
Follow the WeChat public account “ML_NLP“

Author | Adherer Organizer | NewBeeNLP
Interview tips knowledge compilation series, continuously updated
Full of valuable content, recommended to collect, or as usual, see you in the background (code: BT)
1. What Is the Basic Principle of BERT?
BERT comes from Google’s paper Pre-training of Deep Bidirectional Transformers for Language Understanding[1]. BERT stands for “Bidirectional Encoder Representations from Transformers” and is an autoencoder language model (Autoencoder LM). It is designed with two tasks to pre-train the model.
-
The first task trains the language model using MaskLM. In simple terms, when inputting a sentence, it randomly selects some words to predict, replacing them with a special symbol [MASK]. The model then learns what words should fill these places based on the given labels. -
The second task adds a sentence-level continuity prediction task on top of the bidirectional language model, which predicts whether the two segments of text input into BERT are consecutive. This task helps the model better learn the relationships between continuous text segments.
Final experiments show the effectiveness of the BERT model, achieving SOTA results in 11 NLP tasks.
Compared to the original RNN and LSTM, BERT can perform concurrent execution while extracting relational features of words in sentences and can extract relational features at multiple different levels, thereby more comprehensively reflecting the semantics of sentences. Compared to word2vec, it can also obtain word meanings based on the context of sentences, thus avoiding ambiguity. However, the drawbacks are also evident, with too many model parameters and a large model size, making it prone to overfitting with small training datasets.
2. How Does BERT Use Transformers?
BERT only uses the Encoder module of the Transformer. In the original paper, the authors assembled two BERT models with 12 and 24 layers of Transformer Encoders, respectively:
The number of layers (i.e., the number of Transformer Encoder blocks) is , the dimension of the hidden layers is , and the number of self-attention heads is . In all examples, we set the dimension of the feed-forward layer (the feed-forward layer on the Transformer Encoder side) to , i.e., when is , it is ; when is .
The illustration is as follows:
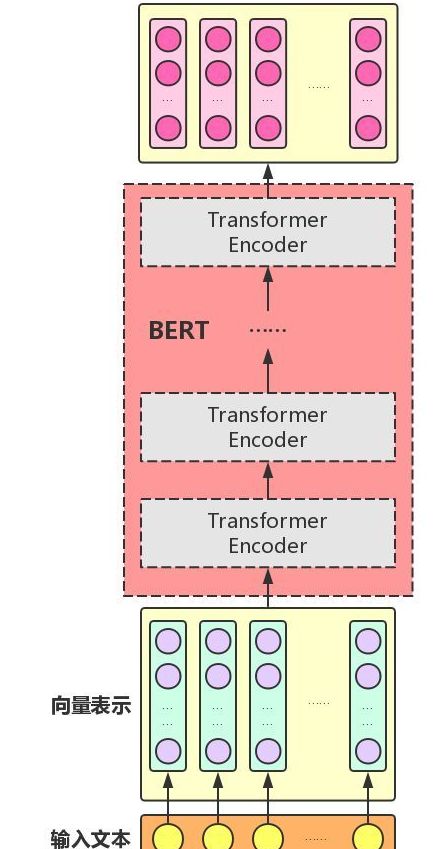
“It is important to note that compared to the Encoder side of the Transformer itself, BERT’s Transformer Encoder side input vector representation adds Segment Embeddings.”
3. What Is the Training Process of BERT?
In the original paper, the authors proposed two pre-training tasks: Masked LM and Next Sentence Prediction.
3.1 Masked LM
The task description for Masked LM is: Given a sentence, randomly erase one or several words in that sentence and predict what those erased words are based on the remaining vocabulary, as shown in the figure below.
