

Source: Algorithm Advancement
This article is approximately 4100 words and is recommended to be read in 8 minutes.
LongLLaVA performs excellently in long-context multimodal understanding.
The authors of this article come from The Chinese University of Hong Kong, Shenzhen, and the Shenzhen Big Data Research Institute. The first authors are PhD student Wang Xidong and research assistant Song Dingjie from The Chinese University of Hong Kong, Shenzhen, whose main research focuses are Medical AGI and Multimodal Learning, respectively; PhD student Chen Shunian focuses on Multimodal Learning, and PhD student Zhang Chen focuses on Efficient Language Models. The corresponding author is Professor Wang Benyou from the School of Data Science at The Chinese University of Hong Kong, Shenzhen.
Expanding the long-context capabilities of multimodal large language models (MLLMs) is crucial for video understanding, high-resolution image understanding, and multimodal agents. This involves a series of systematic optimizations, including model architecture, data construction, and training strategies, particularly addressing challenges such as performance degradation with an increasing number of images and high computational costs.
The team adjusted the model architecture to a hybrid of Mamba and Transformer blocks, considering the temporal and spatial dependencies between multiple images in data construction, and adopted a progressive training strategy. They proposed the first hybrid architecture multimodal large language model, LongLLaVA, achieving a better balance between efficiency and performance.

LongLLaVA not only achieved competitive results on various benchmark tests but also maintained high throughput and low memory consumption, capable of processing nearly a thousand images on a single A100 80GB GPU, demonstrating broad application prospects.

-
Paper link:
-
Project link:
1. Introduction
The rapid advancement of multimodal large language models (MLLMs) demonstrates their significant capabilities across various application areas. However, understanding scenarios with multiple images remains an important but underexplored aspect. In particular, extending MLLMs’ application scenarios to understanding longer videos, higher-resolution images, and decision-making based on more historical information is crucial for enhancing user experience and further expanding the application range of MLLMs.
However, extending the context length of MLLMs to improve their usability faces challenges such as performance degradation when processing more images and high computational costs. Some studies focus on constructing long-context training data containing multiple images to enhance performance. Other studies explore innovative training strategies to alleviate performance degradation. Regarding the issue of high computational costs, LongVILA has made progress in improving multi-node efficiency by reducing communication costs. However, the issue of accelerating computation when managing longer contexts remains to be solved.
To address the above challenges, this study proposes the LongLLaVA system solution, utilizing a hybrid architecture for acceleration. This solution comprehensively optimizes across three dimensions: multimodal architecture, data construction, and training strategies.
-
For multimodal architecture, a hybrid architecture combining Transformer and Mamba is adopted, and an efficient image representation method is proposed, which applies 2D pooling to image tokens to reduce computational costs while maintaining performance.
-
For data construction, unique formats are designed for different tasks to enable the model to distinguish the temporal and spatial dependencies between images.
-
In terms of training strategies, a three-stage multimodal adaptive approach is adopted — single-image alignment, single-image instruction tuning, and multi-image instruction tuning — to gradually enhance the model’s ability to handle multimodal long contexts.
Experimental results show that LongLLaVA excels in efficiently understanding multimodal long contexts. It leads in retrieval, counting, and ranking tasks on VNBench, achieving nearly 100% accuracy during a needle-in-haystack evaluation of 1000 images on a single 80GB GPU. To ensure research reproducibility and promote community development, the team will open-source all models, codes, and datasets related to LongLLaVA.
2. LongLLaVA: Extending LLaVA to Longer Contexts
To address the above challenges and enhance the model’s adaptability to long texts and multi-image scenarios, the team made improvements from three perspectives: multimodal model architecture, data construction, and training strategies.
