Click the “ReadingPapers” card below to get daily interpretations of top journal papers.
Paper Information
Abstract
Unsupervised learning, which learns data distribution without labeled samples, is a very promising method to solve the challenging task of hyperspectral pan-sharpening. Inspired by this, we introduce an innovative Generative Adversarial Network framework (named MFT-GAN), which integrates transformer networks and multi-scale interaction techniques. Specifically, MFT-GAN consists of a generator and two discriminators. The generator is composed of a Multi-Scale Feature Guided Branch (MFGB) and a Feature Interaction Fusion Branch (FIFB). The former aims to extract spectral and spatial information branches from low-resolution hyperspectral (LRHS) and pan (PAN) images through convolutional sampling operations. The latter achieves interaction of spectral and spatial information at different scales through multi-scale interaction techniques. The multi-scale interaction results are then fused layer by layer through convolutional sampling and pixel summation operations to generate high-resolution hyperspectral (HRHS) images. The discriminators consist of a spectral transformer discriminator and a spatial transformer discriminator, aimed at maintaining structural and parameter balance while learning long-term spectral and spatial correlations. Additionally, a mixed loss function is used to complete the adversarial training of MFT-GAN to improve its performance. Experiments on simulated and real datasets further demonstrate the effectiveness of the proposed MFT-GAN method.Keywords: Feature interaction fusion, Generative Adversarial Network, Multi-scale feature guidance, Spectral and spatial transformers, Unsupervised hyperspectral pan-sharpening.Insert image description here
III. Proposed Method
This paper focuses on feature interaction and fusion across different scales. MFT-GAN consists of a generator and two discriminators. The generator includes two branches, MFGB and FIFB, aimed at performing multi-scale feature extraction, interaction, and fusion tasks. Two transformer-based discriminators are designed to preserve the spectral and spatial information of the two observed images through adversarial learning. Figure 1 shows the overall structure of the MFT-GAN generator and discriminators. For convenience, LRHS images are represented as and PAN images are represented as . The fused image is represented as , where and are the spatial dimensions, is the number of channels, and and are the spatial resolution ratios of P and Y. Additionally, represents the generator, and and represent the spectral and spatial discriminators, respectively.
A. Generator Structure
Multi-Scale Feature Guided Branch: In hyperspectral pan-sharpening, the input data contains spectral and spatial information (spectral information exists in LRHS images, while spatial information exists in PAN images). To enable interaction and fusion of these two types of information over a wide range, we first designed an MFGB in the generator (see Figure 2). It is a CNN-based dual-branch structure that extracts multi-scale spectral and spatial information from LRHS and PAN images, respectively. The two branches in different directions obtain features at different scales through upsampling and downsampling, described as follows:
Where represents the convolutional layer with a kernel size of 3 and a stride of 1, represents the LeakyReLU function. Up represents the convolutional upsampling using a 2-D transpose convolution layer with a kernel size of 2 and a stride of 2. Down represents the convolutional downsampling using a 2-D convolution layer with a kernel size of 3 and a stride of 2. is used to distinguish images at different scales. For Y, as increases, the image size of increases. For P, as increases, the image size of decreases.
Feature Interaction Fusion Branch: After MFGB, multi-scale spectral and spatial information can be obtained, which will be used as guiding items to implement multi-scale interaction fusion techniques. Specifically, we designed a multi-head cross-attention module (see Figure 3) that calculates the long-term correlation of two feature maps at the same scale to achieve long-term interaction between information. It is used to compute different-scale spectral and spatial information, resulting in interaction results at different scales. Finally, the final fused image is generated by performing feature aggregation operations on the interaction results at different scales (see Figure 2).
