Research Progress on Multimodal Named Entity Recognition Methods
Wang Hairong1,2, Xu Xi1, Wang Tong1, Jing Boxiang1
1. School of Computer Science and Engineering, Northern Minzu University; 2. Key Laboratory of Intelligent Processing of Image and Graphics, Northern Minzu University
Click “Read the Original” at the end of the article to view the literature!
Table of Contents

01
Abstract

02
Chart Appreciation

03
Cite This Article

04
Author Introduction
Abstract
In order to address the issues of insufficient semantic representation of text features, lack of semantic representation of visual features, and difficulties in fusing text and image features in multimodal named entity recognition research, a series of multimodal named entity recognition methods have been proposed. First, we summarize the overall framework of multimodal named entity recognition methods and the commonly used techniques in each part. Then, we categorize them into BiLSTM-based MNER methods and Transformer-based MNER methods, and further classify them into four types of model structures: pre-fusion model, post-fusion model, Transformer single-task model, and Transformer multi-task model based on their architecture. Next, experiments were conducted on two datasets, Twitter-2015 and Twitter-2017, for these two types of methods. The experimental results show that the collaborative representation of multiple features can enhance the semantics of each modality, and multi-task learning can promote the fusion of modal features or result fusion, thereby improving the accuracy of MNER. Finally, in future research on MNER, it is suggested to focus on enhancing modal semantics through collaborative representation of multiple features and promoting the fusion of modal features or result fusion through multi-task learning.
