

Self-Supervised Learning is a popular research area in recent years. It aims to extract the inherent representation features of unlabeled data by designing auxiliary tasks as supervisory signals, thereby enhancing the model’s feature extraction capabilities.
Today, let’s explore what self-supervised learning is!


01
What is Self-Supervised Learning?
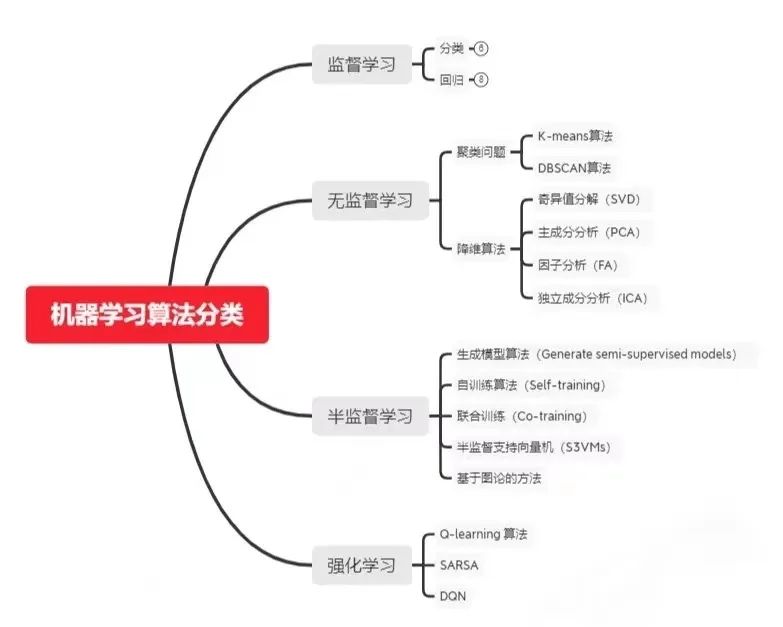

Machine learning can be classified into supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning based on the task.
Self-Supervised Learning is a type of unsupervised learning, also known as a (pretext task). It primarily utilizes auxiliary tasks (pretext) to mine self-supervised information from large-scale unlabeled data, training the network with this constructed supervisory information to learn representations valuable for downstream tasks.
The advantage of self-supervised learning is that it can be trained on unlabeled data, while supervised learning requires a large amount of labeled data, and reinforcement learning requires extensive interaction with the environment. In an era where data is king, this characteristic has led many to believe that self-supervised learning is the direction of artificial intelligence development.


