

New Intelligence Report
New Intelligence Report
Author: Gaode Intelligent Technology Center
[New Intelligence Guide]The research and development team of Gaode Intelligent Technology Center designed a contrastive learning framework for knowledge distillation in their work, and proposed COS-NCE LOSS based on this framework. This paper has been accepted by AAAI 2021.
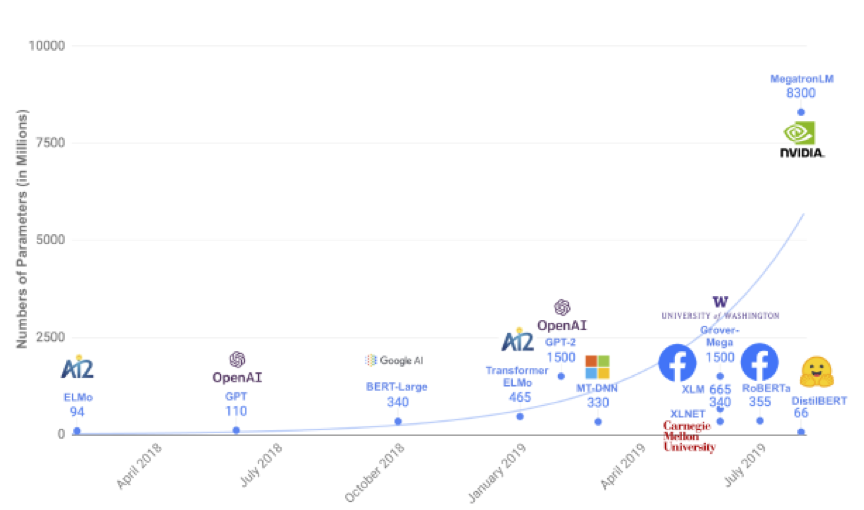
Background Introduction
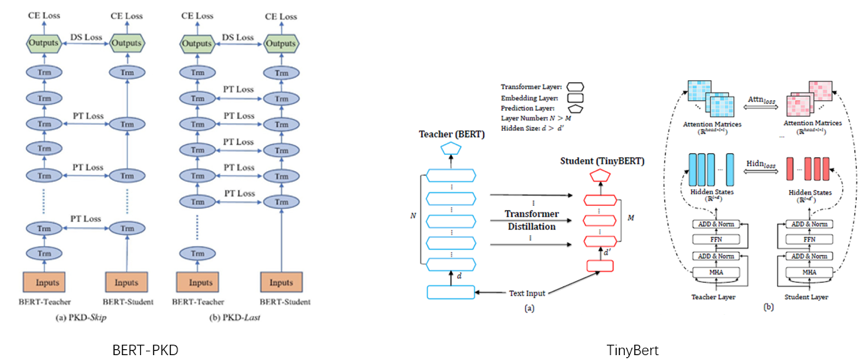
Method
3.1 Problem Definition
The teacher network is defined as fT(x,θ): x is the model input, θ is the model parameter, and the model output is ZT. The student network is defined as fS(x,θ‘) with output ZS. The goal is for the student’s fS(x,θ’) expression to be closer to the teacher’s fT(x,θ) expression while minimizing the prediction layer loss, ensuring that the student performs with the same efficacy as the teacher.
