
Source: “Communications of the China Computer Federation” 2015 Issue 3 “Special Topic”
Authors: Liu Shujie, Dong Li, Zhang Jiajun, et al.
Introduction to Deep Learning
Deep learning is one of the most rapidly developing fields in machine learning in recent years. Strictly speaking, deep learning is not a completely new machine learning method, but a synonym for learning methods based on deep neural networks (Deep Neural Network, DNN). The deep neural networks here are almost identical to the traditional multilayer neural networks. The reason deep learning has regained high attention in academia after years of silence is due to its groundbreaking achievements in a series of important artificial intelligence tasks. For example, in the iconic benchmark task of handwritten digit recognition in machine learning, deep learning can reduce the error rate from 1.4% (SVM model) to 0.39%[1]; in the field of speech recognition, deep learning historically reduced the error rate from 27.4% to 18.5%[2].
A notable characteristic of modern deep learning methods is their ability to perform automatic feature learning. Effective feature extraction is a common foundational element for various machine learning methods. Given a learning task, such as speech recognition, face detection, or machine translation, the first question to address is what kind of features are most useful for the task. Discovering and selecting effective features is crucial for the performance of machine learning. Features can be defined by experts or learned by machines. Allowing machines to automatically learn features is called feature learning.
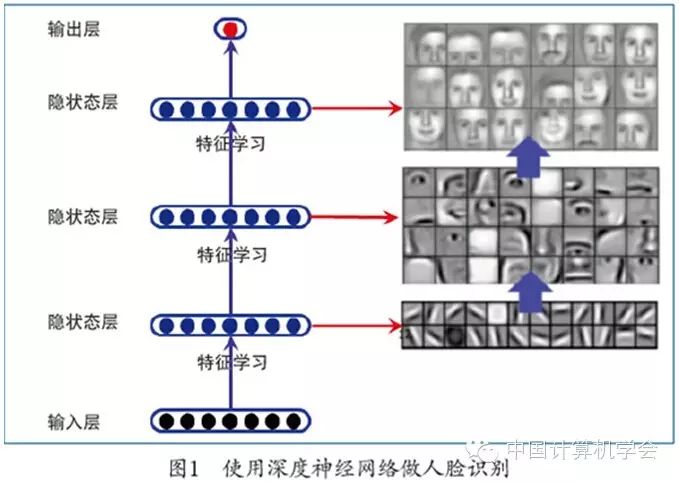
Deep learning is a type of feature learning. Unlike most simple feature learning methods, deep learning methods can automatically learn a hierarchical structure of features. In this hierarchy, high-level features are constructed from low-level features, and different combinations of different low-level features can construct different high-level features. As shown in Figure 1, using deep neural networks, the first-level features can be learned from raw pixel inputs to describe points and lines; using the first-level features, the second-level features can be learned to describe higher-level features such as eyes, noses, and car tires; deep neural networks can also learn more specific features describing faces, cars, etc.
Structurally, deep neural networks are forward multilayer neural networks, proposed by Warren McCulloch in 1943[3]. The term “deep” refers to being relative to single-layer neural networks (perceptron model). As shown in Figure 1, multilayer neural networks have an input layer, multiple hidden state layers, and an output layer (which can be a vector). Each layer takes the next layer as input and obtains the state of that layer through a linear or nonlinear function.
Deep neural networks typically use backpropagation methods for training, but due to the large number of layers and unstable training results caused by random initialization, deep neural networks have not been widely promoted in practical applications. Until 2006, Hinton and others used a layer-wise unsupervised pre-training method based on restricted Boltzmann machines (RBM) to achieve breakthroughs in digital image recognition (reducing the error rate to 1.4%)[4]. Subsequently, Bengio and Salakhutdinov proposed an autoencoder-based pre-training method, which also achieved good results (reducing the error rate to 1.2%)[5].
The training framework of deep learning is divided into two parts: layer-wise unsupervised pre-training and supervised backpropagation. During unsupervised pre-training, starting from the first layer’s hidden state, unsupervised learning is performed using restricted Boltzmann machines or autoencoders to obtain the parameters of that layer from the given input, and then that layer is fixed as input to the second layer, using the same unsupervised learning method to obtain the second layer’s parameters. This layer-wise unsupervised pre-training can provide a good initial parameter for the next step of supervised backpropagation.
