The revolution brought by the Transformer in the field of natural language processing (NLP) is beyond words. Recently, researchers from the Indian Institute of Technology and biomedical AI startup Nference.ai conducted a comprehensive investigation of Transformer-based pre-trained models in NLP and compiled the results into a review paper. This article will roughly translate and introduce this paper, focusing on the discussion section where the researchers highlighted new research opportunities in the field. It is worth noting that the researchers named the paper “AMMUS”, which stands for AMMU Smiles, in memory of their friend K.S.Kalyan.

-
Section 2 will briefly introduce self-supervised learning, which is the core technology of T-PTLM.
-
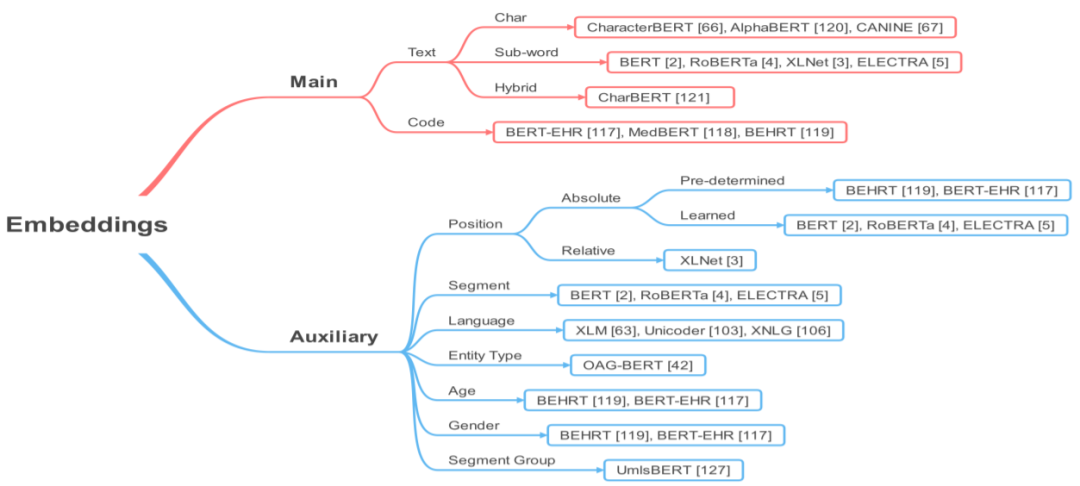
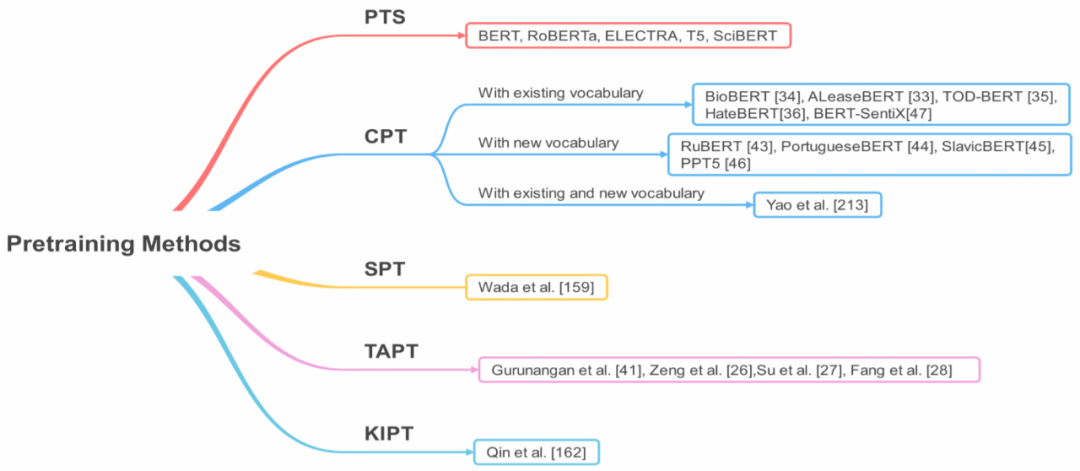
Section 3 will introduce some core concepts related to T-PTLM, including pre-training, pre-training methods, pre-training tasks, embeddings, and downstream adaptation methods.