3.2 Model Distillation Structure
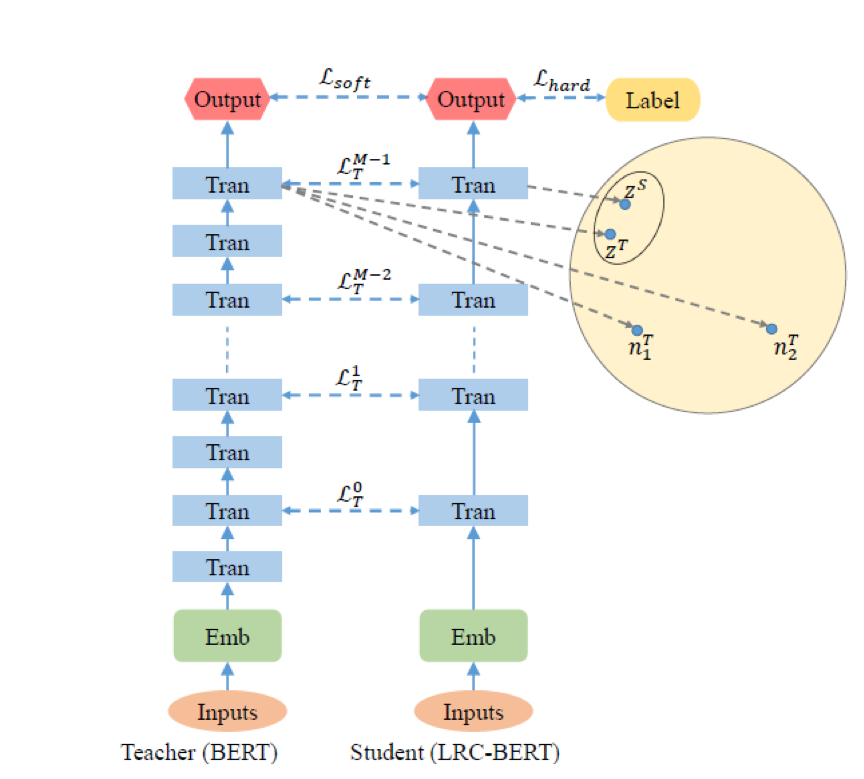
The figure below shows the structure of LRC-BERT, where contrastive learning acts on the intermediate layer expressions, allowing the student to learn the teacher’s potential semantic information. For instance, the student expression ZS should approach the teacher feature expression ZT while distancing itself from negative examples n1T and n2T.
3.3 COS-based NCE Loss
The concept of contrastive learning has existed for a long time, but it became a popular direction in February 2020 when Ting Chen from Hinton’s group proposed SimCLR, which achieved a 7% improvement in representations trained with this framework, even approaching the performance of supervised models.
The goal of contrastive learning is to learn a representation Z for input X (ideally, knowing Z would mean knowing X). The measure used is mutual information I(X,Z), and deriving the objective of maximizing mutual information leads to the contrastive learning loss (also known as InfoNCE). Its core is to calculate the distance between sample representations, bringing positive samples closer and pushing negative samples further away to obtain deep information expression of X.
This paper designs the contrastive loss COS-NCE for intermediate layer knowledge distillation. For a given teacher network fT(x,θ) and student network fS(x,θ’), any positive example randomly selects K negative samples N = {n1–, n2–, ……., nk–}, thus obtaining the teacher’s intermediate layer expression ZT, the student’s intermediate layer expression ZS, and K negative example expressions N= {n1–, n2–, ……., nk–}.
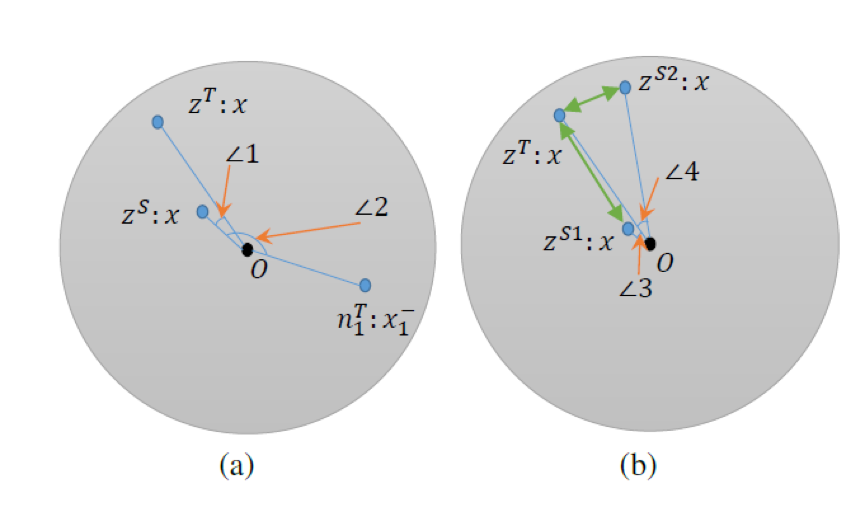
Unlike previous contrastive learning methods that used Euclidean distance or mutual information as loss, this paper proposes a cosine angle metric to conduct contrastive learning. As shown in the figure below:
(a) In the feature space, ZS and ZT are closer in angle, while the angle difference with negative examples nT increases.
