
Source: Multimodal Machine Learning and Large Models
This article is approximately 1800 words long and is recommended for a 10-minute read.
This article introduces the evaluation of DeCUR in three common multimodal scenarios (Radar Optical, RGB Elevation, and RGB Depth) and demonstrates its continuous improvement, regardless of architecture, as well as in multimodal and modality-missing settings.
Decoupling Common and Unique Representations for Multimodal Self-supervised LearningAuthors: Yi Wang, Conrad M Albrecht, Nassim Ait Ali Braham, Chenying Liu, Zhitong Xiong, and Xiao Xiang ZhuAffiliations:Technical University of Munich, German Aerospace Center Remote Sensing Technology Institute, Munich Machine Learning Center
Paper link:
https://arxiv.org/pdf/2309.05300
Code link:
https://github.com/zhu-xlab/DeCUR
Introduction
Most existing multimodal self-supervised methods only learn common representations across modalities, neglecting intra-modal training and modality-specific representations. This paper proposes a simple yet effective multimodal self-supervised learning method, called Decoupling Common and Unique Representations (DeCUR). By reducing multimodal redundancy to distinguish inter-modal and intra-modal embeddings, DeCUR can integrate complementary information between different modalities. The paper evaluates DeCUR in three common multimodal scenarios (Radar Optical, RGB Elevation, and RGB Depth) and demonstrates its continuous improvement, regardless of architecture, as well as in multimodal and modality-missing settings.
Research Motivation
Feature embedding dimensions can be divided into common dimensions across modalities and unique dimensions specific to each modality. During training, the normalized cross-correlation matrix of the common and unique dimensions between the two modalities is computed, driving the common dimension matrix to identity while driving the unique dimension matrix to zero. Therefore, common embeddings remain consistent across different modalities, while modality-specific embeddings are excluded.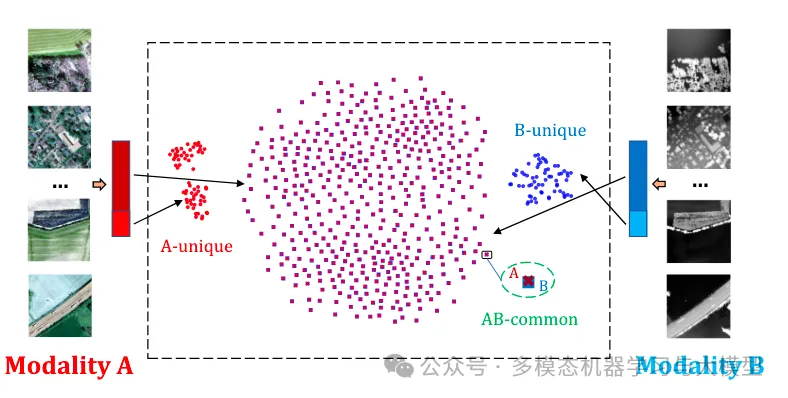 Figure 1: t-SNE visualization of decoupled common and unique representations for two modalities.However, simply pushing away the unique dimensions would lead to collapse, as these dimensions cannot learn any useful information. Therefore, in addition to inter-modal learning, the paper also includes intra-modal learning, utilizing all embedding dimensions and driving the cross-correlation matrix between two augmented views of the same modality to be consistent. This intra-modal component not only avoids collapse by allowing unique dimensions to learn meaningful representations within a modality but also enhances inter-modal learning through stronger intra-modal knowledge. Figure 1 provides a t-SNE visualization of the potential space of learned representations, where the common and unique embeddings of each modality, as well as the modality-specific unique embeddings between modalities, are well separated.
Figure 1: t-SNE visualization of decoupled common and unique representations for two modalities.However, simply pushing away the unique dimensions would lead to collapse, as these dimensions cannot learn any useful information. Therefore, in addition to inter-modal learning, the paper also includes intra-modal learning, utilizing all embedding dimensions and driving the cross-correlation matrix between two augmented views of the same modality to be consistent. This intra-modal component not only avoids collapse by allowing unique dimensions to learn meaningful representations within a modality but also enhances inter-modal learning through stronger intra-modal knowledge. Figure 1 provides a t-SNE visualization of the potential space of learned representations, where the common and unique embeddings of each modality, as well as the modality-specific unique embeddings between modalities, are well separated.
