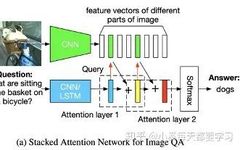
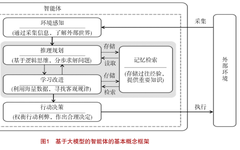
Overview of Multimodal Learning and Latest Directions
This article summarizes the main content from the TPAMI review literature, and the author adds the latest papers and analyses related to this field. Paper: Multimodal Machine Learning: A Survey and Taxonomy Humans interact with the world through various sensory organs, such as eyes, ears, and touch. Multimodal Machine Learning (MML) studies machine learning problems … Read more