(b) For different students fs1 and fs2 (the semantics of student fs1 are closer to the teacher’s semantics): in Euclidean distance (green), Zs2 is closer to ZT, but in cosine-based distance measurement, Zs1 is relatively closer to ZT than Zs2, demonstrating that cosine-based distance is more aligned with semantic feature expression measurement.
The COS-based NCE loss formula is as follows, g(..,..) -> [0,2] is used to measure the angle distance between two vectors. The smaller g(x,y) is, the more similar the two vectors are; g(x,y)=2 indicates a boundary state of dissimilarity. The design motivation for COS-NCE is to minimize the angle distance between ZS and ZT, while maximizing the angle distance between ZS and NT.
As shown in the figure below, g(niT, zS) and g(zT, zS) need to be amplified. This paper’s approach is to transform the maximization problem into a minimization problem, specifically defined as:2-(g(niT, zS) -g(zT, zS)).
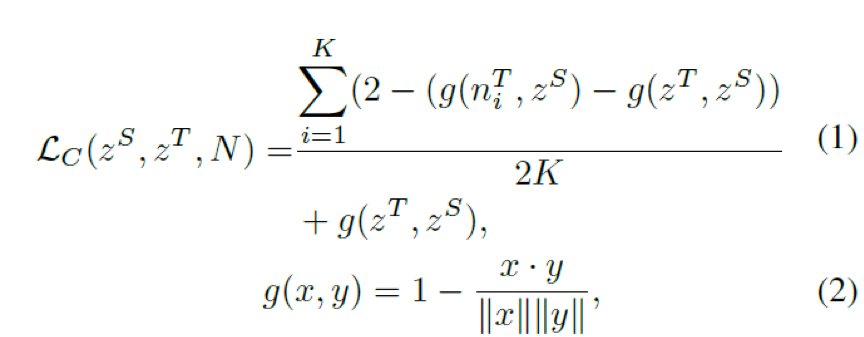
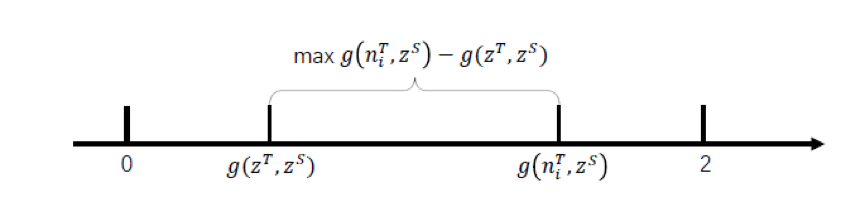
3.4 Distillation for Transformer Layer
COS-NCE is used for transformer-layer distillation, where each transformer layer includes multi-head attention and FFN. This paper focuses on distilling the output of the FFN. Here, we assume the teacher has N transformer layers, and the student has M transformer layers.
We choose to use a uniform method to complete the mapping between the teacher’s N transformer layers and the student’s M transformer layers. The formula is as follows, hiS ∈ Rl×d represents the output of the i-th transformer layer of the student network. hφiT ∈ Rl×d‘ represents the output of the φi-th transformer of the teacher network. j = φi is the layer mapping function for the student to learn the corresponding layer output from the teacher, where l denotes the text length, and d‘ and d denote the hidden sizes of the teacher and student (d’s dimension is less than d’).
HiT = { h0,iT, h1,iT, …….., hk-1,iT } corresponds to the i-th transformer of the teacher network with K negative samples. W ∈ Rd×d‘ is the dimensional mapping parameter, aiming to align the hidden sizes of the student and teacher.