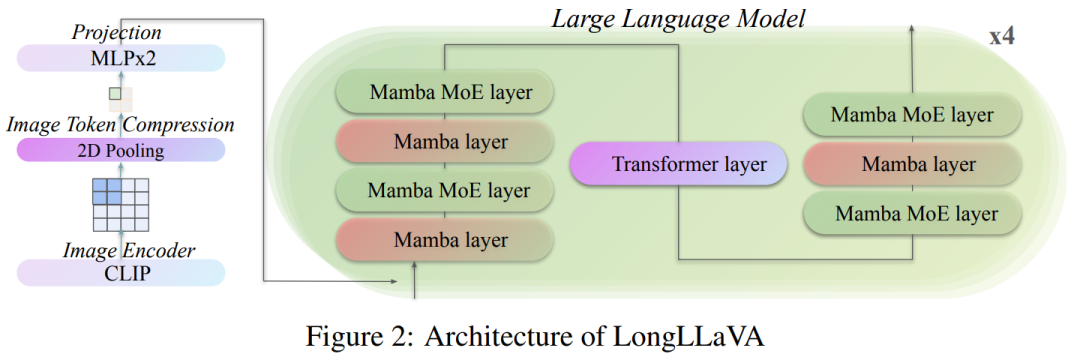
2.1 Multimodal Architecture
LongLLaVA is based on three core components of LLaVA: visual encoder, mapper, and large language model.
Visual information processing. The team uses CLIP as the visual encoder to encode visual information, and employs a two-layer MLP as the mapper to map visual features to a text embedding space suitable for LLM. Before mapping, 2D pooling is applied, effectively saving training and inference time while maintaining the fundamental spatial relationships between image blocks.
Hybrid LLM architecture. LongLLaVA adopts a hybrid LLM architecture, integrating Transformer and Mamba layers in a 1:7 ratio, as shown in Figure 2. A mixture of experts (MoE) method is also employed in each layer, using 16 experts and selecting the top two experts for each token. RMSNorm is used between layers to enhance normalization, while positional embeddings are omitted. The model integrates grouped query attention (GQA) and SwiGLU activation functions, similar to other large language models. The total number of parameters in the model is 53 billion, with a total of 13 billion activation parameters during inference.

2.2 Data Processing Protocol
To ensure the model effectively distinguishes temporal and spatial dependencies between images in multi-image scenarios and performs well across various tasks, the team meticulously differentiated special characters under different scenarios. As shown in Figure 3, these special characters comprehensively handle various relationships between images in different contexts, enhancing the model’s adaptability to different tasks.
-
Regular single and multi-image input: Use <img></img> to help the model distinguish between image and text tokens.
-
Video: Add <t> between different frames to indicate their temporal dependencies.
-
High-resolution images: Use newline characters “\n” to distinguish the main image from its sub-images. For the arrangement of sub-images, they are segmented by traversing from the top-left to the bottom-right, adding “\n” between segmented rows to retain the relative spatial positions of sub-images.
2.3 Training Strategies
The team gradually achieved adaptation to single-modal and multimodal scenarios, transforming the pretrained language model into a multimodal long-context model.
Pure text instruction fine-tuning. First, enhance the pretrained language model’s ability to follow instructions of varying lengths in pure text scenarios. This is achieved using a dataset containing 278k pure text entries from Evol-instruct-GPT4, WildChat, and LongAlign.
