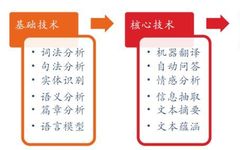

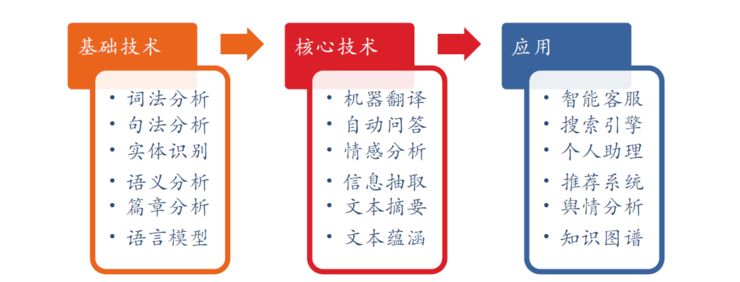
Source: Deep Learning and NLP
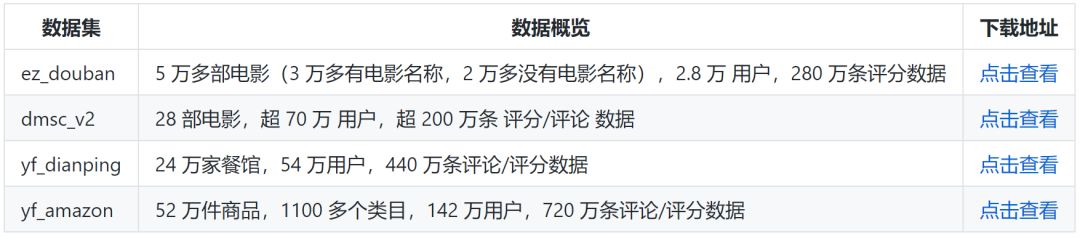
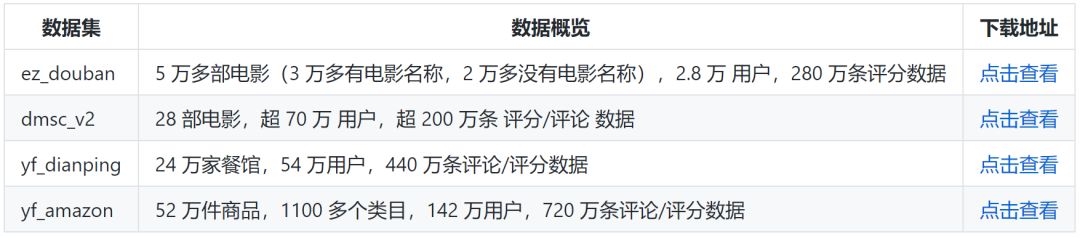
This resource organizes a large number of datasets for text classification, entity recognition & part-of-speech tagging, search matching, recommendation systems, coreference resolution, encyclopedia data, pre-trained word vectors or models, Chinese Cloze tests, and more.
The content of this article is compiled from: https://github.com/InsaneLife/ChineseNLPCorpus
Text Classification
News Classification
Today’s Headlines Chinese News (Short Text) Classification Dataset: https://github.com/fateleak/toutiao-text-classfication-dataset
Data scale: 380,000 entries, distributed across 15 categories.
Collection time: May 2018.
Split ratio: 0.7, 0.15, 0.15.
Tsinghua News Classification Corpus:
Filtered historical data from Sina News RSS subscription channels from 2005 to 2011.
Data volume: 740,000 news documents (2.19 GB)
Small data experiments can filter categories: Sports, Finance, Real Estate, Home, Education, Technology, Fashion, Politics, Games, Entertainment
http://thuctc.thunlp.org/#%E8%8E%B7%E5%8F%96%E9%93%BE%E6%8E%A5
RNN and CNN experiments: https://github.com/gaussic/text-classification-cnn-rnn
University of Science and Technology of China News Classification Corpus: http://www.nlpir.org/?action-viewnews-itemid-145
Sentiment/Opinion/Comment Polarity Analysis
Entity Recognition & Part-of-Speech Tagging
Weibo Entity Recognition
https://github.com/hltcoe/golden-horse
Boson Data
Contains 6 types of entities.
https://github.com/InsaneLife/ChineseNLPCorpus/tree/master/NER/boson
People’s Daily Dataset
Three types of entities: Person names, Place names, Organization names
1998: https://github.com/InsaneLife/ChineseNLPCorpus/tree/master/NER/renMinRiBao
2004: https://pan.baidu.com/s/1LDwQjoj7qc-HT9qwhJ3rcA password: 1fa3
MSRA Microsoft Research Asia Dataset
Over 50,000 entries of Chinese named entity recognition annotated data (including locations, organizations, and persons)
https://github.com/InsaneLife/ChineseNLPCorpus/tree/master/NER/MSRA
SIGHAN Bakeoff 2005: A total of four datasets, including Traditional Chinese and Simplified Chinese, below is the Simplified Chinese segmentation data.