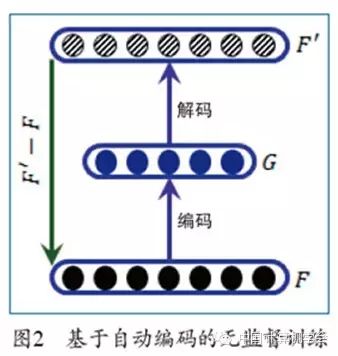
Given the current layer’s state, how can we use unsupervised training methods to obtain the next layer’s state and the parameters connecting the two layers? Here, we briefly introduce the training method based on autoencoders. As shown in Figure 2, suppose the current layer is an n-dimensional vector F (its value is fixed as input), and the next layer is an m-dimensional vector G. First, construct an n-dimensional output layer F’, and randomly initialize the parameters of the two layers. Given input F, the hidden layer’s state G, and obtain the output layer’s result F’, then use the difference between F and F’ as loss for backpropagation to update the parameters of both layers. This constructed single hidden layer neural network can be understood as encoding the input F to obtain the hidden layer G and decoding the hidden layer G to obtain the input F. If m < n, the parameters obtained from such training can compress and reduce the dimensionality of F under minimal encoding loss. If m ≥ n, we need to add regularization terms (L1 or L2) to the loss function to perform sparse coding or dimensionality increase.
Deep Learning in Natural Language Processing
With the groundbreaking progress in speech and image processing, deep learning has also received increasing attention in the field of natural language processing (NLP) and is gradually being applied to various tasks in NLP. However, NLP tasks have their own characteristics, and the main differences from speech and image processing are reflected in the following two aspects.
-
The input signals in speech and image processing can be represented in vector space, while natural language processing typically operates at the vocabulary level. Converting independent words into vectors and using them as inputs to neural networks is the foundation for applying neural networks to NLP.
-
NLP tasks often involve various recursive structures. Language models, part-of-speech tagging, etc., require processing sequences, while syntactic parsing, machine translation, etc., correspond to more complex tree structures. Such structured processing usually requires special neural networks.
Word Vectorization Representation
Words are the basic units of natural language processing. Vocabulary itself is usually applied as features in various NLP tasks within statistical models. In traditional research methods, vocabulary is usually represented in a one-hot form, that is, assuming the vocabulary size is V, the k-th word is represented as a vector of size V, where the k-th dimension is 1 and all others are 0. The disadvantage of this representation is that it cannot effectively capture the semantic information of words, meaning that regardless of how semantically related two words are, their one-hot vector representations are orthogonal. This representation also easily leads to data sparsity. When different words are applied as completely different features in statistical models, the infrequent words appearing in the training data lead to biased estimates for the corresponding features.
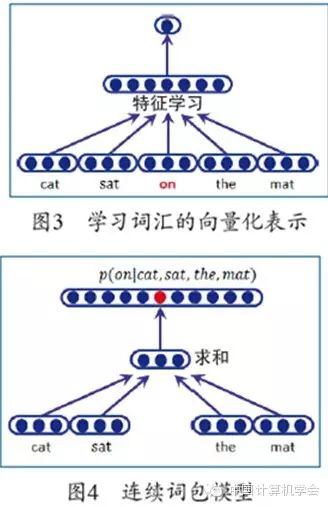
Collobert et al. proposed a method using neural networks to automatically learn vectorized representations of vocabulary[6], based on the principle that the meaning of a word should be determined by the words surrounding it. As shown in Figure 3, each word in the vocabulary is first randomly initialized as a vector, and then large-scale monolingual corpora are used as training data to optimize this vector, ensuring that similar words have similar vector representations. The specific optimization method involves randomly selecting a segment of training data with a window size of n (in Figure 3, the window size is 4, and the segment is “cat sat on the mat”) as a positive example. The word vectors corresponding to phr+ are concatenated as the input layer of the neural network, and after passing through a hidden layer, a score f + is obtained. f + indicates whether this segment is a normal natural language segment. The middle word in the window is randomly replaced with another word from the vocabulary, resulting in a negative example segment phr-, which in turn gives a negative score f -. The loss function is defined as a ranking hinge loss, which ensures that the score of the positive example f + is at least 1 greater than the score of the negative example f -. The gradient of this loss function is obtained, and backpropagation is used to learn the parameters of each layer of the neural network while also updating the word vectors in positive and negative example samples. This training method can cluster words that are suitable to appear in the middle position of the window while separating those that are not suitable, thereby mapping semantically (grammatically or part-of-speech) similar words to nearby positions in vector space.