-
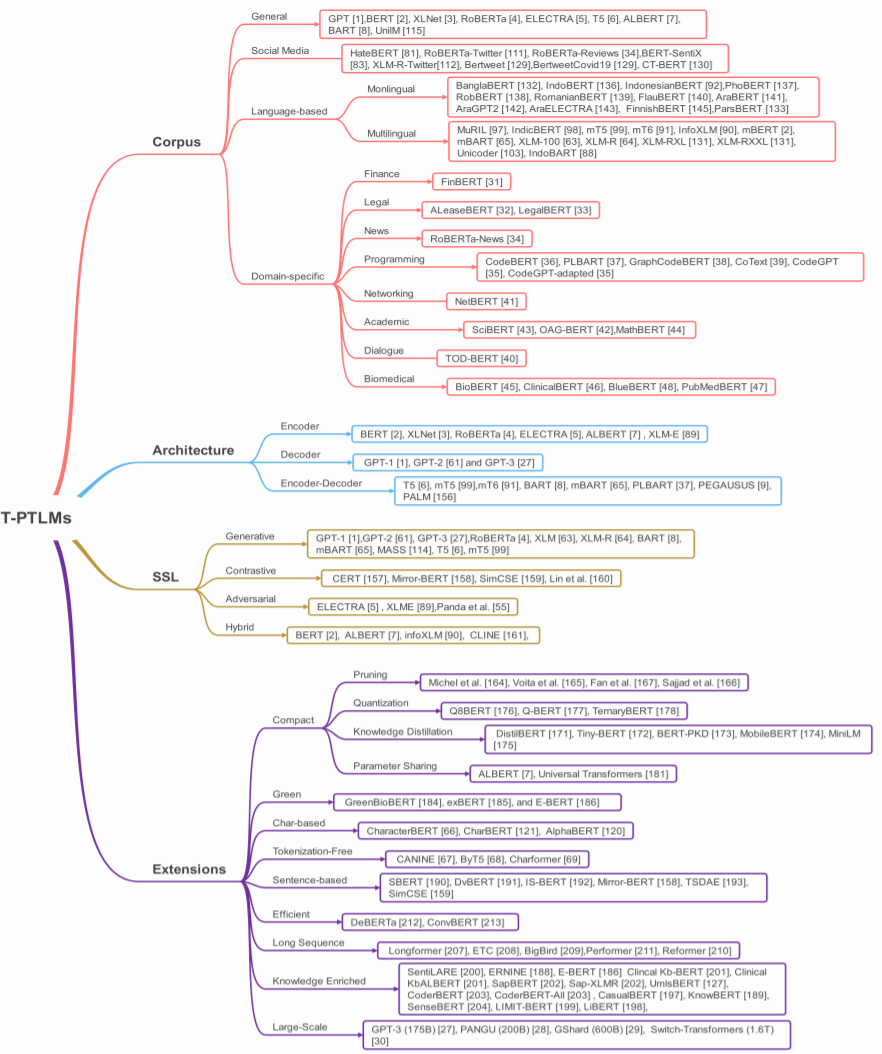
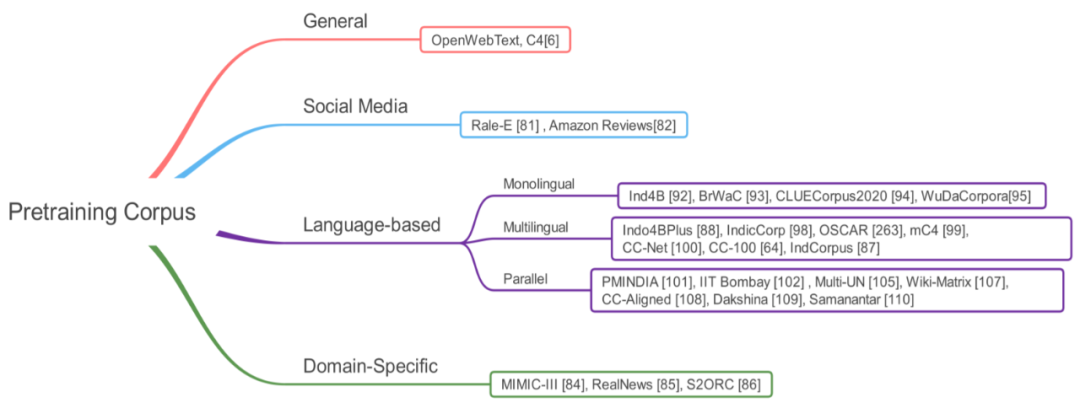
Section 4 will provide a new classification method for T-PTLM, considering four aspects: pre-training corpus, architecture, types of self-supervised learning, and expansion methods.
