scaling with increasing context length. With the release of Mamba, these state space models (SSM) can compete with and even surpass Transformers on medium and small scales while maintaining linear scalability with respect to sequence length, giving Mamba advantageous deployment characteristics.
In simple terms, Mamba first introduces a simple yet effective selection mechanism, which can reparameterize SSM based on the input, allowing the model to filter out irrelevant information while indefinitely retaining necessary and relevant data.
Recently, a paper titled “The Mamba in the Llama: Distilling and Accelerating Hybrid Models” demonstrated that large transformers can be distilled into large hybrid linear RNNs by reusing the weights of the attention layers, requiring minimal additional computation while retaining most of their generative quality.
The resulting hybrid model contains a quarter of the attention layers and achieves performance comparable to the original Transformer in chat benchmark tests, outperforming open-source hybrid Mamba models trained from scratch using trillions of tokens in both chat and general benchmark tests. Additionally, the study proposed a hardware-aware speculative decoding algorithm to accelerate the inference speed of Mamba and hybrid models.

Paper link: https://arxiv.org/pdf/2408.15237
The best-performing model from this study was distilled from Llama3-8B-Instruct, achieving a length-controlled win rate of 29.61 against GPT-4 on AlpacaEval 2, and a win rate of 7.35 on MT-Bench, surpassing the best instruction-tuned linear RNN model.
Method
Knowledge distillation (KD) is a model compression technique used to transfer knowledge from a large model (teacher model) to a smaller model (student model), aiming to train the student network to mimic the behavior of the teacher network. This study aims to distill the Transformer to match the performance of the original language model.