Unlike the method of replacing the middle word, Mikolov et al. proposed a continuous bag-of-words model (CBOW)[7] that uses surrounding words to predict the middle word. As shown in Figure 4, the continuous bag-of-words model directly sums the vectors of adjacent words to obtain the hidden layer and uses the hidden layer to predict the probability of the middle word. Like the bag-of-words model, it uses direct summation, so the position of surrounding words does not affect the prediction result, hence it is also called a bag-of-words model. Mikolov et al. also proposed a continuous skip-gram model[7]. In contrast to the prediction method of the continuous bag-of-words model, the continuous skip-gram model predicts surrounding words’ probabilities based on the middle word. These two models were developed based on the open-source tool word2vec. Huang et al. combined the context of words in sentences with global context to learn word vector representations. The global context is the weighted average of all word vectors in the document where the word appears[8]. Additionally, some studies have found that word vectors learned using neural network methods can capture interesting linear relationships, such as king – man + woman ≈ queen[9].
Due to the relatively easy acquisition of large-scale monolingual data, training neural networks to learn vectorized representations of vocabulary has become possible. The trained word vectors can be applied to other NLP tasks and to some extent alleviate the data sparsity caused by insufficient training data for specific tasks.
Language Models
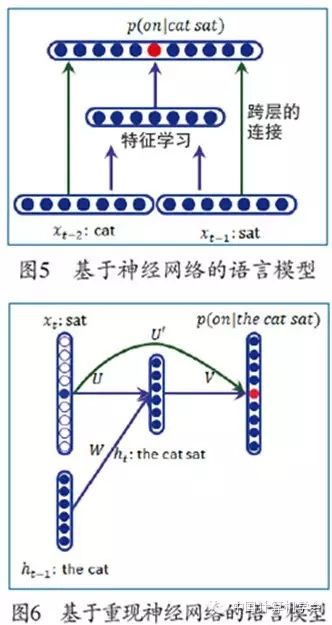
Traditional N-Gram language models also face data sparsity issues. To address this, Bengio and Schwenk proposed a neural network-based language model[10], as shown in Figure 5. This neural network has a structure similar to that in Figure 3, representing words as vectors and using them as inputs to the neural network. During training, the word vectors are optimized and updated. The difference in structure between Figure 5 and Figure 3 is the addition of skip layer connections, where the output depends not only on the hidden layer but also on the word vectors themselves, outputting the probability of the next word given the input word segment (here it is cat sat). This model ensures that the output is a vector of size equal to the vocabulary size through the final softmax layer, with the sum of the vector’s elements equal to 1. The computational demand of the softmax function is very high, resulting in slower training speeds. To solve this problem, Minih and Hinton first clustered the words, constructed a hierarchical binary tree, and converted the probability of predicting the next word into the probability of the path in the binary tree, thus replacing the softmax computation with multiple sigmoid functions, speeding up the training process.
The model in Figure 5 can only use limited history to predict the next word. To use more history, Mikolov et al. introduced recurrent neural networks to train language models[11]. Recurrent neural networks allow the newly generated historical states to serve as inputs to the next time point’s neural network (with parameters unchanged), forming a recursive structure. As shown in Figure 6, the input layer of the recurrent neural network is divided into two parts: one part is the current word xt, and the other part is the historical state ht-1 at time t-1. xt and ht-1 are combined through the neural network to generate the current historical vector ht, which, together with xt, predicts the next word. The recurrent neural network can theoretically maintain infinite history by continuously adding the information of the input word to the historical vector. Figure 6 shows the generation of the current history “the cat sat” using the previous history “the cat” and the current word “sat”, predicting the next word “on”. The newly generated history “the cat sat” then predicts the next word “the” together with the newly generated word “on”.