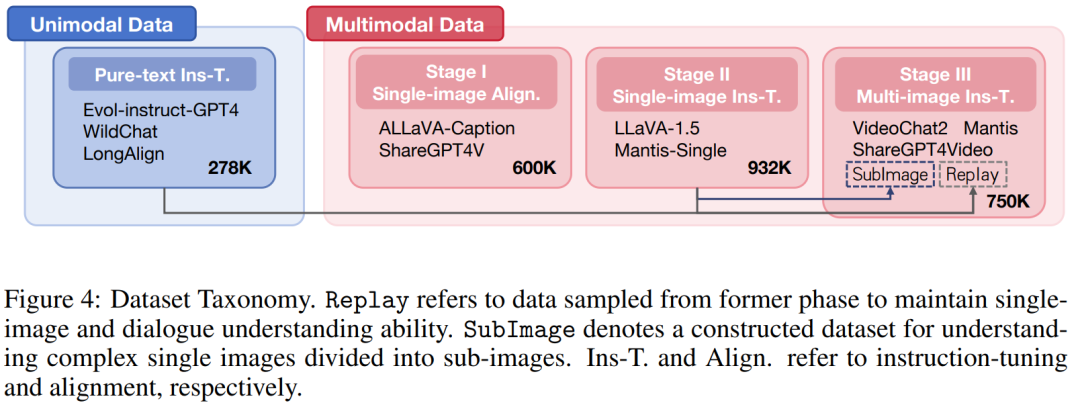
In multimodal adaptation, after the “single-image alignment” and “single-image instruction fine-tuning” phases in LLaVA, the team introduced the “multi-image instruction fine-tuning” phase to gradually enhance the model’s multimodal long-context capability. The progressive training approach is not only to better control variables but also to increase the model’s reusability. Specific dataset usage is illustrated in Figure 4.
Phase 1: Single-image alignment. This phase aims to align visual modality features with text modality. The team used datasets such as ALLaVA-Caption and ShareGPT4V, which contain approximately 600K high-quality image-caption pairs. During this phase, only the mapper is trained while freezing the parameters of the visual encoder and LLM.
Phase 2: Single-image instruction fine-tuning. The goal of this phase is to equip the model with multimodal instruction-following capabilities. The team used datasets such as LLaVA-1.5 and Manti-Single, totaling approximately 932K high-quality question-answer pairs. During this process, only the visual encoder is frozen, while the mapper and LLM parts are trained.
Phase 3: Multi-image instruction fine-tuning. In this phase, the model is trained to follow instructions in multimodal long-text scenarios. The team sampled 200K, 200K, and 50K data items from Mantis, VideoChat2, and ShareGPT4Video, respectively. To retain the model’s single-image understanding and pure text dialogue capabilities, the team included an additional 200K and 50K data items from the single-image instruction fine-tuning and pure text instruction fine-tuning phases as Replay section. Additionally, to enhance the model’s ability to interpret complex single images (segmented into multiple sub-images), the team sampled 50K data from the single-image instruction fine-tuning phase, filling and segmenting the original image into sub-images sized 336×336 as SubImage section.
3. Evaluation Results
3.1 Main Results
As shown in Table 2, LongLLaVA performs excellently on MileBench, even surpassing the closed-source model Claude-3-Opus, especially excelling in retrieval tasks, highlighting its strong capabilities in handling multi-image tasks.
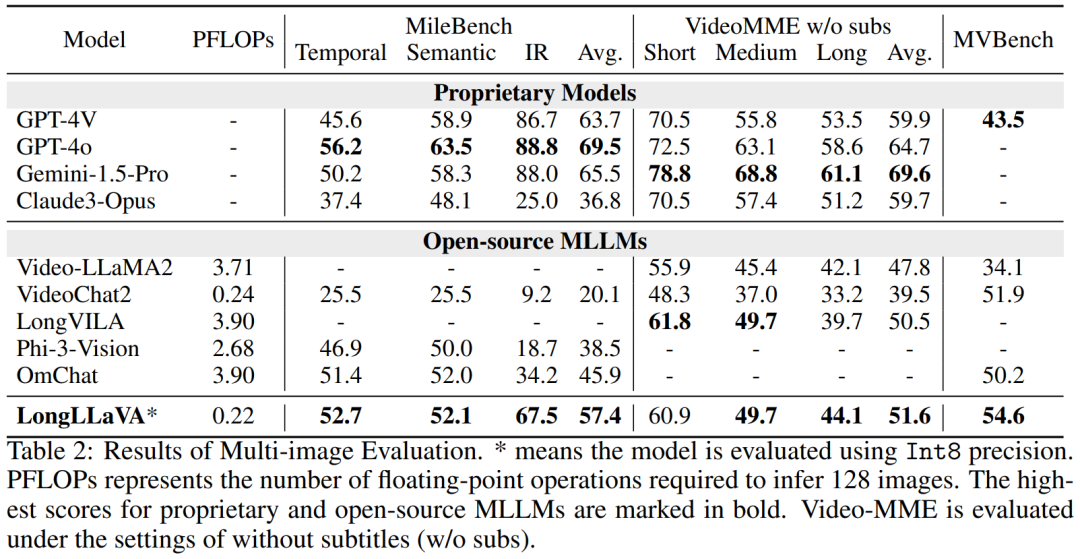
LongLLaVA excels in tasks involving medium to long videos, surpassing traditional video models such as Video-LLaMA2 and VideoChat2. While achieving these impressive results, LongLLaVA’s FLOPs are an order of magnitude lower than other models.