The study proposed a multi-level distillation method that combines progressive distillation, supervised fine-tuning, and directed preference optimization. Compared to ordinary distillation, this method achieves better perplexity and downstream evaluation results.
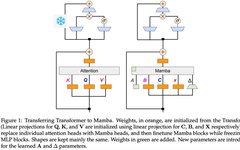
The study assumes that most of the knowledge from the Transformer is retained in the MLP layers migrated from the original model and focuses on the fine-tuning and alignment steps of distilling LLMs. During this stage, the MLP layers remain frozen while the Mamba layers are trained.
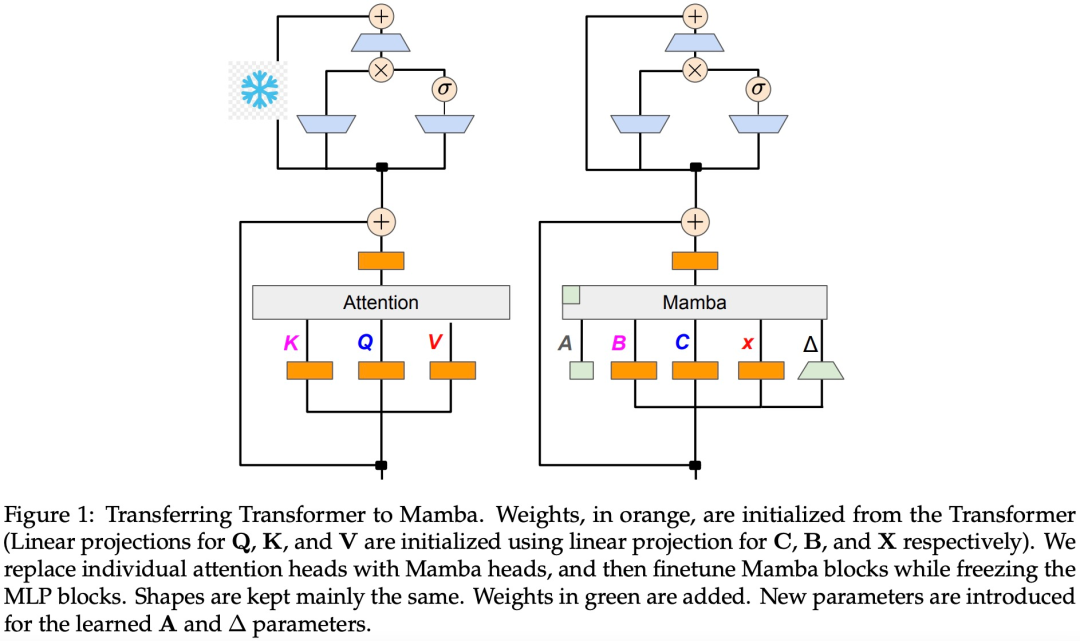
The study believes that there are inherent connections between linear RNNs and the attention mechanism. By removing softmax, the attention formula can be linearized:
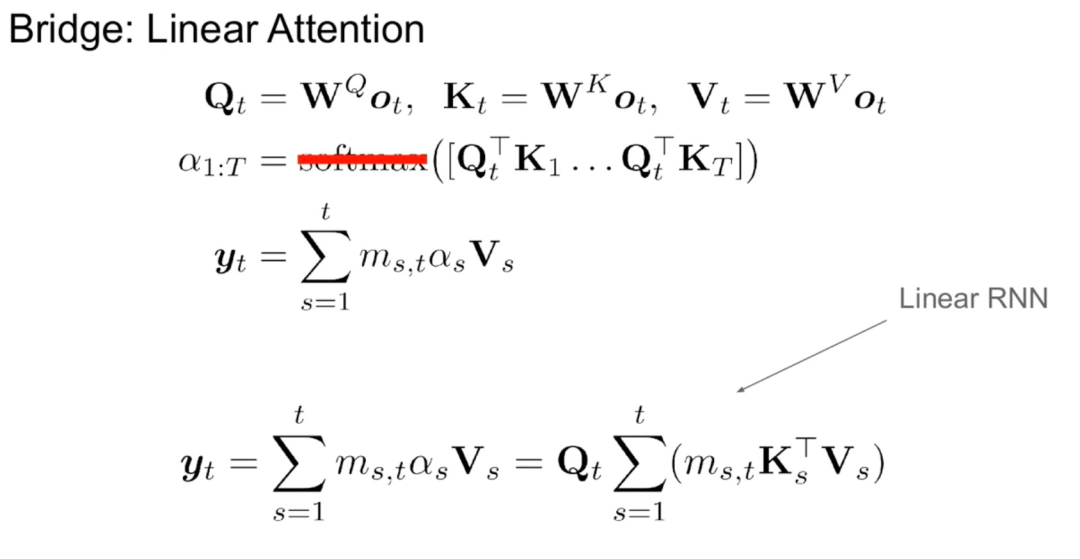
However, linearizing attention can lead to degraded model capability. To design an effective distilled linear RNN, the study aims to stay as close to the original Transformer parameterization as possible while effectively scaling the capacity of the linear RNN. The study does not attempt to make the new model capture the exact original attention function but uses the linearized form as a starting point for distillation.
As shown in Algorithm 1, the study directly feeds the standard Q, K, V heads from the attention mechanism into the Mamba discretization, and then applies the resulting linear RNN. This can be seen as a rough initialization using linear attention, allowing the model to learn richer interactions through expanded hidden states.

The study directly replaces the Transformer attention heads with fine-tuned linear RNN layers while keeping the Transformer MLP layers unchanged and not training them. This approach also needs to handle other components, such as cross-head shared keys and values for grouped query attention. The research team noted that this architecture differs from many architectures used in Mamba systems, and this initialization allows any attention block to be replaced with a linear RNN block.