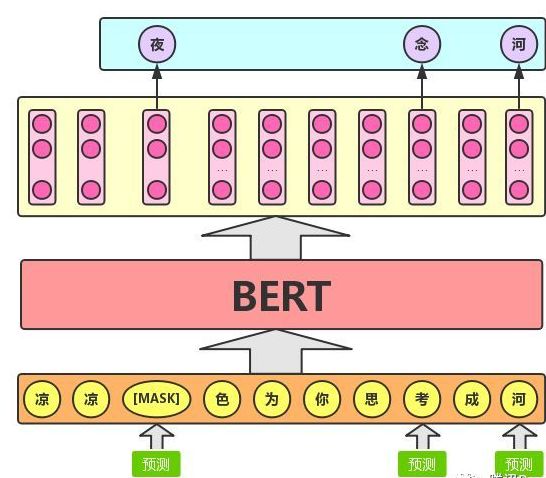
The pre-training process of the BERT model actually mimics our language learning process, inspired by the task of “fill-in-the-blank”. Specifically, the authors randomly select 15% of the vocabulary in a sentence for prediction. For the words erased in the original sentence, 80% of the time they are replaced with a special symbol [MASK], 10% of the time they are replaced with a random word, and the remaining 10% of the time they remain unchanged.
The main reason for this approach is that in subsequent fine-tuning tasks, the [MASK] token does not appear in the sentences, and another benefit is that when predicting a word, the model does not know whether the word at the input position is the correct word (10% probability), forcing the model to rely more on contextual information to predict the word and giving the model a certain degree of error correction capability. The aforementioned drawback is that only 15% of the labels in each batch of data are predicted, which means the model may require more pre-training steps to converge.
3.2 Next Sentence Prediction
The task description for Next Sentence Prediction is: Given two sentences in an article, determine whether the second sentence follows the first sentence in the text, as shown in the figure below.
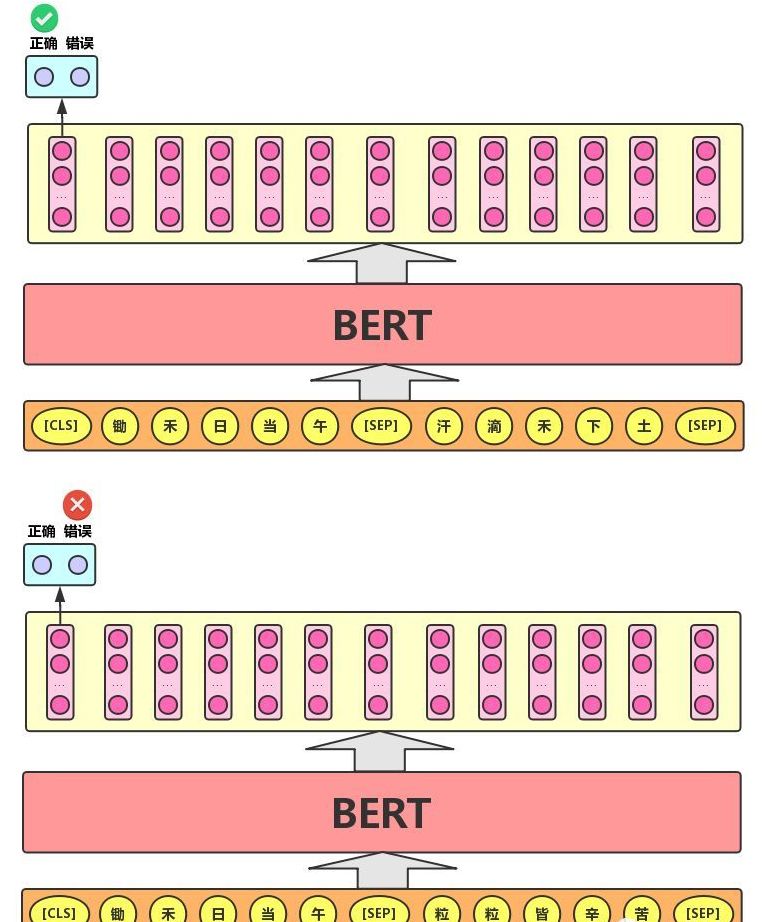
This is similar to the “paragraph reordering” task, which involves scrambling the paragraphs of an article and requiring us to restore the original text through reordering, necessitating a thorough and accurate understanding of the overall meaning of the text.