Chart Appreciation
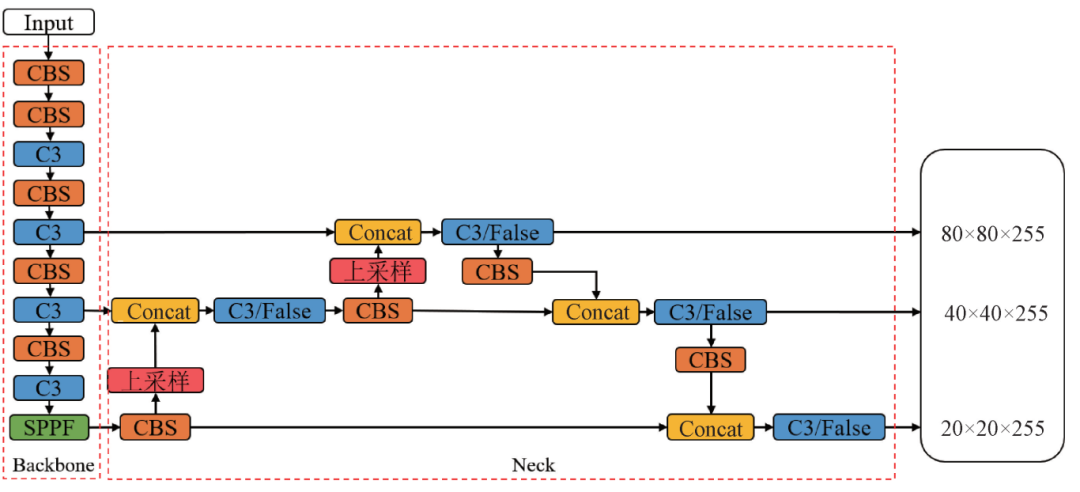
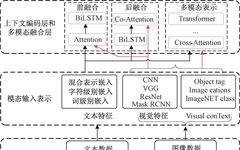
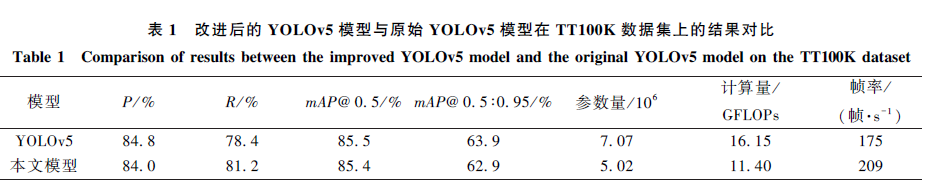
Figure 1 – Structure of YOLOv5
Figure 1 – Structure of YOLOv5
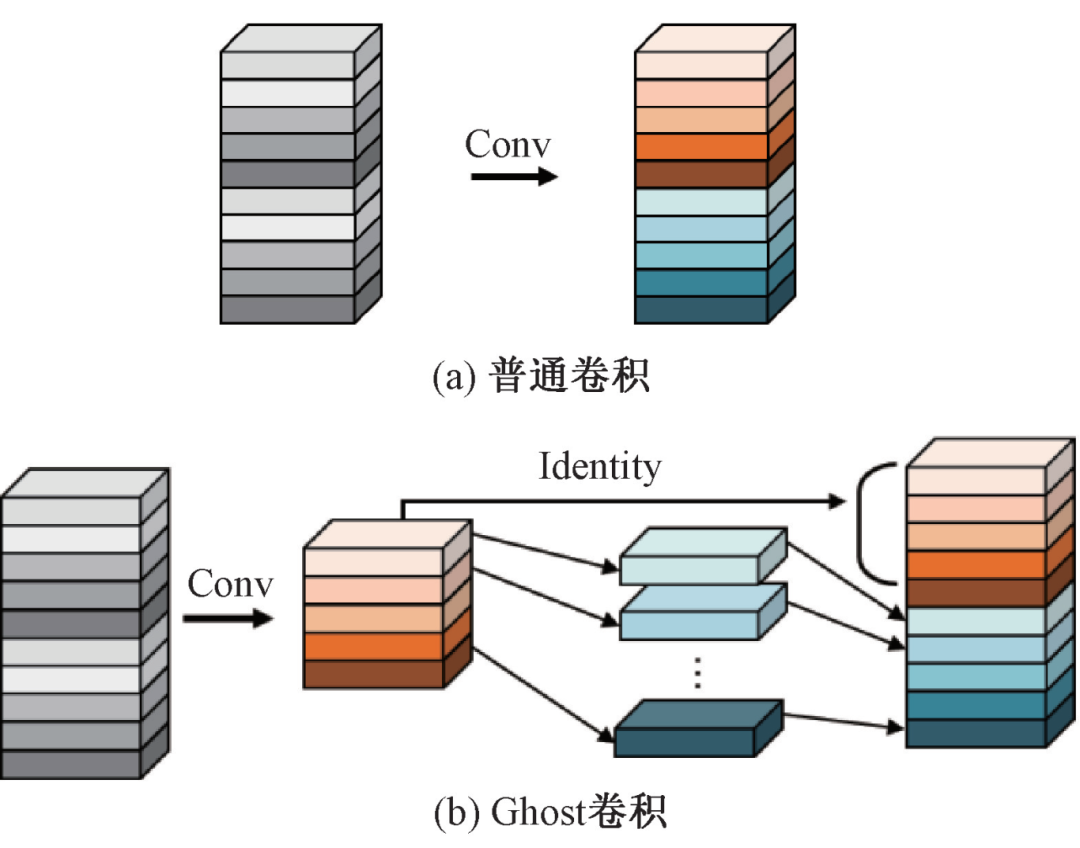
Figure 2 – Normal Convolution and Ghost Convolution
Figure 2 – Normal convolution and Ghost convolution
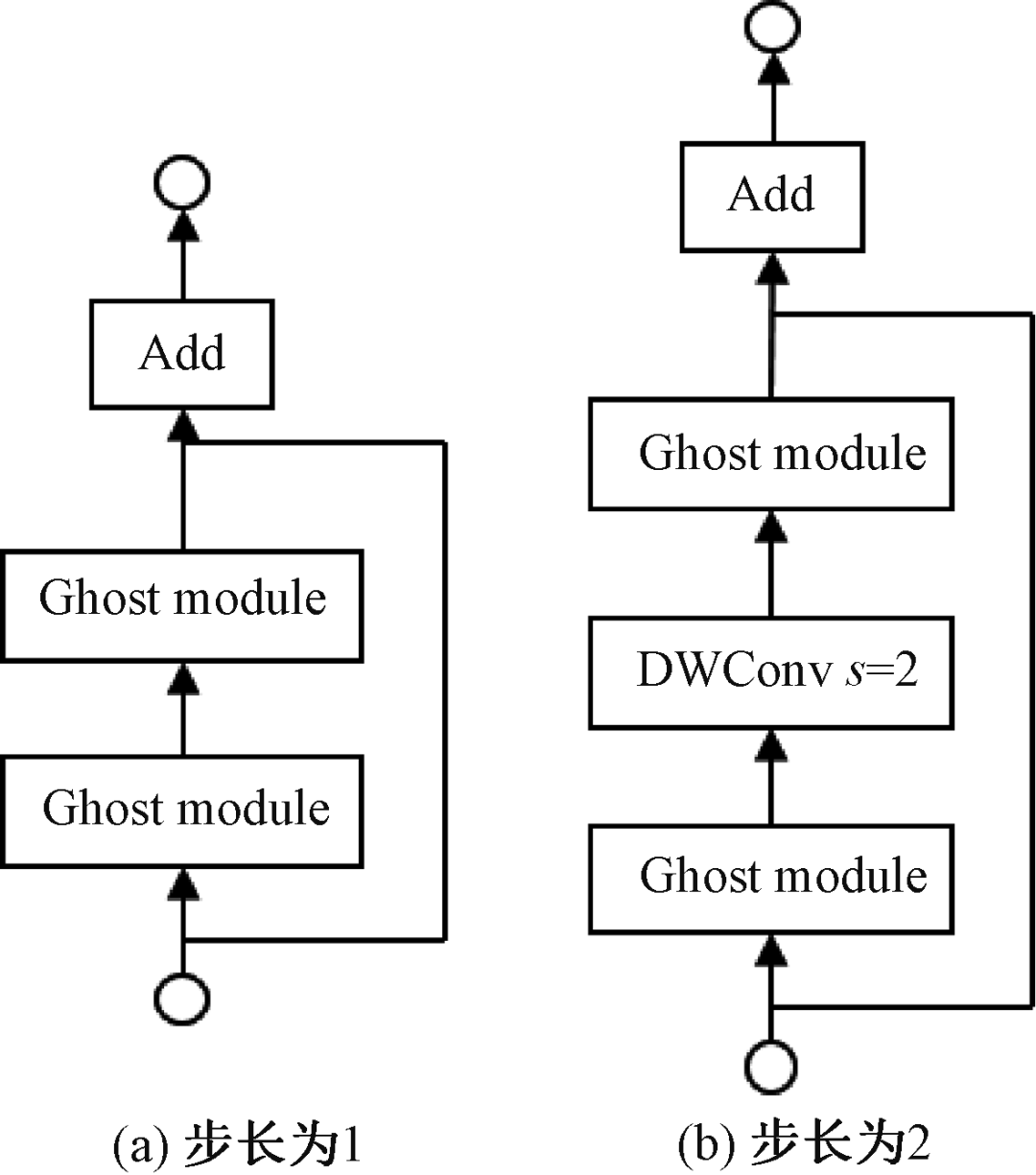
Figure 3 – GhostBottleneck Module
Figure 3 – GhostBottleneck module
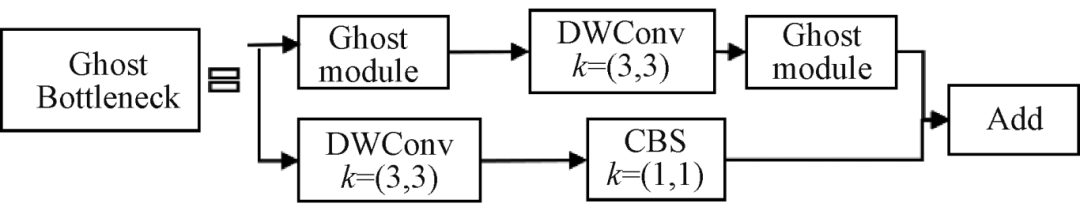
Figure 4 – GhostBottleneck Used in This Article
Figure 4 – GhostBottleneck in this article
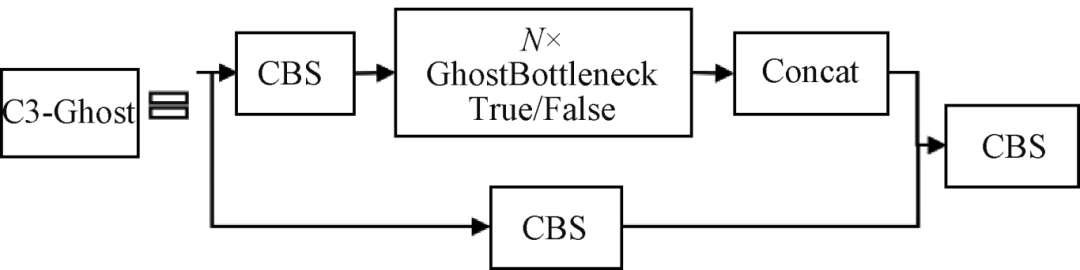
Figure 5 – C3-Ghost Module Based on C3
Figure 5 – C3-Ghost module based on C3
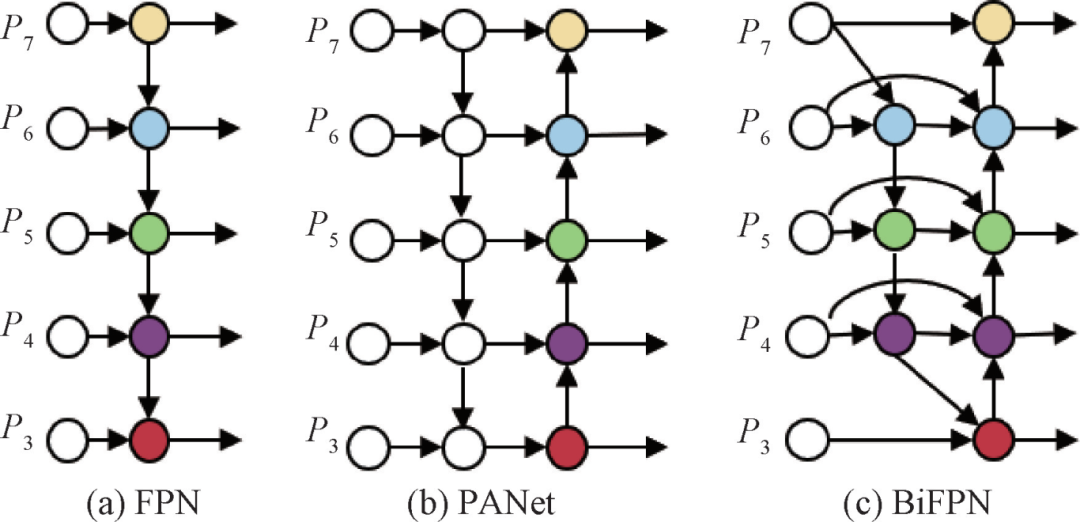
Figure 6 – Structures of FPN, PANet and BiFPN