Syntactic Parsing
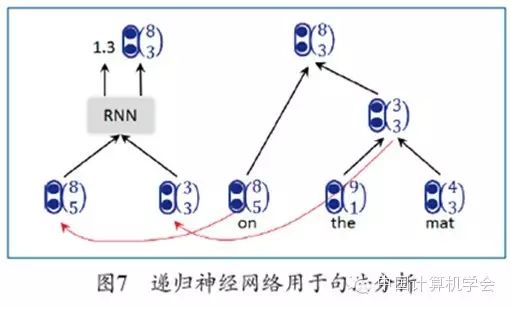
Socher et al. proposed using recursive neural networks (RNN) to predict tree structures[12]. The input layer of the recursive neural network has two parts, representing the vector representations of the left and right child nodes, respectively. The vector representations of the two child nodes are processed through the neural network to generate the vector representation of the parent node and simultaneously generate a score. This score indicates the credibility of creating the parent node. As shown in Figure 7, the representations of the left and right child nodes are (8, 5) and (3, 3), respectively, generating the parent node’s vector representation (8, 3) and a credibility score of 1.3. The parent node’s vector representation can also be combined with other child nodes through the same recursive neural network to form a larger parent node. This recursion continues until the root node representation of the entire sentence is generated, forming a complete syntactic parse tree. The overall credibility score of the tree is the sum of the credibility scores of all nodes. Based on the vectorized representation of each node, a softmax layer can be added to compute the probability of each node corresponding to syntactic labels. The leaf nodes of the syntactic parse tree are the words in the sentence, and the vector representations of the leaf nodes are initialized using the word vectors obtained through training on large-scale monolingual data and updated through the recursive neural network.
To better describe the information of different syntactic structures, Socher expanded the standard recursive neural network into a compositional vector grammar[13]. The standard recursive neural network uses the same parameters to combine child nodes, calculating the credibility of the parent node and the probability of syntactic labels; whereas the compositional vector grammar uses different parameters for different syntactic labels. For example, when two nodes (with syntactic labels B and C) combine to generate a new parent node, a corresponding neural network for types B and C is used; when D and E combine to form a parent node, another neural network is used. This allows the trained neural network to more accurately describe the combination forms and semantic information of different syntactic structures. To further improve model performance, Socher et al. combined the compositional vector grammar with probabilistic context-free grammar (PCFG)[13]. When child nodes with syntactic labels B and C generate the parent node D, the credibility score is calculated as: s(D) = (v(B,C))TD + logP(D→B C), where (v(B,C))TD represents the credibility score obtained from the parent node’s vector representation, and logP(D→B C) represents the logarithm of the probability of the rule D→B C in the PCFG.
Machine Translation
Deep neural networks have also been introduced into statistical machine translation research. Yang et al. borrowed and expanded the CD-DNN-HMM model from speech recognition and applied it to word alignment[14]. This method addresses the data sparsity issue of alignment through word vectors while also introducing context for disambiguation in translation. Auli et al. expanded recurrent neural networks by incorporating source language information through word alignment, proposing a joint model for translation and language[15]. The scoring of this joint model is added as a feature to the log-linear model, improving translation performance. Liu et al. proposed an additive neural network to describe translation probabilities. This method inputs word vectors trained from monolingual data into a single hidden layer neural network, outputting a translation probability based on the word vectors[16].
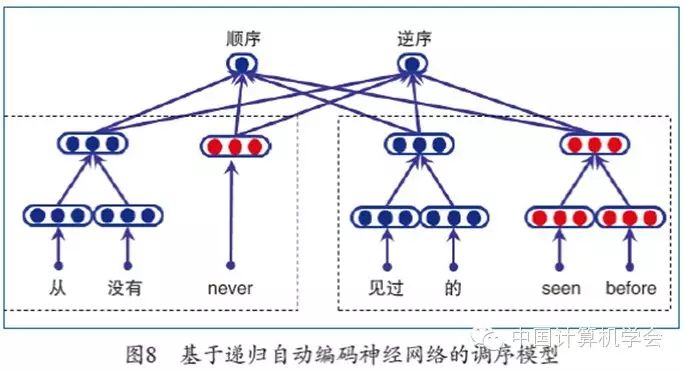
The maximum entropy reordering model based on vocabulary uses boundary words as features to determine whether the target language segment is in order or reversed. Li et al. proposed a method using recursive auto-encoding neural networks to utilize the entire segment’s information[17]. The recursive auto-encoding neural network initializes the parameters of the recursive neural network using the auto-encoding principle, that is, given two child nodes, obtaining the parent node’s encoding through a recursive neural network, and then attempting to restore the input of the two child nodes based on the parent node’s encoding. As shown in Figure 8, the recursive auto-encoding neural network can recursively generate vector representations of source and target language segments starting from word vectors and obtain probabilities for ordered and reversed sequences based on the source and target language segments of the two translation pairs.
