

This article is about 14,500 words, and it is recommended to read for more than 15 minutes.
This article will share the research achievements of Ant Group's multimodal cognitive team in the field of video multimodal retrieval over the past year.
[ Introduction ] This article will share the research achievements of Ant Group’s multimodal cognitive team in the field of video multimodal retrieval over the past year. The article mainly revolves around how to improve the effectiveness of video-text semantic retrieval and how to efficiently perform video-source retrieval.
It mainly includes the following major parts:
1. Overview
2. Video-Text Semantic Retrieval
3. Video-Video Source Retrieval
4. Summary
5. Q&A
01. Overview
Video multimodal retrieval has wide applications within Ant Group. Video multimodal retrieval specifically includes two directions: one is video-text semantic retrieval, and the other is video-video source retrieval.

The video-text semantic retrieval direction aims to retrieve videos that are semantically close to the text, where the retrieval text may not directly appear in the descriptions of the retrieved videos, but the content of the retrieved videos must ensure semantic relevance to the retrieval text. For example, in the search bar of Alipay, users expect to retrieve video content related to their text query; in security monitoring scenarios, text can be used to search for sensitive videos in security contexts. The retrieval text is usually short.
The other direction is video-video source retrieval. Source retrieval allows for finding segments related to the query video in the video repository, which has wide applications in practical scenarios. For example, in video procurement, it can avoid procuring videos that already exist, thus reducing procurement costs; in video copyright protection, when a user provides a short video, it is necessary to search through a massive video repository to determine whether the video infringes copyright.

Methods to quickly enhance video-text semantic retrieval include: video-text pre-training, focusing on hard samples, and introducing fine granularity. Regarding video-text pre-training, we used the r@sum metric on the MSRVTT text-video retrieval dataset to measure the effectiveness of the semantic retrieval algorithm. The r@sum metric is the sum of top-1 recall (r@1), top-5 recall (r@5), and top-10 recall (r@10). By adopting video-text pre-training, we achieved a 24.5% improvement in the r@sum metric; subsequently, by focusing on hard samples, we successfully improved the r@sum by 8.1%; introducing fine-grained recognition technology can enhance the r@sum by 2.8%. In addition, in the field of video source retrieval, we independently developed a video infringement detection method. Based on this method, we successfully saved 85% of storage space and achieved an 18-fold speed increase in infringement retrieval, while the retrieval effectiveness compared to traditional video retrieval methods improved by 2.78% in top-1 F1-score. Next, we will elaborate on our enhancement methods regarding video-text semantic retrieval and video-video source retrieval.
02. Video-Text Semantic Retrieval
In the past year, we conducted research in three areas to improve the effectiveness of video-text semantic retrieval: video-text pre-training, focusing on hard samples, and introducing fine granularity.
1. Video-Text Pre-training
The first key advancement is the video-text pre-training technology. Before elaborating on this, let’s first introduce the meaning of “video-text pre-training”.
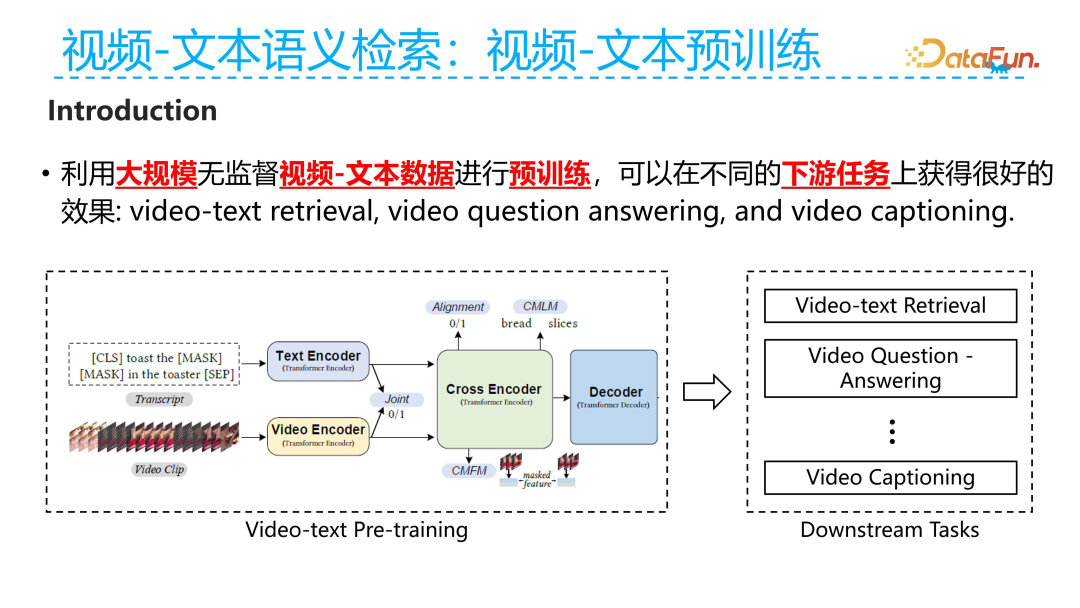
Pre-training is the stage before formal fine-tuning, and it mainly utilizes large-scale and unsupervised video-text pair data for semantic alignment training to enhance the representational capability of downstream tasks. Through pre-training, we expect the model to perform well on various downstream tasks. Common downstream tasks include video-text retrieval, VQA (video question answering), and video captioning.
