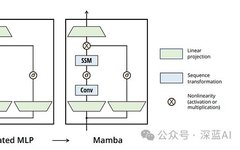


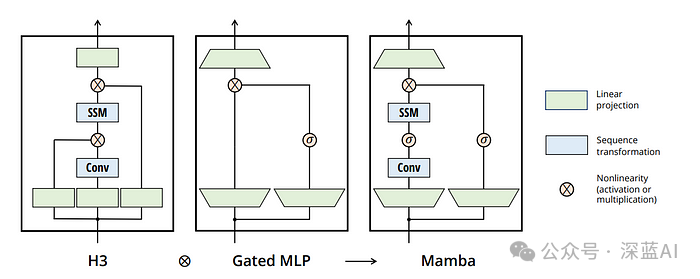
▲Figure 1|Development of Sequence Modeling Network Architecture ©️【Deep Blue AI】
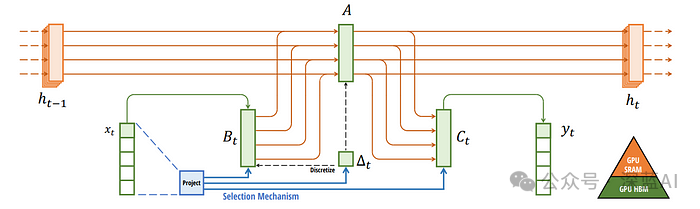
▲Figure 2|Mamba Introduces Selective State Space ©️【Deep Blue AI】

