
“ This article provides a deep analysis of the Transformer model, including the overall architecture, the background and details of the Attention structure, the meanings of QKV, the essence of Multi-head Attention, FFN, Positional Embedding, and Layer Normalization, as well as everything you want to know!
“
The author is : Pang Xiaoxiao, an algorithm engineer at ByteDance AI-Lab, focusing on machine translation, speaks French, enjoys music, writing, recording, and drone aerial photography (just starting out). There is a referral link at the end of the article, feel free to connect and submit!!
“Transformer” is a model architecture proposed in the 2017 paper “Attention is All You Need”. This paper conducted experiments only for the scenario of machine translation, completely defeating the then SOTA, and due to the parallel computation on the encoder side, training time was greatly reduced.
Its groundbreaking idea has overturned the previous notion of equating sequence modeling with RNNs, and it is now widely used in various fields of NLP. Currently, language models such as GPT and BERT, which are flourishing in various NLP tasks, are all based on the Transformer model. Therefore, understanding every detail of the Transformer model is particularly important.
Given that there are numerous articles in both Chinese and English about Transformers, repetitive and superficial content will not be reiterated here. In this article, I will strive to find some core and detailed points to analyze and explain the relationship between details and the overall function.
This article aims to be accessible yet thorough, seeking to cover every confusion I encountered during my learning, achieving “understanding the phenomenon and the reasons behind it”. I believe that through my detailed analysis, everyone will gain a deeper understanding of the function of each part of the Transformer, thus elevating their overall understanding of this model architecture to a new level and deeply understanding the motivation behind the Transformer and its extended work.
This article will unfold according to the following ideas
0. Overall architecture of Transformer
-
Background of Attention (Why is there Attention?) -
Details of Attention (What is Attention?) -
Query, Key, Value -
Essence of Multi-head Attention -
Other parts of the Transformer model architecture -
Feed Forward Network -
Positional Embedding -
Layer Normalization -
Comparison of Transformer and RNN -
References
0. Transformer Architecture
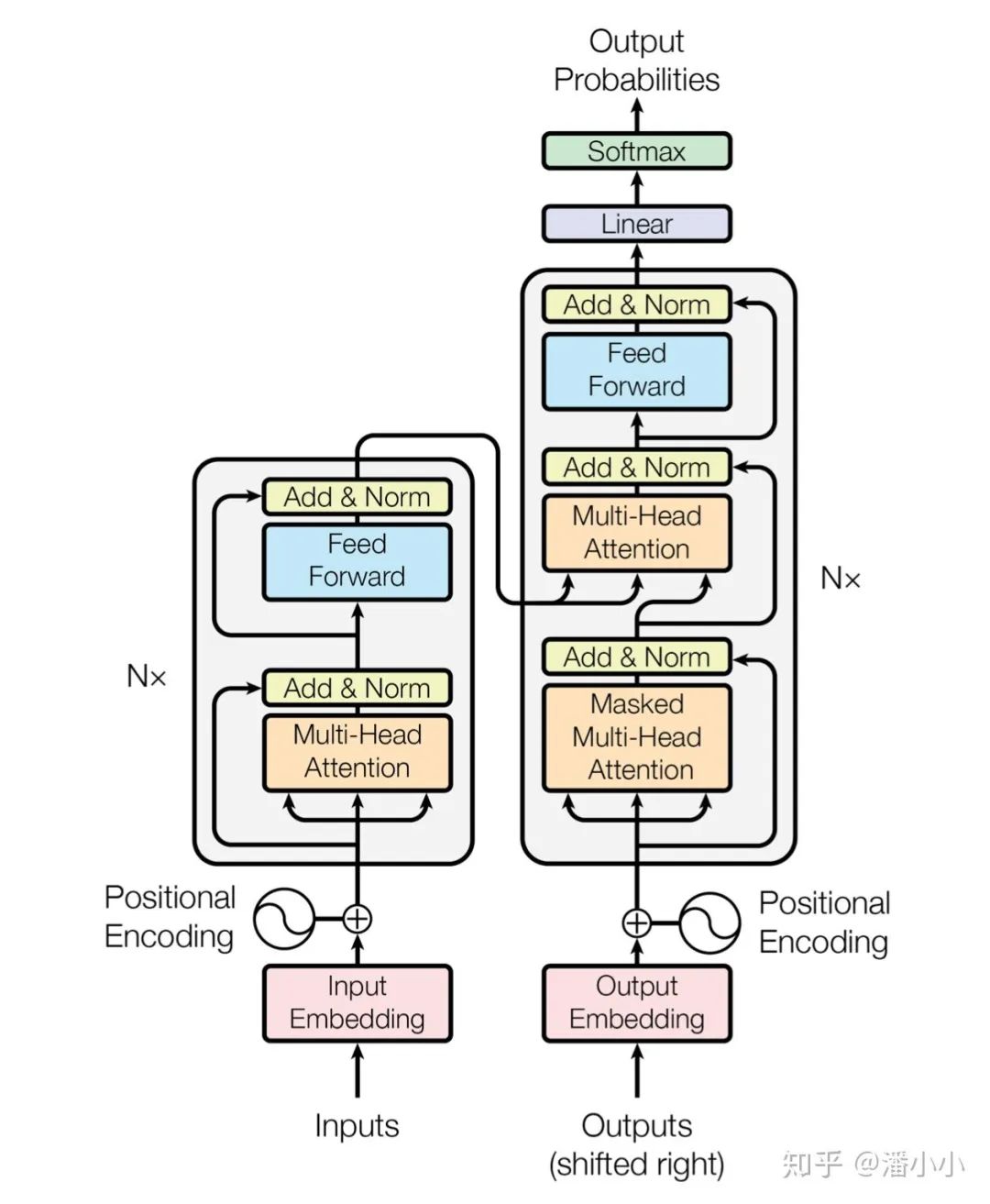
Here, I will not elaborate on the meanings of encoder and decoder and their modules but will directly address the details. “The following key questions will be addressed:”
-