To understand the pre-training task, two concepts need to be understood: one is where the video-text pair data comes from, and the other is how to understand the text corresponding to the video. Typically, a video corresponds to two text sources: one is the title description corresponding to the video, which is usually an overview of the entire video content, such as the title text corresponding to each video in a short video app; the other source is the audio accompanying each video segment, and the text corresponding to the audio is recognized using Automatic Speech Recognition (ASR) technology. Based on the start and end time intervals of the ASR, the corresponding video segment can be regarded as the ASR text for the current time segment, thus establishing the relationship between video and text. We constructed a large-scale unsupervised video-text pair based on these two types of related data and conducted pre-training on this dataset. Then, the pre-trained model serves as the initialization model for various downstream tasks, significantly improving the effectiveness of downstream tasks.

Most short video scenarios in China mainly target Chinese users. Currently, we face two major challenges in Chinese video-text pre-training. First, there is a lack of publicly available Chinese video-text pre-training datasets; datasets commonly used in academia are mostly in English, such as HowTo100M and WebVid, making it difficult to obtain publicly available Chinese video-text pre-training datasets. In light of this, we constructed the industry’s first open-access Chinese video-text pre-training dataset, which was presented at CVPR 2023. Second, model design needs to focus on cross-modal interaction to achieve deeper interaction and integration between video and text, thereby enhancing the effectiveness of video-text retrieval. We proposed a novel model to enhance cross-modal interaction between video and text, namely SNP-S3, which has been published in the IEEE T-CSVT journal in 2023.
First, let’s introduce the main research achievements of the first part. We proposed the industry’s first publicly released Chinese video-text pre-training dataset. By pre-training on this dataset, we can significantly enhance the performance of Chinese video-text retrieval models.

The main work includes three parts: first, we constructed a large-scale public Chinese video-text dataset CNVid-3.5M; secondly, we adopted effective data processing methods to filter out low-matching video-text pairs, significantly improving data quality; finally, we conducted Chinese pre-training on CNVid-3.5M and verified that our proposed CNVid-3.5M can significantly enhance the effectiveness of Chinese video-text pre-training, establishing a benchmark on this dataset. The entire process is illustrated in the figure above.

Next, let’s introduce the dataset construction process. We collected raw videos from multiple Chinese video websites. When collecting videos, we paid special attention to the category and theme of the current video and tried to maintain the balance between different categories and themes. We successfully constructed 4.5 million raw Chinese video-text pairs. The figure above shows the word cloud generated from the keywords corresponding to the video.