Figure 6 – Structures of FPN, PANet and BiFPN
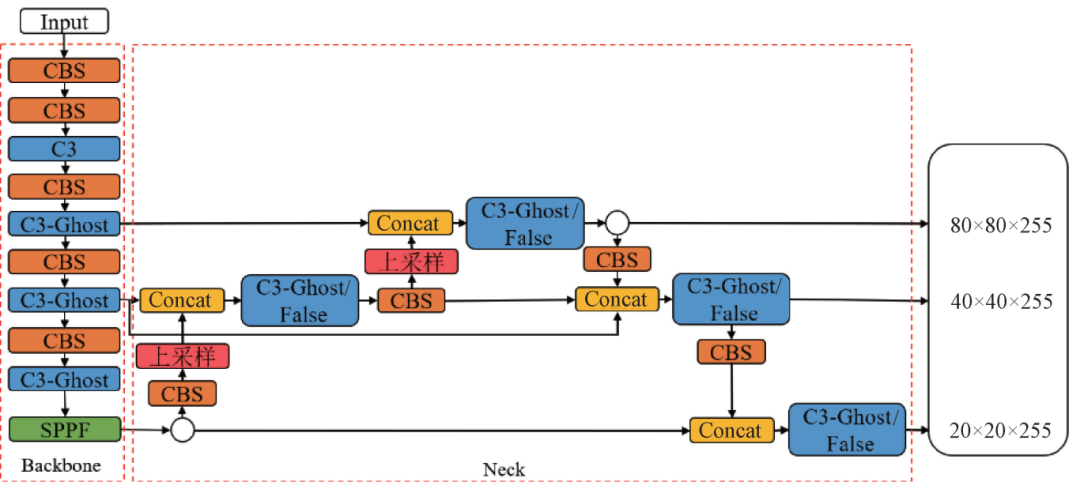
Figure 7 – Structure of Lightweight YOLOv5
Figure 7 – Structure of lightweight YOLOv5

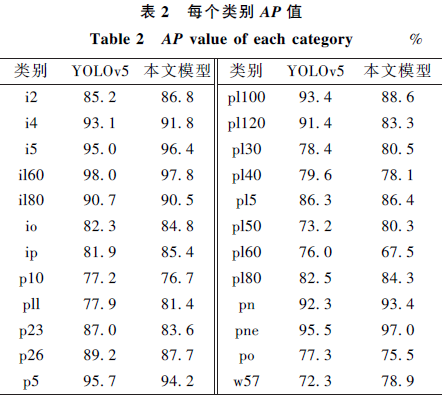
Figure 8 – 24 Traffic Sign Categories
Figure 8 – 24 traffic sign categories

Figure 9 – Training Process Curve
Figure 9 – Training process curve

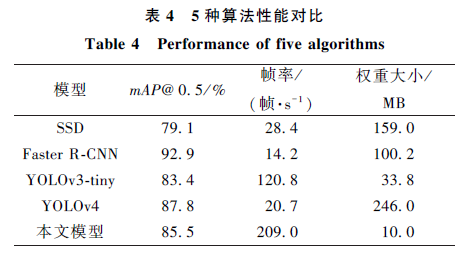
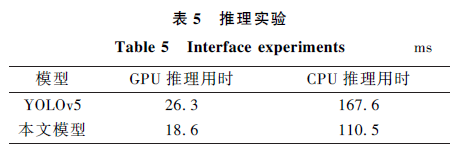
Figure 10 – Results Before and After Improvement
Figure 10 – Results before and after improvement

Cite This Article
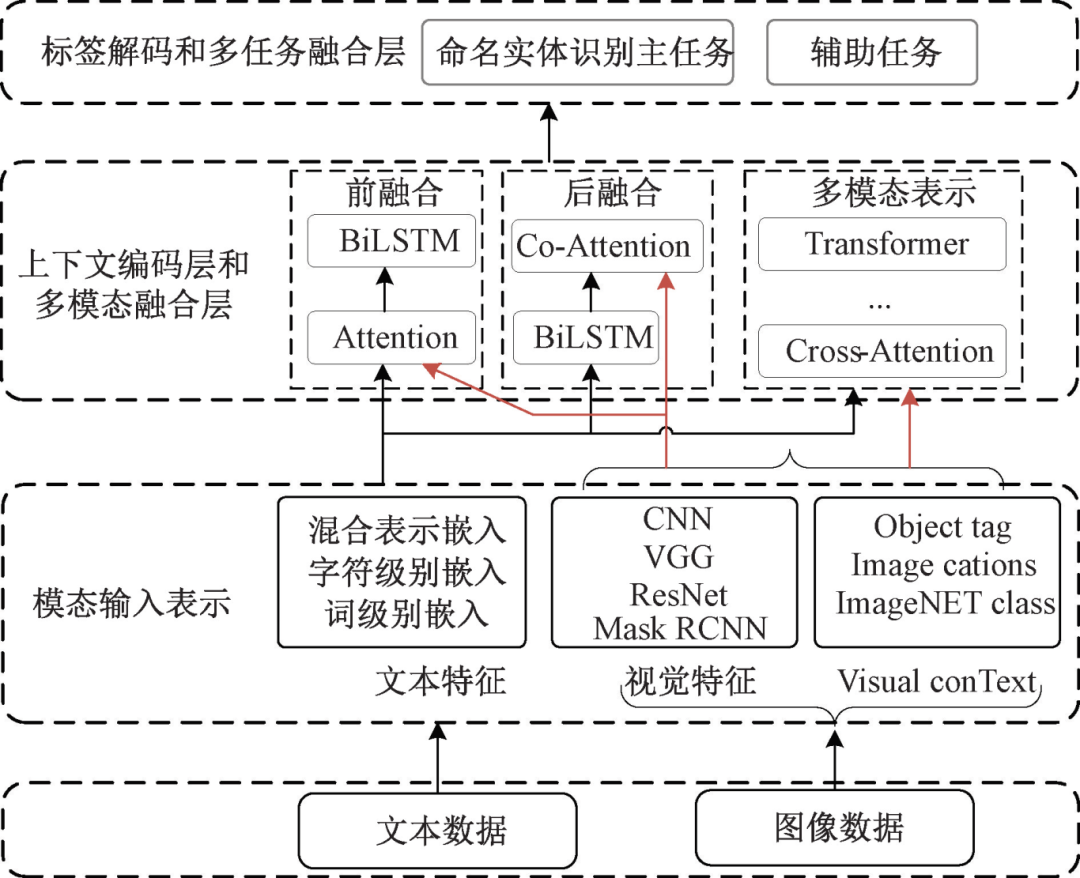
Figure 1 – Basic Framework of Multimodal Named Entity Recognition
Figure 1 – Basic framework of MNER
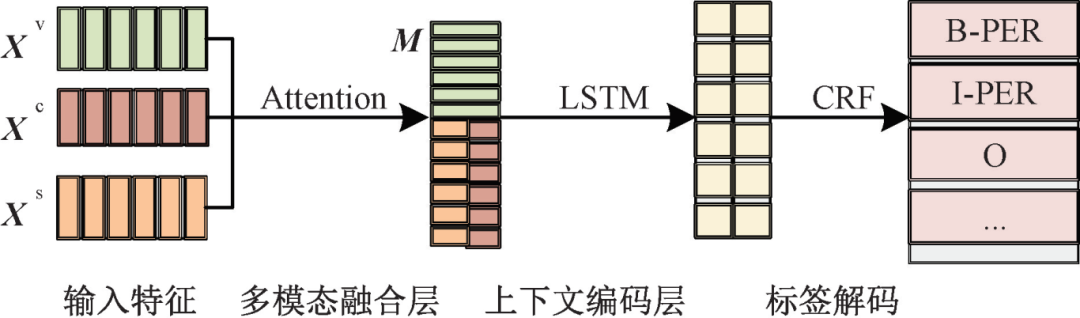
Figure 2 – Pre-fusion Model
Figure 2 – Pre-fusion model

Figure 3 – Post-fusion Model
Figure 3 – Pos-fusion model