Zhang et al. applied the recursive auto-encoding neural network to learn bilingual segment vector representations[18] (as shown in Figure 9), but the separately generated vector representations for source and target languages do not have semantic correspondence. To obtain semantic relevance, they trained the neural network using an interactive optimization approach, first fixing the vector representation of the target language segment; then optimizing the source language neural network based on that vector representation; and finally fixing the vector representation of the source language segment to optimize the target language neural network. This bilingual constraint on the segment representations applied to the probability estimation of statistical machine translation achieved significant results.
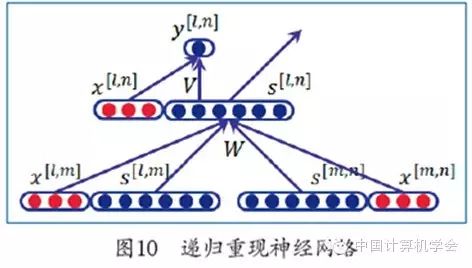
Traditional recursive neural networks do not incorporate new information when combining two child nodes, unlike recurrent neural networks. To introduce language model knowledge into recursive neural networks and model the decoding process of statistical machine translation, Liu et al. proposed the recursive recurrent neural network (R2NN) method, combining recursive neural networks and recurrent neural networks[19]. As shown in Figure 10, the recursive recurrent neural network introduces three input layers into the recursive neural network, representing additional input information for the two child nodes and additional information for the parent node. The former is used to generate the parent node’s vector representation, while the latter generates the confidence score for the parent node. The recursive recurrent neural network can not only automatically learn useful features for translation but also naturally incorporate traditional features as additional information into the neural network model.
Cui et al. utilized the topic representations learned from deep neural networks for disambiguation in statistical machine translation[20]. Traditional methods often use information within sentences to disambiguate translations, whereas Cui et al.’s method retrieves documents related to the sentence to be translated using information retrieval techniques. These documents use deep neural network methods to learn the topic representations of sentences, thereby utilizing the consistency between the topic representations of translation candidates and the sentence’s topic representation for disambiguation.
Sentiment Analysis
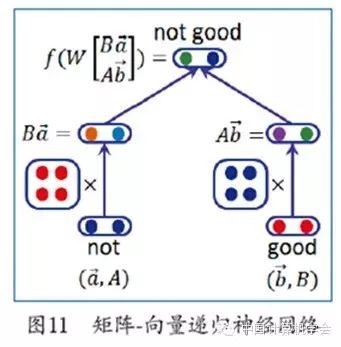
Understanding human emotions has always been a goal of artificial intelligence. Currently, deep learning is primarily used to determine the emotional category and intensity of a given text. To better address the semantic compositionality issue in sentiment analysis (e.g., the emotional polarity of “not very fond” is opposite to “fond”), some research works utilize the recursive nature of natural language and the compositionality of semantics, using recursive neural networks to model the emotional semantics of sentences. Socher et al. built upon the recursive auto-encoding model, adding supervised information about emotional categories in addition to using reconstruction loss[21]. This semi-supervised recursive auto-encoding model can retain more emotional information when constructing phrase vector representations from word vectors. The syntactic parse tree is used to determine the order of semantic composition, replacing the greedy search for the minimal loss recursive structure in the recursive auto-encoding model. To better handle the semantic composition of sentiment analysis, Socher et al. proposed the Matrix-Vector Recurrent Neural Network (MV-RNN). As shown in Figure 11, each word has not only a vector but also a matrix representing a certain semantic operation. During semantic composition, two semantic operation matrices are applied to the other half, and then semantic composition is performed to obtain the vector representation of the phrase. To describe the interaction between two vectors, Socher et al. further proposed the recursive tensor neural network[22]. Unlike ordinary neural networks, the recursive tensor neural network uses tensor-based composition functions instead of the original linear functions to expand the capability of the semantic composition function. Similarly, to address the semantic composition issue, Dong et al. proposed the Adaptive Recursive Neural Network (AdaRNN). In constructing phrase vector representations, the adaptive recursive neural network adaptively uses multiple semantic composition functions based on the current composition vector[23]. This allows the emotional semantic operation information of each word to be embedded into the word vectors, which can then be used to select different semantic composition functions. By combining dependency tree information, Dong et al. applied the adaptive recursive neural network to solve target-dependent sentiment classification tasks[24].