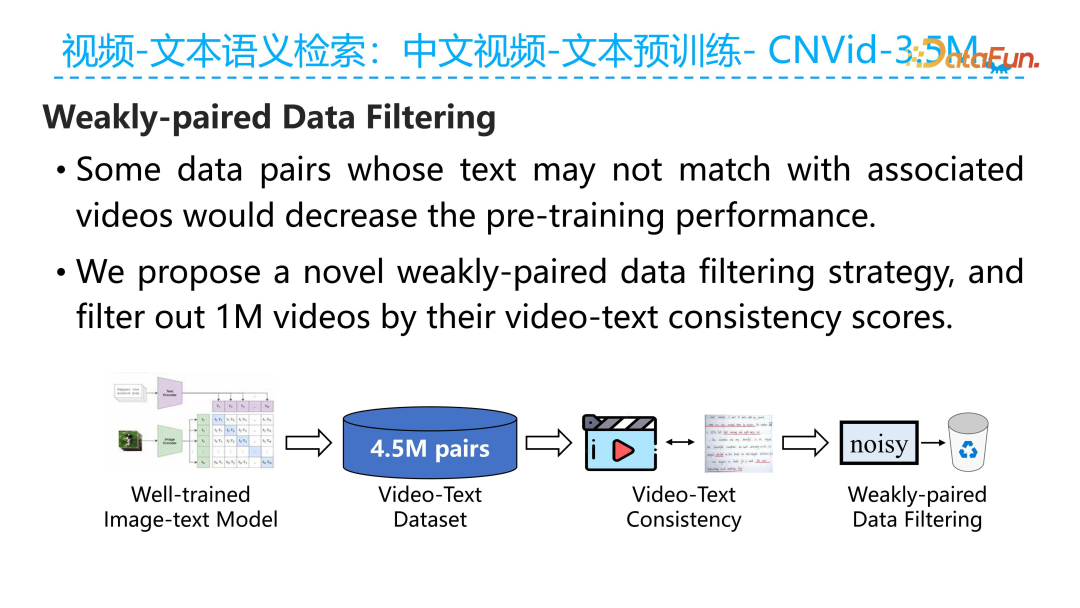
After collecting the data, the next step was data cleaning, filtering out relatively low-quality video-text pairs in the dataset. The original video-text pairs are not strictly semantically aligned. For example, the visual signals present in the current video and the text converted from the background music audio may not have clear semantic relevance, and introducing text from background music audio could contaminate the training data. Therefore, we filtered out as many of these unrelated video-text pairs as possible. To achieve this goal, we proposed a method for cleaning video data using a vision-language pre-training model. The specific implementation steps are as follows: first, we used the trained vision-language relevance model CLIP to assess the relevance between the current text and each key frame in the video, aggregating the relevance between key frames to obtain overall relevance. By setting a threshold for overall relevance, we filtered out videos with low relevance. As a result, we filtered out nearly 1 million low-quality video-text pairs, retaining about 3.5 million Chinese video-text pairs.
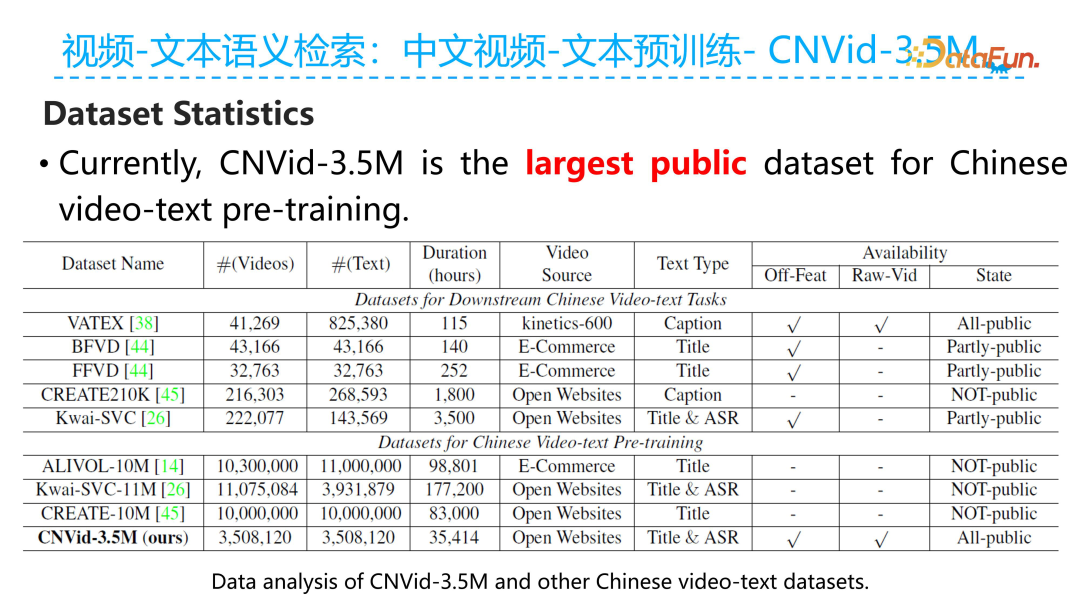
The figure above shows the basic metric statistics of the CNVid-3.5M dataset we constructed. As of the current sharing time, our constructed Chinese 3.5 million CNVid-3.5M is currently the largest publicly available Chinese video-text pre-training dataset in the industry.