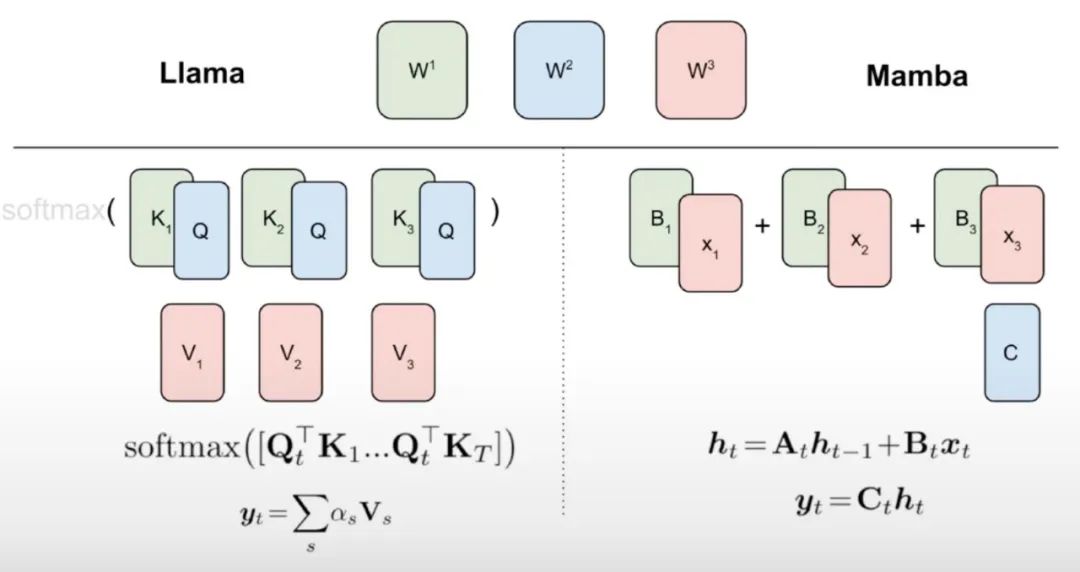
The study also proposed a new algorithm for speculative decoding of linear RNNs using hardware-aware multi-step generation.
Algorithm 2 and Figure 2 show the complete algorithm. This method only retains one RNN hidden state in the cache for verification and delays advancing it based on the success of the multi-step kernel. Since the distilled model contains transformer layers, the study also extends speculative decoding to Attention/RNN hybrid architectures. In this setup, the RNN layers perform verification according to Algorithm 2, while the Transformer layers only perform parallel verification.
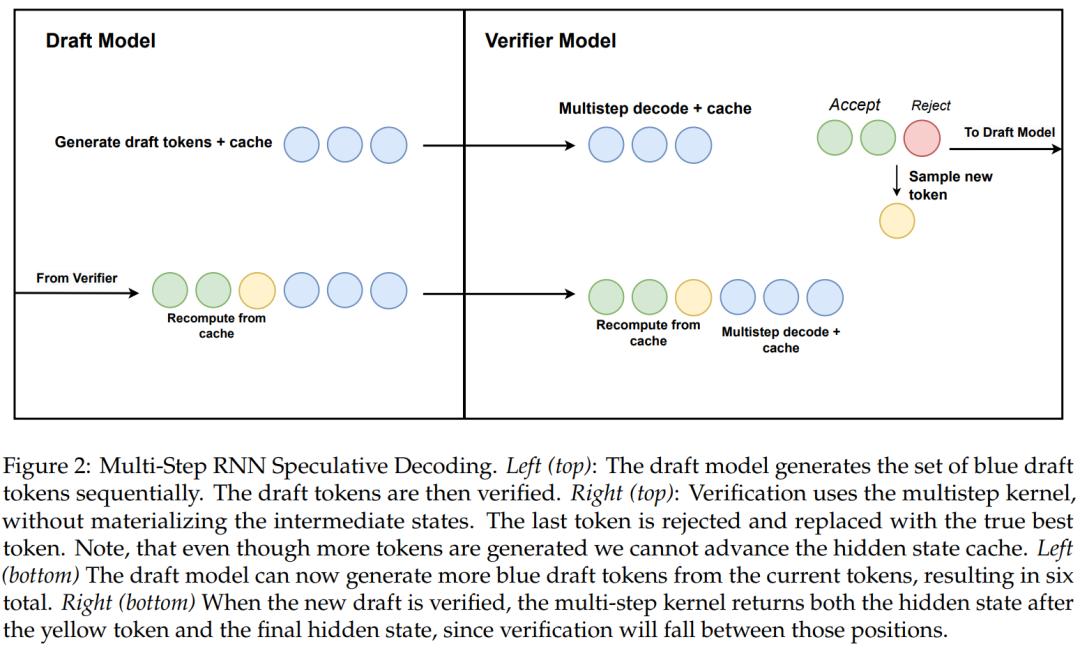

To validate the effectiveness of this method, the study used Mamba 7B and Mamba 2.8B as target models for inference. The results are shown in Table 1.