Kalchbrenner et al. introduced dynamic k-max pooling techniques into convolutional neural networks to handle the variable length characteristics of natural language, achieving good results in sentiment classification tasks[25]. Quoc et al. introduced paragraph vectors into neural network language models to represent global semantic information, thus deriving vector representations for paragraphs (or sentences). By incorporating supervised information about emotional categories, improvements were achieved in both sentence-level and document-level sentiment classification tasks[26].
To learn word vectors containing emotional information, Labutov et al. added supervised information about emotional classification to existing word vectors, ensuring that the newly modified word vectors are as similar as possible to the original vectors while performing better on classification tasks. Experimental results show that modified word vectors for sentiment analysis tasks can achieve better classification results[27]. Tang et al. used emoji symbols from Twitter as weak labels, directly embedding emotional information into vector representations when learning word vectors[28], rather than modifying the word vectors learned through unsupervised methods. They extended this idea by using word (or phrase) vectors as features to automatically construct large-scale sentiment lexicons[29].
Other Natural Language Processing Tasks
Collobert et al. proposed a unified multi-task framework based on deep neural networks to handle part-of-speech tagging, shallow syntactic parsing, named entity recognition, and semantic role labeling in NLP, and released the open-source tool SENNA based on this framework[6]. Socher et al. used dynamic pooling techniques to resolve the issue of inconsistent sentence lengths and successfully applied recursive auto-encoding neural networks to paraphrase detection tasks[30]. Lu et al. combined deep neural networks with hierarchical topic models to solve complex multi-level matching problems, successfully applying them to automatic question answering and matching of Weibo comments[31]. He et al. used denoising auto-encoding neural networks to learn document representations, applying them to entity linking tasks with good results[32]. Bordes et al. applied deep neural networks to semantic disambiguation, significantly improving performance[33]. Wu et al. proposed using text-window-based denoising auto-encoding neural networks for Chinese word segmentation, significantly reducing error rates[34].
Outlook
Although deep learning has made significant progress in speech and image processing, language, being a unique artificial symbolic system, requires more research and exploration to apply deep learning to natural language processing: the learning of vocabulary representations for specific tasks and the exploration of relationships between vocabulary are receiving increasing attention; processing structured outputs of natural language requires more complex neural networks; complex neural networks impose new demands for efficient and parallel training algorithms. We believe that as more training data becomes available and computational power increases, deep learning will play an even more significant role in the field of natural language processing.
Figures:

 Author Introduction
Author Introduction

Liu Shujie
Associate Researcher at Microsoft Research Asia. Main research areas include statistical machine translation, natural language processing, and machine learning.
 Dong Li
Dong Li
Graduate student at Beihang University. Main research areas include sentiment analysis, natural language processing, and artificial intelligence.
 Zhang Jiajun
Zhang Jiajun
Member of CCF. Associate researcher at the Institute of Automation, Chinese Academy of Sciences. Main research areas include natural language processing, machine translation, and statistical learning.
Other authors: Wei Furui, Li Mu, Zhou Ming
References
[1] Marc’Aurelio Ranzato, Christopher Poultney, Sumit Chopra, et al. Efficient learning of sparse representations with an energy-based model. In J. Platt et al., editor, In Proceedings of NIPS, MIT Press, 2006.
[2] Seide, Frank, Gang Li, and Dong Yu. Conversational speech transcription using context-dependent deep neural networks. Proceedings of Interspeech, 2011:437~440.
[3] McCulloch, Warren S., and Walter Pitts. A logical calculus of the ideas immanent in nervous activity. The bulletin of mathematical biophysics 1943: 115~133.
[4] Hinton, G. E., Osindero, et al. A fast learning algorithm for deep belief nets. Neural Computation, 2006; 18: 1527~1554.
[5] Hinton, G. E. and Salakhutdinov, R. Reducing the dimensionality of data with neural networks. Science, 2006; 313(5786):504~507.
[6] Ronan Collobert, Jason Weston, Léon Bottou, et al. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011:2493~2537.
[7] Mikolov, Tomas, Kai Chen, et al. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013.
[8] Huang, Eric H., Richard Socher, et al. Improving word representations via global context and multiple word prototypes. Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers-Volume 1. Proceedings of ACL, 2012:873~882.