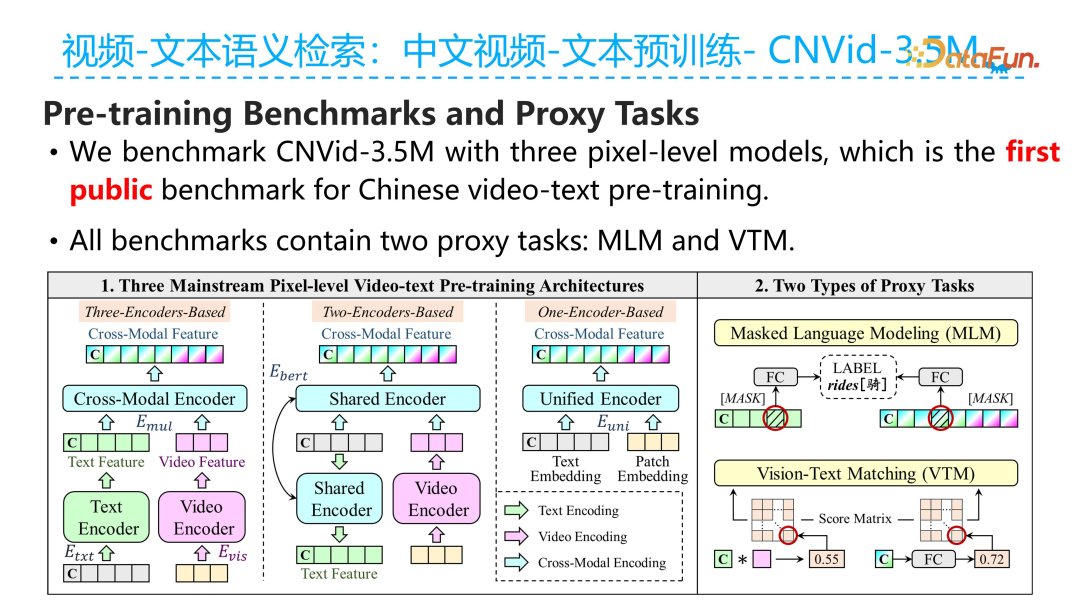
Next, we constructed a benchmark based on the CNVid-3.5M dataset to observe whether various model architectures show improvement when pre-trained on our constructed dataset.
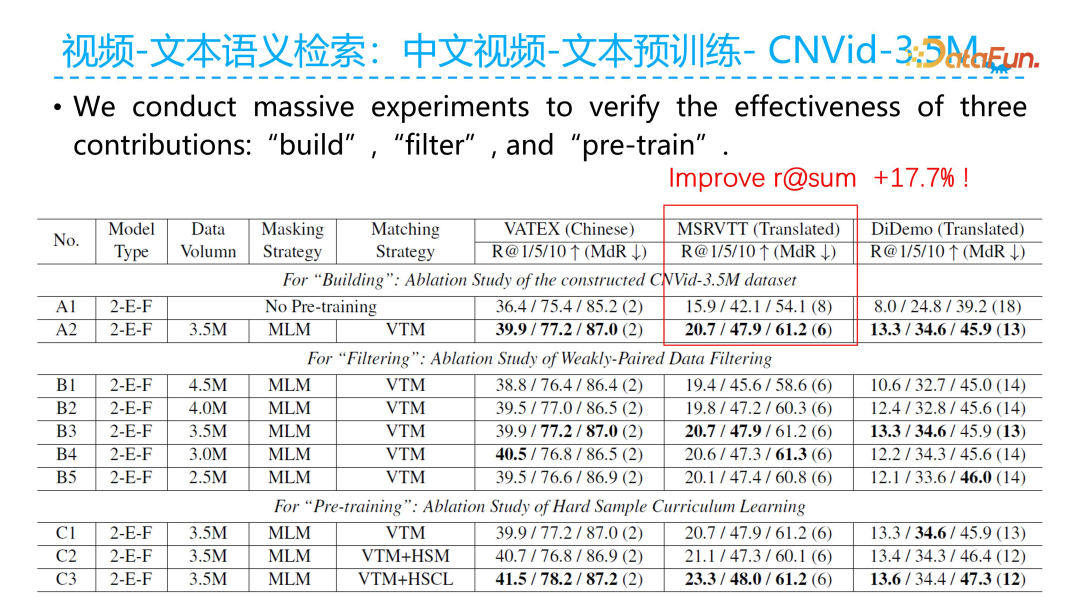
The figure above shows the detailed experimental results of the three stages. During the dataset construction process, we used the original dataset we collected for video-text pre-training. The results showed that using the pre-trained model on the translated Chinese MSRVT dataset significantly improved the overall R@SUM metric by 17.7% compared to before pre-training.