How does Attention work, what are the meanings and functions of its parameters, how does the backpropagation algorithm update these parameters, and how does it affect the updates of other parameters? -
Why use scaled attention? -
Why does Multi-head attention work better than single-head attention, and what is its essence? Analyze from the perspective of the backpropagation algorithm? -
How does Positional encoding work, and how does it affect the updates of other parameters when applying the backpropagation algorithm? The same theory can be extended to other additional embeddings, such as language embeddings in multilingual models. -
What is the role of the feed-forward part in each encoder/decoder layer, and analyze from the perspective of the backpropagation algorithm? -
Details of the backpropagation algorithm in the decoder with masking, how to ensure consistency between training and inference? -
What happens if there is inconsistency (decoder does not use mask)?
1. Background of Attention
To deeply understand the Attention mechanism, it is necessary to understand its background, the types of problems it was generated for, and the initial problems it aimed to solve.
First, let’s review the evolution history of models in the field of machine translation:
Machine translation began its journey into the neural network era from RNNs, with several important stages: Simple RNN, Contextualized RNN, Contextualized RNN with attention, Transformer (2017). Let’s introduce them one by one.
-
“Simple RNN”: In this encoder-decoder model structure, the encoder compresses the entire source sequence (regardless of length) into a vector (encoder output), and the only connection between the source information and the decoder is that the encoder output serves as the input to the decoder’s initial states. This leads to an obvious problem: as the decoder length increases, the information in the encoder output diminishes.
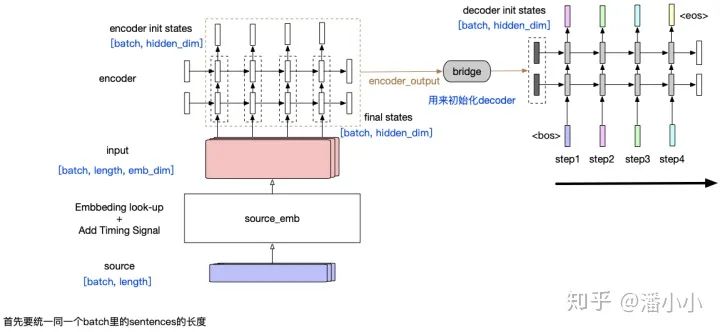
This model has two main problems:
-
The source sequence, regardless of its length, is uniformly compressed into a fixed-dimensional vector, and it is evident that this vector contains more information about the tokens at the end of the source sequence, and if the sequence is very long, it may ultimately “forget” the information about the tokens at the beginning of the sequence. -
The second problem is also caused by the characteristics of RNNs: as the information in the decoder timesteps increases, the information contained in the initial hidden states related to the encoder output also diminishes, causing the decoder to gradually “forget” the information of the source sequence and focus more on the tokens in the target sequence that precede that timestep.
