Click I Love Computer Vision to get CVML new technologies faster
https://juejin.im/post/5e57d69b6fb9a07c8a5a1aa2
Paper Title: “Attention Is All You Need”
Authors: Ashish Vaswani Google Brain
Published in: NIPS 2017
Introduction
Remember when I attended MLA at Nanjing University in 2018, the big shots at the conference were all talking about the Attention mechanism. So what is Attention? To put it simply, the Attention mechanism is about weighting. Currently, there are three implementations which I categorize as:
-
Attention based on CNN
-
Attention based on RNN
-
Self-Attention, i.e., the Transformer structure
Attention in CNN
Attention based on CNN can be divided into channel-wise and spatial-wise, which can be seen in SE-Block [1] and CBAM-Block [2], while most others are variants of these two.
To explain briefly, for instance, in the channel-wise case, if a feature map at a certain layer has 64 channels, a weight is assigned to each channel, i.e., ,
,
where represents the weight of each channel,
represents the weight of each channel, represents the original features of each channel, and
represents the original features of each channel, and represents the weighted features of each channel, while the weight
represents the weighted features of each channel, while the weight is calculated from all original features using a small neural network, which can be seen as the weight automatically capturing the dependencies between channels.
is calculated from all original features using a small neural network, which can be seen as the weight automatically capturing the dependencies between channels.
Attention in RNN

 to weight
to weight where
where represents the weight of the j-th hidden layer at time t. The formula is as follows:
represents the weight of the j-th hidden layer at time t. The formula is as follows:
 which represents the input of the decoder at the current moment
which represents the input of the decoder at the current moment and the output of the decoder at the time t-1
and the output of the decoder at the time t-1 which indicates the degree of correlation. The higher the correlation, the greater the weight of that
which indicates the degree of correlation. The higher the correlation, the greater the weight of that . The formula is as follows:
. The formula is as follows:
Self-Attention
The above two cases are mentioned briefly without elaboration. Interested students can refer to the literature for details. This article focuses on the Transformer structure mentioned in “Attention is all you need”, which is often referred to as self-attention. This structure was initially used in the field of machine translation.
The paper mentions that the motivation for this method is that when using RNN for sequential modeling, it is inherently sequential, meaning that the output of  must wait for the input of
must wait for the input of  , leading to low computational efficiency and preventing parallel computation. The Transformer directly inputs the entire original sequence without waiting, allowing for direct parallel computation.
, leading to low computational efficiency and preventing parallel computation. The Transformer directly inputs the entire original sequence without waiting, allowing for direct parallel computation.
Transformer Framework
 ‘s vector.
‘s vector. in the MHA’s softmax). Then, after passing through a fully connected layer and softmax layer, it outputs the predicted probabilities at the current moment.
in the MHA’s softmax). Then, after passing through a fully connected layer and softmax layer, it outputs the predicted probabilities at the current moment.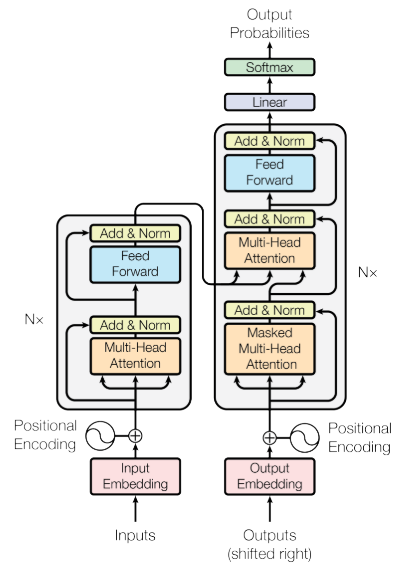
Multi-Head Attention
To clarify Multi-Head Attention, we must start from single Attention. The paper refers to single Attention as ProScaled Dot-Product Attention, structured as shown in the left diagram:
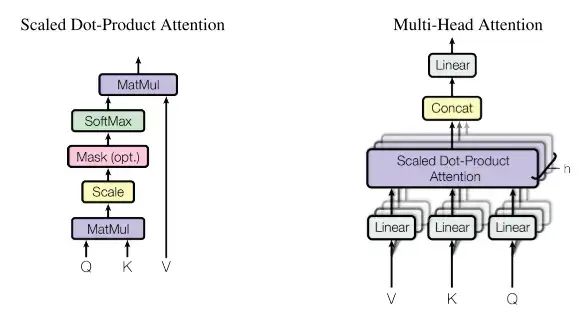
First, we define the queries  , keys
, keys  , and values
, and values  , then the formula for single Attention is as follows:
, then the formula for single Attention is as follows:

Thus, the softmax yields a weight that weights V. So how is self-similarity reflected? From the Transformer structure above, we know that Q, K, and V are the same input. Therefore, the calculated weights are influenced most by the keys most relevant to the queries, meaning that the elements most relevant to the current element in the input sequence have the greatest influence.
Multi-Head Attention, as shown in the right diagram, is simply repeating single Attention multiple times and concatenating the output vectors, which are then passed to a fully connected layer to produce the final result. The formula is as follows:

Thus, the structure of the transformer has been explained. We find that this structure indeed improves computational efficiency and captures self-similarity in the data, and can handle long-range dependencies well (because the input is to input all elements together; I must say that Google is really rich; without enough computing resources, who could come up with such a money-burning method). There are many interesting implementation details, and I will dig deeper into them and write another blog about them if I have the opportunity in the future.
References
[1] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7132-7141.
[2] Woo S, Park J, Lee J Y, et al. CBAM: Convolutional Block Attention Module[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 3-19.
[3] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
CV Subdivision Direction Group Chat
52CV has established multiple professional CV group chats, including: object tracking, object detection, semantic segmentation, pose estimation, face recognition and detection, medical image processing, super-resolution, neural architecture search, GAN, reinforcement learning, etc. Scan the code to add CV Jun to pull you into the group. If you are already friends with CV Jun’s other accounts, please directly private message him,
(Please be sure to specify the relevant direction, for example: object detection)

If you prefer to communicate in QQ, you can add 52CV’s official QQ group: 805388940.
(I may not be online all the time. If I can’t verify in time, please forgive me)

Long press to follow I Love Computer Vision