a) Multi-Head Cross-Attention Module: Inspired by the attention mechanism, we developed a multi-head cross-attention module to achieve multi-scale interaction. This module has inputs of spectral and spatial information from MFGB ( and ). First, and are mapped to the same dimension using convolutional layers with a kernel size of 1, and then reshaped into two sequences. These two sequences are then divided into three subsequences of the same dimension: queries Q, keys K, and values V. By exchanging their Q (a query Q in one sequence combined with keys K and values V in another), the multi-head self-attention results are calculated to achieve feature interaction. Finally, feedforward neural networks (FNN), residual connections, and pixel addition operations are added to further enhance performance. In Figure 2, the multi-head cross-attention pre-calculates the interaction results between Y and P images at multiple scales, described and formulated as follows:Where Chunk represents dividing the sequence into multiple subsequences. MutiHead represents multi-head self-attention computation. represents the intermediate output. Additionally, FNN consists of two layers of linear connection networks and the activation function LeakyReLU.b) Feature Aggregation: As shown in Figure 2, to facilitate the interaction of spectral and spatial information across multiple scales, we use a multi-head cross-attention computation strategy. This method can generate interaction results of different scales. Then, through layer-wise convolutional upsampling and pixel addition operations, these results are aggregated to obtain the fused result:Where and represent convolutional upsampling using a 2-D transpose convolution layer with a kernel size of 2 and a stride of 2. After the above feature aggregation, the