-
“Contextualized RNN”: To address the second problem, which is the diminishing information of the encoder output as the decoder timesteps increase, a contextualized RNN sequence-to-sequence model was proposed: at each timestep, the decoder adds a context to its input. For ease of understanding, we can regard this as the encoded source sentence. This allows the decoder to input the entire source sentence’s information along with the current token of the target sequence at each step, preventing the source context information from diminishing as the timesteps grow.
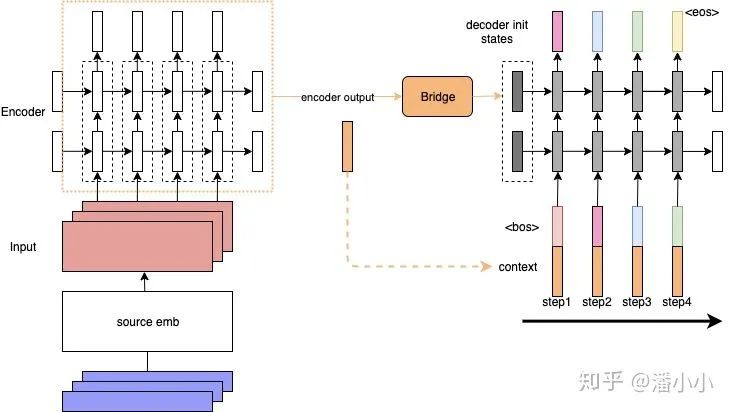
However, there is still an issue: the context for each timestep is static (the final hidden states of the encoder or the average of the outputs at all timesteps). But should the context used for each decoder token during decoding really be the same? In this context, Attention was born:
-
“Contextualized RNN with soft align (Attention)”: The application of Attention in the field of machine translation was first proposed in a 2014 paper titled Neural Machine Translation by Jointly Learning to Align and Translate.
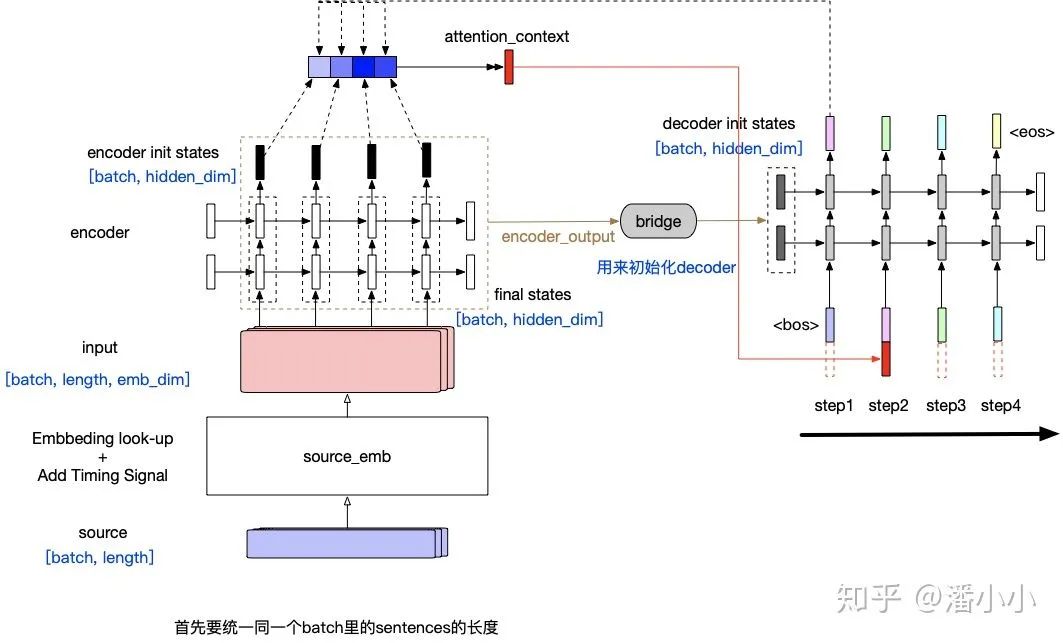
Before the input of each timestep into the decoder RNN structure, an “attention” operation is performed between the vector of the current input token and each vector of the encoder output’s positions. The purpose of this “attention” operation is to calculate the “relevance” between the current token and each position, thus determining the weight of each position’s vector in the final context for that timestep. The final context is the “weighted average” of each position’s vector in the encoder output.