MSR: http://sighan.cs.uchicago.edu/bakeoff2005/
PKU: http://sighan.cs.uchicago.edu/bakeoff2005/
Search Matching
OPPO Mobile Search Ranking
OPPO mobile search ranking query-title semantic matching dataset.
Link: https://pan.baidu.com/s/1Hg2Hubsn3GEuu4gubbHCzw Extraction code: 7p3n
Web Search Result Evaluation (SogouE)
User queries and related URL list
https://www.sogou.com/labs/resource/e.php
Recommendation Systems
Encyclopedia Data
Wikipedia
Wikipedia periodically packages and publishes its corpus:
Data processing blog
https://dumps.wikimedia.org/zhwiki/
Baidu Encyclopedia
Can only be crawled by oneself, crawl link: https://pan.baidu.com/share/init?surl=i3wvfil Extraction code: neqs.
Coreference Resolution
CoNLL 2012: http://conll.cemantix.org/2012/data.html
Pre-trained: (Word Vectors or Models)
BERT
Open source code: https://github.com/google-research/bert
Model download: BERT-Base, Chinese: Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parameters
ELMO
Open source code: https://github.com/allenai/bilm-tf
Pre-trained model: https://allennlp.org/elmo
Tencent Word Vectors
The Chinese word vector dataset publicly released by Tencent AI Lab contains over 8 million Chinese words, each corresponding to a 200-dimensional vector.
Download link: https://ai.tencent.com/ailab/nlp/embedding.html
Hundreds of Pre-trained Chinese Word Vectors
https://github.com/Embedding/Chinese-Word-Vectors
Chinese Cloze Test Dataset
https://github.com/ymcui/Chinese-RC-Dataset
Chinese Ancient Poetry Database
The most comprehensive Chinese ancient poetry dataset, nearly 14,000 poets from the Tang and Song dynasties, close to 55,000 Tang poems and 260,000 Song poems. 1,564 poets from the Song and Yuan periods, 21,050 lyrics.
https://github.com/chinese-poetry/chinese-poetry
Insurance Industry Corpus
https://github.com/Samurais/insuranceqa-corpus-zh
Chinese Character Decomposition Dictionary
English can do char embedding, and for Chinese, you might as well try character decomposition
https://github.com/kfcd/chaizi
Chinese Dataset Platforms
Sogou Lab
Sogou Lab provides some high-quality Chinese text datasets, mostly from before 2012.
https://www.sogou.com/labs/resource/list_pingce.php
University of Science and Technology of China Natural Language Processing and Information Retrieval Shared Platform
http://www.nlpir.org/?action-category-catid-28
Small Chinese Corpus
Contains small amounts of data for Chinese named entity recognition, Chinese relationship recognition, Chinese reading comprehension, etc.
https://github.com/crownpku/Small-Chinese-Corpus
Wikipedia Dataset
https://dumps.wikimedia.org/
NLP Tools
THULAC: https://github.com/thunlp/THULAC: Includes Chinese word segmentation and part-of-speech tagging functions.
HanLP: https://github.com/hankcs/HanLP
Harbin Institute of Technology LTP: https://github.com/HIT-SCIR/ltp
NLPIR: https://github.com/NLPIR-team/NLPIR
jieba Segmentation: https://github.com/yanyiwu/cppjieba
Download 1: Four Essentials
Reply "Four Essentials" in the backend of the Machine Learning Algorithms and Natural Language Processing public account to get the learning materials for TensorFlow, Pytorch, machine learning, and deep learning essentials!
Download 2: Repository Address Sharing
Reply "Code" in the backend of the Machine Learning Algorithms and Natural Language Processing public account to get 195 NAACL papers + 295 ACL2019 papers with open-source code. The open-source address is as follows: https://github.com/yizhen20133868/NLP-Conferences-Code
Heavy news! The Machine Learning Algorithms and Natural Language Processing Group has officially been established! There are many resources in the group, and everyone is welcome to join and learn!
Extra bonus resources! Qiu Xipeng's deep learning and neural networks, official Chinese tutorial for Pytorch, data analysis using Python, machine learning study notes, official Chinese version of pandas documentation, effective Java (Chinese version), and other 20 bonus resources.
How to obtain: After entering the group, click on the group announcement to receive the download link. Please modify the remarks to [School/Company + Name + Direction] when adding. For example - HIT + Zhang San + Dialogue System. The account owner, please avoid the group. Thank you!
Recommended Reading:
12 Golden Rules for Solving NER Problems in Industry
Three Steps to Master the Core of Machine Learning: Matrix Derivation
Distillation Techniques in Neural Networks, Starting with Softmax