In light of the controversy surrounding Transformer-based predictors, researchers are pondering why Transformers perform even worse than linear models in time series forecasting while dominating many other fields.
Recently, a new paper from Tsinghua University proposed a different perspective— the performance of Transformers is not inherent but rather a consequence of improperly applying the architecture to time series data.

Paper link: https://arxiv.org/pdf/2310.06625.pdf
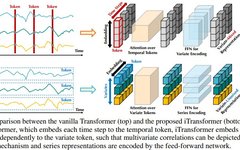
The existing structure of Transformer-based predictors may not be suitable for multivariate time series forecasting. As shown on the left side of Figure 2, points at the same time step generally represent completely different physical meanings, yet the measurements are inconsistent; these points are embedded into one token, erasing multivariate correlation. Moreover, in the real world, due to the local receptive fields of multivariate time points and misaligned timestamps, the tokens formed by single time steps are difficult to reveal beneficial information. Furthermore, although sequence variations are greatly influenced by the order of the sequence, the variant attention mechanism has not been appropriately adopted in the temporal dimension. Therefore, the ability of Transformers to capture fundamental sequential features and depict multivariate correlations is weakened, limiting their capability and generalization across different time series data.
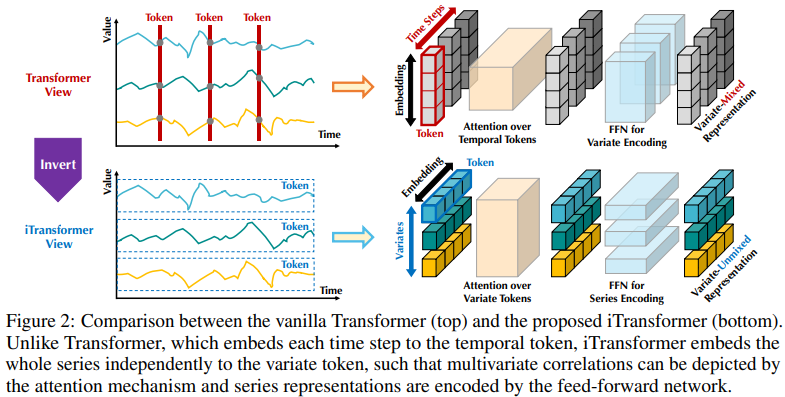
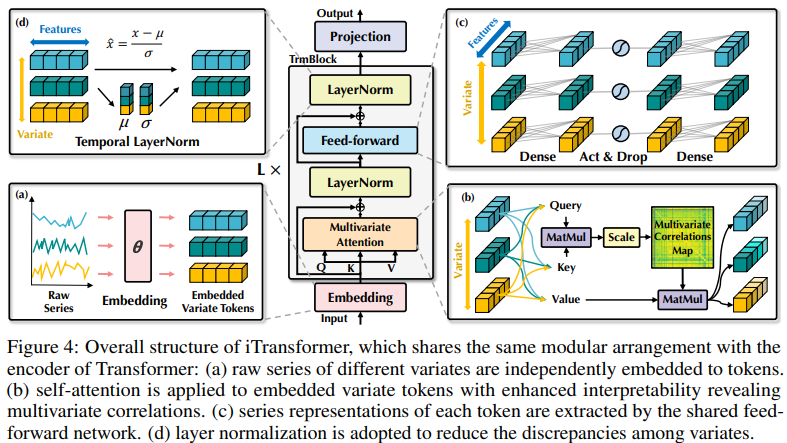
Regarding the irrationality of embedding multivariate points of each time step into one (time) token, researchers approach the problem from a reverse perspective of time series, embedding the entire time series of each variable independently into one (variable) token, which is an extreme case of expanding the local receptive field through patching. By inversion, the embedded tokens gather global representations of the sequences, allowing for a more variable-centric approach and better leveraging the attention mechanism for multivariate correlation. Meanwhile, the feedforward network can proficiently learn generalized representations of different variables encoded by any retrospective sequence and decode them to predict future sequences.
