

From | Zhihu
Address | https://zhuanlan.zhihu.com/p/91839581
Author | Zhao Qiang
Editor | Machine Learning Algorithms and Natural Language Processing Public Account
This article is for academic sharing only. If there is any infringement, please contact the backend for deletion.
Attention is being applied more and more widely, especially after BERT became popular. What is so special about Attention? What are its principles and essence? What types of Attention are there? This article will explain all aspects of Attention in detail.
What Is the Essence of Attention
The Attention mechanism, if understood superficially, matches its name very well. Its core logic is “from focusing on everything to focusing on key points“.

The Attention mechanism is very similar to how humans look at pictures. When we look at a picture, we do not see the entire content clearly but rather focus our attention on the focal point of the image. Take a look at the picture below:

We will definitely see the four characters “Jinjiang Hotel” clearly, as shown in the image below:

However, I believe no one would notice the string of “phone numbers” above “Jinjiang Hotel” or “Xiyunlai Restaurant”, as shown in the image below:

So, when we look at a picture, it is actually like this:

The visual system described above is a type of Attention mechanism, concentrating limited attention on key information to save resources and quickly obtain the most effective information.
Attention Mechanism in AI
The Attention mechanism was first applied in computer vision and later began to be used in the NLP field, truly flourishing in NLP, because the effects of BERT and GPT in 2018 were surprisingly good, thus gaining popularity. Transformer and Attention became the focus of attention.
To express the position of Attention in a diagram, it is roughly as follows:
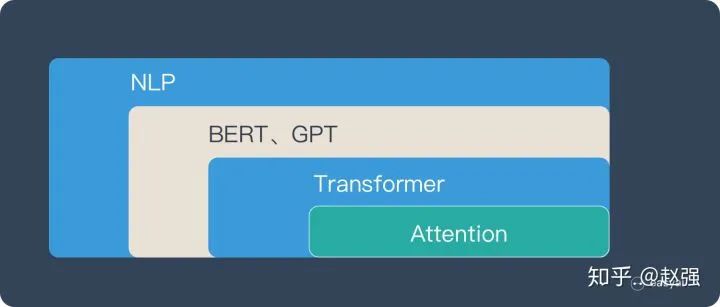
Here, let everyone have a macro concept of Attention; the following text will provide a more detailed explanation of the Attention mechanism. Before that, let’s talk about why we need Attention.
Three Major Advantages of Attention
The main reasons for introducing the Attention mechanism are three:
-
1. Fewer parameters
-
2. Fast speed
-
3. Good performance
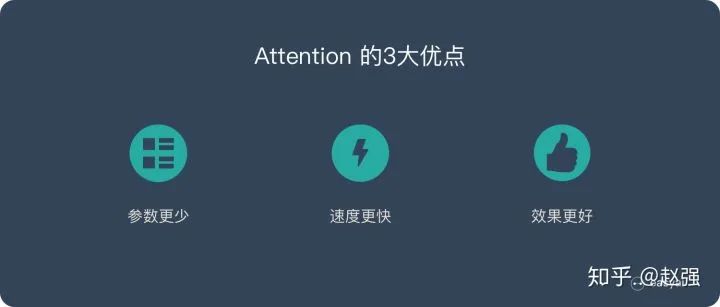
Fewer Parameters
The model complexity is smaller compared to CNN and RNN, with fewer parameters. Therefore, the requirements for computational power are also lower.
Fast Speed
Attention solves the problem that RNN cannot compute in parallel. The Attention mechanism does not depend on the previous computation results at each step, so it can be processed in parallel like CNN.
Good Performance
Before the introduction of the Attention mechanism, there was a problem that everyone was troubled by: long-distance information would be weakened, just like a person with weak memory cannot remember past events.
Attention focuses on key points; even if the text is relatively long, it can capture the key points without losing important information. The red expectation in the image below is the highlighted key point.