The Next Sentence Prediction task is essentially a simplified version of paragraph reordering: it only considers two sentences to determine whether they are preceding and succeeding sentences in an article. In the actual pre-training process, the authors randomly select 50% correct sentence pairs and 50% incorrect sentence pairs from the text corpus for training, combined with the Masked LM task, allowing the model to more accurately capture semantic information at the sentence and paragraph levels.
By jointly training the Masked LM task and the Next Sentence Prediction task, the BERT model ensures that the vector representations of each character/word output can comprehensively and accurately characterize the overall information of the input text (single sentence or sentence pair), providing better initial model parameters for subsequent fine-tuning tasks.
4. Why Does BERT Perform Better Than ELMo? What Are the Differences Between ELMo and BERT?
4.1 Why Does BERT Perform Better Than ELMo?
From the perspective of network structure and the final experimental results, BERT’s superior performance compared to ELMo can be attributed to the following reasons:
-
The feature extraction capability of LSTM is far weaker than that of Transformer. -
The feature fusion capability of bidirectionally concatenated features is relatively weak (this is a conjecture without specific experimental validation). -
Furthermore, BERT’s training data and model parameters are both larger than those of ELMo, which is also an important factor.
4.2 What Are the Differences Between ELMo and BERT?
The ELMo model obtains the embedding representation of words in a sentence through language model tasks, using it as additional new features for downstream tasks. Since ELMo provides the feature form of each word to downstream tasks, this type of pre-training method is referred to as “Feature-based Pre-Training.” In contrast, BERT is a “Fine-tuning based model,” which aligns with the fine-tuning approach commonly used in the image domain. Downstream tasks need to adapt the model to the BERT model to leverage the pre-trained parameters of BERT.
5. What Are the Limitations of BERT?
According to the XLNet paper, BERT has two shortcomings:
-
In the first pre-training phase, BERT assumes that multiple words in a sentence that are masked are conditionally independent, even though sometimes these words may be related. For instance, in the phrase “New York is a city,” if we mask both “New” and “York,” given “is a city,” “New” and “York” are not independent because “New York” is an entity. The probability of seeing “York” after “New” is much higher than seeing “York” after “Old.” -
However, it should be noted that this issue is not significant, and it can be argued that it does not greatly affect the final results. The pre-training corpus of BERT is massive (often tens of gigabytes), so if the training data is large enough, it compensates for the direct interdependence of masked words through other examples. -
BERT’s pre-training includes special [MASK] tokens, but these do not appear in the downstream fine-tuning, leading to inconsistency between the pre-training and fine-tuning phases. The impact of this issue on the final results is also not very clear, as many BERT-related pre-training models still maintain the [MASK] token and achieve significant results, often outperforming BERT on various datasets. However, it is indeed a compromise to introduce the [MASK] token for constructing an autoencoder language model.
Another drawback is that BERT’s masking of words after tokenization can lead to issues. To solve the OOV problem, we typically segment a word into finer-grained WordPieces. BERT randomly masks these WordPieces during pre-training, which may result in only part of a word being masked. For example:

The word “probability” may be segmented into three WordPieces: “pro”, “#babi”, and “#lity”. A possible random mask might mask “#babi” while leaving “pro” and “#lity” unmasked. This makes the prediction task easier because between “pro” and “#lity,” the only possible candidate is “#babi.” Thus, the model only needs to remember some words (the sequence of WordPieces) to complete this task rather than predicting based on the semantic relationships in the context. A similar situation can occur with the Chinese word “模型,” where parts may be masked, making prediction easier.
To address this issue, a natural idea is to either mask the entire word or not mask it at all, which is known as Whole Word Masking. This is a straightforward idea, requiring minimal modifications to BERT’s code.
“TODO: There are also other shortcomings and improvements; I will add them after reviewing related papers.”
