

Author | Yu Xuan Su
Source | Zhihu
Address | https://zhuanlan.zhihu.com/p/434672623
This article is for academic sharing only; if there is any infringement, please contact us to delete it.
1. CLINE: Contrastive Learning with Semantic Negative Examples for Natural Language Understanding
Construct positive and negative examples using synonyms/antonyms, three losses: ① MLM; ② Predict whether each token is replaced, binary classification 0/1; ③ Contrastive loss, pulling positive examples closer, pushing negative examples away.
2. Self-Guided Contrastive Learning for BERT Sentence Representations
Two BERTs construct positive and negative examples: ① A BERT without optimized parameters performs max pooling on all layers of the transformer hidden layers, transforming (batch,len,768) to (batch,1,768), then taking the mean as the output representation of the sentence; ② An optimized BERT directly uses the last layer [CLS] as the sentence representation; representations from ① and ② of the same sentence form positive examples, while representations from different sentences form negative examples.
3. ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer
Four types of data augmentation to construct positive examples: ① Randomly add some noise to token_embedding; ② Index transformation of token_embedding; ③ Randomly deactivate some tokens in token_embedding (setting entire rows to zero); ④ Random deactivation of the entire token_embedding.
4. DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations
Two sentences from the same article are positive examples, while two sentences from different articles are negative examples.
5. Contrastive Instance Learning Framework for Distantly Supervised Relation Extraction
Sentences of the same category are placed in a word bag, and some unimportant words are chosen from this category’s word bag to insert/replace in the sentence as positive examples, while all other category word bags serve as negative examples for this sentence.
6. SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization
The first stage directly generates documents, the second stage uses contrastive learning: pulling all generated documents closer to the original text, and hoping that the loss in the second stage allows all candidate documents to be sorted according to the scores from the first stage;
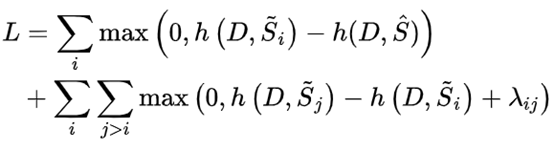
D is the original document, s_hat is the label, h is the scoring function. The specific operation is to calculate the similarity between the label and the generated document’s [cls], where si···sj are generated documents, sorted in descending order of scores, so sj’s score must be less than si’s. By minimizing the loss above, the ranking from i to j must be from large to small, hoping the model can rank candidate documents without reference documents.
7. Modeling Discriminative Representations for Out-of-Domain Detection with Supervised Contrastive Learning
Two losses: ① Cross-entropy loss for predicting sentence categories; ② Contrastive learning loss – positive examples come from the same category data, negative examples come from different categories.
8. Contrastive Learning for Many-to-many Multilingual Neural Machine Translation
Although the same sentence translated into different languages represents different expressions, in human cognition, the actual semantics should be similar – using multilingual examples to construct positive and negative examples.
Supplementary Knowledge:
SimCSE: Essentially, (self, self) serves as positive examples, while (self, others) serves as negative examples to train the contrastive learning model; (the same sentence goes through the encoder twice, with outputs from two different random dropouts serving as positive examples)
Loss function:

Where:
① Since it is unsupervised, y_true is None for input, and the y_true in the code block below is artificially constructed in ③;
② In each batch, each sentence is repeated once. Sentences a, b, c. Compiling into a batch results in: [a, a, b, b, c, c];
③ If idxs_1 is [[0,1,2,3,4,5]], then idxs_2 is [[1],[0],[3],[2],[5],[4]], the artificially constructed y_true is:

y_pred = K.l2_normalize(y_pred, axis=1
# L2 regularization to reduce the impact of singular values
similarities = K.dot(y_pred, K.transpose(y_pred))
# Similarity of each sentence in the batch with other sentences
similarities = similarities - tf.eye(K.shape(y_pred)[0]) * 1e12
# Set the similarity of itself to zero
similarities = similarities * 20
# Simply scale all similarities by 20 to expand the loss range
loss = K.categorical_crossentropy(y_true, similarities, from_logits=True)
# Optimization target, a typical six-class problem
In supervised SimCSE, positive examples are (positive sample dropped twice), while negative examples include: ① (positive sample dropped, other positive samples dropped) ② (positive sample dropped, negative samples dropped)
R-Drop: Using KL divergence to calculate the two drop values, expecting the results of different drop outputs to tend toward complete consistency. KL divergence can be viewed at: http://www.sniper97.cn/index.php/note/deep-learning/note-deep-learning/3886/
Technical Group Invitation

Scan the QR code to add the assistant on WeChat