The Principle of Attention
Attention is often discussed in conjunction with Encoder–Decoder. The previous article “Understanding the Encoder-Decoder Model Framework in NLP and Seq2Seq” also mentioned Attention.
The following animation demonstrates the general process of introducing Attention into the Encoder-Decoder framework to complete machine translation tasks.
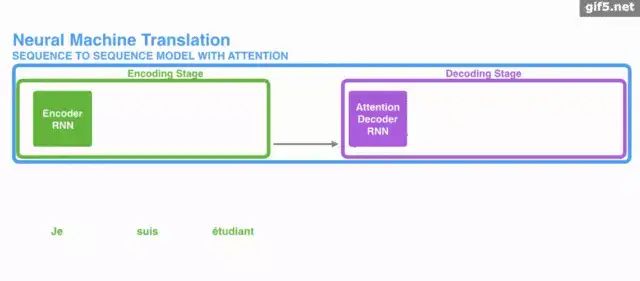
However, Attention does not necessarily have to be used within the Encoder-Decoder framework; it can operate independently of it.
The following image illustrates the principle diagram after separating from the Encoder-Decoder framework.
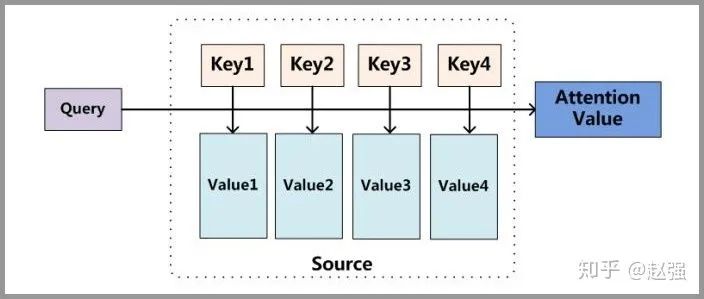
Explaining with a Short Story
The diagram above may seem abstract; let’s explain the principle of Attention with an example:
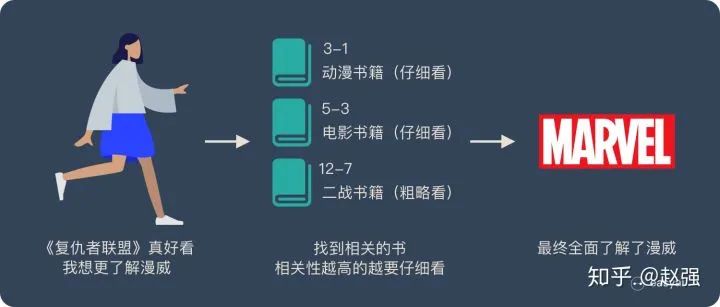
In a library (source), there are many books (value). To facilitate searching, we assign numbers to the books (key). When we want to learn about Marvel (query), we can look at those related comics, movies, or even World War II (Captain America) related books.
To improve efficiency, not all books will be read carefully; for Marvel, comics and movies will be studied in detail (high weight), while World War II books will just be skimmed through (low weight).
After reading everything, we will have a comprehensive understanding of Marvel.
Three Steps to Break Down the Principle of Attention:
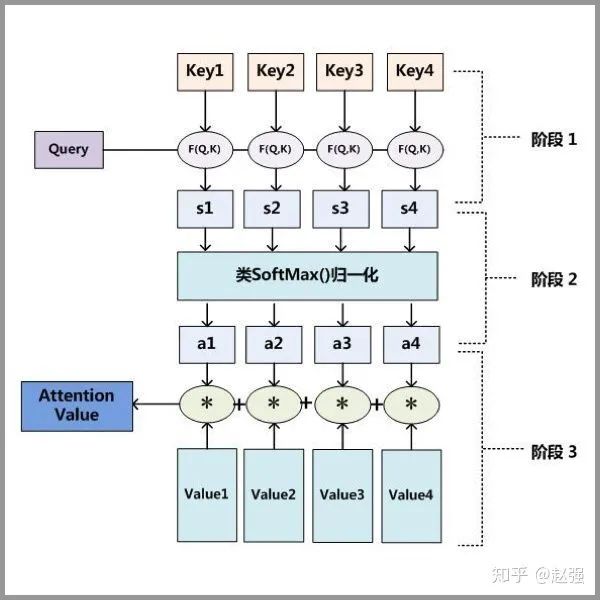
Step 1: Calculate the similarity between query and key to obtain weights.
Step 2: Normalize the weights to get directly usable weights.
Step 3: Perform a weighted sum of the weights and values.
From the modeling above, we can roughly feel that the idea of Attention is simple; the four words “weighted sum” can summarize it highly, simplicity is the ultimate sophistication. To make a somewhat inappropriate analogy, learning a new language generally goes through four stages: rote memorization (learning grammar through reading and recitation) -> grasping the main points (understanding the core meaning by accurately understanding keywords in simple conversations) -> comprehensive understanding (understanding context and connections behind the language in complex conversations, developing the ability to learn through analogy) -> reaching the pinnacle (immersive practice). This is similar to the development of Attention; the RNN era was the period of rote memorization, the Attention model learned to grasp the main points, evolved into transformer, achieved comprehensive understanding and excellent expression learning ability, and then to GPT and BERT, accumulating practical experience through large-scale multi-task learning, greatly enhancing performance. To answer why Attention is so excellent? It is because it enlightens the model, allowing it to grasp the main points and learn comprehensively. — Alibaba Technology
To learn more technical details, you can check out the articles or videos below:
“Article” Attention Mechanism in Deep Learning
“Article” Attention Everywhere, Do You Really Understand It?
“Article” Exploring the Attention Mechanism and Transformer in NLP
“Video” Li Hongyi – Transformer
“Video” Li Hongyi – Explanation of ELMO, BERT, GPT
N Types of Attention
There are many different types of Attention: Soft Attention, Hard Attention, Static Attention, Dynamic Attention, Self Attention, etc. Below, I will explain the differences among these various types of Attention.
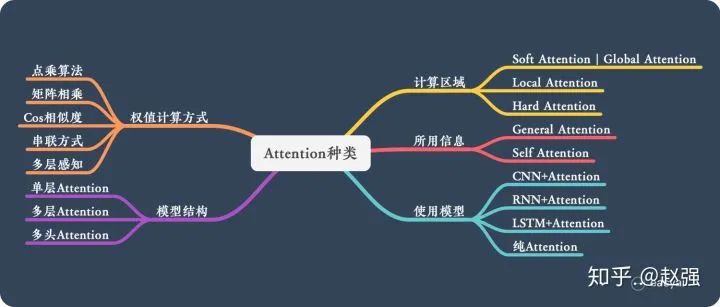
Since the article “Some Summaries of Attention for NLP” has summarized it very well, I will directly quote it below:
This section classifies the forms of Attention based on the calculation area, the information used, structural hierarchy, and models.
1. Calculation Area
Based on the calculation area of Attention, it can be divided into the following types:
1) Soft Attention, which is a more common way of Attention, calculates weight probabilities for all keys, with each key having a corresponding weight. It is a global calculation method (also called Global Attention). This method is relatively rational, referencing the content of all keys before weighting. However, the computational load may be relatively high.