At the same time, the table also reveals that during our filtering stage, when reducing the data from 4.5 million to 3.5 million, although the amount of pre-training data decreased, the overall model performance actually improved.

The second challenge of Chinese video-text pre-training lies in model design, which needs to focus on cross-modal interaction. To address this issue, we proposed a model that enhances cross-modal interaction between video and text, called SNP-S3. S3 refers to the enhancement of important semantic information and is designed to address the following two shortcomings of traditional pre-training.
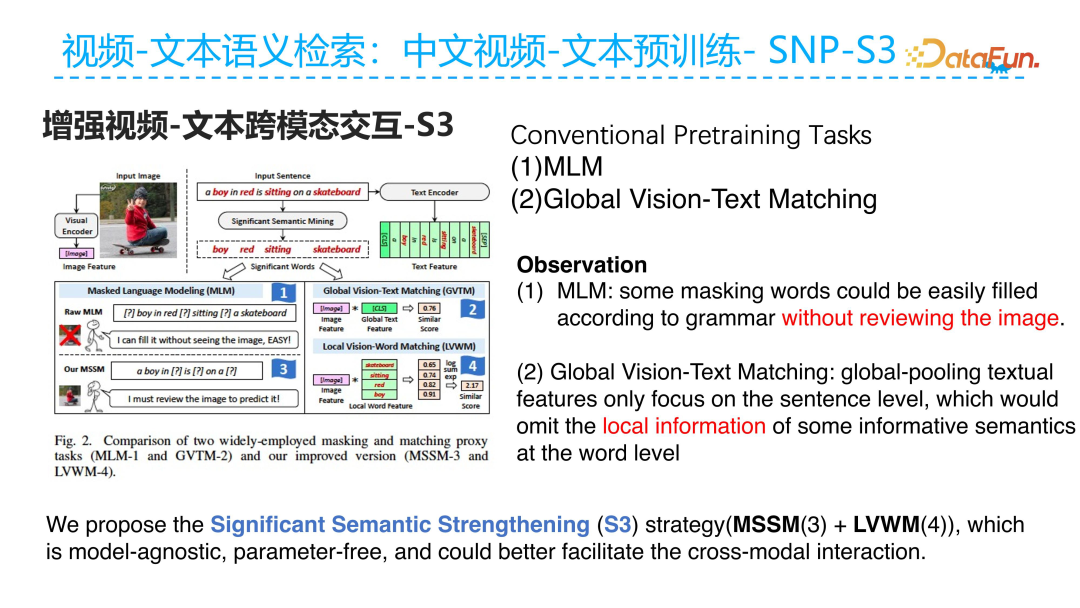
The traditional pre-training task typically uses a mask language modeling task directly on a cross-modal encoder, while another common pre-training task is global Vision-Text Matching. As shown in the figure above, a problem with the traditional Mask Language Model (MLM) task is that when the masked token is not an important word in the text, such as the quantifier “a”, the model can restore the current masked word directly using grammatical knowledge without looking at the relevant video content. However, when the masked word is a keyword, the model must see the current video to know what the masked word is. For example, if a boy is wearing a red shirt, if “red” is masked, the model cannot reconstruct it without visual input. By forcing the model to infer the masked text based on the given visual input, it enhances the interaction between different modalities.
The traditional Vision-Text Matching task has a problem as it focuses more on global alignment, where the visual and text are aligned semantically at the sentence level. Sentence-level alignment is global granularity and lacks local information. For example, in a sentence, if the key word “red” is removed, the matching with the video can still be done very well. This means that the retrieval model does not actually have fine-grained discrimination ability. Attributes like “red” and verbs need more fine-grained capability. We hope to make the model more sensitive to these fine-grained pieces of information based on traditional global matching. Thus, we introduced keyword matching to match more important words in the sentence, such as nouns, verbs, and adjectives, with the video to enhance the model’s recognition capability at the fine-grained level.
These two improvements, namely masking important words in the Mask Language Modeling task (Mask Significant Semantic Model, MSSM) and adding fine-grained improvements on global information (LVWM), serve the goal of S3 significant semantic enhancement.