3.2 Diagnostic Evaluation of Long-context Large Language Models
Considering that previous evaluations could not adequately capture MLLM’s capabilities in long contexts, the team adopted a new diagnostic evaluation set VNBench to further analyze the model’s atomic capabilities in long contexts. VNBench is a long-context diagnostic task framework based on synthetic video generation, including tasks such as retrieval, ranking, and counting.
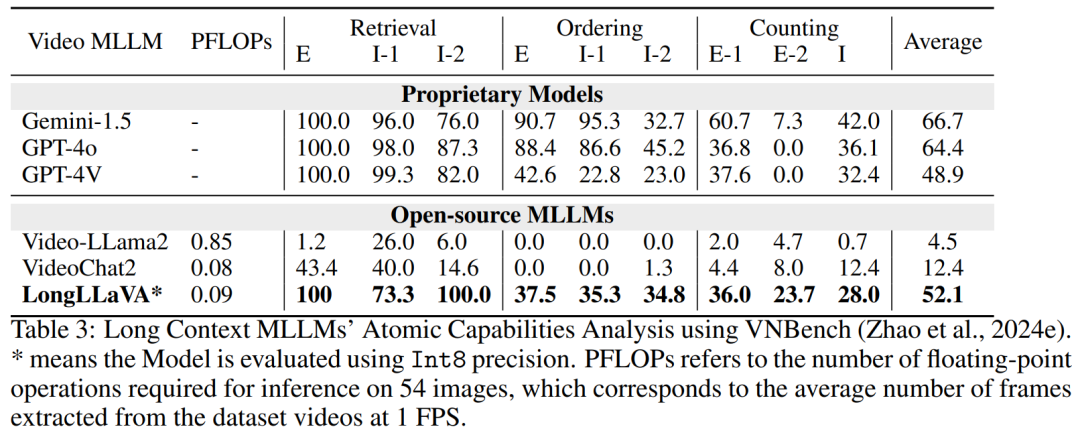
The results, as shown in Table 3, indicate that LongLLaVA performs comparably to leading closed-source models in cross-context retrieval, ranking, and technical capabilities, even surpassing GPT-4V in some aspects. Among open-source models, LongLLaVA also demonstrates its outstanding performance, showcasing its advanced capabilities in managing and understanding long contexts.