2) Hard Attention, this method directly locates a specific key, ignoring the others. The probability of this key is 1, while the probabilities of the other keys are all 0. Therefore, this alignment method requires high precision; if it is not aligned correctly, it will have a significant impact. On the other hand, because it is non-differentiable, it generally needs to be trained using reinforcement learning methods (or using gumbel softmax, etc.).
3) Local Attention is actually a compromise between the above two methods, calculating within a window area. First, use the Hard method to locate a certain place, and from this point, a window area can be obtained; within this small area, use the Soft method to calculate Attention.
2. Information Used
Assuming we want to calculate Attention for a piece of original text, where the original text refers to the text we want to perform attention on, the information used includes internal information and external information. Internal information refers to the information within the original text, while external information refers to additional information outside the original text.
1) General Attention utilizes external information and is often used in tasks that need to establish relationships between two texts. The query generally contains additional information, aligning the original text based on the external query.
For example, in reading comprehension tasks, it is necessary to establish the relationship between the question and the article. Assuming that the baseline is to calculate a question vector q for the question, the q is concatenated with all the article word vectors and input into LSTM for modeling. In this model, all article word vectors share the same question vector. Now we want each word vector of the article at each step to have a different question vector, meaning that at each step, the word vector of the article at that step calculates attention based on the question, where the question belongs to the original text, and the article word vectors belong to external information.
2) Local Attention uses only internal information; the keys, values, and queries are only related to the input original text. In self-attention, key=value=query. Since there is no external information, each word in the original text can perform Attention calculations with all words in that sentence, which is equivalent to finding internal relationships within the original text.
Still using the reading comprehension task as an example, in the baseline mentioned above, it stated that a vector q is calculated for the question, so here we can also use attention, using only the information of the question itself to perform attention without introducing information from the article.
3. Structural Hierarchy
In terms of structure, Attention can be divided into single-layer attention, multi-layer attention, and multi-head attention based on whether hierarchical relationships are established:
1) Single-layer Attention is a more common practice, using a single query to perform attention on a piece of original text.
2) Multi-layer Attention is generally used for models with hierarchical relationships in the text. Assuming we divide a document into multiple sentences, in the first layer, we perform attention for each sentence to calculate a sentence vector (which is single-layer attention); in the second layer, we perform attention on all sentence vectors to calculate a document vector (also single-layer attention), and finally, use this document vector to perform tasks.
3) Multi-head Attention, as mentioned in “Attention is All You Need”, uses multiple queries to perform attention multiple times on a piece of original text, with each query focusing on different parts of the original text, equivalent to repeating single-layer attention multiple times:
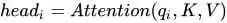
Finally, these results are concatenated together:
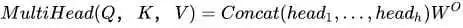
4. Model Aspects