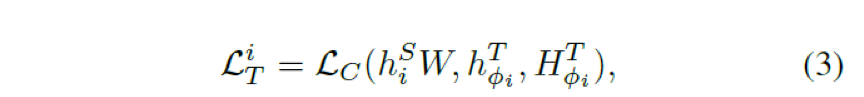
3.5 Distillation for Predict Layer
To better adapt to downstream prediction tasks, this paper uses the student’s prediction layer output to learn the teacher’s prediction layer output, i.e., soft loss. Meanwhile, the student learns the real label, i.e., hard loss. KL divergence is used for the student to learn the teacher’s prediction distribution, and cross-entropy loss is used for the student to learn the real label.
yS and yT are the prediction outputs of the student and teacher, respectively, t controls the smoothness of the output distribution, and y is the true label. Formula 6 is the final loss function, where α, β, and γ are the weighting coefficients for different losses.
To enable the model to learn intermediate layer expressions more efficiently, this paper adopts a two-stage training method. In the first stage, we focus on the intermediate layer’s contrastive loss, setting α, β, and γ to 1, 0, and 0, respectively. In the second stage, β and γ are set greater than 0 to ensure the model can predict downstream tasks.
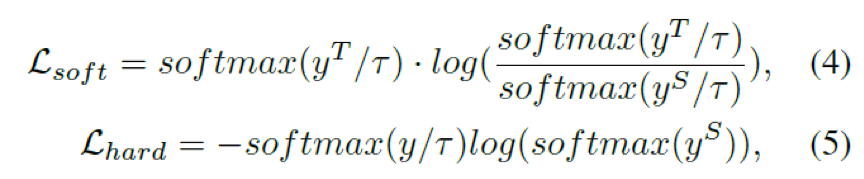
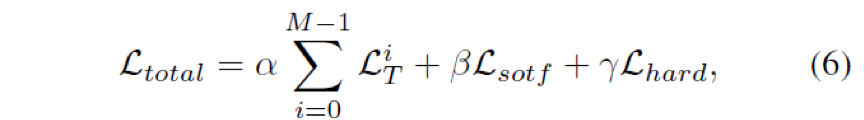
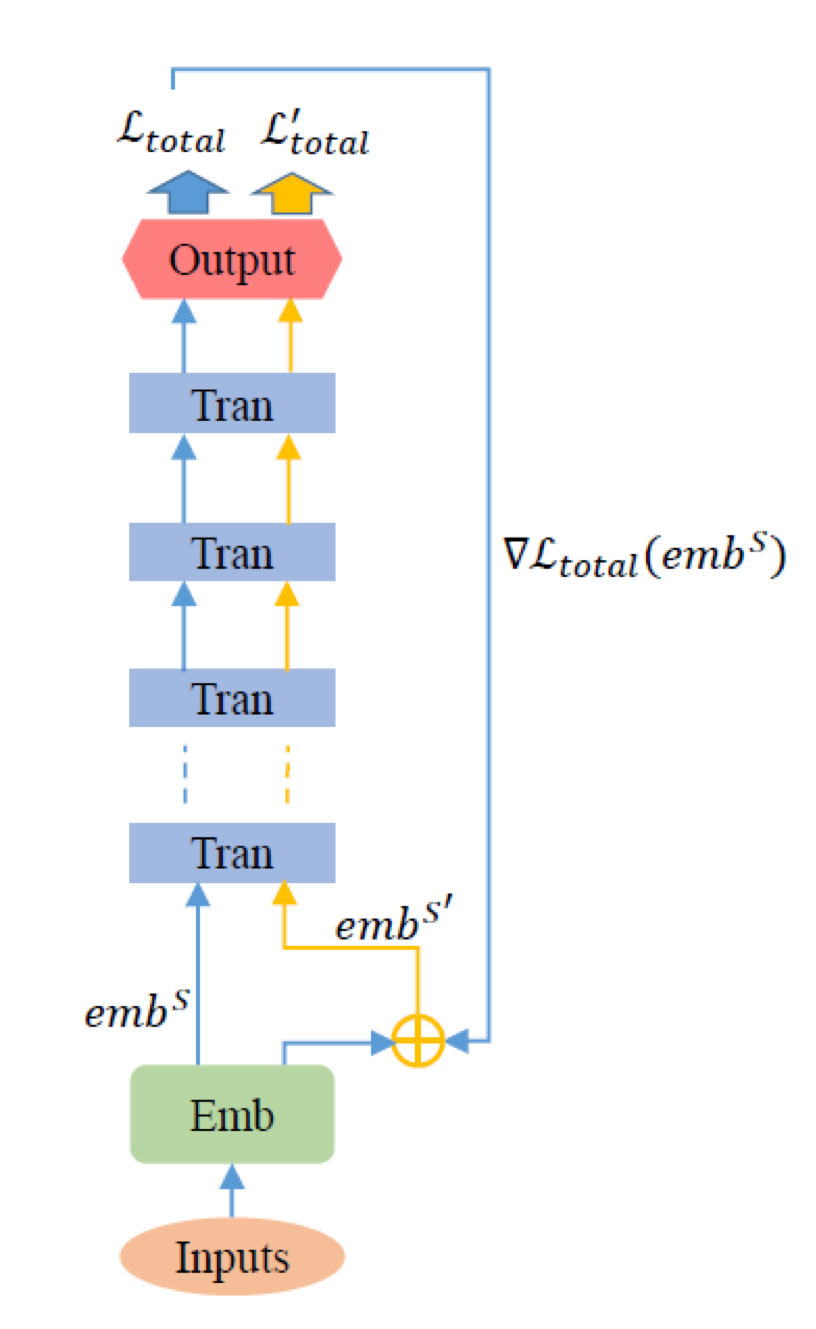
3.6 Training Based on Gradient Perturbation
The model structure is an important factor affecting robustness, so how to make the model more robust has become a significant focus in model compression algorithms. Previously, regularization was introduced in model compression pruning algorithms to increase reliability, while this paper introduces gradient perturbation technology to enhance the robustness of LRC-BERT.