3.3 Ablation Experiments
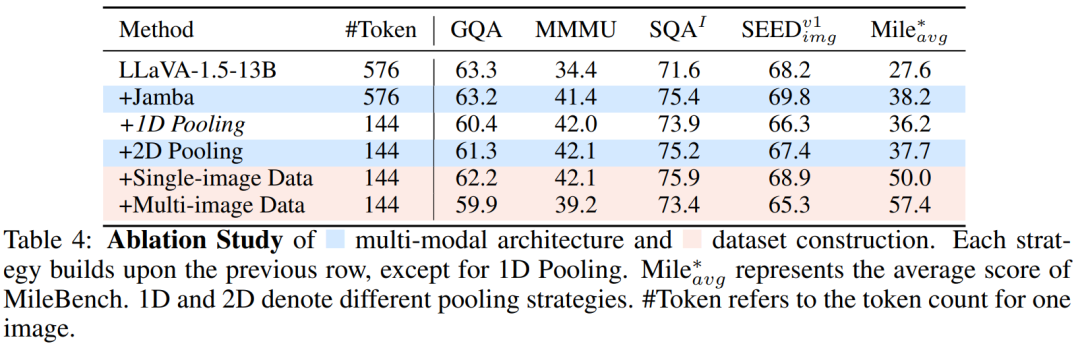
Table 4 shows that using a hybrid LLM architecture with the same data observed significant improvements across the evaluation sets, proving its potential in multimodal scenarios. For token compression, 2D pooling was chosen, significantly reducing the computational load while keeping performance degradation within acceptable limits. Compared to 1D pooling, the 2D pooling method yielded better results. In terms of data construction, after training the team’s single-image data, the model’s accuracy on SEEDBench improved by 1.5%, and on MileBench, it improved by 12.3%. Subsequent multi-image training further increased the accuracy on MileBench by 7.4%, validating the effectiveness of the dataset construction.
4. Further Analysis
To understand the internal workings of LongLLaVA and its cross-modal long-text processing capabilities, the team conducted further analysis.
4.1 Motivation for Hybrid Architecture
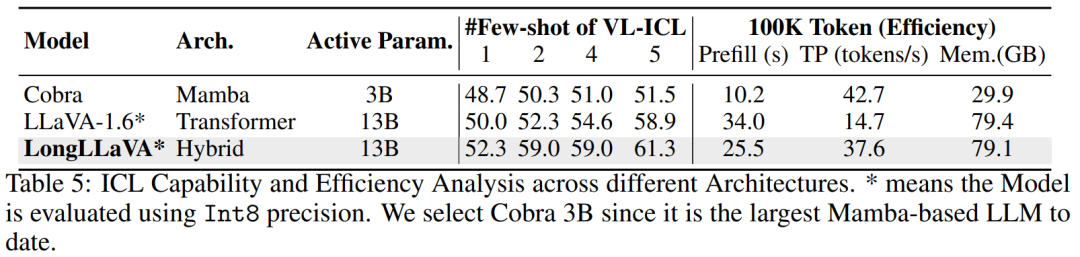
The team discussed the pros and cons of different architectures in terms of ICL capability and inference efficiency, emphasizing the balanced advantages of the hybrid architecture.
ICL Analysis. The team evaluated the performance of matching image tasks in multimodal context learning on the VL-ICL benchmark test. The input for this task includes an image pair, with output indicating whether a specific relationship exists. MLLM needs to learn relationships from examples. As shown in Table 5, the hybrid architecture and Transformer architecture show rapid performance improvement with an increasing number of examples, while the Mamba architecture shows less improvement, confirming its inadequacy in contextual learning.
Efficiency Analysis. The team focused on three aspects: pre-fill time (first inference delay), throughput (number of next tokens generated per second), and memory usage. The team controlled the input text length to 100K and measured the time and maximum memory usage required to generate 1 token and 1000 tokens. Throughput is calculated as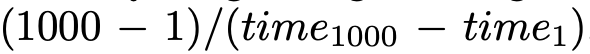 . To better simulate real application scenarios, the team evaluated the Transformer and hybrid architectures using the vLLM framework and Int8 quantization. As shown in Table 5, the Mamba architecture has the fastest pre-fill time and the highest throughput. Compared to the Transformer architecture with similar inference parameters, the hybrid architecture achieves 2.5 times the throughput, 75% of the pre-fill time, and reduced memory usage.
. To better simulate real application scenarios, the team evaluated the Transformer and hybrid architectures using the vLLM framework and Int8 quantization. As shown in Table 5, the Mamba architecture has the fastest pre-fill time and the highest throughput. Compared to the Transformer architecture with similar inference parameters, the hybrid architecture achieves 2.5 times the throughput, 75% of the pre-fill time, and reduced memory usage.