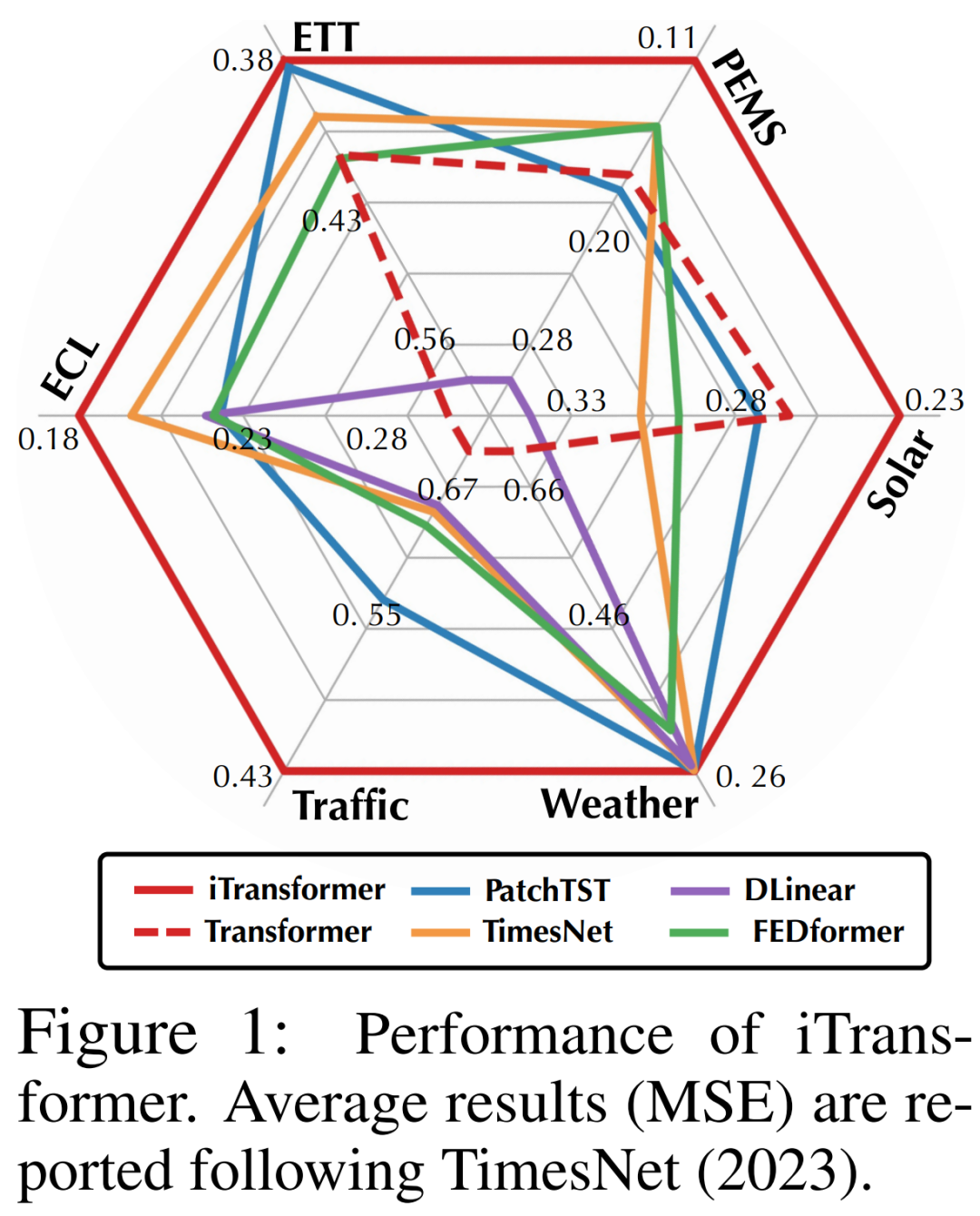
Researchers believe that Transformers are not ineffective for time series forecasting, but rather misused. In the paper, they revisit the structure of Transformers and advocate for using iTransformer as a fundamental pillar for time series forecasting. They embed each time series as a variable token, adopt multivariate correlation attention, and utilize feedforward networks for sequence encoding. Experimental results show that the proposed iTransformer achieves SOTA levels on the real-world prediction benchmarks shown in Figure 1, unexpectedly addressing the pain points of Transformer-based predictors.
In summary, the contributions of this paper are as follows:
-
Researchers reflected on the architecture of Transformers, discovering that the native Transformer components’ capabilities on time series have not been fully developed.
-
The proposed iTransformer treats independent time series as tokens, capturing multivariate correlations through self-attention and using layer normalization and feedforward network modules to learn better global representations of sequences for time series forecasting.