02
Main Methods of Self-Supervised Learning
The main methods of self-supervision can be divided into three categories:
● Context-Based
Based on the contextual information of the data itself, we can construct many tasks, such as the important Word2vec algorithm in the NLP field. Word2vec mainly utilizes the order of sentences, for example, CBOW predicts the center word using surrounding words, while Skip-Gram predicts surrounding words using the center word.
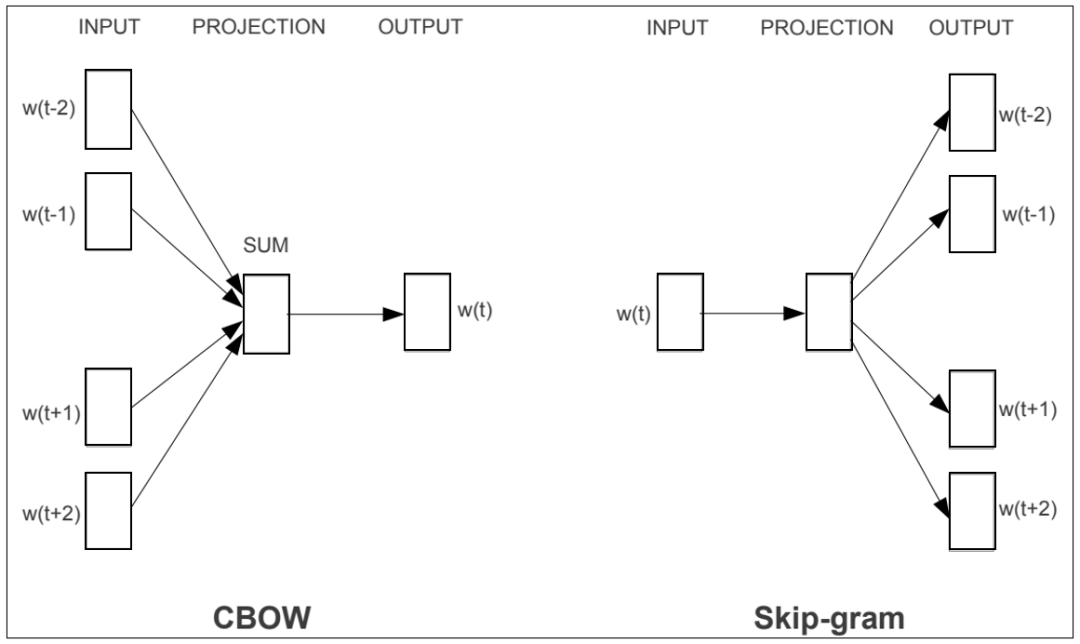
Figure 1: Two Methods of Word2vec
In the field of images, researchers construct auxiliary tasks (pretext) through a method called Jigsaw. This involves dividing an image into nine parts and then predicting the relative positions of these parts to generate loss. For example, inputting the eyes and right ear of a cat in the image and letting the model learn that the right ear is above the eyes. If the model can accomplish this task well, it can be considered that the representation learned by the model contains semantic information.
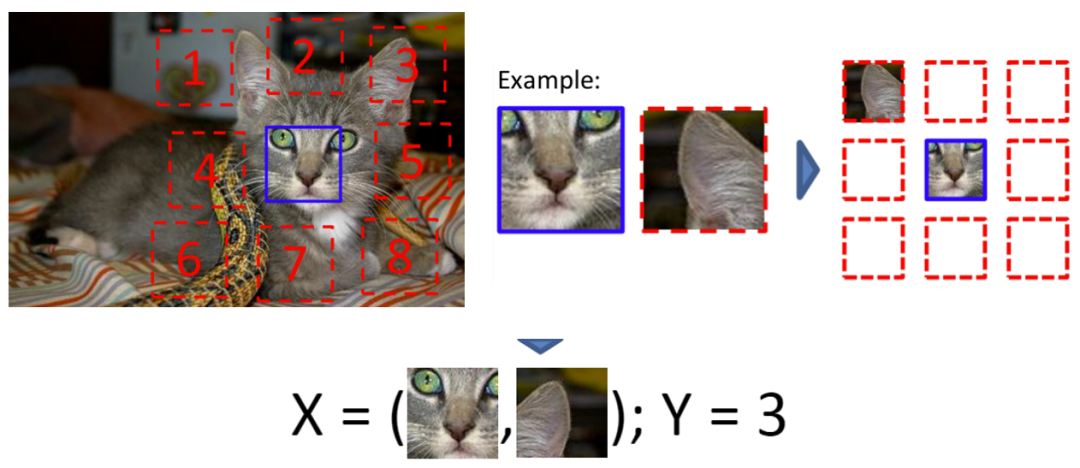
Unsupervised Visual Representation Learning Based on Context Prediction
● Temporal Based
Most of the context-based methods rely on the information of the samples themselves, while there are also many constraint relationships between samples. Therefore, we can use temporal constraints for self-supervised learning. The data type that best reflects temporal relationships is video.
In the video domain, research can be conducted based on frame similarities. Each frame in a video has the concept of feature similarity; simply put, adjacent frames in a video have similar features, while frames that are far apart have lower similarity. By constructing similar (positive) and dissimilar (negative) samples, we can impose self-supervised constraints.
● Contrastive Based
The third category of self-supervised learning methods is based on contrastive constraints, which constructs representations by learning the similarity or dissimilarity between two entities. The temporal-based methods mentioned in the second part already involve contrastive constraints, which measure the distance between positive and negative samples to achieve self-supervised learning.
Some content in this article is sourced from publicly available information.
Through self-supervised learning, we can achieve far more than with supervised learning.