Skip to content
We have discussed computer vision (or more narrowly, machine vision) before. Last year, the cover story of Electronic Engineering Magazine also talked about computer vision, but the content at that time was more focused on how computers acquire and understand image information from the outside world, leaning towards the perception aspect.
According to the definition from Wikipedia, computer vision broadly includes the acquisition, processing, analysis, and understanding of digital images, as well as analyzing high-dimensional data from the real world, generating digital and symbolic information, and making decisions. The key aspect remains the ability to acquire and understand information from images (which include videos and 3D point clouds generated from LiDAR).
This may sound abstract, but looking at some subfields helps us better understand what computer vision is: scene reconstruction, object detection/recognition, event detection, action recognition, video tracking, 3D pose estimation, information retrieval, 3D scene modeling, image restoration… these all fall under computer vision.
For example, image restoration is based on understanding the original image and acquiring information, using algorithms and AI to repair and enhance the original image.
In last year’s discussions about computer vision, we viewed AI as a significant driving force in its current development. Here, AI refers to neural networks. It is evident that AI and CV (computer vision) often appear together, which is not surprising. However, this year, a well-known event occurred in the AI field: generative AI and Transformer models became buzzwords.
In fact, during this year’s World Artificial Intelligence Conference, we spoke with engineers from Graphcore, a UK-based AI high-performance computing chip company. They mentioned that generative AI technology is already collaborating with related companies in the CV field, with applications including photo retouching, painting assistance, architectural rendering, and more.
The AI Accelerator Institute also listed generative AI as the top trend in computer vision in their mid-year report on the five major trends for 2023.
In this article, we attempt to discuss how computer vision and generative AI are working together and what generative AI can bring to computer vision; more importantly, it serves as a popular science explanation of the value of Transformers in computer vision.
Figure 1: An image generated by Midjourney using “computer vision” as a keyword.
Those who pay attention to AI should be well aware that AI and CV have traditionally been associated with CNNs (Convolutional Neural Networks). In other words, CNNs are more widely known for completing image and video-related tasks. From healthcare to automotive, the application of CNNs in CV is flourishing.
Through a large amount of training data, CNNs can “learn” the characteristics of a particular object. For instance, to recognize a dog in an image, the earlier layers of the neural network learn features such as the edges and textures of the image object; deeper layers learn higher-level features, such as ears, tails, and other distinguishing characteristics…
The key to CNNs lies in the convolution (C) operation. The convolution process can be seen as continuously moving a small filter across the input image or feature map, performing multiplication and addition operations within each spatial region. A key aspect of CNN convolution operations is parameter sharing, where the same set of weights can be used across all positions in the input, reducing the number of parameters and generalizing the network across different spatial locations. In summary, this process enables feasible image information acquisition.
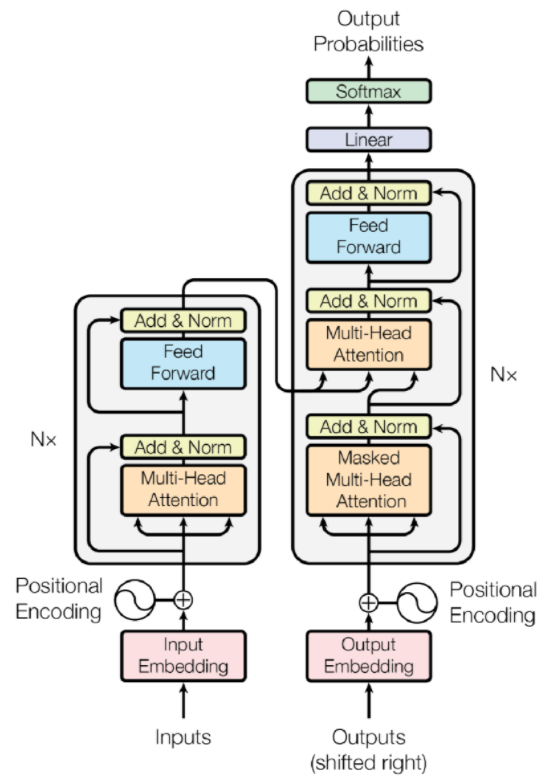
So what is the Transformer that we often talk about now? The Transformer structure employs a so-called self-attention mechanism to capture global correlations and the relationships between different elements in a sequence. The entire process works like this: the input contains a series of tokens (like the individual words we use when chatting with ChatGPT), and each token is embedded into a continuous vector space. Then, an encoder position encoding operation is applied to the embedded tokens to provide their relative positions in the sequence, allowing the model to understand their order.