generated image retains essential spectral and spatial detail information. We use a detail injection strategy to add these images to the interpolated upsampled LRHS images to further preserve spectral and spatial information:Where represents the convolutional layer with a kernel size of 1 and a stride of 1. It is used to map FA to the same dimension as .
B. Discriminator Structure
To achieve structural and parameter balance, we integrated transformers into the two discriminators (see Figure 2); the detailed structure of these discriminators is shown in Figure 4. We can see that the spectral and spatial transformers use different attention mechanisms, namely spectral self-attention and spatial self-attention, and are computed using the same formula. As shown in Figure 5, the input data has different dimensions, calculating different self-attention results, which allows for the acquisition of long-term spectral features and long-term spatial features. Specifically, spectral self-attention calculates the spectral correlation between different pixels, while spatial self-attention calculates the spatial correlation between different bands. This computation can better preserve spectral and spatial features. The spectral transformer discriminator is used to distinguish between the interpolated upsampled LRHS image () and the generated HRHS image () as real or fake. In Figure 2 and Program 1, we can see the operational process of the spectral transformer discriminator. Unlike traditional discriminators, the spectral transformer discriminator iteratively computes the long-term spectral correlation of feature maps through the spectral transformation module. In each iteration of the spectral transformation, parameters are not shared because the input dimensions are different. This design aims