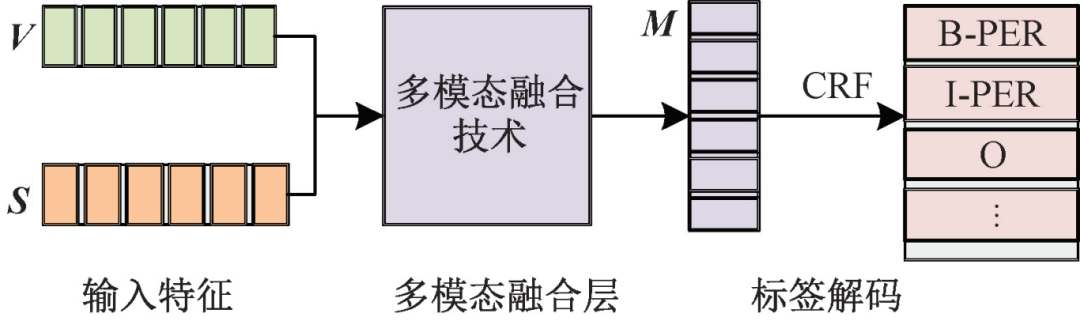
Figure 4 – Transformer Single-task Model
Figure 4 – Transformer single-task model
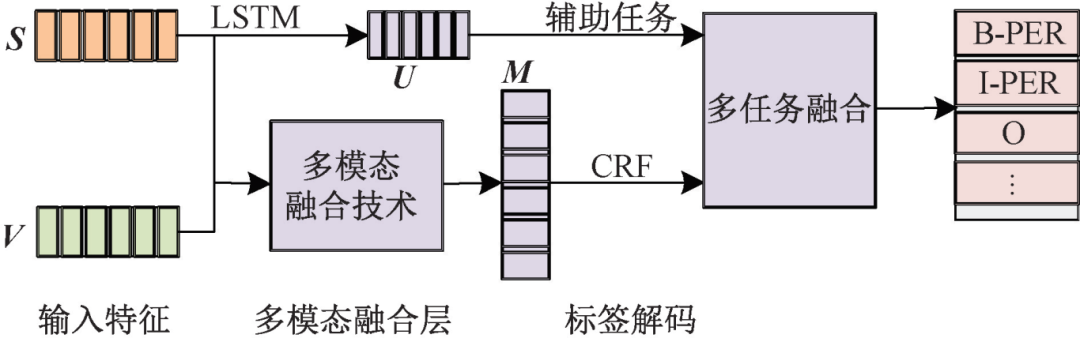
Figure 5 – Transformer Multi-task Model
Figure 5 – Transformer multi-task model


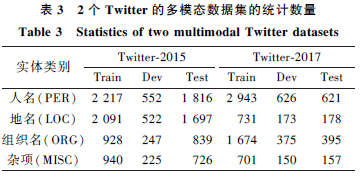
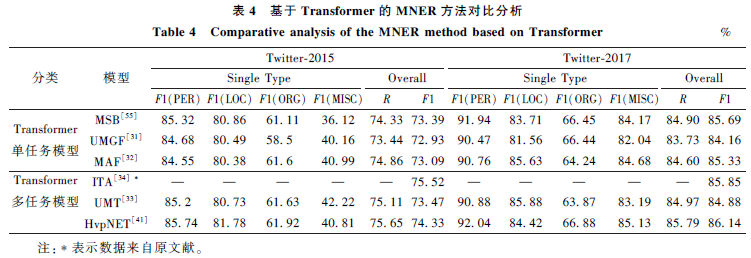
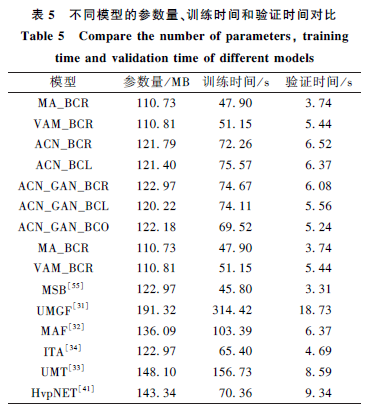
Cite This Article
Wang Hairong, Xu Xi, Wang Tong, et al. Research progress of multimodal named entity recognition [J]. Journal of Zhengzhou University (Engineering Science), 2024, 45(2):60-71.
WANG H R, XU X, WANG T, et al. Research progress of multimodal named entity recognition [J]. Journal of Zhengzhou University (Engineering Science), 2024, 45(2):60-71.
Author Introduction
PhD, Associate Dean of the School of Computer Science and Engineering, Northern Minzu University, Professor, Master’s Supervisor.