■2.1 Import Required Libraries
# Importing PyTorch related libraries
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from torch.nn import functional as F
from einops import rearrange
from tqdm import tqdm
# Importing system related libraries
import math
import os
import urllib.request
from zipfile import ZipFile
from transformers import AutoTokenizer
torch.autograd.set_detect_anomaly(True)■2.2 Setting Identifiers and Training Device
# Configuration identifiers and hyperparameters
USE_MAMBA = 1
DIFFERENT_H_STATES_RECURRENT_UPDATE_MECHANISM = 0
# Set the device used
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')← Swipe left/right to view the complete code →
■2.3 Set Initialization Hyperparameters
# Manually defined hyperparameters
d_model = 8
state_size = 128 # State size
seq_len = 100 # Sequence length
batch_size = 256 # Batch size
last_batch_size = 81 # Last batch size
current_batch_size = batch_size
different_batch_size = False
h_new = None
temp_buffer = None■2.4 Define S6 Module
# Define S6 module
class S6(nn.Module):
def __init__(self, seq_len, d_model, state_size, device):
super(S6, self).__init__()
# A series of linear transformations
self.fc1 = nn.Linear(d_model, d_model, device=device)
self.fc2 = nn.Linear(d_model, state_size, device=device)
self.fc3 = nn.Linear(d_model, state_size, device=device)
# Set some hyperparameters
self.seq_len = seq_len
self.d_model = d_model
self.state_size = state_size
self.A = nn.Parameter(F.normalize(torch.ones(d_model, state_size, device=device), p=2, dim=-1))
# Parameter initialization
nn.init.xavier_uniform_(self.A)
self.B = torch.zeros(batch_size, self.seq_len, self.state_size, device=device)
self.C = torch.zeros(batch_size, self.seq_len, self.state_size, device=device)
self.delta = torch.zeros(batch_size, self.seq_len, self.d_model, device=device)
self.dA = torch.zeros(batch_size, self.seq_len, self.d_model, self.state_size, device=device)
self.dB = torch.zeros(batch_size, self.seq_len, self.d_model, self.state_size, device=device)
# Define internal parameters h and y
self.h = torch.zeros(batch_size, self.seq_len, self.d_model, self.state_size, device=device)
self.y = torch.zeros(batch_size, self.seq_len, self.d_model, device=device)
# Discretization function
def discretization(self):
# Discretization function definition as described on page 28 of the Mamba paper
self.dB = torch.einsum("bld,bln->bldn", self.delta, self.B)
# dA = torch.matrix_exp(A * delta) # matrix_exp() only supports square matrix
self.dA = torch.exp(torch.einsum("bld,dn->bldn", self.delta, self.A))
return self.dA, self.dB
# Forward propagation
def forward(self, x):
# Refer to Algorithm 2 in the Mamba paper
self.B = self.fc2(x)
self.C = self.fc3(x)
self.delta = F.softplus(self.fc1(x))
# Discretization
self.discretization()
if DIFFERENT_H_STATES_RECURRENT_UPDATE_MECHANISM: # If not using 'h_new', will trigger local allowed error
global current_batch_size
current_batch_size = x.shape[0]
if self.h.shape[0] != current_batch_size:
different_batch_size = True
# Scale h's dimensions to match the current batch
h_new = torch.einsum('bldn,bldn->bldn', self.dA, self.h[:current_batch_size, ...]) + rearrange(x, "b l d -> b l d 1") * self.dB
else:
different_batch_size = False
h_new = torch.einsum('bldn,bldn->bldn', self.dA, self.h) + rearrange(x, "b l d -> b l d 1") * self.dB
# Change y's dimensions
self.y = torch.einsum('bln,bldn->bld', self.C, h_new)
# Update h's information based on h_new
global temp_buffer
temp_buffer = h_new.detach().clone() if not self.h.requires_grad else h_new.clone()
return self.y
else: # Will trigger an error
# Set h's dimensions
h = torch.zeros(x.size(0), self.seq_len, self.d_model, self.state_size, device=x.device)
y = torch.zeros_like(x)
h = torch.einsum('bldn,bldn->bldn', self.dA, h) + rearrange(x, "b l d -> b l d 1") * self.dB
# Set y's dimensions
y = torch.einsum('bln,bldn->bld', self.C, h)
return y■2.5 Define MambaBlock Module
# Define MambaBlock module
class MambaBlock(nn.Module):
def __init__(self, seq_len, d_model, state_size, device):
super(MambaBlock, self).__init__()
self.inp_proj = nn.Linear(d_model, 2*d_model, device=device)
self.out_proj = nn.Linear(2*d_model, d_model, device=device)
# Residual connection
self.D = nn.Linear(d_model, 2*d_model, device=device)
# Setting bias property
self.out_proj.bias._no_weight_decay = True
# Initialize bias
nn.init.constant_(self.out_proj.bias, 1.0)
# Initialize S6 module
self.S6 = S6(seq_len, 2*d_model, state_size, device)
# Add 1D convolution
self.conv = nn.Conv1d(seq_len, seq_len, kernel_size=3, padding=1, device=device)
# Add linear layer
self.conv_linear = nn.Linear(2*d_model, 2*d_model, device=device)
# Normalization
self.norm = RMSNorm(d_model, device=device)
# Forward propagation
def forward(self, x):
# Refer to Figure 3 in the Mamba paper
x = self.norm(x)
x_proj = self.inp_proj(x)
# 1D convolution operation
x_conv = self.conv(x_proj)
x_conv_act = F.silu(x_conv) # Swish activation
# Linear operation
x_conv_out = self.conv_linear(x_conv_act)
# S6 module operation
x_ssm = self.S6(x_conv_out)
x_act = F.silu(x_ssm) # Swish activation
# Residual connection
x_residual = F.silu(self.D(x))
x_combined = x_act * x_residual
x_out = self.out_proj(x_combined)
return x_out■2.6 Define Mamba Model
# Define Mamba model
class Mamba(nn.Module):