From a model perspective, Attention is generally used in CNN and LSTM, and can also be calculated purely with Attention.
1) CNN + Attention
The convolution operation of CNN can extract important features, which I think also embodies the idea of Attention. However, the convolutional receptive field of CNN is local, requiring multiple layers of convolution to expand the field of view. Additionally, Max Pooling directly extracts the feature with the highest value, which resembles the idea of hard attention, directly selecting a specific feature.
Attention can be added to CNN in the following aspects:
a. Perform attention before convolution, such as Attention-Based BCNN-1, which is a text entailment task that needs to process two texts simultaneously, performing attention on the sequence vectors of both inputs to compute feature vectors, which are then concatenated with the original vectors as input to the convolution layer.
b. Perform attention after convolution, such as Attention-Based BCNN-2, performing attention on the outputs of the convolution layer of both texts as input to the pooling layer.
c. Perform attention at the pooling layer to replace max pooling. For example, Attention pooling first uses LSTM to learn a good sentence vector as the query, then uses CNN to learn a feature matrix as the key, and finally generates weights using the query against the key, performing attention to obtain the final sentence vector.
2) LSTM + Attention
LSTM has a Gate mechanism, where the input gate selects which current information to input, and the forget gate selects which past information to forget. I think this is a form of Attention to some extent, and it is claimed to solve the long-term dependency problem. In reality, LSTM needs to capture sequential information step by step, and its performance on long texts will gradually decline as the steps increase, making it difficult to retain all useful information.
LSTM usually needs to obtain a vector before performing tasks, with common methods including:
a. Directly using the last hidden state (which may lose some previous information, making it difficult to express the entire text).
b. Performing equal-weight averaging on all hidden states at each step (treating all steps equally).
c. Using the Attention mechanism to weight all hidden states, concentrating attention on the important hidden state information throughout the text. This performs slightly better than the previous two methods and allows for visual observation of which steps are important, but care must be taken to avoid overfitting, and it also increases computational load.
3) Pure Attention
Attention is all you need, without using CNN/RNN; at first glance, it seems like a refreshing approach, but upon closer inspection, it is essentially still a lot of vectors calculating attention.
5. Similarity Calculation Methods
When performing attention, we need to calculate the score (similarity) between the query and a certain key. Common methods include:
1) Dot product: the simplest method,
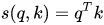
2) Matrix multiplication:
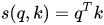
3) Cosine similarity:
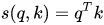
4) Concatenation: concatenating q and k,
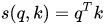
5) Multi-layer perceptron can also be used:
This article was first published in the Product Manager’s AI Knowledge Base. Original address:
Understanding Attention (Principles, Advantages, and Types) – Product Manager’s AI Learning Libraryeasyai.tech
Important! The WeChat group for Natural Language Processing has been established.
You can scan the QR code below to join the group for discussion.
Note: Please modify the remarks to [School/Company + Name + Direction] when adding.
For example – Harbin Institute of Technology + Zhang San + Dialogue System.
The account owner, please avoid adding if you are a micro-business. Thank you!

Recommended Reading:
[Long Article Explanation] From Transformer to BERT Model
Sai Er Translation | Understanding Transformer from Scratch
A picture is worth a thousand words! A step-by-step guide to building a Transformer with Python