Each layer of the encoder has two sub-layers: the first layer implements the self-attention mechanism, allowing each token in the sequence to refer to other tokens to obtain global relevance; the second layer is a feed-forward neural network that operates independently on each token.
The decoder part has multiple layers, each containing three sub-layers. The self-attention mechanism in the decoder allows tokens to relate to other decoder tokens, capturing relevant information within the decoder. The attention sub-layer between the encoder and decoder allows the decoder to relate to the encoded input sequence. Finally, the feed-forward neural network sub-layer in the decoder operates independently on each token, as shown in Figure 2.
Additionally, the output layer of the decoder predicts the likelihood of the next token in the sequence. From the entire process, it is not difficult to see that Transformers are better suited for NLP (natural language processing), where the self-attention mechanism allows each element in the sequence to relate to all other elements, enabling the model to weigh their importance based on contextual relationships.
In general, the characteristics of CNNs and Transformers determine their different application directions. Naturally, CNNs excel in tasks such as image classification and object recognition, while Transformers have advantages in natural language understanding and generation.
Figure 2: Structure of the Transformer model. Source: Attention Is All You Need (arXiv:1706.03762)
Generative AI and Computer Vision
If there is a task that involves both image and text work, such as an image accompanied by a text input request, what should be done? Should we consider letting CNN handle the text-related tasks or letting the Transformer handle the image-related tasks?
For CNNs, as explained earlier, they can capture specific patterns formed by pixels within a defined area of an image; however, when it comes to token text and acquiring contextual relationships, CNNs fall short. Moreover, one characteristic of CNNs mentioned earlier is parameter sharing, which assumes that the same model is applicable at any position in the input data. This is not suitable for text processing, as different words appearing in different positions in a sentence can convey different meanings.
If we use Transformers to handle image tasks, it would mean that self-attention requires each pixel in the image to relate to other pixels contextually. Given the scale of contemporary images’ pixel counts and the computational power available from chips, this is unrealistic.
However, in 2021, a team from Google Research published a paper proposing a solution that involves slicing an image into small pieces and treating each piece as a token. This way, Transformers can learn to recognize objects with high accuracy based on these tokens. This method offers good parallelism and flexibility, making it suitable for large-scale image recognition tasks.
Furthermore, it allows the output image’s small slices from the Transformer to be integrated with text, significantly expanding application possibilities. Consequently, a vast number of related research papers emerged within two years. Excluding the more well-known ones, a representative recent example would be Meta’s SAM (Segment Anything Model), where the team utilized the MAE (Masked Auto-Encoder) Vision Transformer combined with CLIP, along with image + input prompts, to generate so-called masks.
SAM primarily addresses the segmentation problem in images, which is the process of dividing an image into different regions or objects, similar to cutting out images in Photoshop (see Figure 3). Since then, many demonstrations have used SAM combined with Diffusion to change the appearance of objects in input photos, such as changing a hairstyle or the material of clothing.
Figure 3: Image segmentation demonstration from the SAM official website.
In fact, the term Vision Transformer (ViT) was already coined in 2020 to describe a Transformer specifically designed for computer vision. The basic structure, as previously mentioned, involves slicing the input image into small pieces, tokenizing them, and applying these tokens to the standard Transformer structure: essentially transferring the NLP approach to CV.
In the process of inputting to generative AI and generating new images or text results, there is already a potential for disruption for many industries related to computer vision, truly broadening the boundaries of computer vision.
Here, we list three types of algorithms frequently discussed by foreign computer vision researchers as fundamental modules constituting generative AI in the field of computer vision—each of which has traces of Transformers in its internal structure: GAN (Generative Adversarial Network), VAE (Variational Autoencoder), and DDPM (Denoising Diffusion Probabilistic Model).
GANs are quite well-known, consisting of two neural networks: a generator and a discriminator. The generator creates synthetic images hoping to fool the discriminator, while the discriminator strives to distinguish problematic images, ultimately achieving continuous improvement.
VAEs have also appeared in many discussions about generative AI, employing the encoder-decoder structure, where the encoder maps the input image into latent space; after some processing, the decoder reconstructs the image from the low-dimensional representation. It is said that VAEs excel at understanding complex data, making them invaluable for artistic creation.
VAEs are also crucial components of Stable Diffusion and DALL-E, although their roles within these systems seem to differ. DDPM focuses on enhancing signal-to-noise ratios, but the process appears to involve adding noise to understand how to eliminate it in the reverse path.
