
I have been following Deepseek for more than a year. At that time, the Mixtral-8x7B model had just come out, and I wrote an article analyzing its MoE architecture. Soon after, Deepseek launched their first version of the Deepseek MoE model, and their staff added me on WeChat after seeing the article;
Mixtral-8x7B Model Pit: https://zhuanlan.zhihu.com/p/674751021When doing Paiss, I regarded Deepseek MoE as a mainstream model and conducted experimental comparisons;
After Deepseek V2 was released, the cleverly designed MLA architecture caught my attention. It inspired me to write the article CLOVER. In MLA, there is an absorb operation that can absorb Key Weight into Query Weight and Value Weight into Output Weight, but the downside is that the number of parameters will increase after merging. CLOVER merges first and then decomposes, obtaining orthogonal attention heads without changing the model structure, which is greatly beneficial for pruning and fine-tuning;
With the complete explosion of Deepseek V3/R1, I also come to add fuel to the fire:
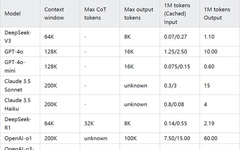
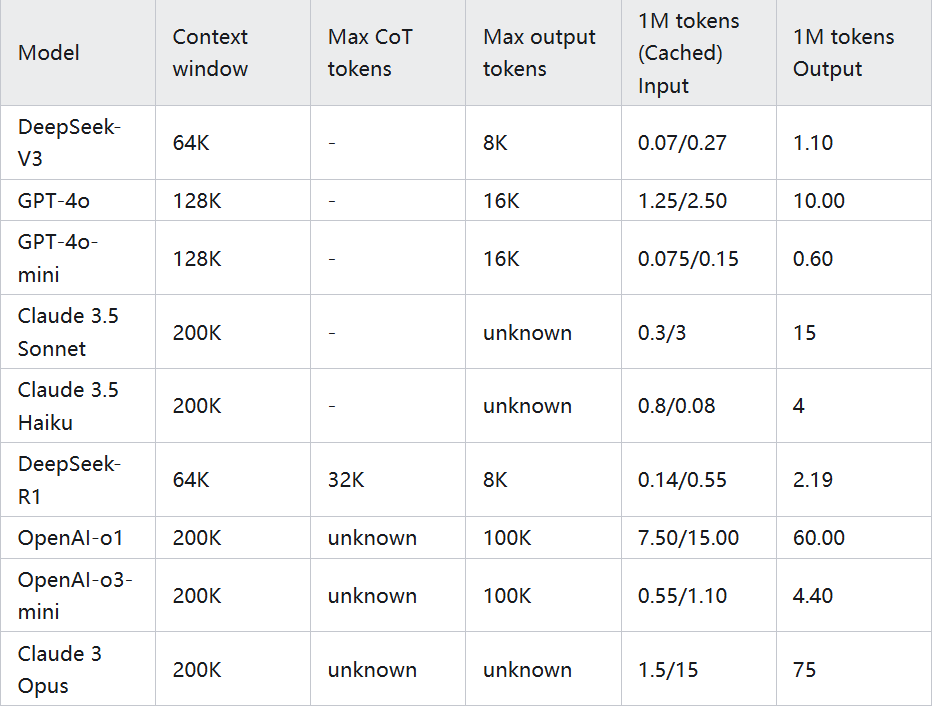
TransMLA: Multi-head Latent Attention Is All You Need
arxiv: https://arxiv.org/abs/2502.07864
github: https://github.com/fxmeng/TransMLA-
This article theoretically proves that under the same KV Cache cost, the expressive ability of MLA is always greater than that of GQA, and this advantage is verified through experiments. -
This article proposes a TransMLA method that can equivalently transform mainstream models such as LLaMA-3 and Qwen-2.5 from GQA to the more capable MLA. -
This article will use the modified model to reproduce the capabilities of R1. It will also explore technologies such as MoE, MTP structure, mixed precision quantization training, and inference acceleration, hoping to promote the transition from GQA models to MLA models, help beginners understand the technologies used by Deepseek, and provide a low-cost migration model architecture solution for large model vendors.
TransMLA Method
This section first presents the following theorem:
Theorem 1: When the KV cache size is the same, the expressive ability of MLA is greater than that of GQA.
Proof: In the following sections 1) 2) 3), we demonstrate that any GQA configuration can be converted to an MLA form with the same KV cache size. In section 4), we further prove that there exist situations where MLA cannot be represented by GQA.