6. What Are the Inputs and Outputs of BERT?
The main input to the BERT model is the original word vectors of the characters/words (or tokens) in the text. These vectors can be randomly initialized or pre-trained using algorithms like Word2Vector to serve as initial values. The output is the vector representation of each character/word in the text, which integrates the semantic information of the entire text, as shown in the figure below (for convenience, and to maintain consistency with the current Chinese version of the BERT model, we uniformly refer to “character vectors” as input):
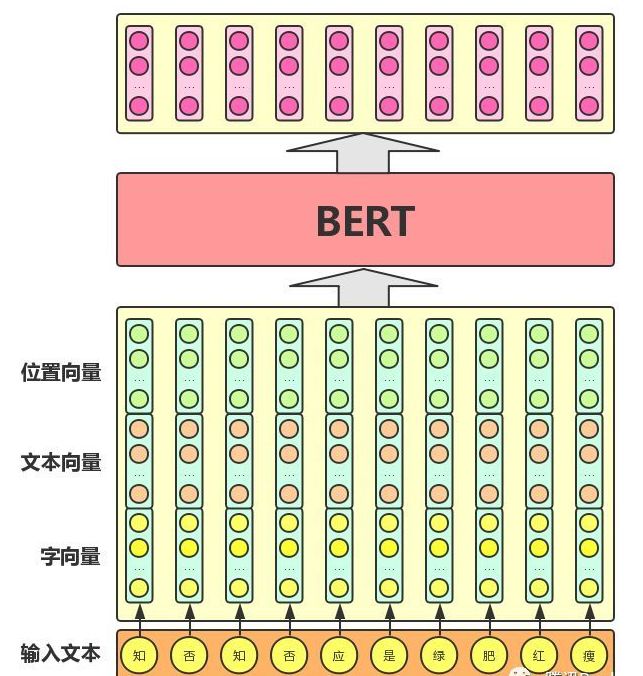
As can be seen from the figure, **the BERT model converts each character in the text into a one-dimensional vector by querying the character vector table as input to the model; the output is the vector representation of each character that integrates the semantic information of the entire text.** Additionally, the model’s input includes two other components:
-
Text vector (corresponding to Segment Embeddings): This vector’s values are learned automatically during model training to characterize the global semantic information of the text and are integrated with the semantic information of individual characters/words.
-
Position vector (corresponding to Position Embeddings): Given that characters/words at different positions in the text carry different semantic information (e.g., “I love you” and “You love me”), the BERT model assigns a different vector to each character/word at different positions for differentiation.
Finally, the BERT model sums the character vectors, text vectors, and position vectors as input to the model. Notably, in the current BERT model, the authors also further segment English vocabulary into finer-grained semantic units (WordPiece), such as splitting “playing” into “play” and “##ing”; for Chinese, the authors have not segmented the input text but directly use individual characters as the basic units of the text.
It is essential to note that the above figure only briefly introduces the representation of a single sentence input into the BERT model. In practice, when performing the Next Sentence Prediction task, a [CLS] token is added at the start of the first sentence, and [SEP] tokens are added between the two sentences and at the end of the last sentence.
7. How to Fine-tune BERT for Sentence Semantic Similarity/ Multi-label Classification/ Machine Translation/ Text Generation Tasks?
7.1 For Sentence Semantic Similarity Tasks
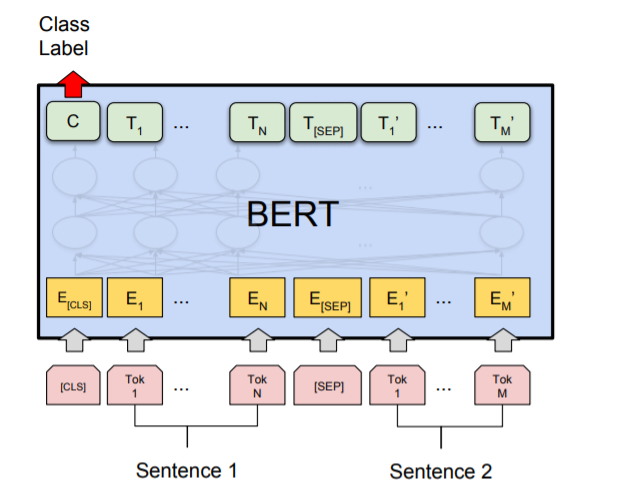
In practical operations, after the last sentence, a [SEP] token is added. The semantic similarity task inputs two sentences in the aforementioned manner and then, similar to the classification task in the paper, connects the output corresponding to the [CLS] token position to softmax for classification (in fact, many datasets for semantic similarity exist in the GLUE task).