-
Through experiments, iTransformer achieved SOTA performance on real-world prediction benchmarks. Researchers analyzed the inversion module and architectural choices, providing directions for future improvements of Transformer-based predictors.
iTransformer
In multivariate time series forecasting, given historical observations:
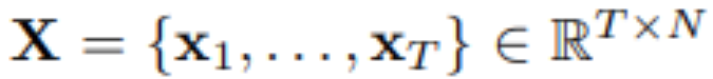
With T time steps and N variables, researchers predict the future S time steps: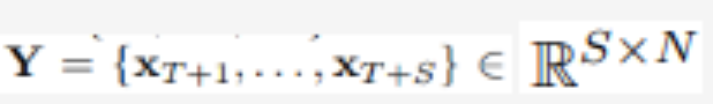 .For convenience, denoted as
.For convenience, denoted as 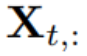 for multivariate variables recorded at time step t simultaneously,
for multivariate variables recorded at time step t simultaneously, 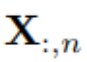 for the entire time series indexed by n for each variable.It is worth noting that in the real world, due to system delays of monitors and loosely organized datasets,
for the entire time series indexed by n for each variable.It is worth noting that in the real world, due to system delays of monitors and loosely organized datasets, 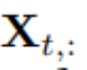 may not contain time points that are essentially the same timestamps.
may not contain time points that are essentially the same timestamps.
Elements of 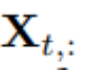 can differ from each other in physical measurements and statistical distributions, while variable
can differ from each other in physical measurements and statistical distributions, while variable 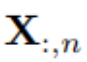 typically shares this data.
typically shares this data.
The architecture proposed in this paper, equipped with a variant of Transformer called iTransformer, does not fundamentally require more specific demands on Transformer variants; it merely states that the attention mechanism should apply to multivariate correlation modeling. Therefore, a set of effective attention mechanisms can serve as plugins to reduce the complexity of associations when the number of variables increases.
The iTransformer shown in Figure 4 utilizes a simpler pure encoder architecture of Transformer, including embedding, projection, and Transformer blocks.
Experiments and Results
Researchers conducted a comprehensive evaluation of the proposed iTransformer across various time series forecasting applications, validating the generality of the proposed framework and further investigating the effects of reversing the responsibilities of Transformer components for specific time series dimensions.
Researchers extensively included six real-world datasets in the experiments, including ETT, weather, power, traffic datasets used by Autoformer, the solar energy dataset proposed by LST5 Net, and the PEMS dataset evaluated by SCINet. For more information about the datasets, please refer to the original text.
Prediction Results
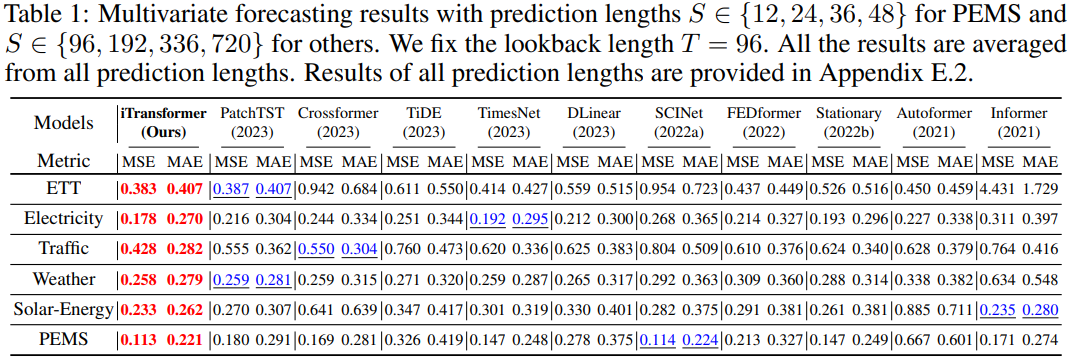
As shown in Table 1, the best results are highlighted in red, and the optimal ones are underlined. The lower the MSE/MAE, the more accurate the prediction results. The proposed iTransformer achieves SOTA performance. The native Transformer components can handle time modeling and multivariate correlation, and the proposed inverted architecture effectively addresses real-world time series forecasting scenarios.
Generality of iTransformer
Researchers applied the framework to Transformers and their variants to evaluate iTransformers, which typically address the secondary complexity issues of self-attention mechanisms, including Reformer, Informer, Flowformer, and FlashAttention. Researchers found that the simple inverted perspective can enhance the performance of Transformer-based predictors, thereby improving efficiency, generalizing unseen variables, and better utilizing historical observation data.