Main Research and Teaching Experience: Visiting scholar at Northeastern University in 2010, exchange study at Shanghai University and Fudan University in 2019. Since July 2015, Associate Professor at Northern Minzu University, mainly responsible for teaching courses such as “Natural Language Processing” and “Software Testing”.
Research Achievements: Published more than 40 academic papers in international journals, conferences, and domestic core journals, led and completed more than 10 various research projects, and applied for 8 invention patents. Representative papers: “Multimodal Named Entity Recognition Method with Enhanced Text and Image Semantics”, “Research of Vertical Domain Entity Linking Method Fusing Bert-Binary”, “Research on the Construction Method of Rice Knowledge Graph”, “Knowledge Inference Model of OCR Conversion Error Rules Based on Chinese Character Construction Attributes Knowledge Graph”, “Multi-level Relationship Analysis and Mining Method of Text and Image Data”, etc.
Recruitment Direction and Examination Requirements: Recruiting master’s students in the direction of artificial intelligence and big data processing, multimodal knowledge mining, etc.
Contact Information: Email: [email protected]
✦
Contact Information for Journal of Zhengzhou University (Engineering Science):
Submission Website: http://gxb.zzu.edu.cn
WeChat Public Account: zdxbgxb
Contact Email: [email protected]
Contact Number: 0371-67781276
Contact Number: 0371-67781277
For more exciting content, please follow us

Copyright Statement:
This article is an original content of the editorial department of “Journal of Zhengzhou University (Engineering Science)”, and reprints are welcome!