4.2 Scaling Laws of Image Quantity
As the number of images that can be processed increases, the model is able to support more image blocks for high-resolution image understanding, as well as utilize more video frames for video understanding. To explore the impact of increasing the number of sub-images and video frames, the team evaluated LongLLaVA on V* Bench and Video-MME benchmarks, respectively.
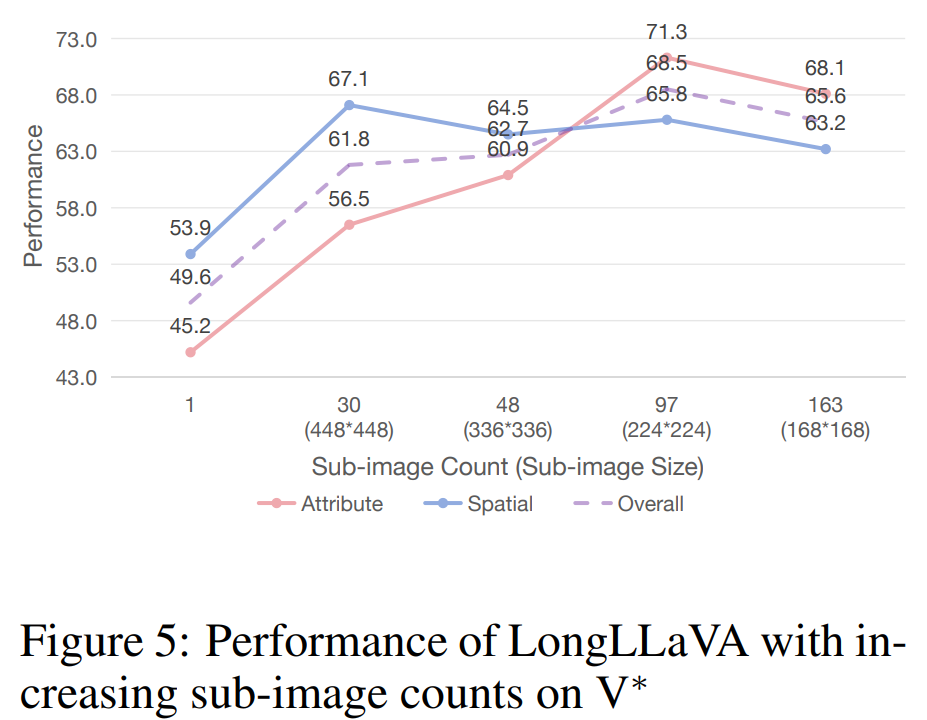
Increasing the Number of Sub-images. V* Bench evaluates a model’s ability to locate small targets in large images. As shown in Figure 5, initially increasing the number of sub-images significantly improved model performance, indicating better understanding of image details. However, the team also found that further increasing the number of sub-images slightly decreased performance, suggesting that too many sub-images might interfere with performance on this task.
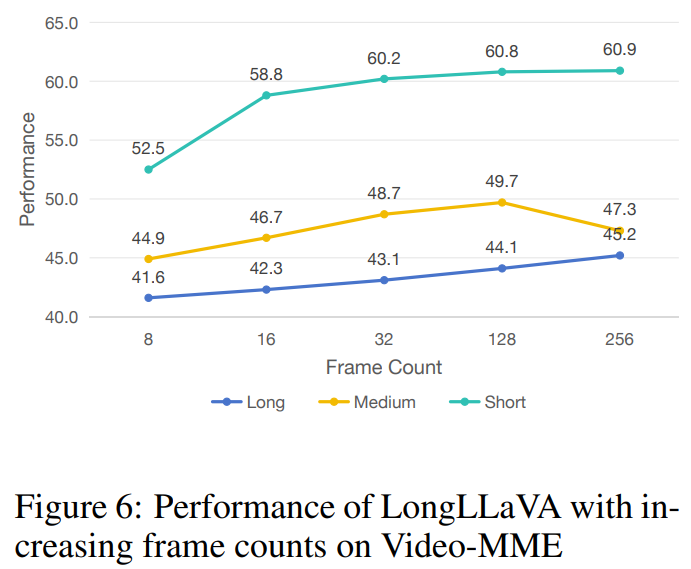
Increasing the Frame Count. The video multimodal encoder is a benchmark testing the model’s ability to extract information from videos. As seen in Figure 6, as the number of sampled frames increases, the model’s performance on the benchmark significantly improves, peaking when extracting 256 frames. This indicates that the model can effectively understand and utilize the information contained in additional sampled frames to provide better responses.