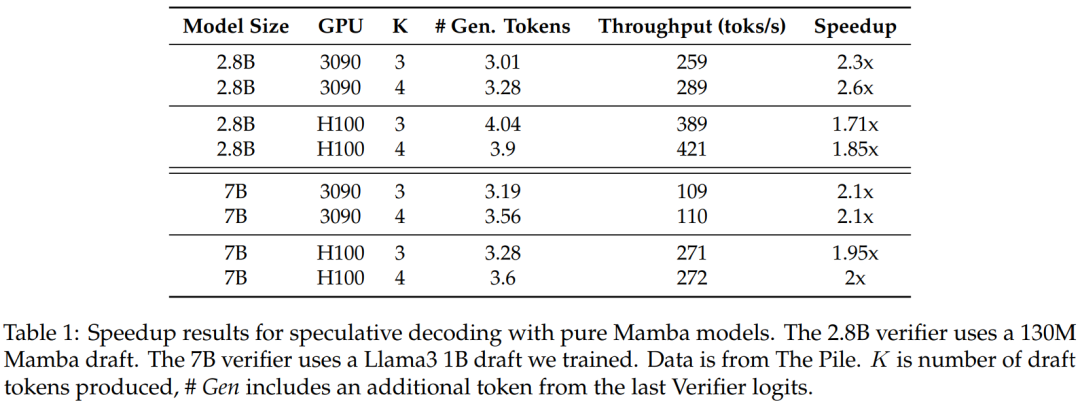
Figure 3 shows the performance characteristics of the multi-step kernel itself.
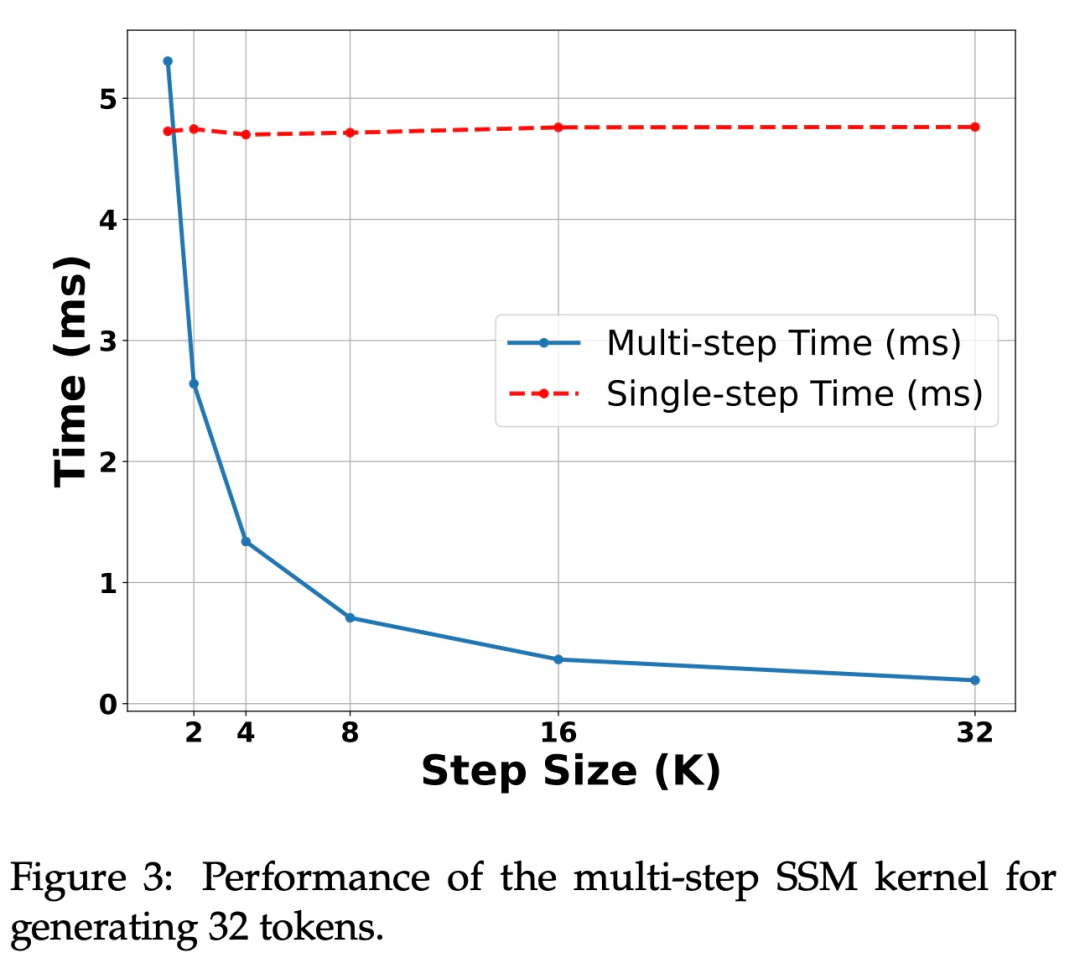
Acceleration on H100 GPU. The algorithm proposed by the study shows strong performance on Ampere GPUs, as shown in Table 1. However, it faces significant challenges on H100 GPUs. This is mainly due to the speed of GEMM operations being too fast, making the overhead from caching and recomputation more apparent. In fact, the simple implementation of the study’s algorithm (using multiple different kernel calls) achieved considerable acceleration on the 3090 GPU but showed no acceleration on the H100 at all.