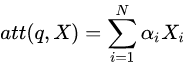
2. Details of Attention
2.1. Dot Product Attention
Let’s introduce the specific calculation method of attention. There are many ways to calculate attention: additive attention, dot product attention, and parameterized calculation methods. Here, we focus on the formula for dot product attention:
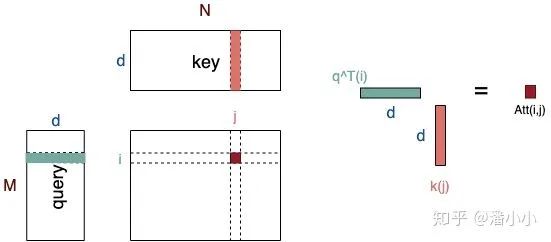
As shown in the figure, , are the query and key, where the query can be regarded as a vector composed of M dimensions of d (the vector representation of a sequence of length M), and the key can be regarded as a vector composed of N dimensions of d (the vector representation of a sequence of length N).
-
【A small question】Why is there a scaling factor ? -
One sentence to answer this question: The scaling factor serves to “normalize”. -
Assume that the elements in , have a mean of 0 and a variance of 1, then the mean of the elements in will be 0 and the variance will be d. When d becomes very large, the variance of the elements in will also become very large. If the variance of the elements in is large, then the distribution of will tend to become steep (the larger the variance of the distribution, the more concentrated it is in the regions of large absolute values). In summary, the distribution of will be related to d. Therefore, multiplying each element in by will restore the variance to 1. This decouples the steepness of the distribution from d, thereby keeping the gradient values stable during the training process. -
Linear transformation matrices mapping , , to , , -
Linear transformation matrix mapping the output expression to the final output -
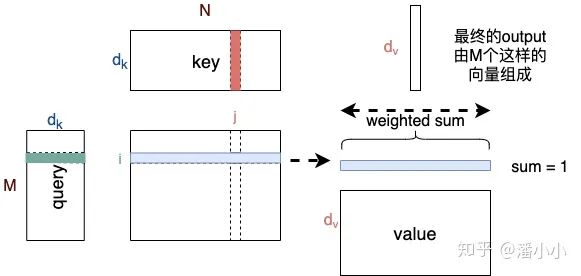
The dimensions of Query and Key must match, while the dimensions of Value can differ from those of Query/Key. -
The lengths of Key and Value must be the same. Key and Value essentially correspond to the same Sequence expressed in different spaces. -
The dimension of the Output obtained from Attention matches that of Value, and its length matches that of Query. -
Each position i of the Output is a vector resulting from the weighted average of all position vectors of Value; the weights are obtained from the attention calculations between the query at position i and all positions of key, with the number of weights equal to the length of key/value. -
The q, k, v of self-attention are all the same input, i.e., the high-dimensional representation output by the previous layer of the current sequence. -
The q of cross-attention represents the current sequence, while k, v are the same input, corresponding to the output of the last layer of the encoder (which remains unchanged for each layer of the decoder).
2.2. Parameters involved in the Attention mechanism
A complete attention layer involves the following parameters:
2.3. Query, Key, Value
The attention weights obtained from Query and Key are applied to Value. Therefore, their relationships are:
In the classic Transformer structure, we denote the linear mappings before Query, Key, Value as q, k, v, and after mapping as Q, K, V. Therefore:
Each layer’s linear mapping parameter matrix is independent, so the mapped Q, K, V are different. The optimization goal of the model parameters is to map q, k, v into a new high-dimensional space, allowing each layer’s Q, K, V to capture the relationships between q, k, v at different abstract levels. Generally, the lower layers capture more lexical-level relationships, while the higher layers capture more semantic-level relationships.
2.4. Role of Attention
In the following section, I will explain the role of attention using machine translation as an example, and clarify the meanings of query, key, and value in simple terms.
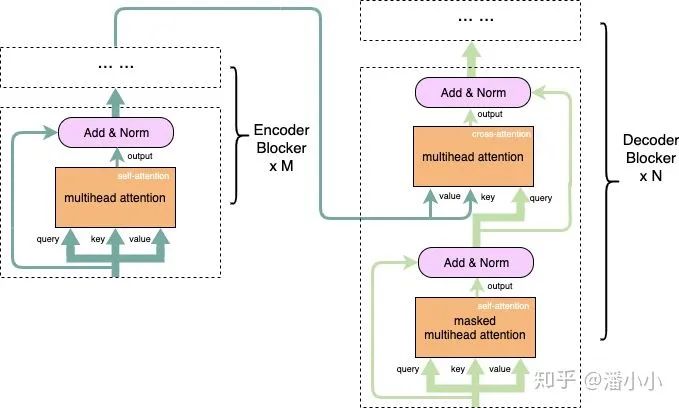
Query corresponds to the sequence that needs to be “expressed” (referred to as sequence A), while Key and Value correspond to the sequence “used to express” A (referred to as sequence B). Here, Key and Query are in the same high-dimensional space (otherwise they cannot be used to calculate similarity), while Value does not have to be in the same high-dimensional space, and the final output is in the same high-dimensional space as Value. In simpler terms, this can be described as:
❝
The high-dimensional expressions of sequence A and sequence B in high-dimensional space are calculated for similarity at each position _“respectively” _ , and the resulting weights are applied to the high-dimensional expression of sequence B, obtaining the high-dimensional expression of sequence A.