7.2 For Multi-label Classification Tasks
The multi-label classification task, or MultiLabel, refers to a sample that may belong to multiple categories simultaneously, having multiple labels. For example, an L-sized cotton jacket may have at least two labels—size: L, type: winter clothing.
For multi-label classification tasks, a straightforward naive approach would be to train several classification models for each category, then determine which subclass it belongs to within that category. However, this method is too brute-force; multi-label classification tasks can actually be solved with “only one model.”
When using the BERT model to solve multi-label classification problems, the input is consistent with that of ordinary single-label classification problems. After obtaining its embedding representation (i.e., the embedding from the BERT output layer), several labels connect to several fully connected layers (also known as projection layers), each followed by a softmax classification layer. This way, the losses of all labels are summed together. This approach effectively shares the parameters of the feature extraction layers across n classification models, yielding a shared representation (whose dimensions can be adjusted based on the task; since it is a multi-label classification task, the dimensions can be increased somewhat), and finally performs the multi-label classification task.
7.3 For Translation Tasks
For translation tasks, I thought of a method because BERT generates embedding as a “byproduct.” Therefore, the embedding obtained from the BERT output layer can be directly utilized as the input/output embedding representation for machine translation tasks. However, this may encounter the UNK issue. To address the UNK problem, the obtained word vector embedding can be concatenated with the character vector embedding to produce the input/output representation (corresponding to English, this means concatenating token embedding with embedding processed through charcnn).
7.4 For Text Generation Tasks
Regarding generation tasks, I found the following papers:
BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model[2]
MASS: Masked Sequence to Sequence Pre-training for Language Generation[3]
Unified Language Model Pre-training for Natural Language Understanding and Generation[4]
8. Is BERT Still Effective for Data with Missing Spaces or Misspelled Words? What Are the Improvement Methods?
8.1 Is BERT Effective for Data with Missing Spaces?
Logically, it may become ineffective because if there are no spaces, it becomes a long segment of text. However, this still requires verification. How to handle data with missing spaces? One approach is to use Bi-LSTM + CRF for segmentation, process it into normal text, and then input it into BERT for downstream tasks.
8.2 Is BERT Effective for Data with Misspelled Words?
If there are a small number of misspelled words, the impact should not be significant because BERT’s pre-training corpus is very rich, and many corpora are not clean, including many cases of misspelled words. However, if the proportion of misspelled words is relatively high, such as 30% or 50%, it is necessary to use manual feature engineering methods. For example, in Chinese, different misspellings can be replaced with the same word to reduce the impact of typos, such as replacing 花被, 花珼, 花呗, 花呗, 花钡 with 花呗.
9. How Are BERT’s Embedding Vectors Obtained?
Taking Chinese as an example, “The BERT model converts each character in the text into a one-dimensional vector by querying the character vector table as input (along with position embedding and segment embedding); the output is the vector representation of each character that integrates the semantic information of the entire text.”
For the input token embedding, segment embedding, and position embedding, they are all randomly generated. It is important to note that in the Transformer paper, position embeddings are generated by fixed values from sin/cos functions, while in the code implementation here, they are randomly generated like ordinary word embeddings, making them trainable. The authors likely chose this method because BERT’s training data is much larger than that of the Transformer paper, allowing the model to learn independently.
10. Why Does BERT Use Mask? How Is It Masked? What Are the Similarities and Differences Between Its Mask and CBOW?
10.1 Why Does BERT Use Mask?
BERT randomly masks a portion of the words in input X, where one of the main tasks during the pre-training process is to predict these masked words based on the context. This is a typical Denoising Autoencoder approach, where the masked words serve as the so-called noise introduced on the input side. Pre-training methods like BERT are referred to as DAE LM. Therefore, in summary, the [MASK] token in the BERT model is a means of introducing noise.
Regarding the DAE LM pre-training model, its advantage is that it can naturally integrate into a bidirectional language model, seeing both the preceding and following context of the predicted words. However, the drawbacks are also evident, primarily the inconsistency between the pre-training phase and the fine-tuning phase due to the introduction of [MASK] tokens on the input side.
