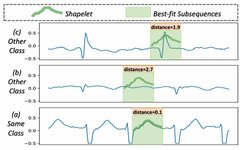
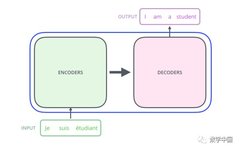
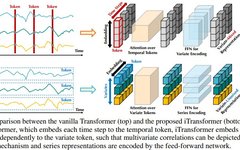
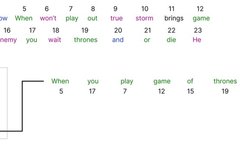
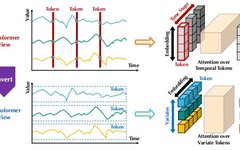
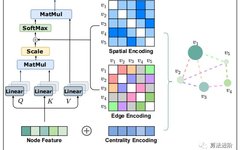
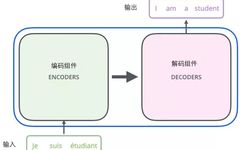
Overview of Transformer Pre-trained Models in NLP
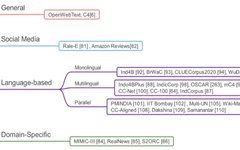
The revolution brought by the Transformer in the field of natural language processing (NLP) is beyond words. Recently, researchers from the Indian Institute of Technology and biomedical AI startup Nference.ai conducted a comprehensive investigation of Transformer-based pre-trained models in NLP and compiled the results into a review paper. This article will roughly translate and introduce … Read more