❞
In the encoder, there is only self-attention, while in the decoder, there is both self-attention and cross-attention.
【Self-Attention】 In the encoder, the self-attention’s query, key, and value all correspond to the source sequence (i.e., A and B are the same sequence), while in the decoder, the self-attention’s query, key, and value correspond to the target sequence.
【Cross-Attention】 In the decoder, the cross-attention’s query corresponds to the target sequence, while key and value correspond to the source sequence (the cross-attention used in each layer is the final output of the encoder).
2.5. Masking on the Decoder Side
The Transformer model is a self-regressive model (p.s. I will write a separate article to introduce non-autoregressive translation models), meaning that the inference of subsequent tokens is based on the previous tokens. The function of masking on the decoder side is to ensure consistency between the training phase and the inference phase.
The original text from the paper regarding this point is as follows:
❝
We also modify the self-attention sub-layer in the decoder stack to prevent attending to subsequent positions. This masking, combined with the fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
❞
During the inference phase, tokens are inferred in a left-to-right order. This means that when inferring the token at timestep T, the decoder can only “see” the T-1 tokens at timesteps < T and cannot perform attention with tokens at timesteps greater than itself (since it does not yet know what the subsequent tokens are). To ensure consistency between training and inference, during training, we must also prevent tokens from attending to those that come after them.
2.6. Multi-head Attention
Attention maps the query and key into the same high-dimensional space to calculate similarity, while multi-head attention maps the query and key into different subspaces of the high-dimensional space to calculate similarity.
Why do we need multi-head attention? The original paper states:
❝
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.
❞
This means that it enhances the expressiveness of each layer’s attention without changing the amount of parameters. 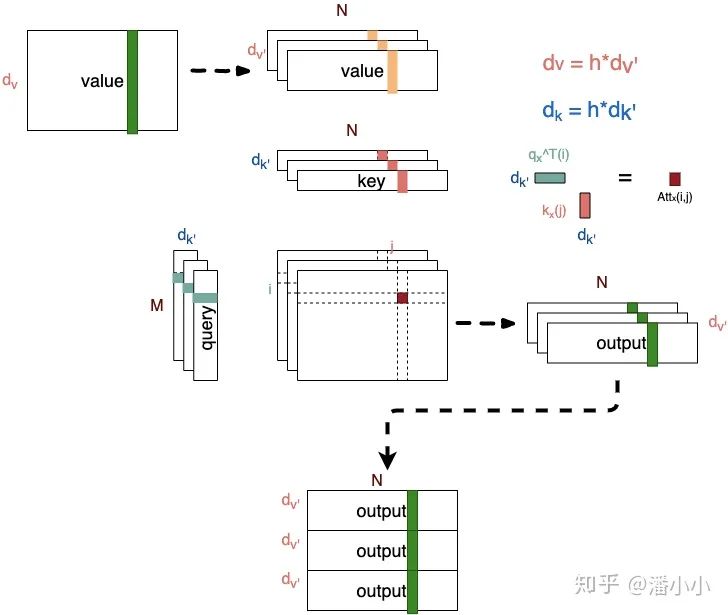 Diagram of Multi-head Attention
Diagram of Multi-head Attention
The essence of Multi-head Attention is to map the same query, key, and value into different subspaces of the original high-dimensional space for attention calculations while merging the attention information from different subspaces in the final step. This reduces the dimensionality of each vector when calculating attention for each head, which in a sense prevents overfitting; since Attention has different distributions in different subspaces, Multi-head Attention effectively finds the relationships between sequences from different perspectives and integrates the associations captured in different subspaces during the final concatenation step.
As can be seen from the above figure, the attention score between and has changed from 1 to h, corresponding to their association in h subspaces.
3. Other Parts of the Transformer Model Architecture
3.1. Feed Forward Network
After each layer passes through attention, there is a FFN, which serves to transform the space. The FFN consists of two layers of linear transformation, with the activation function being ReLu.