The figure below illustrates the gradient perturbation process. This paper does not directly use Ltotal for backpropagation on the model; instead, it first calculates the gradient of the embedding ▽Ltotal(embS) and applies it to the input of embS for perturbation. Finally, the loss after gradient perturbation is used to update the model parameters. The formula indicates that embS’ is the representation with added gradient perturbation.
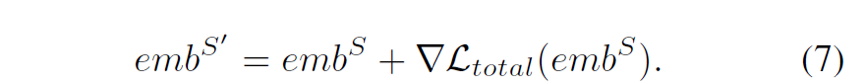
Experiments
4.1 Dataset
GLUE Benchmark https://gluebenchmark.com/ (General Language Understanding Evaluation) is an important metric for measuring the level of natural language understanding technology. The dataset includes nine tasks such as natural language inference, semantic similarity, question-answer matching, and sentiment analysis. This paper evaluates LRC-BERT on the GLUE dataset.
4.2 Experimental Parameter Settings
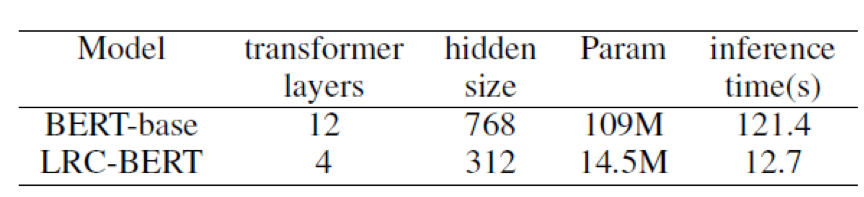
This paper uses BERT-Base as the teacher, which includes 12 transformer layers, each containing 12 attention heads, 768 hidden sizes, and 3072 intermediate sizes. The student network uses 4 transformer layers, each containing 12 attention heads, 312 hidden sizes, and 1200 intermediate sizes. To better validate the effectiveness of LRC-BERT, this paper sets up two model groups: LRC-BERT includes pre-training (using Wikipedia corpus) and specific tasks distillation; LRC-BERT1 directly conducts specific tasks distillation.
In the distillation experiment, learning rates were chosen as {5e-5, 1e-4, 3e-4}, with a batch size of 16. For datasets with less than 10K training data like MRPC, RTE, and CoLA, 90 epochs were used; other datasets used 18 epochs. The two-stage experiment settings used 80% of the steps for the first stage {α:β:γ = 1:0:0}, and the remaining 20% of the steps for the second stage training {α:β:γ = 1:1:3}, with t set to 1.1.