10.2 How Is It Masked?
Given a sentence, 15% of the words are randomly masked, and then BERT is tasked with predicting these masked words. As mentioned in section 10.1, introducing [MASK] tokens on the input side causes inconsistency between the pre-training and fine-tuning phases. Therefore, in the paper, the authors adopted the following measures to alleviate this issue:
If a token is among the selected 15% of tokens, it is randomly executed as follows:
-
With an 80% probability, it is replaced with [MASK], for example, my dog is hairy → my dog is [MASK]. -
With a 10% probability, it is replaced with a random word, e.g., my dog is hairy → my dog is apple. -
With a 10% probability, it remains unchanged, e.g., my dog is hairy → my dog is hairy.
The benefit of this approach is that BERT does not know which of the 15% tokens is being replaced by [MASK] (note: this means that while it does not know which token is replaced by [MASK] during input, it still knows which word to predict during output). Furthermore, any word could potentially be replaced, meaning that what it sees as “apple” might actually be the masked word. This forces the model to not overly rely on the current word when encoding and to consider its context, even correcting its context. For example, in the above case, the model encodes “apple” based on the context “my dog is,” encoding it with the semantics of “hairy” rather than that of “apple.”
10.3 What Are the Similarities and Differences Between Its Mask and CBOW?
“Similarities”: The core idea of CBOW is to predict the input word given its context, using its preceding and following context. BERT essentially does the same thing, but BERT’s method involves randomly masking 15% of the words in a sentence and having BERT predict these masked words.
“Differences”: First, in CBOW, every word becomes an input word, while this is not the case for BERT. The reason for this is that doing so would make the training data too large and the training time excessively long. Secondly, for input data, CBOW only includes the context of the word to be predicted, while BERT’s input is a “complete” sentence with [MASK] tokens replacing the predicted word. This means that BERT replaces the word to be predicted with a [MASK] token on the input side.
Moreover, after training with the CBOW model, each word’s word embedding is unique, which does not effectively handle the issue of polysemy. In contrast, BERT’s word embeddings (token embeddings) incorporate contextual information, meaning that even the same word can have different embeddings in different contexts.
In fact, while organizing this question, I have come up with a new question, described as follows:
“Why can’t the [mask] token in BERT’s input data be left empty or directly input the original data, allowing for Q K V interactions without the word to be predicted in self-attention?”
This question also needs to add some details. If the data were processed like CBOW, leaving only one “blank” for each data point, then during prediction, we could integrate the representations of all words other than the predicted word (using methods like averaging or max pooling) and then connect it to softmax for classification.
At first glance, it seems that this idea could work, and I don’t see any unreasonable aspects. However, it should be noted that this approach would require calculating a set of Q, K, V for each word predicted. Even if not calculated each time, storing the Q, K, V obtained each time would consume a lot of space. In summary, while this approach might be feasible, the actual operational difficulty would be substantial, requiring several times the computational load of pre-training the BERT model (at least), and saving intermediate states is not easy. Furthermore, if we were to implement this like CBOW, where would the innovation in the article lie?~
11. What Are the Loss Functions Corresponding to BERT’s Two Pre-training Tasks (Displayed in Formula Form)?
BERT’s loss function consists of two parts: the first part comes from the Mask-LM “word-level classification task”, and the second part is the “sentence-level classification task”. Through the joint learning of these two tasks, BERT learns representations that contain both token-level information and sentence-level semantic information. The specific loss functions are as follows:
Where is the parameter of the Encoder part in BERT, is the parameter of the output layer connected to the Encoder in the Mask-LM task, and is the classifier parameter connected to the Encoder in the sentence prediction task. Therefore, in the first part of the loss function, if the set of masked words is M, it is a multi-class problem on the size of the vocabulary |V|, specifically:
In the sentence prediction task, it is also a classification problem’s loss function:
Thus, the loss function for the joint learning of the two tasks is:
In terms of specific implementation details for pre-training, BERT utilizes a series of strategies to make the model easier to train, such as the warm-up strategy for learning rates, using GeLu as the activation function instead of the ordinary ReLu, and employing dropout and other common training techniques.
