In 2024, significant progress has been made in the field of “multimodal + reinforcement learning”. Researchers have proposed various innovative methods to integrate data from different modalities to enhance the performance and applicability of reinforcement learning algorithms. For example, methods mentioned in the literature include utilizing Masked Multimodal Learning to achieve the fusion of visual and tactile information, as well as introducing the hierarchical representation model MUSE to address task execution issues under incomplete perception conditions. Additionally, some studies have explored how to effectively use multimodal data in financial trading strategy optimization and robotic control. These results indicate that multimodal technology is bringing new possibilities to reinforcement learning.
The PDF of this article has been compiled,scan the code to add Teacher Xiao Chen,reply “multimodal + reinforcement learning” to get all papers and the latest innovations for free.

Forward the article to your friends circle and take a screenshot to send to Teacher Xiao Chen, and there are more documents PDF and practical codes waiting for you! M2CURL: Sample-Efficient Multimodal Reinforcement Learning via Self-Supervised Representation Learning for Robotic Manipulation
M2CURL: Sample-Efficient Multimodal Reinforcement Learning via Self-Supervised Representation Learning for Robotic Manipulation
Innovations:
-
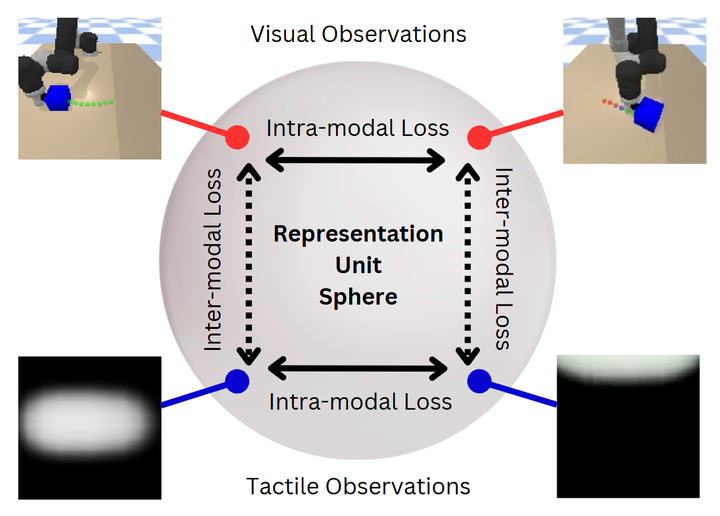
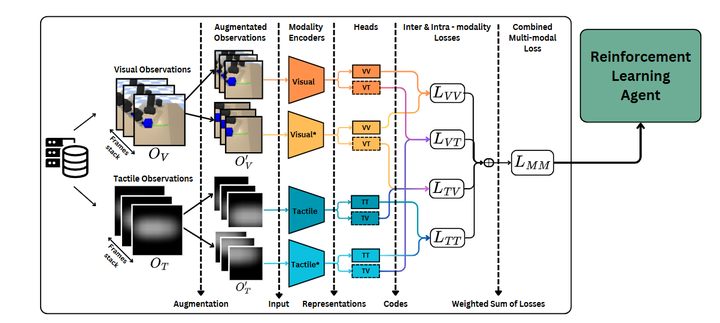
Multimodal Contrastive Self-Supervised Learning: A novel multimodal contrastive unsupervised reinforcement learning method is proposed, which efficiently learns representations in multimodal data through self-supervised learning techniques. This method can extract meaningful feature representations from high-dimensional data, improving the model’s sample efficiency and robustness.
-
Intra- and Inter-Modality Contrastive Loss: Four types of contrastive losses are introduced during the learning process, including intra-modality loss and inter-modality loss, to optimize the learning of multimodal representations. This loss design helps the model better capture correlations between different modalities.
Future Innovation Directions and Specific Models:
-
Expanding to More Tasks and Environments: Apply M2CURL to a wider variety of robotic manipulation tasks, such as grasping, assembling, and disassembling, to validate its generalization capability across different tasks. Moreover, M2CURL can be tested on real-world physical robotic systems to evaluate its performance and adaptability in practical applications.
-
Improving Representation Learning Methods: Explore more complex contrastive loss functions, such as introducing temporal consistency loss, to further enhance the quality of representation learning. Additionally, combine M2CURL with other multi-task learning methods to improve the model’s performance across multiple tasks.
Multimodal Information Bottleneck for Deep Reinforcement Learning with Multiple Sensors
Innovations:
-
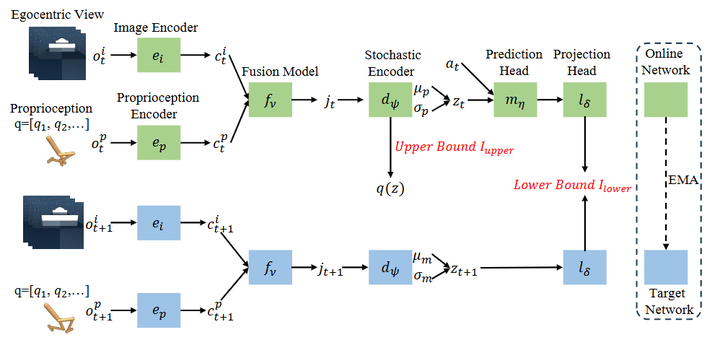
Multimodal Information Bottleneck Model: A new multimodal information bottleneck model is proposed to extract task-relevant joint representations from self-centered images and proprioceptive sensations. This model improves the sample efficiency and performance of reinforcement learning algorithms by compressing irrelevant information and retaining useful information.
-
Information Compression and Retention Mechanism: By minimizing the mutual information between the joint representation and the original multimodal observation, and maximizing the predictive information between consecutive time steps, information compression and retention are achieved. This helps the model better filter out irrelevant information related to the task.