4.3 Main Experimental Results
The main experimental results are as follows: (1) LRC-BERT significantly outperforms DistillBERT, BERT-PKD, and TinyBERT. The average prediction performance of LRC-BERT retains 97.4% of BERT-base’s performance, demonstrating its effectiveness. (2) On datasets with a large amount of training data (>100K), LRC-BERT1 directly distills on downstream tasks. Compared to TinyBERT, it improves by 0.3%, 0.8%, 0.6%, and 0.6% on MNLI-m, MNLI-mm, QQP, and QNLI, respectively. (3) LRC-BERT improves by 4%, 12.1%, and 14.9% compared to LRC-BERT1 on MRPC, RTE, and CoLA, respectively.
Another important reference metric is the model inference speed. As shown in the figure below, LRC-BERT achieved a 9.6× speedup, and a 7.5× benefit in model size.

4.4 Ablation Experiments
Ablation experiments were conducted on the MNLI-m, MNLI-mm, MPRC, and CoLA datasets to analyze the loss function and gradient perturbation.
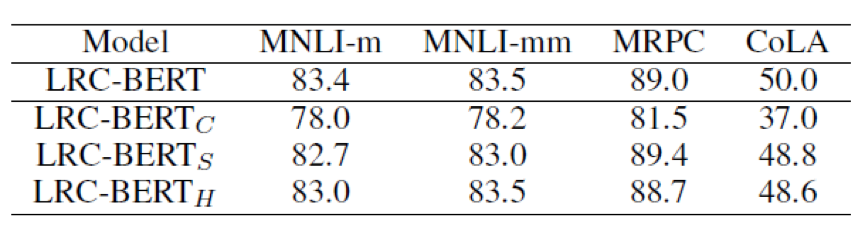
Effect of different loss functions: This paper removes COS-NCE, soft loss, and hard loss to validate the model’s effectiveness, represented by LRC-BERTC, LRC-BERTS, and LRC-BERTH, respectively. As shown in the figure below, removing COS-NCE, which has the greatest impact, results in the worst performance in the following experiments, especially in the CoLA dataset, where the effect drops from 50 to 37. The soft loss and hard loss have limited effects on the final result. Thus, all three losses are effective for LRC-BERT.
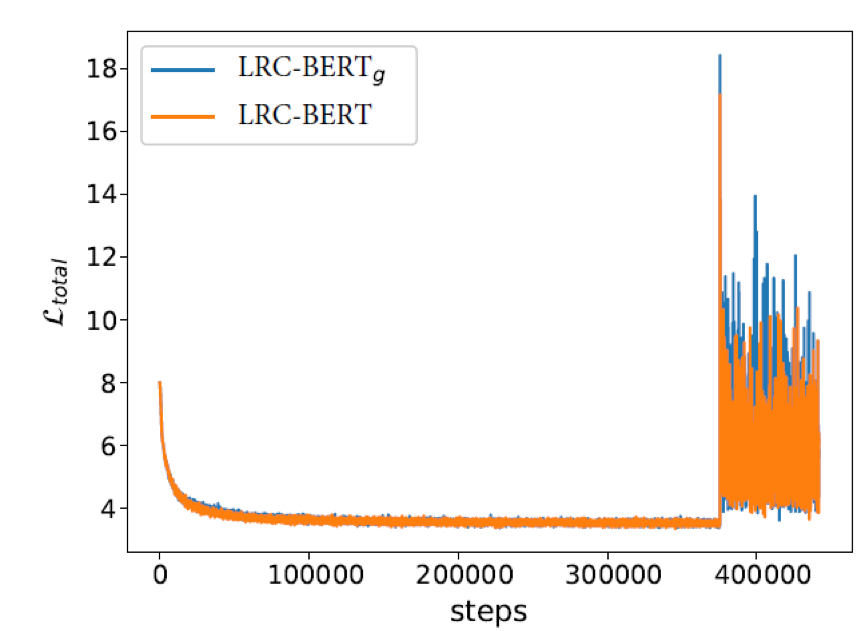
Effect of gradient perturbation: Gradient perturbation can affect the intermediate layer data distribution during training. The model LRC-BERTg is used to validate the effect of removing gradient perturbation. The figure below shows the change in training loss during MNLI-m training; in the second stage, the loss amplitude of LRC-BERT is reduced compared to LRC-BERTg, stabilizing LRC-BERT.