Experiments and Results
The study conducted experiments using two LLM chat models: Zephyr-7B, which is fine-tuned based on the Mistral 7B model, and Llama-3 Instruct 8B. For the linear RNN model, the study used a hybrid version of Mamba and Mamba2, with attention layers set to 50%, 25%, 12.5%, and 0%, with 0% referred to as the pure Mamba model. Mamba2 is a variant architecture of Mamba designed primarily for recent GPU architectures.
Evaluation on Chat Benchmarks
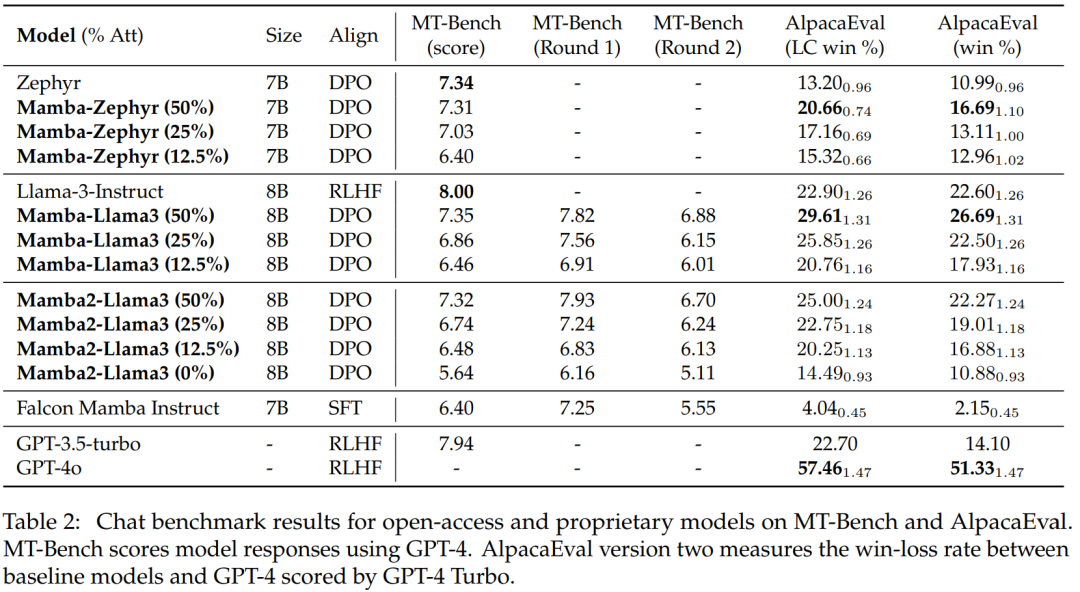
Table 2 shows the performance of the models on chat benchmarks, with the main comparison being large Transformer models. The results show:
The distilled hybrid Mamba model (50%) achieved scores in the MT benchmark test similar to the teacher model and slightly outperformed the teacher model in length-controlled win rates and overall win rates in the AlpacaEval benchmark test.
The performance of the distilled hybrid Mamba (25% and 12.5%) was slightly inferior to the teacher model in the MT benchmark test, but even with more parameters in AlpacaEval, it still surpassed some large Transformers.
The accuracy of the distilled pure (0%) Mamba model did decline significantly.