I once had a perplexing question here: why is there an additional two-layer FFN network after the attention layer’s output is multiplied with ?
In fact, the addition of the FFN introduces non-linearity (ReLu activation function), transforming the space of the attention output, thereby increasing the model’s expressive capacity. The model can still work without the FFN, but its performance is significantly worse.
3.2. Positional Encoding
The positional encoding layer appears only after the embedding of the encoder and decoder, before the first block. It is very important; without this part, the Transformer model would be unusable. Positional encoding is a unique component of the Transformer framework, compensating for the Attention mechanism’s inability to capture positional information.
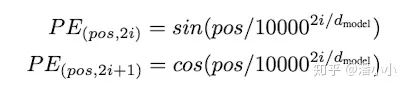
Positional Embedding is directly added to the Embedding, allowing the positional information of each token to be fully integrated with its semantic information (embedding) and passed into all subsequent complex transformations of the sequence representation.
The Positional Encoding (PE) used in the paper is a sinusoidal function; the smaller the position (pos), the longer the wavelength, and each position corresponds to a unique PE. The authors also mentioned that the reason for using sinusoidal functions as PE is that this allows the model to learn the relative positional relationships between tokens: because for any offset k, can be represented linearly by:
The above two formulas can be obtained from the linear combinations of and .
Also, multiplying by a certain linear transformation matrix yields .
p.s. A subsequent work used “relative position representations” in attention (Self-Attention with Relative Position Representations), which may be of interest.
3.3. Layer Normalization
At the end of each block, Layer Normalization appears. Layer Normalization is a general technique that essentially normalizes the optimization space, accelerating convergence.
When we optimize using gradient descent, as the depth of the network increases, the distribution of the data continuously changes. Assuming features are only two-dimensional, this can be illustrated as follows:
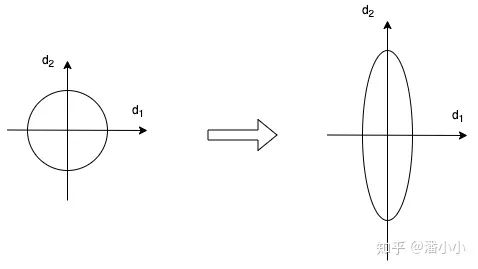 The distribution of data changes; the left image is more normalized, while the right image becomes unnormalized
The distribution of data changes; the left image is more normalized, while the right image becomes unnormalizedTo ensure the stability of the data feature distribution (as shown in the left image), we add Layer Normalization, which can speed up the model’s optimization.
p.s. I will also write a separate article discussing various normalization techniques, so stay tuned~
4. Comparison of Transformer Structure and RNN Structure
Emmm, I will add this part in a few days…
5. References
How Much Attention Do You Need? A Granular Analysis of Neural Machine Translation Architectures Attention is all you need; Attentional Neural Network Models | Łukasz Kaiser| Masterclass[ The Illustrated Transformer](https://link.zhihu.com/?target=https%3A//jalammar.github.io/illustrated-transformer/) Juliuszh: Detailed explanation of Normalization in Deep Learning, BN/LN/WN
Please stay tuned……
This article only briefly introduces the Transformer; numerous subsequent studies based on Transformer are shining in various fields of natural language processing. I will gradually introduce some of the latest developments in my follow-up articles:
[Paper Discussion] Various Optimizations and Improvements of Transformer
[Classic Discussion] Text Pre-training Models (BERT, XLNET, Roberta)
[Classic Discussion] Cross-Language Pre-training Machine Translation Models/Language Models
Phew~ Finally finished writing! Fireworks!
Sharing the repository address:
Reply "code" in the background of the Machine Learning Algorithm and Natural Language Processing public account to obtain 195 NAACL + 295 ACL2019 papers with open-source code. The open-source address is as follows: https://github.com/yizhen20133868/NLP-Conferences-Code
Big news! The Yizhen Natural Language Processing - Pytorch group has officially been established! There are a lot of resources in the group, and you are welcome to join and learn! Please modify the note to [School/Company + Name + Direction] when adding. For example - Harbin Institute of Technology + Zhang San + Dialogue System. The account owner, WeChat merchants, please consciously bypass. Thank you!
Recommended reading:
Longformer: A Pre-trained Model Born for Long Documents Beyond RoBERTa
Understanding KL Divergence Intuitively in One Article
Top 100 Must-Read Papers in Machine Learning: High Citation, Comprehensive Classification, Wide Coverage | GitHub 21.4k stars