[9] Mikolov, Tomas, Wen-tau Yih, et al. Linguistic regularities in continuous space word representations. Proceedings of NAACL-HLT, 2013:746~751.
[10] Bengio, Yoshua, Holger Schwenk, et al. Neural probabilistic language models. Innovations in Machine Learning. Springer Berlin Heidelberg, 2006:137~186.
[11] Mikolov, T., Karafiát, M., Burget, et al. Recurrent neural network based language model. Proceedings of INTERSPEECH, 2010:1045~1048.
[12] Socher, R., Lin, C. C., Manning, C., & Ng, A. Y. Parsing natural scenes and natural language with recursive neural networks. Proceedings of ICML, 2011:129~136.
[13] Socher, R., Bauer, J., Manning, C. D., & Ng, A. Y. Parsing with compositional vector grammars. Proceedings of ACL, 2013.
[14] Yang Nan, Liu Shujie, Li Mu, et al. Word alignment modeling with context dependent deep neural network. Proceedings of ACL, 2013.
[15] Auli, Michael, Michel Galley, et al. Joint language and translation modeling with recurrent neural networks. Proceedings of EMNLP, 2013.
[16] Liu, Lemao, Taro Watanabe, Eiichiro Sumita, et al. Additive neural networks for statistical machine translation. Proceedings of ACL, 2013.
[17] Peng Li, Yang Liu, and Maosong Sun. Recursive autoencoders for ITG-based translation. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 2013:567~577.
[18] Jiajun Zhang, Shujie Liu, Mu Li, et al. Bilingually-constrained phrase embeddings for machine translation. Proceedings of ACL, 2014.
[19] Shujie Liu, Nan Yang, Mu Li, et al. A recursive recurrent neural network for statistical machine translation. Proceedings of ACL, 2014.
[20] Lei Cui, Dongdong Zhang, Shujie Liu, et al. Learning topic representation for SMT with neural networks. Proceedings of ACL, 2014.
[21] Socher, Richard, Jeffrey Pennington, et al. Semi-supervised recursive autoencoders for predicting sentiment distributions. Proceedings of EMNLP, 2011:151-161.
[22] Socher, Richard, Alex Perelygin, et al. Recursive deep models for semantic compositionality over a sentiment treebank. Proceedings of EMNLP, 2013:1631~1642.
[23] Li Dong, Furu Wei, Ming Zhou, et al. Adaptive multi-compositionality for recursive neural models with applications to sentiment analysis. Proceedings of AAAI, 2014.
[24] Li Dong, Furu Wei, Chuanqi Tan, et al. Adaptive recursive neural network for target-dependent Twitter sentiment classification. Proceedings of ACL, 2014.
[25] Nal Kalchbrenner, Edward Grefenstette, Phil Blunsom. A convolutional neural network for modelling sentences. Proceedings of ACL, 2014.
[26] Quoc Le and Tomas Mikolov. Distributed representations of sentences and documents. Proceedings of ICML, 2014.
[27] Igor Labutov and Hod Lipson. Re-embedding Words. Proceedings of ACL, 2013.
[28] Duyu Tang, Furu Wei, Nan Yang, et al. Learning sentiment-specific word embedding for Twitter sentiment classification. Proceedings of ACL, 2014.
[29] Duyu Tang, Furu Wei, Bing Qin, et al. Building large-scale Twitter-specific sentiment lexicon: a representation learning approach. Proceedings of COLING, 2014.
[30] Socher, Richard, Eric H. Huang, et al. Dynamic pooling and unfolding recursive autoencoders for paraphrase detection. Proceedings of NIPS, 2011; 24 801~809.
[31] Lu, Zhengdong, and Hang Li. A deep architecture for matching short texts. Proceedings of NIPS, 2013:1367~1375.
[32] Zhengyan He, Shujie Liu, Mu Li, et al. Learning entity representation for entity disambiguation. Proceedings of ACL, 2013.
[33] Bordes, Antoine, Xavier Glorot, et al. Joint learning of words and meaning representations for open-text semantic parsing. International Conference on Artificial Intelligence and Statistics, 2012:127~135.
[34] Ke Wu, Zhiqiang Gao, Cheng Peng, et al. Text window denoising autoencoder: building deep architecture for chinese word segmentation. Proceedings of NLP-CC, 2013.