Click on the above“Beginner’s Guide to Vision” to choose to add to favorites or pin.
Essential content delivered promptly
The Transformer network architecture, as an exceptional neural network learner, has achieved great success in various machine learning problems. With the booming development of multimodal applications and multimodal big data in recent years, multimodal learning based on Transformer networks has become one of the cutting-edge hotspots in the field of artificial intelligence.
Today, I would like to introduce a survey paper on multimodal learning based on Transformer titled “Multimodal Learning with Transformers: A Survey”, which has been accepted by IEEE TPAMI.

Paper link:
https://arxiv.org/abs/2206.06488
https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=10123038
This survey paper summarizes over three hundred representative papers and outlines the development of Transformer-related technologies aimed at multimodal tasks. The main content includes:
(1) An introduction to multimodal learning, the Transformer ecosystem, and the background of the multimodal big data era;
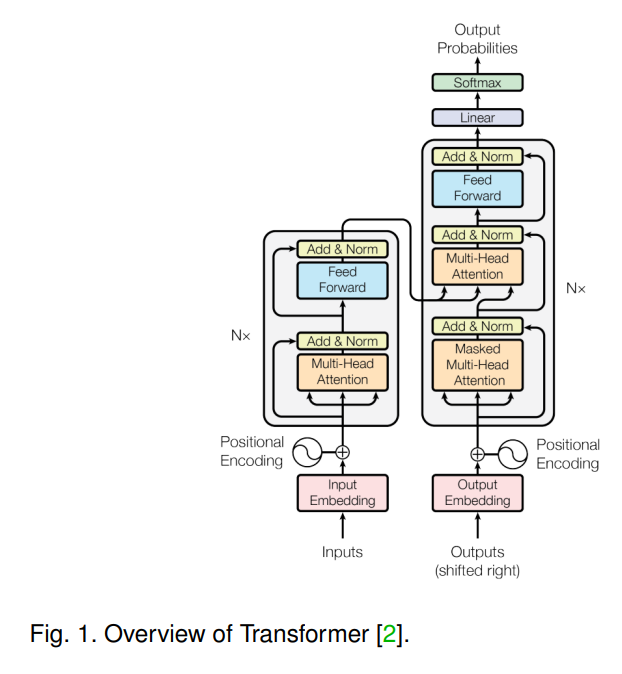
(2) A systematic review and summary of Transformer, visual Transformer, and multimodal Transformer from the perspective of geometric topology;
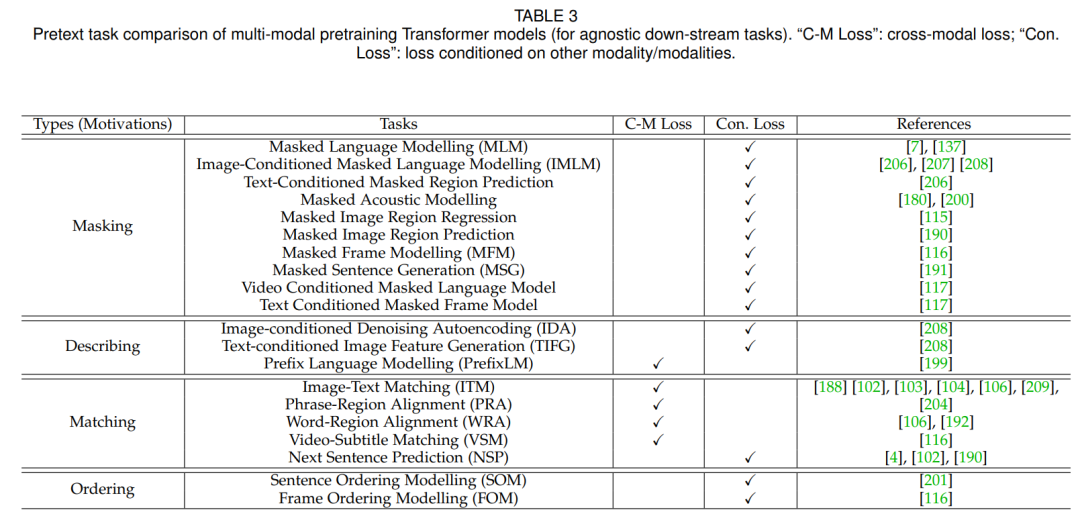
(3) A summary of the applications and research of multimodal Transformers from the two dimensions of multimodal pre-training and specific multimodal tasks;
(4) A comparison and summary of some common technical challenges and design ideas in multimodal Transformer models and applications;
(5) A discussion of some open questions and potential research directions within the research community.