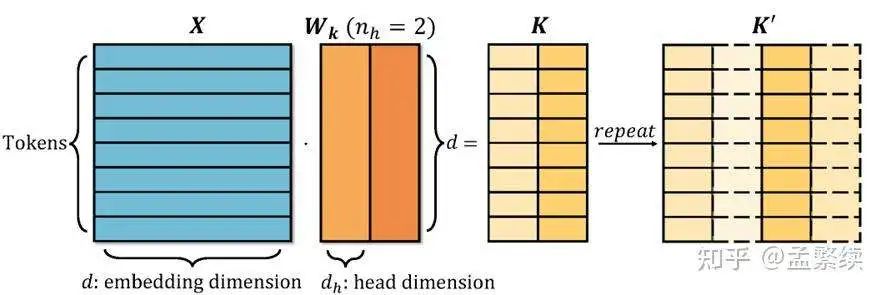
1) GQA form, copy Key-Value
The above figure shows the typical structure of Group Query Attention (GQA). In GQA, the Query is split into heads, each head having a dimension of . To reduce the number of Keys and Values, Keys are defined with heads (where ), each head having a dimension of .
Let be the input sequence with a length of and a hidden dimension of . The projection matrix for Keys is defined as . Then,
Since the standard multi-head attention requires and (and) to have the same number of heads, it must be expanded from heads to heads. Define the copy factor. Divide along its columns into blocks, each block corresponding to a head: where each block . By copying each and concatenating, we obtain the expanded matrix:
2) MHA form, move copy operation to parameter side
The above figure shows a method to replace GQA with Multi-Head Attention (MHA). Before computation, the projection matrix can be copied first. First, divide along its columns into parts, each corresponding to an original attention head in Keys:
Then, copy each and concatenate them in order to form a new projection matrix:
Apply to , directly obtaining . This method is mathematically equivalent to computing first and then copying its heads (GQA).
3) MLA form, low-rank decomposition of parameter matrices
The above figure shows that it is formed by copying, with a maximum of degrees of freedom. Thus, its rank is at most . To understand this more formally, we use singular value decomposition (SVD) to decompose : where and are orthogonal matrices, and is a diagonal matrix containing singular values. Only the first (or fewer) singular values may be non-zero. Thus, we can truncate the SVD, retaining only the first singular values, where:
Define
So
Similarly, the same method can be directly applied to the transformation of Values, which will not be discussed further here. When caching Key and Value matrices, only the low-rank representations and need to be stored. In actual attention computations, we can “expand” the representation by multiplying with and to restore the full dimension and enhance expressive ability.
4) There exist cases where MLA cannot be represented by GQA
Consider a case where the vectors in are orthogonal. In this case, multiplying by and after keeps the output different across channels for each channel. However, in GQA, the heads within each group are copied, meaning that the outputs of all heads within the group are the same. This structural difference implies that certain cases of MLA cannot be represented by GQA, as MLA allows for greater output diversity across different channels.
Based on the above analysis, we have proven Theorem 1. By transforming GQA into an equivalent MLA representation, we can enhance the model’s expressive ability. The following sections will present experimental results to verify this conclusion.
Experimental Results
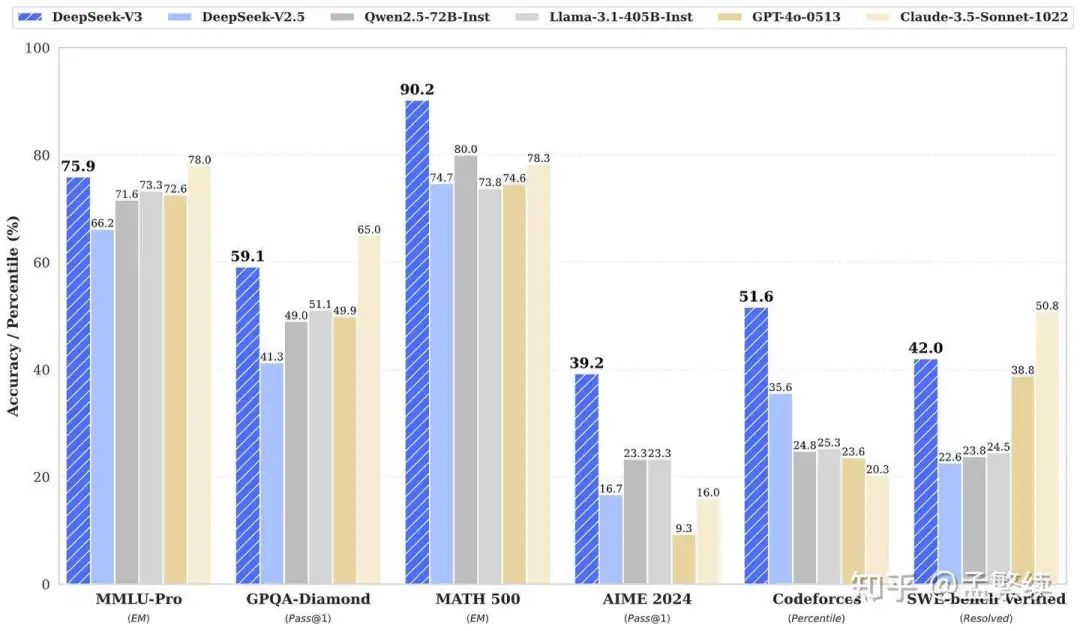
Taking Qwen2.5 as an example, we demonstrate how to convert a GQA-based model into an MLA model and compare the training effects of the model before and after conversion in downstream tasks. Each layer of the Qwen2.5-7B model contains 28 Query heads and 4 Key/Value heads, each head having a dimension of 128, and the KV Cache dimension being 1024. Each layer of the Qwen2.5-14B model contains 40 Query heads and 8 Key/Value heads, each head having a dimension of 128, and the KV Cache dimension being 2048. After converting the Qwen2.5-7B model to the MLA model, the output dimensions of and were both adjusted to 512, while the KV Cache dimension remained 1024. Unlike the GQA model setup, in TransMLA, and are elevated from 512-dimensional features to dimensions. Since 28 Query heads can interact with 28 Queries