What Real Applications Might Exist?
If applications exist above chips, then the topics discussed in this article are quite close to upper-layer applications, which somewhat contradicts the title of “Electronic Engineering Magazine.” However, let’s not forget that in every AI chip technology introduction article, we spend nearly half the space discussing ecosystems and software—because these are essential for AI chip companies.
For these high-performance chip companies, building software tools and ecosystems is not any easier than creating chips; moreover, in this competitive era, they must do as much as possible for downstream customers. Therefore, the aforementioned aspects must be trends they focus on. After all, whatever algorithms become popular, the chips and corresponding tools must adapt accordingly.
Just like this generation of NVIDIA GPUs has particularly added a Transformer Engine.
If generative AI holds such value for CV, then what exactly can it do? This question opens up a vast space for imagination, and perhaps we can try to list some possibilities.
Many traditional algorithms in CV can be tackled using generative AI. For example, image super-resolution, which converts low-resolution images into high-resolution ones—while super-resolution may not strictly fit the definition of “generative AI,” it at least provides the previously missing information. Moreover, super-resolution is not merely about displaying old photos or videos in higher quality; it is said that there are now applications that convert low-resolution medical scan images into high-resolution, more detailed images as references, thereby improving the accuracy of medical assessments.
The arts and content creation fields are likely the most direct application markets. Therefore, at AI-related exhibitions this year, AI chip companies have generally showcased these applications, even launching enterprise-level products—for instance, at the World Artificial Intelligence Conference, Suir Technology released its YaoTu product. This is because generative AI can create detailed and refined visual works.
Initially, we had a confusion: can content creation be considered “computer vision”? Perhaps the answer lies in considering models like ViT, whose generation process aligns with the definition of computer vision. Regardless, it requires the computer to first understand the data fed into it and ultimately make decisions. However, the current applications still seem very limited. So even when inputting text to generate images, it reflects computer vision technology. Some illustrations in Electronic Engineering Magazine, including those in this article, are products of generative AI.
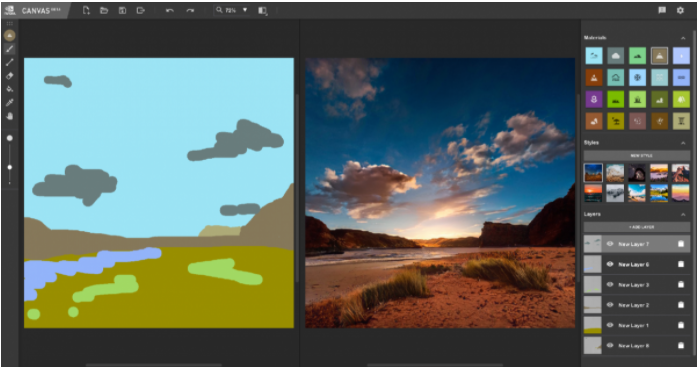
Figure 4: Demonstration of Nvidia Canvas.
Previously, at the NVIDIA GTC conference, we saw a demonstration of Canvas (Figure 4), which is perhaps one of the most impressive applications of generative AI in the content creation direction. By drawing a few strokes on a canvas, Canvas can transform it into a richly detailed realistic photo. This should fall under the category of scene construction applications. At that time, NVIDIA demonstrated using materials generated by Canvas to create CG animations.
During this year’s autumn GTC, Jensen Huang demonstrated how to take a simple 2D flat image, add a PDF document, and communicate with generative AI to generate an interactive 3D virtual factory, which was quite astonishing. Although we think its usability is still quite questionable, it indicates the potential value of generative AI in industrial manufacturing, the metaverse, and digital twins. Upon careful consideration, doesn’t this perfectly align with the definition of computer vision?
Thus, the question of what determines the market potential of generative AI and computer vision should also shift to how much value can be created through digital transformation across various industries. After all, the foundation of all digital twin technologies will be closely related to computer vision and AI.
Some commonly discussed applications, such as in fashion design, where AI can generate customized design schemes and provide virtual try-on experiences in retail; in the automotive sector, generative AI is likely preparing to be applied across various processes, including virtual testing for autonomous driving, virtual digital twin construction before factory startup, AR experiences in retail, and so on; the potential value in architecture, urban planning, entertainment, and industry is self-evident…
As we discuss, the direction of applications seems to have shifted towards what “generative AI” can do. In reality, during the process of social digital transformation, AI CV will certainly be a technical component involved throughout the entire process. Therefore, both generative AI and computer vision are foundational to the development of the digital economy era.