5. Further Expanding the Number of Images to 1000
Utilizing the V-NIAH evaluation framework proposed in LongVA, the team conducted a “needle-in-haystack” test to evaluate model performance. Considering the model’s training sequence length limit of 40,960 tokens, token pooling techniques were employed to reduce the original token count from 144 to 36. This adjustment efficiently retrieves relevant information from a large dataset. As shown in Figure 7, the model achieved nearly 100% retrieval accuracy on a set of 1000 images without additional training.
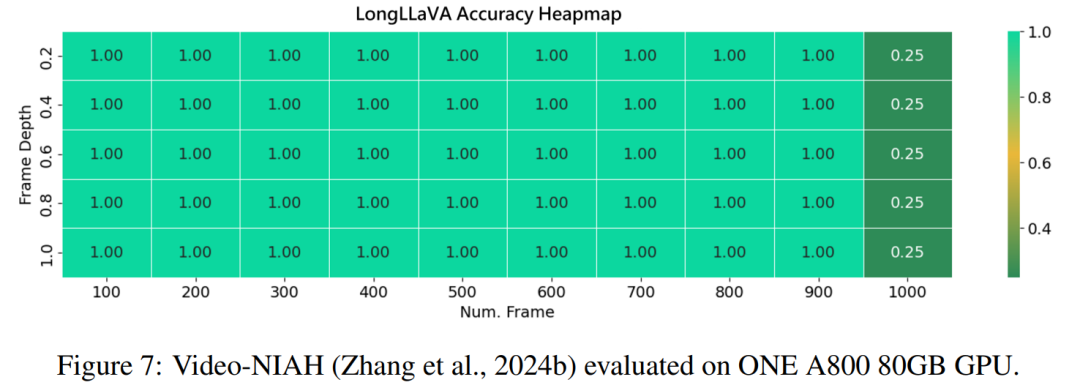
However, when the number of test images exceeded 1,000, the team observed a decline in retrieval accuracy. This performance drop may be due to exceeding the model’s training sequence length, which might affect its ability to maintain accuracy with more images. In future work, the team plans to extend the training sequence length to 140,000 tokens, which is the limit for LongLLaVA’s single-card inference, to further unleash the model’s potential.
6. Conclusion
The innovative hybrid architecture model LongLLaVA (Long-context Large Language and Visual Assistant) excels in long-context multimodal understanding. This model integrates Mamba and Transformer modules, constructs data utilizing the temporal and spatial dependencies between multiple images, and adopts a progressive training strategy.
LongLLaVA demonstrates competitive performance across various benchmark tests while ensuring efficiency, setting a new standard for long-context multimodal large language models (MLLMs).
-
Paper link: https://arxiv.org/abs/2409.02889 -
Project link: https://github.com/FreedomIntelligence/LongLLaVA
About Us
Data Party THU, as a data science public account backed by Tsinghua University’s Big Data Research Center, shares cutting-edge data science and big data technology innovation research dynamics, continuously disseminating data science knowledge, striving to build a data talent aggregation platform, and creating the strongest group of big data in China.

Sina Weibo: @Data Party THU
WeChat Video Account: Data Party THU
Today’s Headlines: Data Party THU