to capture long-term spectral features between different pixel dimensions by gradually reducing dimensions, resulting in excellent classification results at the spectral level. The spatial transformer discriminator is used to distinguish between PAN images () and the generated HRHS image () as real or fake. In Figure 2 and Program 2, we can see the operational process of the spatial transformer discriminator. As with the above theory, the spatial transformer discriminator also uses an iterative computation strategy, and parameters are not shared in each iteration. Using the spatial transformation module and average pooling operation, long-distance spatial features between different spectra are obtained, achieving excellent classification results at the spatial level. Finally, we use the clip function to map the classification results of the two discriminators to the range of -1 to 1, ensuring compatibility with the hinge loss function and aiding effective model training.
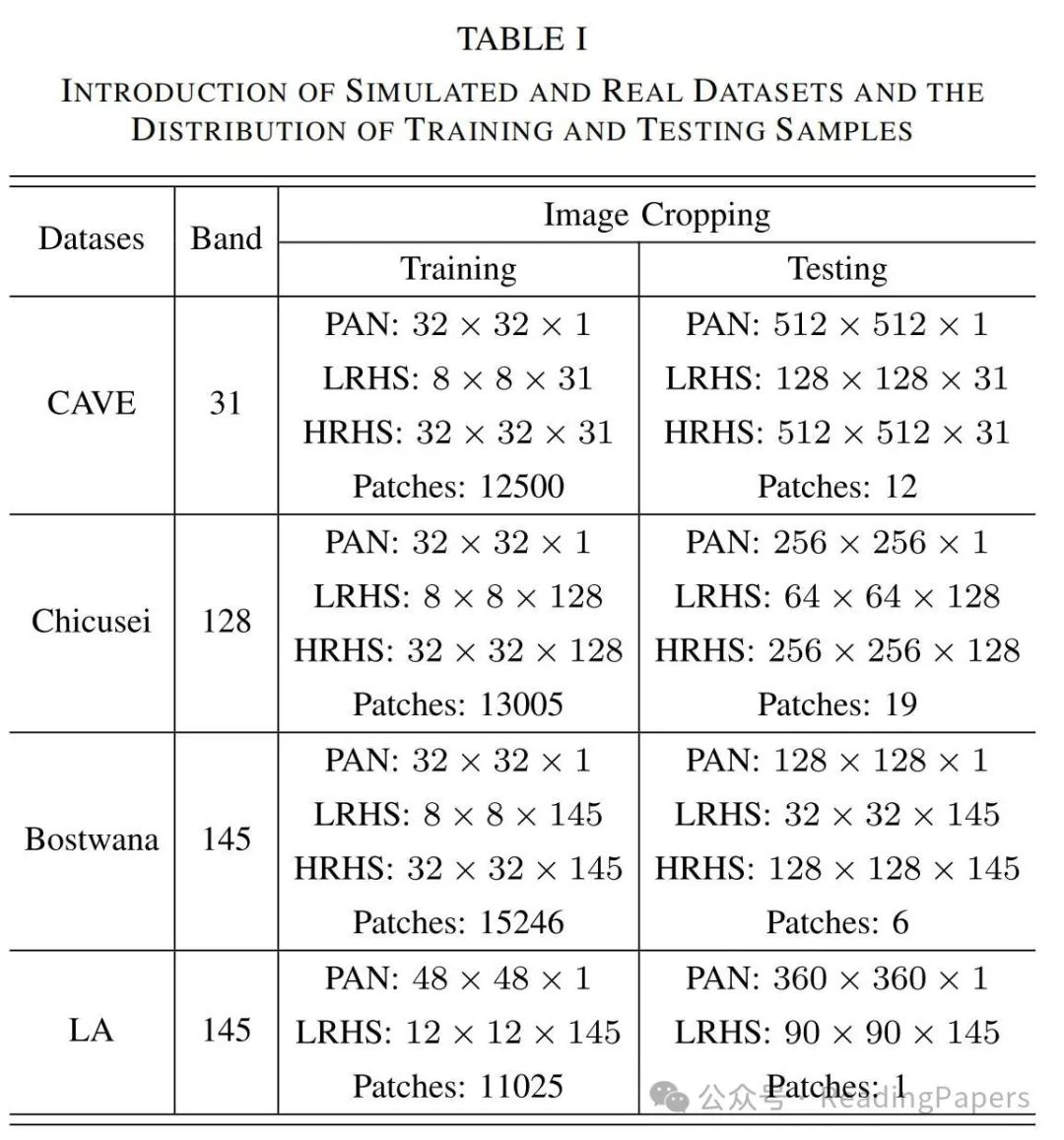
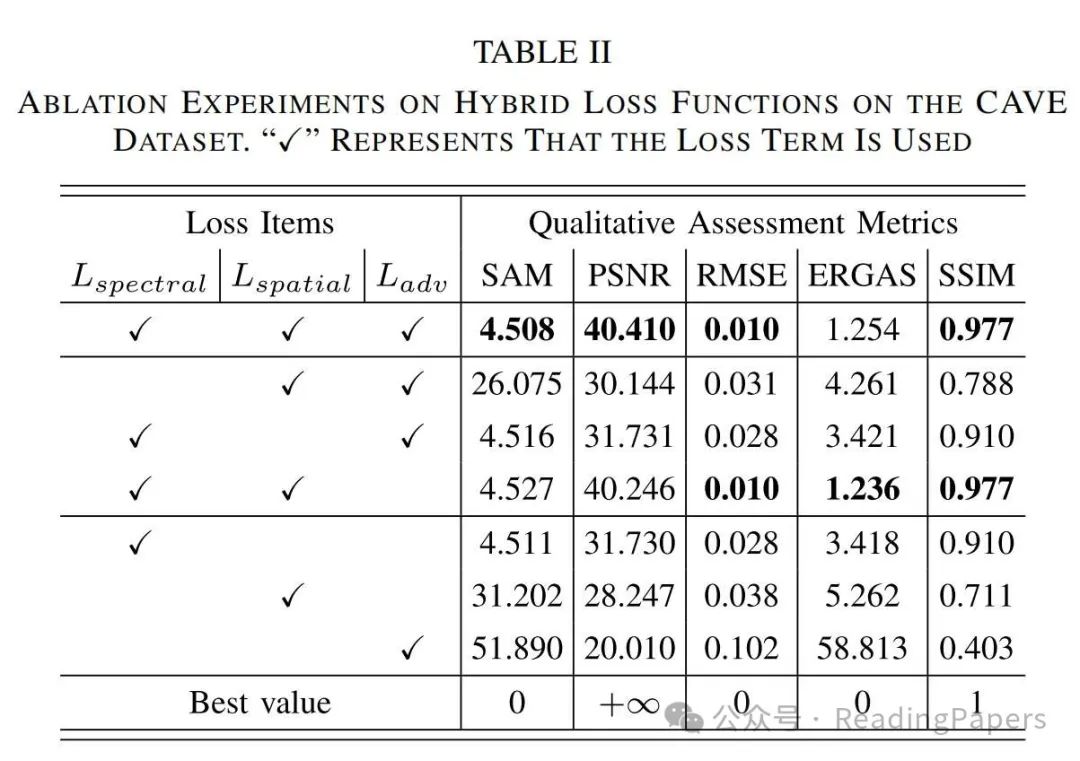
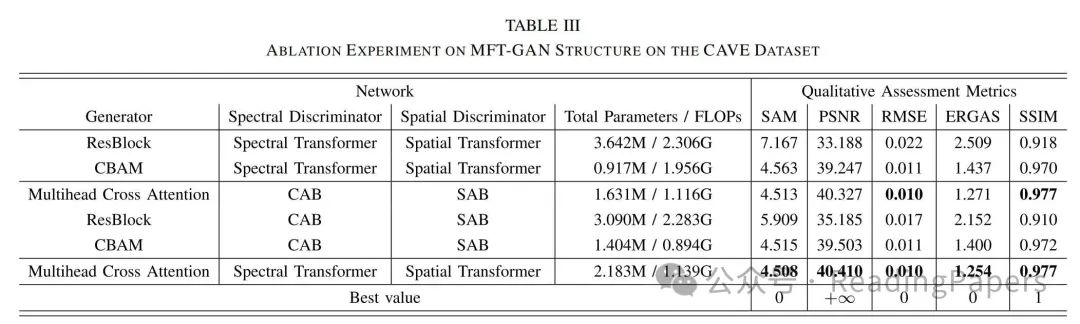
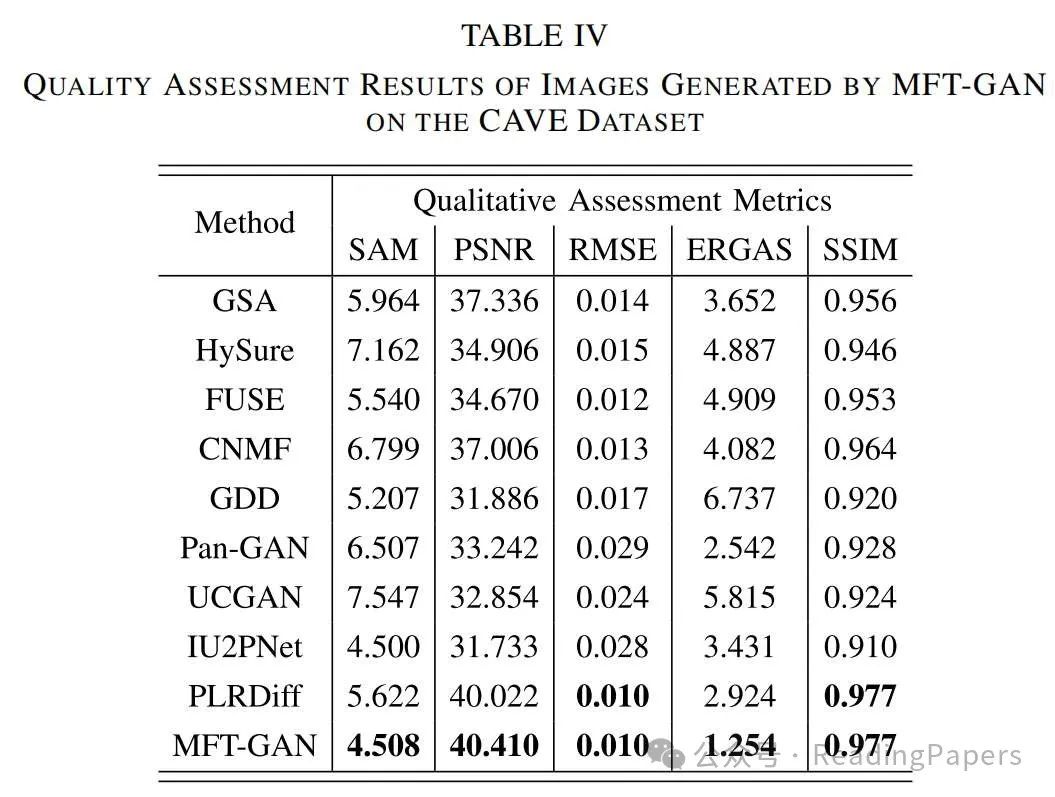
Experimental Results
Statement
The content of this article is a sharing of learning outcomes from the paper. Due to limitations in knowledge and ability, there may be deviations in understanding the original text, with the final content subject to the original paper. The information in this article aims to disseminate and facilitate academic exchange, with the content being the author’s responsibility and does not represent the views of this account. If the text, images, or other content in the article involve issues of content, copyright, or other matters, please contact us in a timely manner, and we will respond and address them as soon as possible.