-
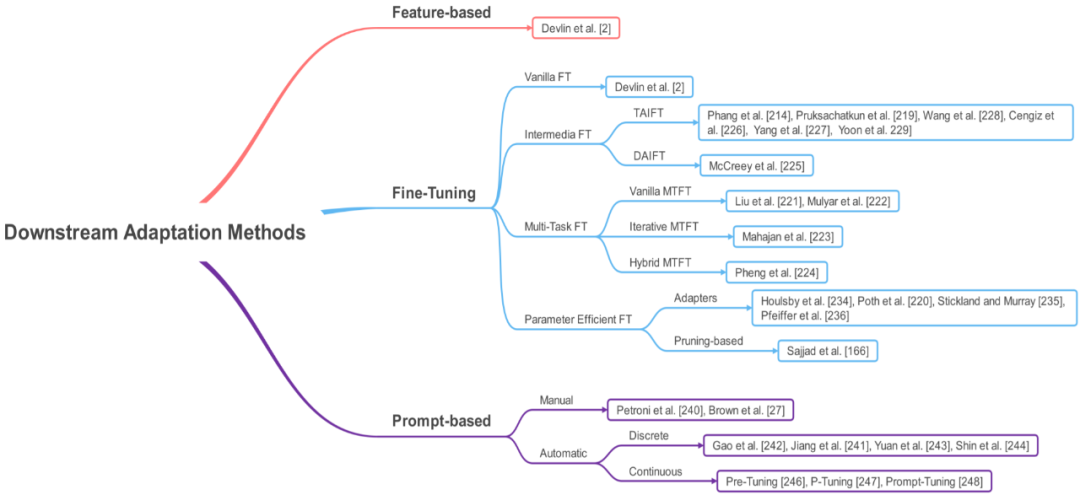
Section 5 will provide a new classification method for different downstream adaptation methods and explain each category in detail.
-
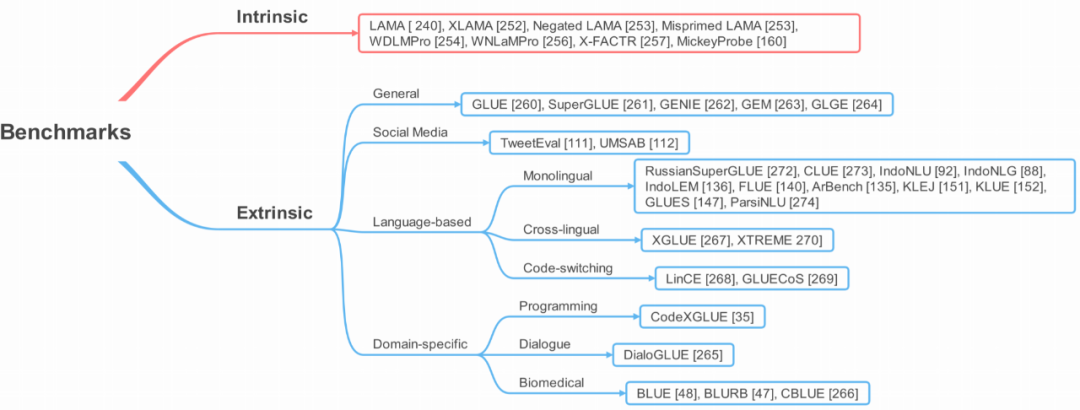
Section 6 will briefly introduce various benchmarks used to evaluate the progress of T-PTLM, including internal and external benchmarks.