Analysis of Two-stage Training Method: The purpose of the two-stage approach is to allow the student to focus more on learning the teacher’s intermediate layer expression in the early training phase. LRC-BERT2 is set to remove the two-stage training and directly adopt {α:β:γ = 1:1:3} for training on MNLI-m. The results are shown in the figure below; the performance drops significantly without the two-stage training, which also demonstrates the role of COS-NCE in intermediate layer distillation.

Analysis of Two-stage Training Method: COS-NCE uses cosine angle distance for distillation of the intermediate layer transformer, while this paper employs BERTM (using MSE to replace COS-NCE as the loss) for comparison. Random case analysis shows that the first two cases predict correctly for LRC-BERT and BERTM, while the latter two cases exhibit fluctuations in predictions leading to errors for BERTM. The angular distance of LRC-BERT remains within the expected range, indicating that LRC-BERT can effectively capture deep semantic information.

Implementation in Gaode’s Specific Business Scenarios
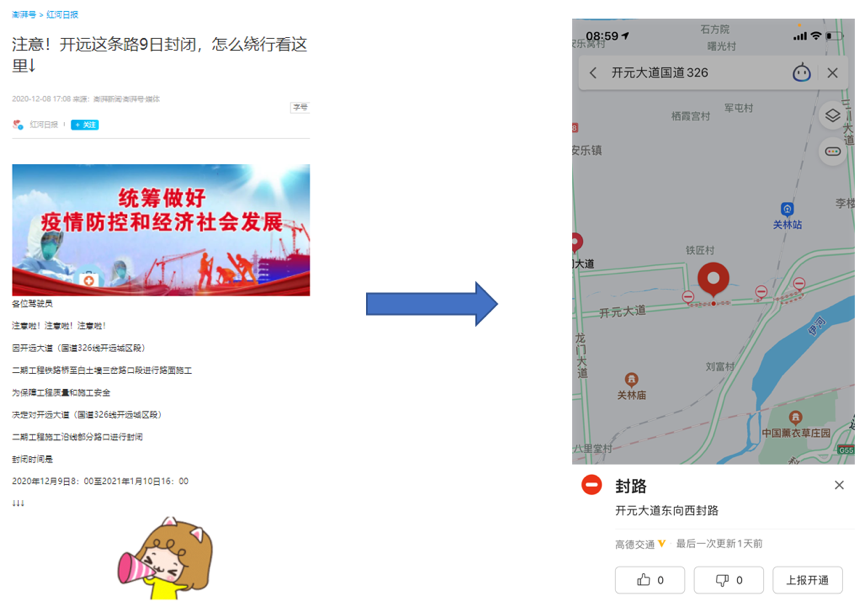
Dynamic events refer to user travel events affected by changes in road capacity, including closures, construction, accidents, etc. As a crucial means of acquiring traffic dynamic events, the NLP event extraction business primarily collects information from official traffic platforms and various media platforms, undergoing named entity recognition and event splitting and combination to finally output dynamic events, which impact Amap users’ route planning, as illustrated in the example below.
The method proposed in this paper has been implemented in Gaode’s traffic dynamic event extraction, with LRC-BERT retaining 97% of BERT-base’s performance, improving accuracy by 4% and recall by 3% on weekdays; accuracy improved by 5% and recall by 7% on holidays. Furthermore, this method has a simple training process, low reproduction cost, and can be widely applied across various business lines using Natural Language Understanding (NLU), enhancing model inference speed and reducing deployment costs.
Conclusion
This paper innovatively proposes a contrastive learning framework for knowledge distillation and introduces COS-NCE LOSS to effectively capture potential semantic information. The gradient perturbation technique is introduced into knowledge distillation for the first time, with experiments validating its ability to enhance model robustness.
To more efficiently extract potential semantic information from intermediate layers, a two-stage model training method is adopted. The GLUE Benchmark experimental results demonstrate the effectiveness of the LRC-BERT model.