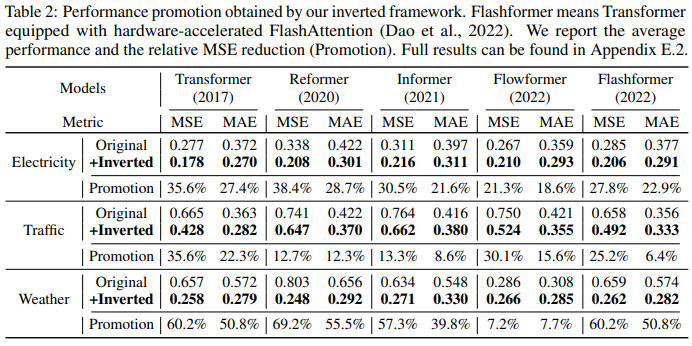
Table 2 evaluates Transformers and their corresponding iTransformers. Notably, the framework consistently improved various Transformers. Overall, Transformers improved by an average of 38.9%, Reformer by an average of 36.1%, Informer by an average of 28.5%, Flowformer by an average of 16.8%, and Flashformer by an average of 32.2%.
Furthermore, since the inverted structure employs attention mechanisms in the variable dimension, the introduction of efficient attention with linear complexity fundamentally resolves the efficiency issues arising from six variables, which are very common in real-world applications but may consume resources for Channel Independent. Thus, iTransformer can be widely applied to Transformer-based predictors.
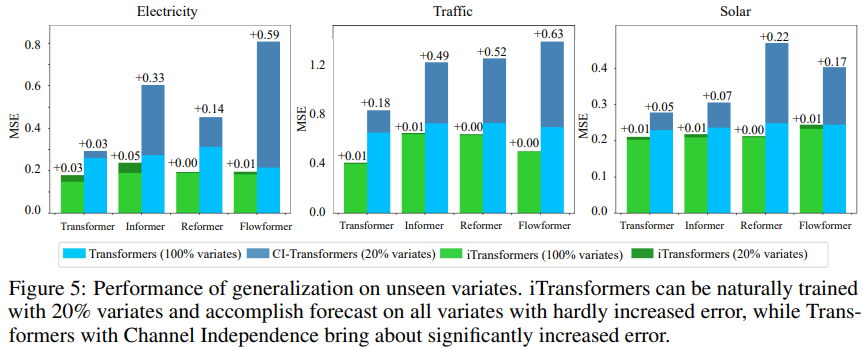
To verify the hypothesis, researchers compared iTransformer with another generalization strategy: Channel Independent, which forces a shared Transformer to learn patterns across all variants. As shown in Figure 5, the generalization error of Channel Independent (CI-Transformers) can significantly increase, while the increase in prediction error for iTransformer is much smaller.
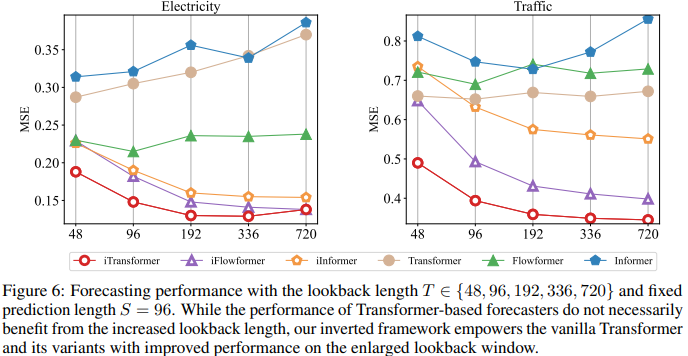
As the responsibilities of attention and feedforward networks are inverted, Figure 6 evaluates the performance of Transformers and iTransformer as the retrospective length increases. It validates the rationale of utilizing MLP in the temporal dimension, indicating that Transformers can benefit from extended retrospective windows for more accurate predictions.
Model Analysis
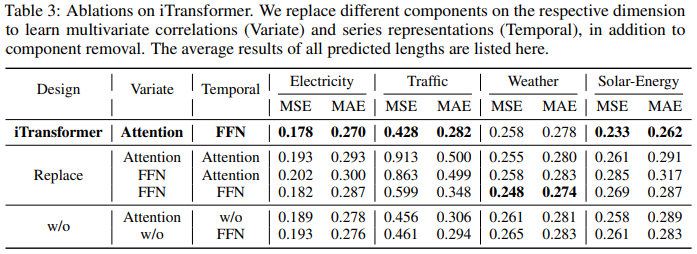
To verify the rationality of the Transformer components, researchers conducted detailed ablation experiments, including component replacement (Replace) and component removal (w/o) experiments. Table 3 lists the experimental results.
For more detailed content, please refer to the original text.