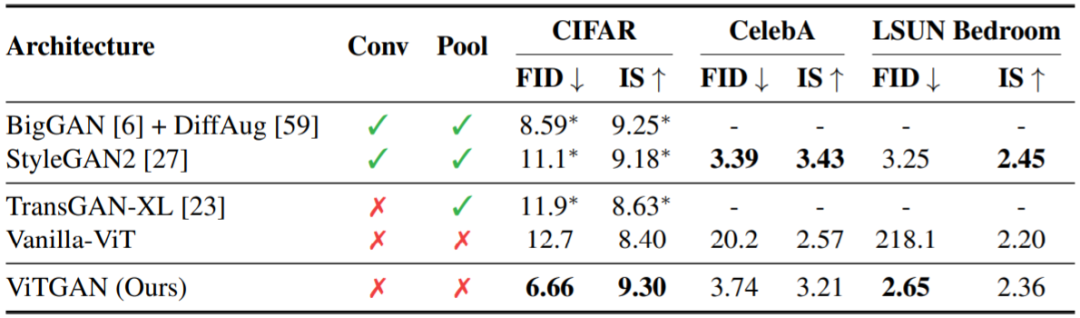
Transformers have brought tremendous advancements to various natural language tasks and have recently begun to penetrate the field of computer vision, starting to show potential in tasks previously dominated by CNNs. A recent study from the University of California, San Diego, and Google Research proposed using visual Transformers to train GANs. To effectively apply this method, the researchers also proposed several improvements, allowing the new method to match state-of-the-art CNN models on some metrics.

-
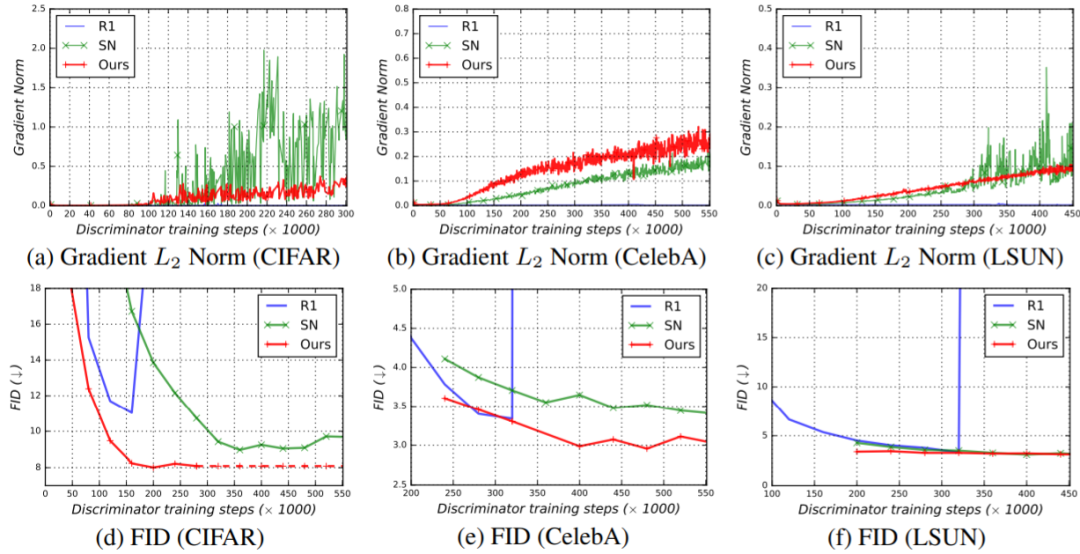
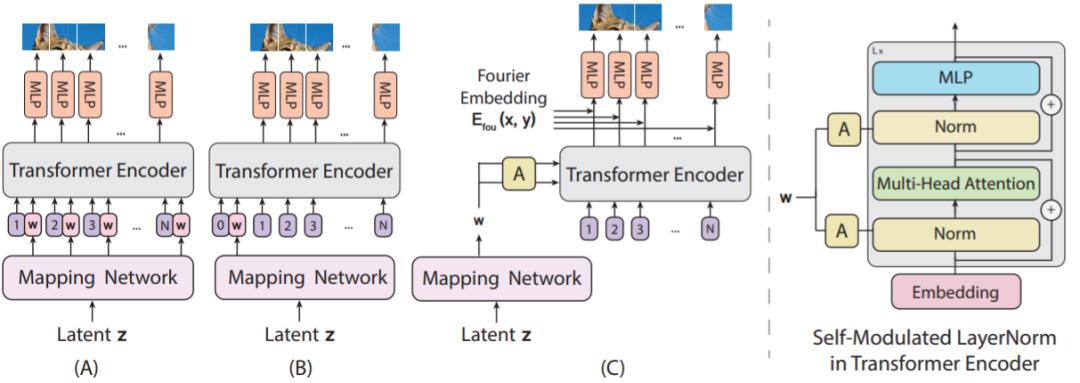