-
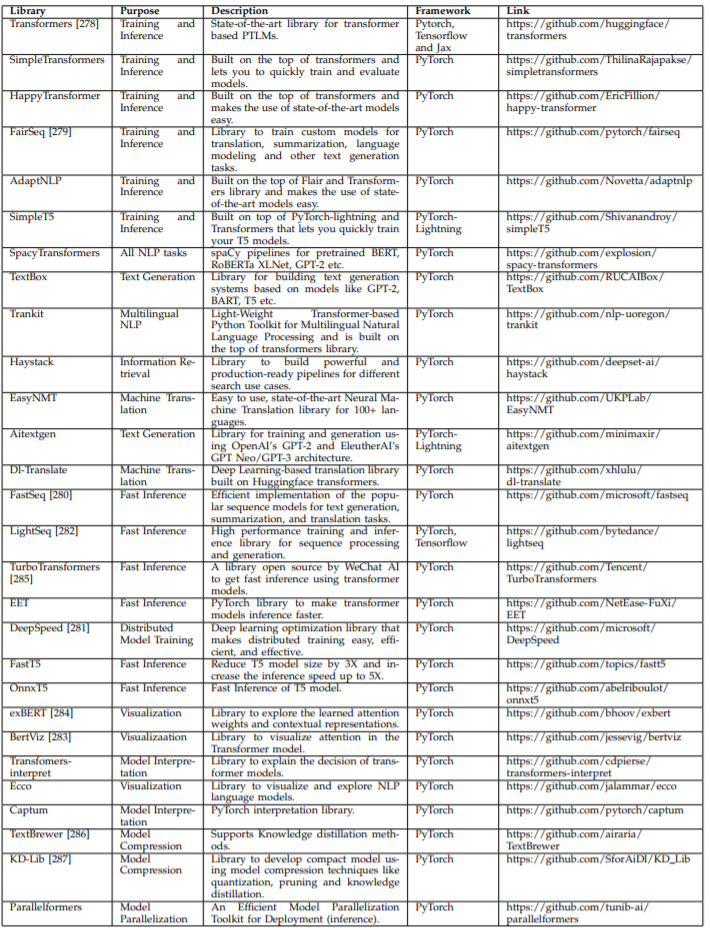
Section 7 will provide some software libraries applicable to T-PTLM, from Huggingface Transformers to Transformer-interpret.
-
Section 8 will briefly discuss some future research directions that may help further improve these models.
-
Heavily relies on human-annotated instances, which are time-consuming and labor-intensive to obtain.
-
Lacks generalization ability and is prone to false correlation issues.
-
Many fields, such as healthcare and law, lack labeled data, which limits the application of AI models in these areas.
-
It is difficult to learn using a large amount of freely available unlabeled data.
-
Learn universal language representations that can provide excellent background for downstream models.
-
Obtain better generalization ability by learning from a large amount of freely available unlabeled text data.
-
By leveraging a large amount of unlabeled text, pre-training helps the model learn universal language representations.
-
Pre-trained models can adapt to downstream tasks by adding just one or two task-specific layers. Therefore, this provides a good initialization, avoiding the need to train downstream models from scratch (only training task-specific layers).
-
Allows models to achieve better performance with small datasets, thus reducing the need for a large number of labeled instances.
-
Deep learning models tend to overfit when trained on small datasets due to their large number of parameters. Pre-training can provide good initialization, thus avoiding overfitting on small datasets, and can be seen as a form of regularization.
-
Prepare the pre-training corpus
-
Generate the vocabulary
-
Design pre-training tasks
-
Select pre-training methods
-
Select pre-training dynamics
-
Casual Language Modeling (CLM)
-
Masked Language Modeling (MLM)
-
Replacement Token Detection (RTD)
-
Shuffled Token Detection (STD)
-
Random Token Replacement (RTS)
-
Swapped Language Modeling (SLM)
-
Translation Language Modeling (TLM)
-
Alternative Language Modeling (ALM)
-
Sentence Boundary Objective (SBO)
-
Next Sentence Prediction (NSP)
-
Sentence Order Prediction (SOP)
-
Sequence-to-Sequence Language Model (Seq2SeqLM)
-
Denoising Autoencoder (DAE)