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the background of the "Little White Learning Vision" public account to download the first OpenCV extension module tutorial in Chinese on the internet, covering over twenty chapters including extension module installation, SFM algorithm, stereo vision, object tracking, biological vision, super-resolution processing, etc.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the background of the "Little White Learning Vision" public account to download 31 vision practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, facial recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the background of the "Little White Learning Vision" public account to download 20 practical projects based on OpenCV to achieve advanced learning in OpenCV.
Group Chat
Welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually be subdivided in the future). Please scan the WeChat ID below to join the group, with the note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Visual SLAM". Please follow the format for the note, otherwise, it will not be approved. After successful addition, you will be invited into the relevant WeChat group based on your research direction. Please do not send advertisements in the group, otherwise, you will be removed from the group. Thank you for your understanding.~
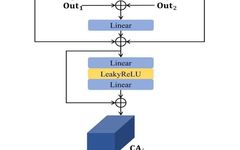

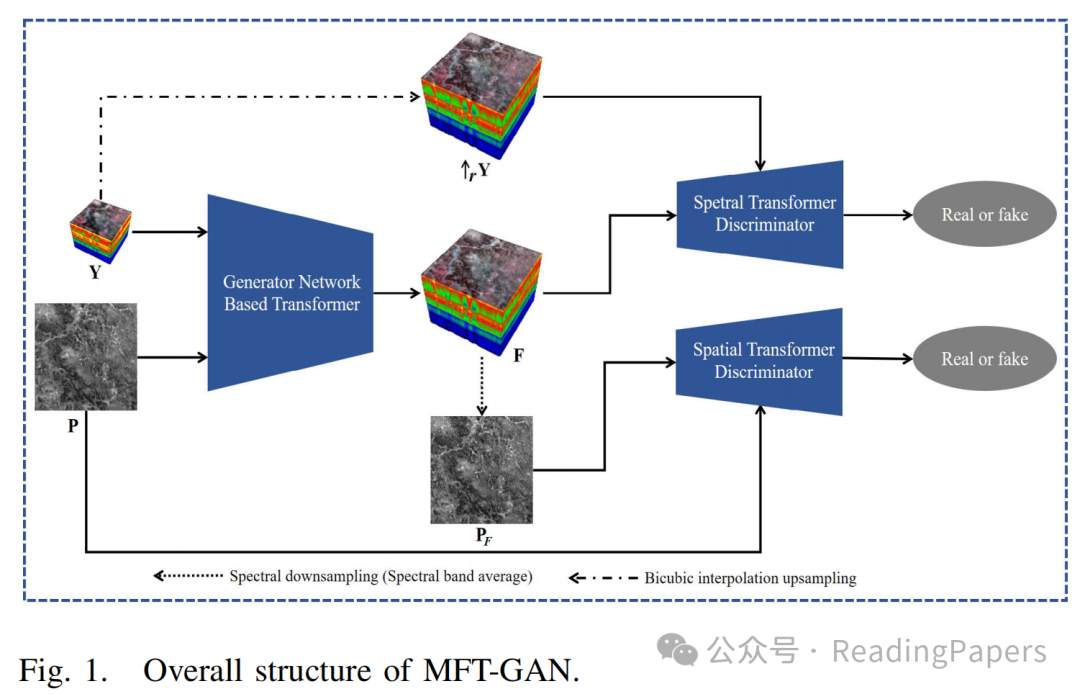
 and PAN images are represented as
and PAN images are represented as  . The fused image is represented as
. The fused image is represented as  , where
, where  and
and  are the spatial dimensions,
are the spatial dimensions,  is the number of channels, and
is the number of channels, and  and
and  are the spatial resolution ratios of P and Y. Additionally,
are the spatial resolution ratios of P and Y. Additionally,  represents the generator, and
represents the generator, and  and
and  represent the spectral and spatial discriminators, respectively.