Self-Modulated Layer Normalization (SLN).The new approach does not send the noise vector z as input to the ViT but instead uses z to modulate the layer normalization operation. This operation is termed self-modulation because it requires no external information;
-
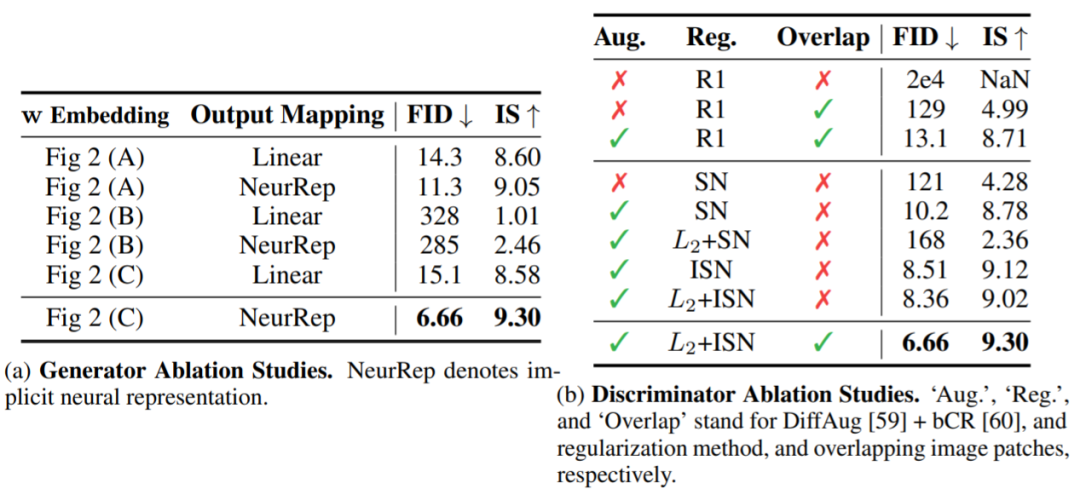
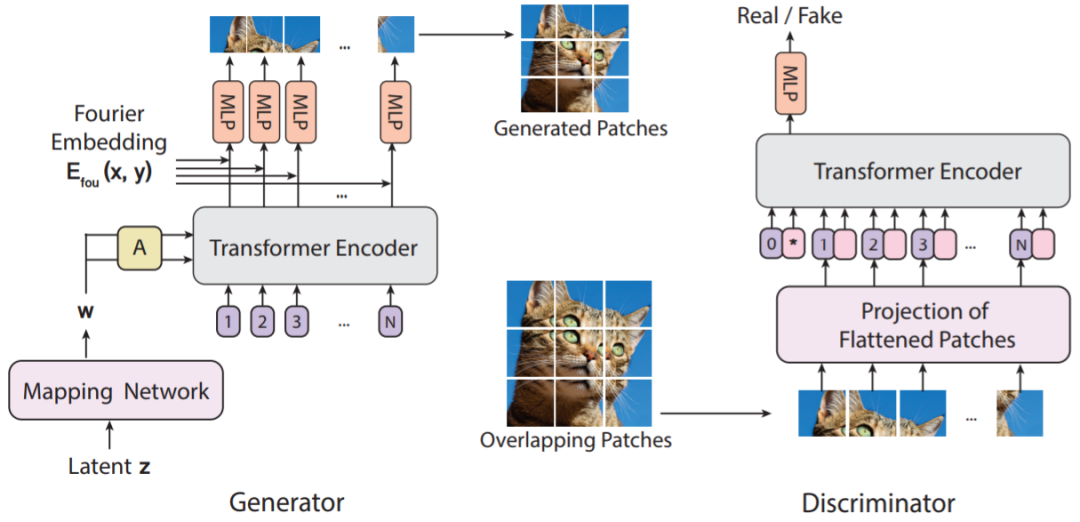
Implicit Neural Representations for Patch Generation.To learn a continuous mapping from patch embeddings to patch pixel values, the researchers used implicit neural representations. When combined with Fourier features or sine activation functions, implicit representations can constrain the generated sample space to smoothly varying natural signal spaces. The researchers found that implicit representations play a particularly significant role when training GANs using ViT-based generators.