The main points and features of the paper include:
(1) One of the main points of this survey is that it emphasizes one of the theoretical advantages of Transformers is their ability to operate in a modality-agnostic manner, thus being compatible with various modalities and their combinations. To support this point, the paper elaborates on how to understand the signal processing processes of Transformers in a multimodal context from a geometric topology perspective. It suggests viewing the self-attention mechanism as a type of graphical modeling, which models the input sequences (both unimodal and multimodal) as a fully connected graph without prior knowledge, where the self-attention mechanism models the embedding vectors of tokens from any modality as nodes on the graph.
(2) The paper discusses the key components of Transformers in a multimodal context as formally as possible.
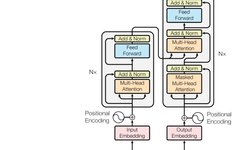
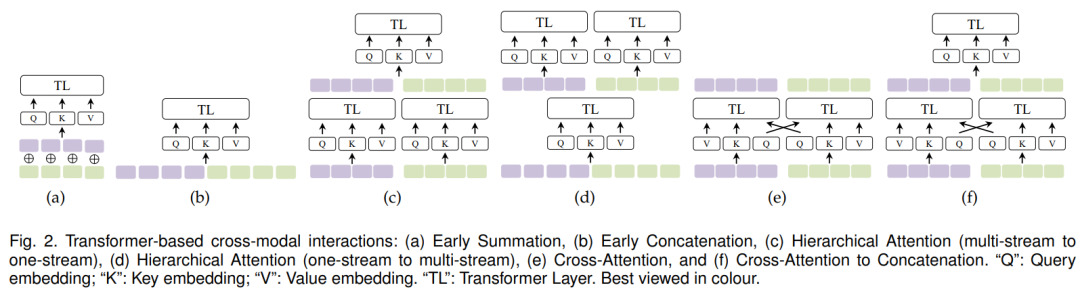
(3) It emphasizes that in multimodal models based on Transformers, cross-modal interactions (e.g., fusion, alignment) are essentially perceived and processed by the self-attention mechanism and its variants. Therefore, from the perspective of self-attention design and evolution, it summarizes the formal expressions in the practice of multimodal learning based on Transformers, categorizing the common multimodal interaction processes based on Transformers into six types of self-attention operations.
(4) In addition to the summarized content, the paper also intersperses many specialized commentary and discussion sections, such as discussing the post-normalization and pre-normalization in the Transformer structure from a mathematical perspective, and understanding and discussing the position embedding in the Transformer structure.
 For more survey papers, please follow: https://github.com/52CV/CV-Surveys
For more survey papers, please follow: https://github.com/52CV/CV-Surveys
Download 1: OpenCV-Contrib Extension Module Chinese Tutorial
Reply: Extension Module Chinese Tutorial in the backend of the “Beginner's Guide to Vision” public account to download the first Chinese version of the OpenCV extension module tutorial online, covering over twenty chapters including extension module installation, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, etc.
Download 2: Python Vision Practical Project 52 Lectures
Reply: Python Vision Practical Project in the backend of the “Beginner's Guide to Vision” public account to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, adding eyeliner, license plate recognition, character recognition, emotion detection, text content extraction, facial recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply: OpenCV Practical Project 20 Lectures in the backend of the “Beginner's Guide to Vision” public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Group Chat
Welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will be gradually subdivided in the future). Please scan the WeChat number below to join the group, and note: “Nickname + School/Company + Research Direction”, for example: “Zhang San + Shanghai Jiao Tong University + Vision SLAM”. Please follow the format, otherwise, you will not be approved. After successful addition, you will be invited to join relevant WeChat groups based on research direction. Please do not send advertisements in the group, otherwise, you will be removed from the group. Thank you for understanding~