Notably, the performance of the distilled hybrid model outperformed Falcon Mamba, which was trained from scratch using over 5 trillion tokens.
General Benchmark Evaluation
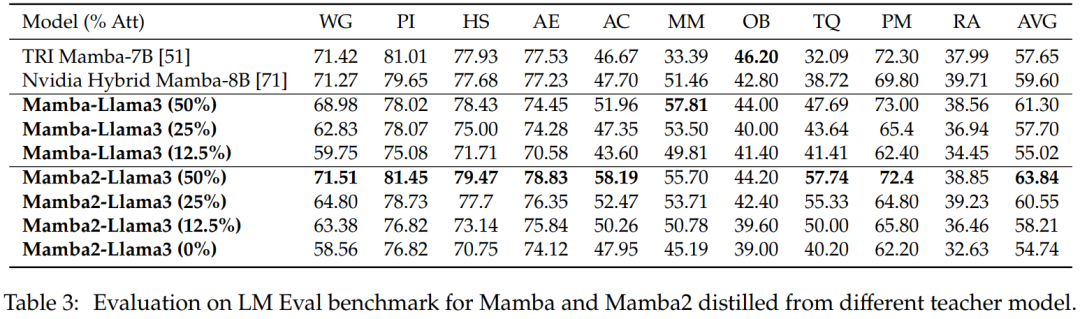
Zero-shot evaluation. Table 3 shows the zero-shot performance of Mamba and Mamba2 distilled from different teacher models in the LM Eval benchmark. The hybrid Mamba-Llama3 and Mamba2-Llama3 models distilled from Llama-3 Instruct 8B performed better compared to open-source TRI Mamba and Nvidia Mamba models trained from scratch.
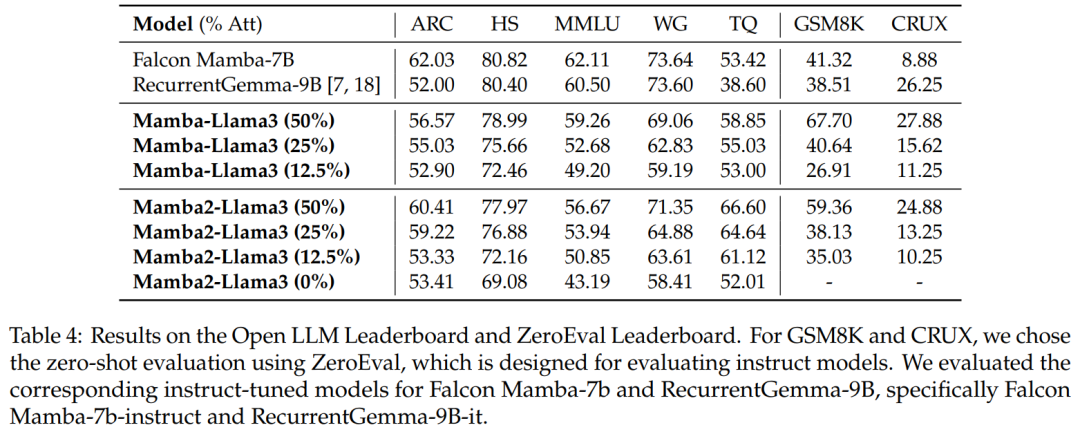
Benchmark Evaluation. Table 4 shows the performance of the distilled hybrid model matching the best open-source linear RNN model on the Open LLM Leaderboard, while outperforming the corresponding open-source instruction models in GSM8K and CRUX.
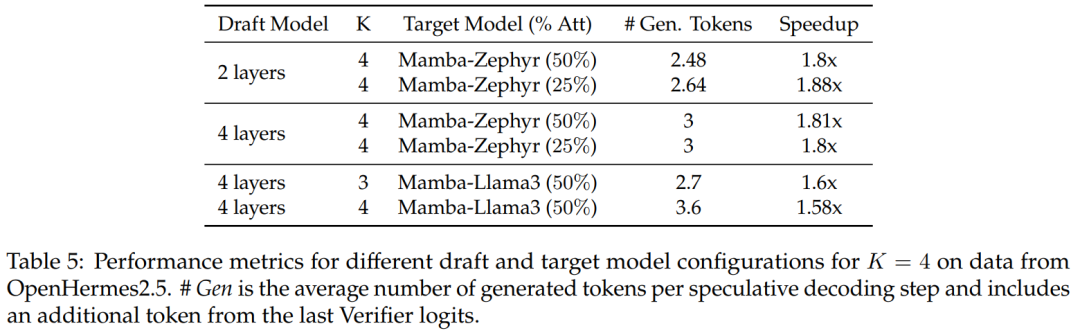
Hybrid Speculative Decoding
For the 50% and 25% distilled models, the study achieved over 1.8 times acceleration on Zephyr-Hybrid compared to the non-speculative baseline.