represent the spectral and spatial discriminators, respectively.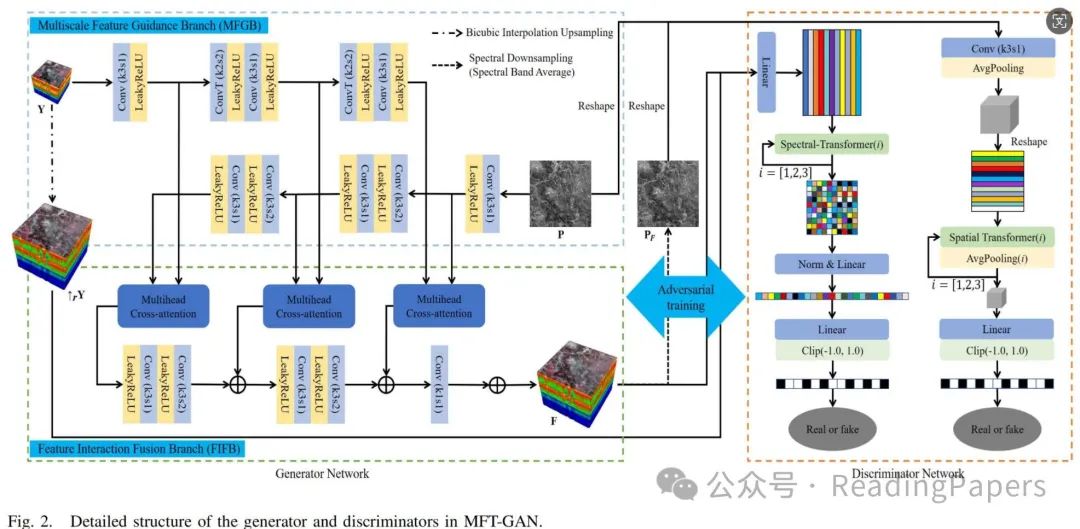
 represents the convolutional layer with a kernel size of 3 and a stride of 1,
represents the convolutional layer with a kernel size of 3 and a stride of 1,  represents the LeakyReLU function. Up represents the convolutional upsampling using a 2-D transpose convolution layer with a kernel size of 2 and a stride of 2. Down represents the convolutional downsampling using a 2-D convolution layer with a kernel size of 3 and a stride of 2.
represents the LeakyReLU function. Up represents the convolutional upsampling using a 2-D transpose convolution layer with a kernel size of 2 and a stride of 2. Down represents the convolutional downsampling using a 2-D convolution layer with a kernel size of 3 and a stride of 2.  is used to distinguish images at different scales. For Y, as
is used to distinguish images at different scales. For Y, as  increases, the image size of
increases, the image size of  increases. For P, as
increases. For P, as  increases, the image size of
increases, the image size of  decreases.
decreases.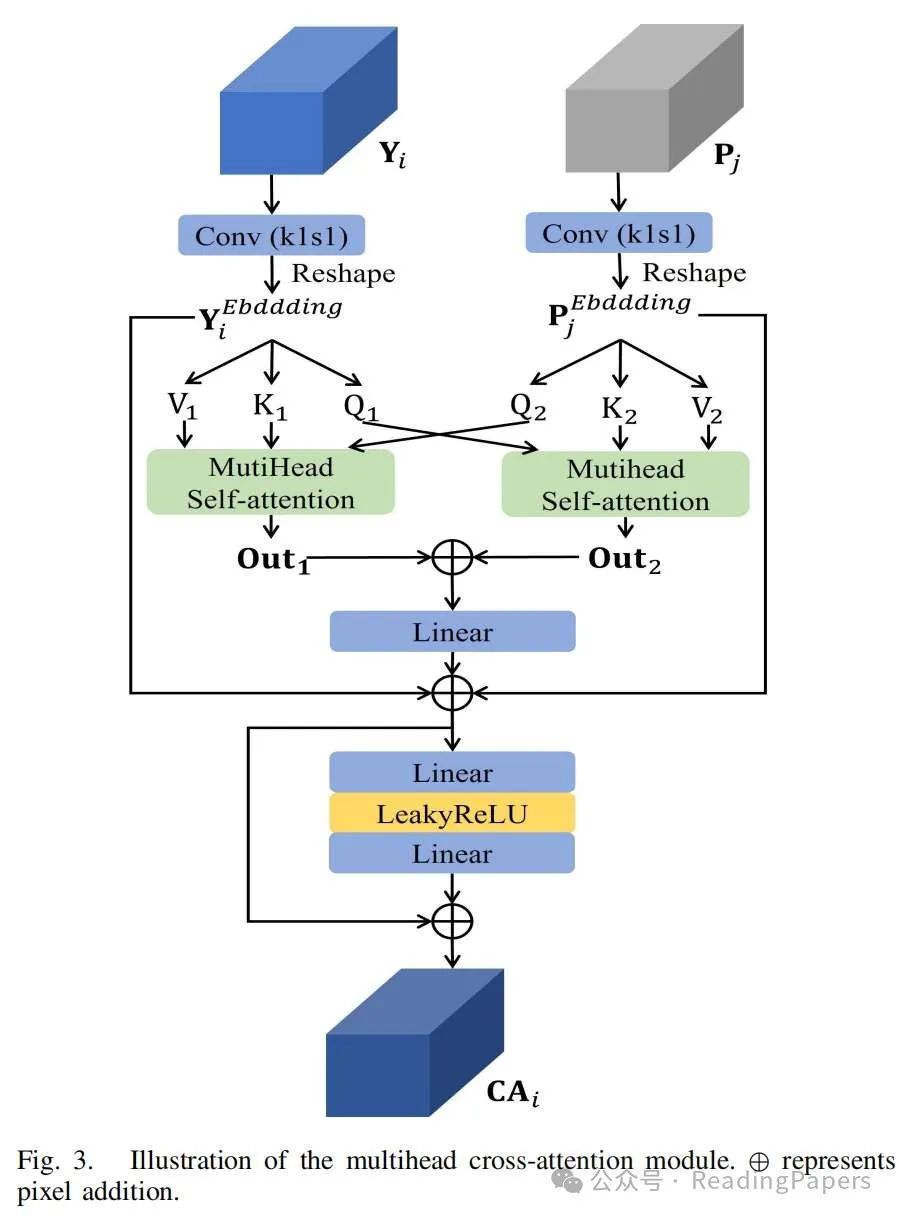
 and
and  ). First,
). First,  and
and  are mapped to the same dimension using convolutional layers with a kernel size of 1, and then reshaped into two sequences. These two sequences are then divided into three subsequences of the same dimension: queries Q, keys K, and values V. By exchanging their Q (a query Q in one sequence combined with keys K and values V in another), the multi-head self-attention results are calculated to achieve feature interaction. Finally, feedforward neural networks (FNN), residual connections, and pixel addition operations are added to further enhance performance. In Figure 2, the multi-head cross-attention pre-calculates the interaction results between Y and P images at multiple scales, described and formulated as follows:
are mapped to the same dimension using convolutional layers with a kernel size of 1, and then reshaped into two sequences. These two sequences are then divided into three subsequences of the same dimension: queries Q, keys K, and values V. By exchanging their Q (a query Q in one sequence combined with keys K and values V in another), the multi-head self-attention results are calculated to achieve feature interaction. Finally, feedforward neural networks (FNN), residual connections, and pixel addition operations are added to further enhance performance. In Figure 2, the multi-head cross-attention pre-calculates the interaction results between Y and P images at multiple scales, described and formulated as follows: represents the intermediate output. Additionally, FNN consists of two layers of linear connection networks and the activation function LeakyReLU.
represents the intermediate output. Additionally, FNN consists of two layers of linear connection networks and the activation function LeakyReLU. and
and  represent convolutional upsampling using a 2-D transpose convolution layer with a kernel size of 2 and a stride of 2. After the above feature aggregation, the generated image retains essential spectral and spatial detail information. We use a detail injection strategy to add these images to the interpolated upsampled LRHS images to further preserve spectral and spatial information:
represent convolutional upsampling using a 2-D transpose convolution layer with a kernel size of 2 and a stride of 2. After the above feature aggregation, the generated image retains essential spectral and spatial detail information. We use a detail injection strategy to add these images to the interpolated upsampled LRHS images to further preserve spectral and spatial information: represents the convolutional layer with a kernel size of 1 and a stride of 1. It is used to map FA to the same dimension as
represents the convolutional layer with a kernel size of 1 and a stride of 1. It is used to map FA to the same dimension as  .