respectively, forming different functional representations, this adjustment significantly enhances the model’s expressive ability. In this way, TransMLA can improve the expressive ability of GQA models without increasing the number of KV Caches. It is worth noting that the increase in the number of parameters is very small. Specifically, for the Q-K pair, an additional matrix of is added, while the original matrix has a dimension of , so the additional parameter amount only accounts for 1/8 of the original matrix. For the V-O pair, the additional parameter amount is also 1/8 of the original parameter amount. Overall, the model’s parameter amount slightly increased from 7.6B to 7.7B, with a very small increase.
To evaluate the performance improvement of the converted MLA model, we trained the original GQA-based Qwen model and the converted TransMLA model on a new instruction fine-tuning dataset called SmolTalk. The SmolTalk dataset contains rich instruction fine-tuning data, as well as data for mathematical tasks such as MetaMathQA and coding tasks such as Self-OSS-Starcoder2-Instruct. During training, we used the torchtune framework, set the batch size to 16, the learning rate to 2e-5, and trained for 2 epochs. During the training process, to minimize the impact on the original model, we only trained the Key-Value layers in the model. For the GQA model, we only trained and ; while for the converted MLA model, we trained the four weight matrices , , , and . The training loss and the model’s performance on the test set are shown in the figure below.
As can be seen from the figure, the converted MLA model shows lower Loss values during training, indicating its stronger fitting ability to the training data. Under the settings of 7B and 14B models, the TransMLA model significantly outperforms the original GQA-based model in accuracy on mathematical and coding tasks. This indicates that TransMLA not only enhances the model’s expressive ability but also brings significant performance improvements in specific tasks.
This performance improvement is not solely due to the increase in trainable parameters in the Key-Value, as the use of orthogonal decomposition also plays a crucial role. To further verify this, we conducted a comparative experiment. In this experiment, we did not use the orthogonal decomposition method but instead initialized the dimensionality increase module using an Identity Map to achieve TransMLA. The resulting model achieved an accuracy of 82.11% on the GSM8K dataset, which is only 0.15% higher than the GQA-based model (81.96%). This result indicates that merely increasing the trainable parameters cannot explain the significant performance improvement of TransMLA; the orthogonal decomposition method plays a key role in enhancing model performance. More experiments are currently underway to further explore the reasons behind this phenomenon and to further verify the contribution of orthogonal decomposition to model performance.
Conclusion
This article proves that GQA models can all be transformed into MLA forms, providing large model vendors with a reason to abandon GQA and embrace MLA, as well as a quick transition method. However, due to the limitations of the original model structure, the structure of TransMLA is not optimal; for example, it does not compress the Query, does not use Decoupled RoPE, and uses independent latent Vectors for Key and Value. If training a model from scratch, it is still recommended to innovate on the structure of Deepseek V3. TransMLA can enhance the effects of the current R1 distillation Qwen and distillation LLaMA projects. In the future, we will carry out this work and open-source training code and models.

Scan the QR code to add the assistant WeChat
About Us