def __init__(self, seq_len, d_model, state_size, device):
super(Mamba, self).__init__()
self.mamba_block1 = MambaBlock(seq_len, d_model, state_size, device)
self.mamba_block2 = MambaBlock(seq_len, d_model, state_size, device)
self.mamba_block3 = MambaBlock(seq_len, d_model, state_size, device)
def forward(self, x):
x = self.mamba_block1(x)
x = self.mamba_block2(x)
x = self.mamba_block3(x)
return x■2.7 Define RMSNorm Module
class RMSNorm(nn.Module):
def __init__(self, d_model: int, eps: float=1e-5, device: str='cuda'):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(d_model, device=device))
def forward(self, x):
output = x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps) * self.weight
return output
# Create simulated data
x = torch.rand(batch_size, seq_len, d_model, device=device)
# Create Mamba algorithm model
mamba = Mamba(seq_len, d_model, state_size, device)
# Define RMSNorm module
norm = RMSNorm(d_model)
x = norm(x)
# Forward propagation
test_output = mamba(x)
print(f"test_output.shape = {test_output.shape}")■3.1 Data Preparation and Training Function
# Define padding function
def pad_sequences_3d(sequences, max_len=None, pad_value=0):
# Get the dimensions of the tensor
batch_size, seq_len, feature_size = sequences.shape
if max_len is None:
max_len = seq_len + 1
# Initialize padded_sequences
padded_sequences = torch.full((batch_size, max_len, feature_size), fill_value=pad_value, dtype=sequences.dtype, device=sequences.device)
# Fill each sequence
padded_sequences[:, :seq_len, :] = sequences
return padded_sequences# Define train function
def train(model, tokenizer, data_loader, optimizer, criterion, device, max_grad_norm=1.0, DEBUGGING_IS_ON=False):
model.train()
total_loss = 0
for batch in data_loader:
optimizer.zero_grad()
input_data = batch['input_ids'].clone().to(device)
attention_mask = batch['attention_mask'].clone().to(device)
# Get input data and labels
target = input_data[:, 1:]
input_data = input_data[:, :-1]
# Pad sequence data
input_data = pad_sequences_3d(input_data, pad_value=tokenizer.pad_token_id)
target = pad_sequences_3d(target, max_len=input_data.size(1), pad_value=tokenizer.pad_token_id)
if USE_MAMBA:
output = model(input_data)
loss = criterion(output, target)
loss.backward(retain_graph=True) # Retain graph for backward pass
# Clip gradients
for name, param in model.named_parameters():
if 'out_proj.bias' not in name:
# Gradient clipping operation
torch.nn.utils.clip_grad_norm_(param, max_norm=max_grad_norm)
if DEBUGGING_IS_ON:
for name, parameter in model.named_parameters():
if parameter.grad is not None:
print(f"{name} gradient: {parameter.grad.data.norm(2)}")
else:
print(f"{name} has no gradient")
if USE_MAMBA and DIFFERENT_H_STATES_RECURRENT_UPDATE_MECHANISM:
model.S6.h[:current_batch_size, ...].copy_(temp_buffer)
optimizer.step()
total_loss += loss.item()
return total_loss / len(data_loader)■3.2 Model Training Loop
# Input pre-trained model weights
encoded_inputs_file = 'encoded_inputs_mamba.pt'
if os.path.exists(encoded_inputs_file):
print("Loading pre-tokenized data...")
encoded_inputs = torch.load(encoded_inputs_file)
else:
print("Tokenizing raw data...")
enwiki8_data = load_enwiki8_dataset()
encoded_inputs, attention_mask = encode_dataset(tokenizer, enwiki8_data)
torch.save(encoded_inputs, encoded_inputs_file)
print(f"finished tokenizing data")
# Combine data
data = {
'input_ids': encoded_inputs,
'attention_mask': attention_mask
}
# Split training and validation sets
total_size = len(data['input_ids'])
train_size = int(total_size * 0.8)
train_data = {key: val[:train_size] for key, val in data.items()}
val_data = {key: val[train_size:] for key, val in data.items()}
train_dataset = Enwiki8Dataset(train_data)
val_dataset = Enwiki8Dataset(val_data)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
# Initialize model
model = Mamba(seq_len, d_model, state_size, device).to(device)
# Define loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW(model.parameters(), lr=5e-6)
# Number of training epochs
num_epochs = 25
for epoch in tqdm(range(num_epochs)):
train_loss = train(model, tokenizer, train_loader, optimizer, criterion, device, max_grad_norm=10.0, DEBUGGING_IS_ON=False)
val_loss = evaluate(model, val_loader, criterion, device)
val_perplexity = calculate_perplexity(val_loss)
print(f'Epoch: {epoch+1}, Training Loss: {train_loss:.4f}, Validation Loss: {val_loss:.4f}, Validation Perplexity: {val_perplexity:.4f}')
References:

Building a Complete NeRF from Scratch with PyTorch
2024-01-31

Detailed Explanation of NeRF Principles and Code (2)
2023-12-01

Detailed Explanation of NeRF Principles and Code (1)
2023-11-24

【Deep Blue AI】 is recruiting authors for long-term. We welcome those who want to transform their scientific and technical experiences into words to share with a wider audience. If you want to join, please click the link below to learn more👇

The Deep Blue AI author team is strongly recruiting! We look forward to your joining.

【Deep Blue AI】‘s original content is created with the author’s personal efforts. We hope everyone follows the original rules and cherishes the authors’ hard work. For reprints, please contact us for authorization and be sure to indicate that it comes from【Deep Blue AI】WeChat official account, otherwise legal action will be taken.
*Click to view, collect, and recommend this article*