Future Innovation Directions and Specific Models:
-
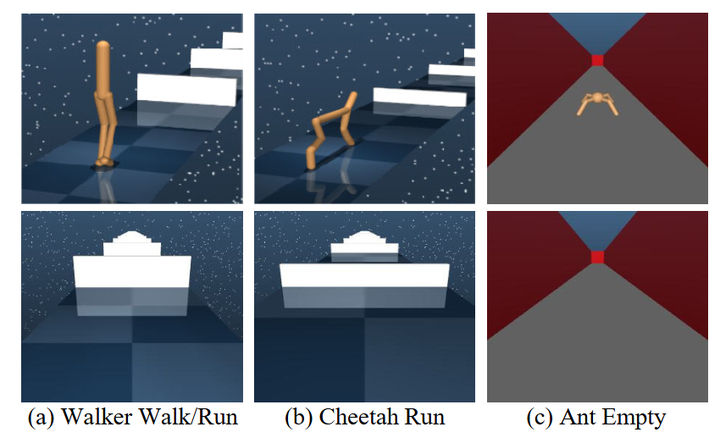
Expanding to More Types of Sensors: Current research mainly focuses on the fusion of visual and proprioceptive sensations. Future explorations can investigate how to incorporate more types of sensors into the multimodal information bottleneck model, further enhancing the robot’s perception and control capabilities in complex environments.
-
Improving Information Compression and Retention Mechanisms: Although current methods can effectively compress task-irrelevant information, there is still room for improvement. For instance, more advanced attention mechanisms or adaptive compression strategies could be introduced to dynamically adjust the level of information compression.
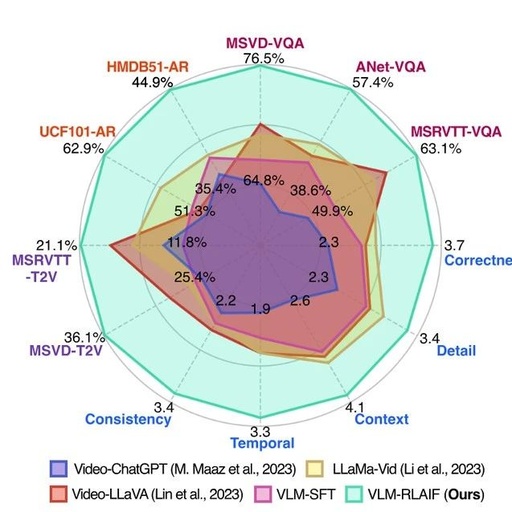
Tuning Large Multimodal Models for Videos using Reinforcement Learning from AI Feedback
Innovations:
-
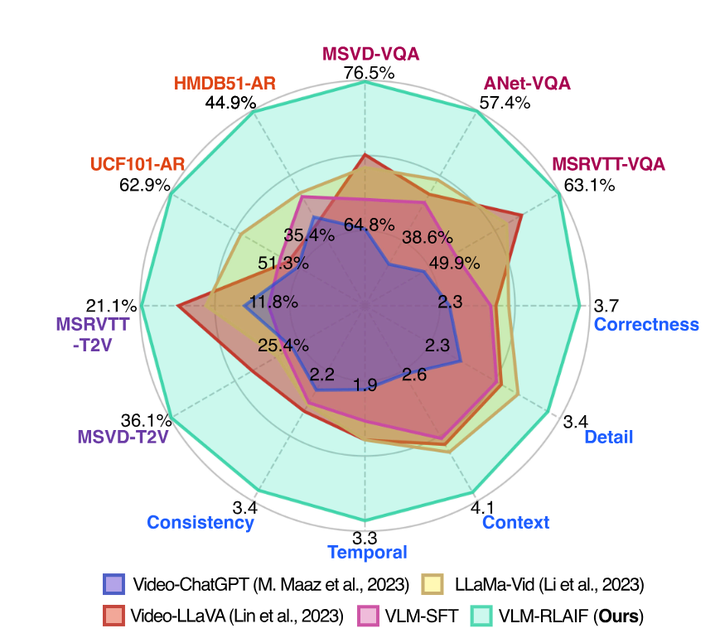
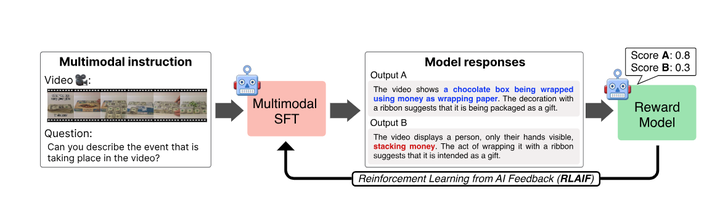
AI Feedback-Based Reinforcement Learning: A novel alignment strategy is proposed, allowing multimodal AI systems to self-supervise and provide self-preference feedback to optimize the alignment between video and text modalities. This approach reduces dependence on manually labeled data, enhancing the model’s automated learning capability.
-
Context-Aware Reward Modeling: Detailed video descriptions are introduced as contextual information for modeling context-aware rewards when generating preference feedback. This innovation enhances the model’s understanding of video content and alignment accuracy.
Future Innovation Directions and Specific Models:
-
Expanding Multimodal Datasets: Build larger-scale, higher-quality video-text alignment datasets to improve the model’s generalization capability and accuracy. Incorporate additional modalities, such as audio and 3D point clouds, to further enrich the multimodal model’s capabilities.
-
Optimizing Reinforcement Learning Algorithms: Investigate more complex reward function designs, combining more contextual information to enhance the quality of model-generated responses. Introduce adaptive learning rate strategies to allow the model to automatically adjust the learning rate based on task difficulty, improving training efficiency and effectiveness.