Contributions of the Paper
- Proposed a simple and effective multimodal self-supervised learning method, DeCUR, which decouples common and unique representations between different modalities and enhances both intra-modal and inter-modal learning. A simple adjustment with deformable attention is used for feature learning of modality information in the ConvNet backbone.
- Evaluated DeCUR through extensive experiments and comprehensive analysis covering three important multimodal scenarios, demonstrating its effectiveness in multimodal and modality-missing environments.
Method
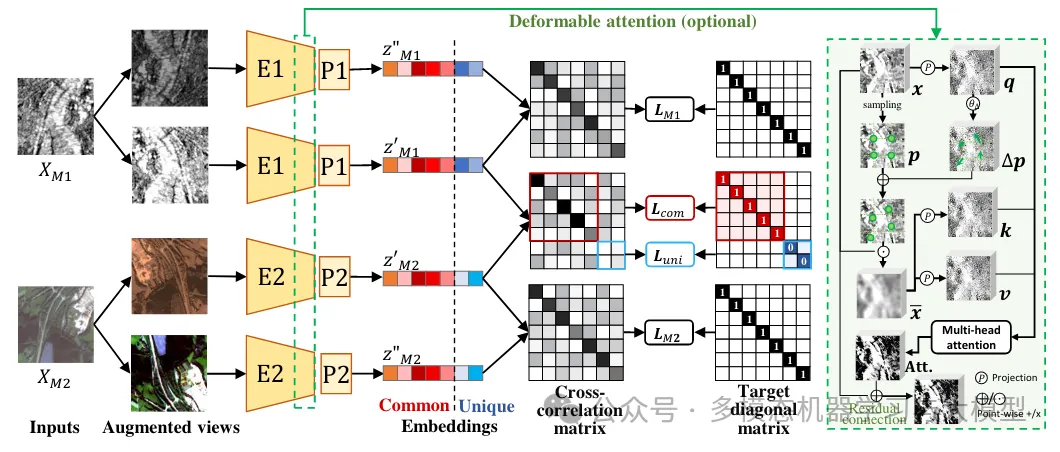 Figure 2: The structure of DeCUR. M1 and M2 represent two modalities. Two augmented views from each modality are fed into modality-specific encoders (E1, E2) and projectors (P1, P2) to obtain embeddings Z.
Figure 2: The structure of DeCUR. M1 and M2 represent two modalities. Two augmented views from each modality are fed into modality-specific encoders (E1, E2) and projectors (P1, P2) to obtain embeddings Z.
Figure 2 illustrates the overall structure of DeCUR. As a multimodal extension of Barlow Twins, DeCUR performs self-supervised learning by reducing redundancy in the joint embedding space of augmented views from an intra-modal/cross-modal perspective. The main contribution of this paper lies in the simple loss design that decouples meaningful modality-specific unique representations across modalities.
Decoupling Common and Unique Representations
As shown in Figure 2, two batches of augmented views from the input of each modality are input into modality-specific encoders and projections. Batch normalization is applied to the embeddings, centering them along the batch dimension. These embeddings are then used to compute the cross-correlation matrix between modalities/intra-modal for optimization.Cross-Correlation Matrix Given two embedding vectors, their cross-correlation matrix C is represented as:
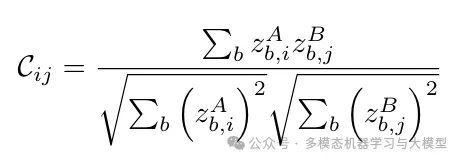
Decoupling Cross-Modal Representations In the cross-modal case, the correlation matrix C between two embeddings from different modalities is calculated, as shown in Figure 2. While most multimodal self-supervised learning algorithms only consider their common representations, this paper explicitly considers the existence of modality-specific unique representations and decouples them during training. Specifically, the total embedding dimension K is divided into and , where stores the common and unique representations, respectively. The cross-modal common representation should be the same (the red part in Figure 2), while the modality-specific unique representation should be decorrelated (the blue part in Figure 2). The loss for reducing redundancy in the cross-modal common representations is as follows:
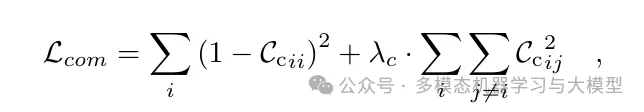
The loss for reducing redundancy in modality-specific unique representations is as follows:
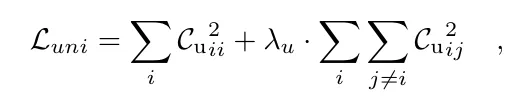
Enhancing Intra-Modal Representations To avoid the collapse of unique dimensions decoupled during cross-modal training and to enhance intra-modal representations, this paper introduces intra-modal training that covers all embedding dimensions. For each modality, the cross-correlation matrix (or )
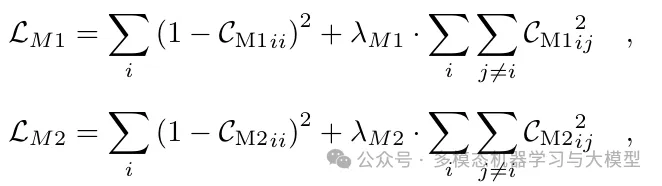
Combining the cross-modal common and unique loss with intra-modal loss, the overall training objective of DeCUR is:
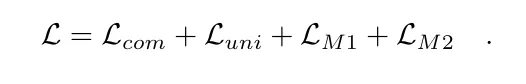
Deformable Attention for Modality Information Feature
In addition to the DeCUR loss design, this paper also adopts deformable attention to help the ConvNet model focus on regions of modality information. Deformable attention modules were proposed in DAT and DAT++ to effectively model relationships between feature tokens under the guidance of important areas in the feature map. For specifics, please refer to the original text.
Experimental Results
Table 2: Comprehensive fine-tuning results of RGB-DEM transfer learning (mIoU) on GeoNRW with a frozen encoder (left: multimodal; right: RGB only).
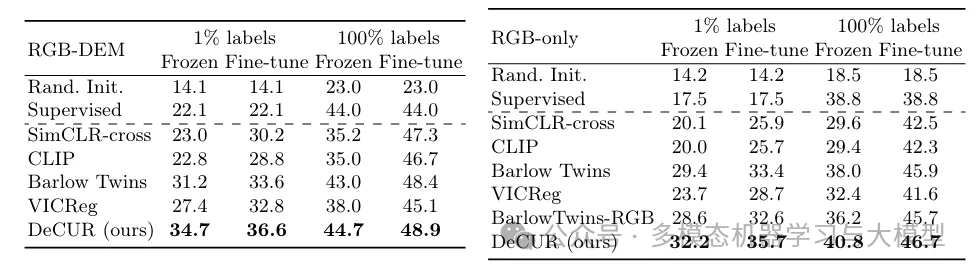 Table 3: RGB Depth fine-tuning results on SUN-RGBD and NYU-Depth v2.
Table 3: RGB Depth fine-tuning results on SUN-RGBD and NYU-Depth v2.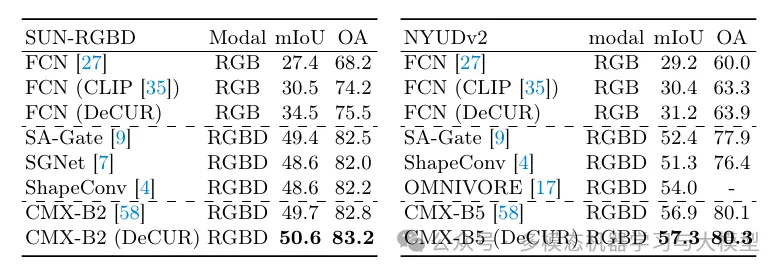
Table 4: Ablation results of the deformable attention module (mAP).
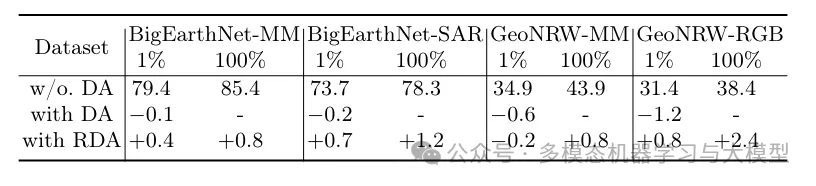
Editor: Wang Jing
About Us
Data Hub THU, as a WeChat public account focused on data science, is backed by Tsinghua University’s Big Data Research Center, sharing cutting-edge data science and big data technology innovation research dynamics, continuously disseminating data science knowledge, and striving to build a data talent gathering platform, creating China’s strongest group in big data.

Weibo: @Data Hub THU
WeChat Video Account: Data Hub THU
Today’s Headline: Data Hub THU