The experiments also showed that the 4-layer draft model trained achieved higher acceptance rates, but the additional overhead also increased due to the larger scale of the draft model. In future work, the study will focus on reducing the size of these draft models.
Comparison with Other Distillation Methods: Table 6 (left) compares the perplexity of different model variants. The study used Ultrachat as seed prompts for distillation within one epoch and compared perplexity. The results found that removing more layers made the situation worse. The study also compared the distillation method with previous baselines and found that the new method showed less degradation, while the Distill Hyena model was trained on a much smaller model in the WikiText dataset and showed greater perplexity degradation.
Table 6 (right) shows that using SFT or DPO alone does not yield significant improvements, while using SFT + DPO produces the best scores.
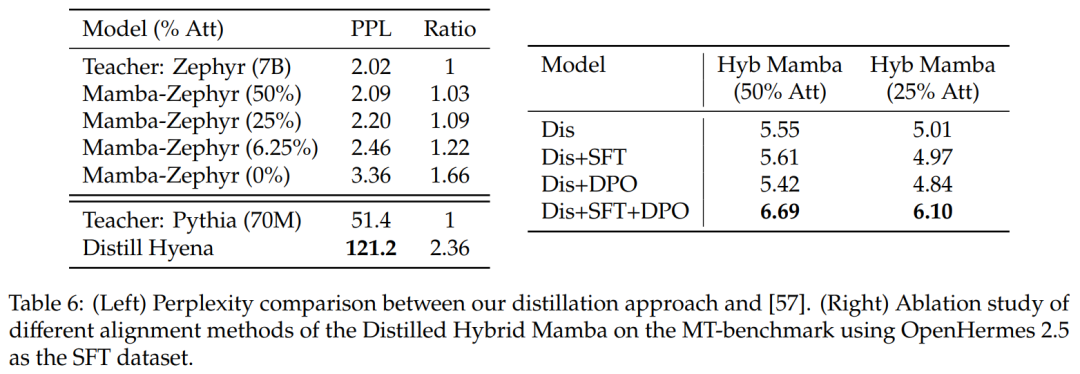
Table 7 compares several different models’ ablation studies. Table 7 (left) shows the distillation results using various initializations, and Table 7 (right) shows that the benefits of progressive distillation and interleaving attention layers with Mamba are minimal.
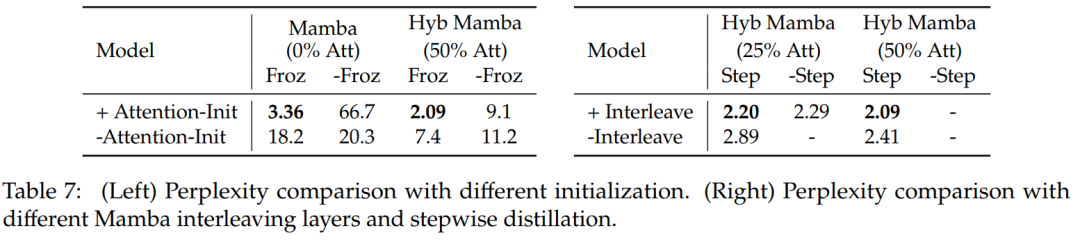
Table 8 compares the performance of hybrid models using two different initialization methods: the results confirm that the initialization of attention weights is crucial.

Table 9 compares the performance of models with and without Mamba blocks. Models with Mamba blocks significantly outperformed those without Mamba blocks. This confirms that adding Mamba layers is crucial, and the performance improvement is not solely due to the remaining attention mechanism.

Interested readers can read the original paper for more research content.

Scan the QR code to add the assistant on WeChat
About Us