.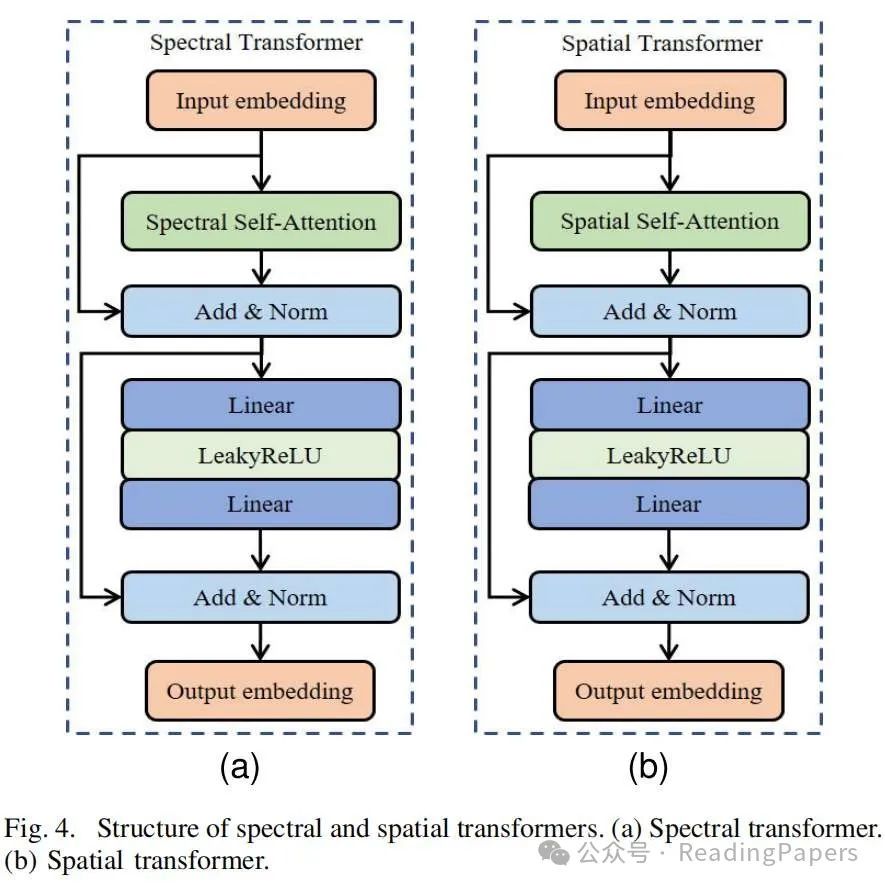
 ) and the generated HRHS image (
) and the generated HRHS image ( ) as real or fake. In Figure 2 and Program 1, we can see the operational process of the spectral transformer discriminator. Unlike traditional discriminators, the spectral transformer discriminator iteratively computes the long-term spectral correlation of feature maps through the spectral transformation module. In each iteration of the spectral transformation, parameters are not shared because the input dimensions are different. This design aims to capture long-term spectral features between different pixel dimensions by gradually reducing dimensions, resulting in excellent classification results at the spectral level. The spatial transformer discriminator is used to distinguish between PAN images (
) as real or fake. In Figure 2 and Program 1, we can see the operational process of the spectral transformer discriminator. Unlike traditional discriminators, the spectral transformer discriminator iteratively computes the long-term spectral correlation of feature maps through the spectral transformation module. In each iteration of the spectral transformation, parameters are not shared because the input dimensions are different. This design aims to capture long-term spectral features between different pixel dimensions by gradually reducing dimensions, resulting in excellent classification results at the spectral level. The spatial transformer discriminator is used to distinguish between PAN images ( ) and the generated HRHS image (
) and the generated HRHS image ( ) as real or fake. In Figure 2 and Program 2, we can see the operational process of the spatial transformer discriminator. As with the above theory, the spatial transformer discriminator also uses an iterative computation strategy, and parameters are not shared in each iteration. Using the spatial transformation module and average pooling operation, long-distance spatial features between different spectra are obtained, achieving excellent classification results at the spatial level. Finally, we use the clip function to map the classification results of the two discriminators to the range of -1 to 1, ensuring compatibility with the hinge loss function and aiding effective model training.
) as real or fake. In Figure 2 and Program 2, we can see the operational process of the spatial transformer discriminator. As with the above theory, the spatial transformer discriminator also uses an iterative computation strategy, and parameters are not shared in each iteration. Using the spatial transformation module and average pooling operation, long-distance spatial features between different spectra are obtained, achieving excellent classification results at the spatial level. Finally, we use the clip function to map the classification results of the two discriminators to the range of -1 to 1, ensuring compatibility with the hinge loss function and aiding effective model training.