12. What Improvements Were Made from Bag-of-Words Model to Word2Vec? What Improvements Were Made from Word2Vec to BERT?
12.1 What Improvements Were Made from Bag-of-Words Model to Word2Vec?
The Bag-of-Words model represents a segment of text (like a sentence or document) using a “bag of words”. This representation does not consider grammar or the order of words. “When using the Bag-of-Words model, the document’s vector representation is simply the sum of the frequency vectors of each word.” From this description, we can identify two shortcomings of the Bag-of-Words model:
-
After vectorization, the relationship between words is weighted, meaning that the frequency of a word does not necessarily correlate with its importance. -
There is no sequential relationship between words.
In contrast, Word2Vec is a model that considers the positional relationships of words. By training on a large corpus, it maps each word to a low-dimensional dense vector, allowing the cosine similarity to determine the relationship between two words. Word2Vec primarily employs neural network models based on CBOW and Skip-Gram algorithms.
Therefore, the improvements from the Bag-of-Words model to Word2Vec focus on the following two aspects:
-
It considers the order of words and incorporates contextual information. -
It provides a more accurate representation of words, yielding richer information.
12.2 What Improvements Were Made from Word2Vec to BERT?
The improvements from Word2Vec to BERT do not have a clear-cut answer. As mentioned in the previous question, much of BERT’s concept is derived from the CBOW model. In terms of accuracy, BERT, utilizing a deeper model and massive amounts of data, yields significantly higher accuracy in downstream tasks compared to Word2Vec. This is also due to the “amplification” of the model and the “huge amplification” of the data. From a methodological significance perspective, BERT’s importance lies in providing a highly generalized pre-trained model for numerous NLP tasks, whereas using the word vectors produced by Word2Vec not only limits the tasks that can be accomplished but may also lead to subpar performance in downstream tasks when directly utilizing the word vectors from Word2Vec.
[5][6][7][8][9][10]
References
Pre-training of Deep Bidirectional Transformers for Language Understanding: https://arxiv.org/abs/1810.04805
[2]BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model: https://arxiv.org/abs/1902.04094
[3]MASS: Masked Sequence to Sequence Pre-training for Language Generation: https://arxiv.org/abs/1905.02450
[4]Unified Language Model Pre-training for Natural Language Understanding and Generation: https://arxiv.org/abs/1905.03197
[5]Detailed Explanation of BERT Model: http://fancyerii.github.io/2019/03/09/bert-theory/
[6]XLNet Principles: http://fancyerii.github.io/2019/06/30/xlnet-theory/
[7]Illustration of the BERT Model: Building BERT from Scratch: http://url.cn/5vprrTM
[8]XLNet: Operational Mechanism and Comparison with BERT: https://zhuanlan.zhihu.com/p/70257427
[9]How to Evaluate the BERT Model?: https://www.zhihu.com/question/298203515
[10][NLP] Detailed Explanation of Google BERT: https://zhuanlan.zhihu.com/p/46652512
Shared repository address:
Reply "code" in the backend of the Machine Learning Algorithms and Natural Language Processing WeChat public account to obtain 195 NAACL + 295 ACL2019 papers with open-source code. The open-source address is as follows: https://github.com/yizhen20133868/NLP-Conferences-Code
Heavy news! The Machine Learning Algorithms and Natural Language Processing group has officially been established! There are plenty of resources in the group; everyone is welcome to join and learn!
Extra benefits! Qiu Xipeng's deep learning and neural networks, official PyTorch Chinese tutorial, data analysis using Python, machine learning notes, official pandas documentation in Chinese, effective Java (Chinese version), and other 20 welfare resources.
How to obtain: After entering the group, click on the group announcement to get the download link. Please modify your remarks when adding: [School/Company + Name + Direction]. For example — HIT + Zhang San + Dialogue System. Please avoid adding if you are a micro-business. Thank you!
Recommended Reading:
Summary and Thoughts on Common Normalization Methods: BN, LN, IN, GN
LSTM That Everyone Can Understand
Comprehensive Analysis of Python "Partial Function" Usage