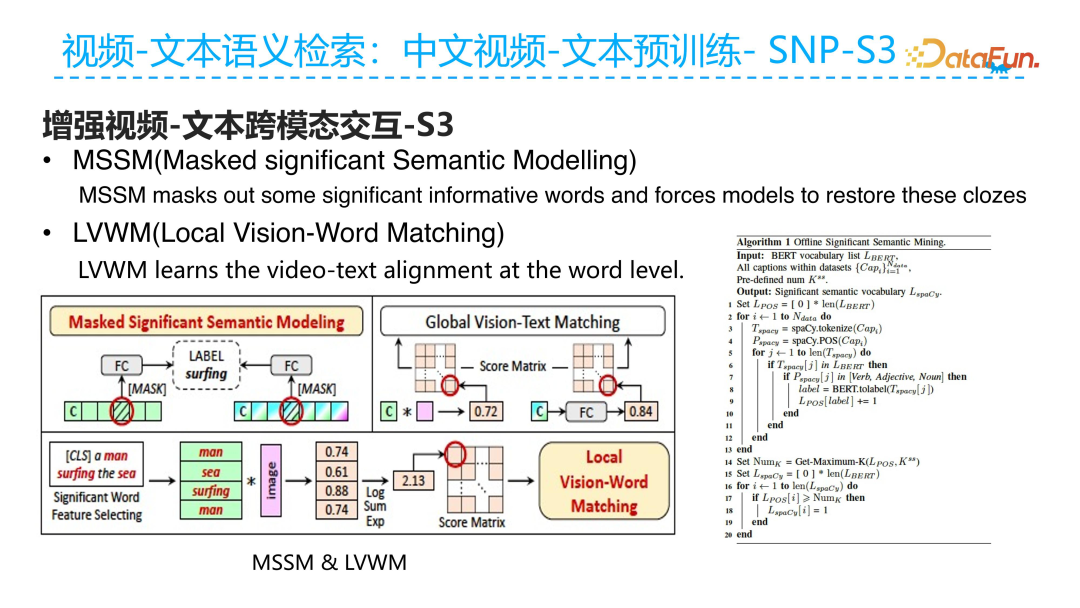
Here we provide a quantitative analysis of the S3 method, allowing us to draw the following conclusions:
-
MSSM shows better performance than traditional MLM across various model architectures, thus can directly replace the previous traditional MLM task.
-
Additionally, the LVWM task can only serve as a supplement to traditional global video-text matching tasks and cannot replace them. If we add the LVWM task to the traditional GVTM task, we can see that B3 performs better than B1, and B7 performs better than B5, proving it is a very good supplement for local information.
-
Moreover, both core components proposed in S3 are model-agnostic. We can see that B1 vs. B4 and B5 vs. B8 perform better on different model architectures such as ResNet50 and PVT; therefore, these two strategies can be applied to any model architecture. Through the S3 strategy, we can improve the r@sum metric by 6.8%.

We also conducted a qualitative analysis of the S3 method. After adding S3, when given input text, the model pays attention to the areas in the visual content that are more relevant to the text. The figure above shows some specific examples, such as images of a person surfing at sea, where the baseline attention area is scattered and lacks semantic relevance; however, after applying the S3 method, it focuses on the person and also pays attention to the background of the waves.
This concludes the introduction to video-text pre-training, which mainly includes two aspects: first, how to construct a Chinese video-text pre-training dataset; second, how to enhance the interaction between video and text in model design. These two optimizations can significantly improve the effectiveness of video-text semantic retrieval.
2. Focusing on Hard Samples
Next, we will continue to share how to further enhance video-text semantic retrieval effectiveness by focusing on hard samples. Focusing on hard samples can improve video-text semantic retrieval by nearly 8.1% in R@Sum.

The key point of focusing on hard samples is that the model can gradually focus on hard samples during the learning process. The main reason is that hard samples may not be helpful for the model’s training at the beginning. At the initial training stage, hard samples might make it difficult for the model to converge, but when the model has converged well, focusing on hard samples can further enhance the model’s performance.
There are two main approaches to focusing on hard samples: one is manually specifying the focus on hard samples, for example, setting different focus levels on hard samples based on the different stages of model training; the other is allowing the model to learn the focus on hard samples adaptively. Our team has explored both aspects.
First, let’s introduce the strategy of manually specifying the focus on hard samples, mainly using the hard sample mining work based on curriculum learning, which was published at CVPR 2023.
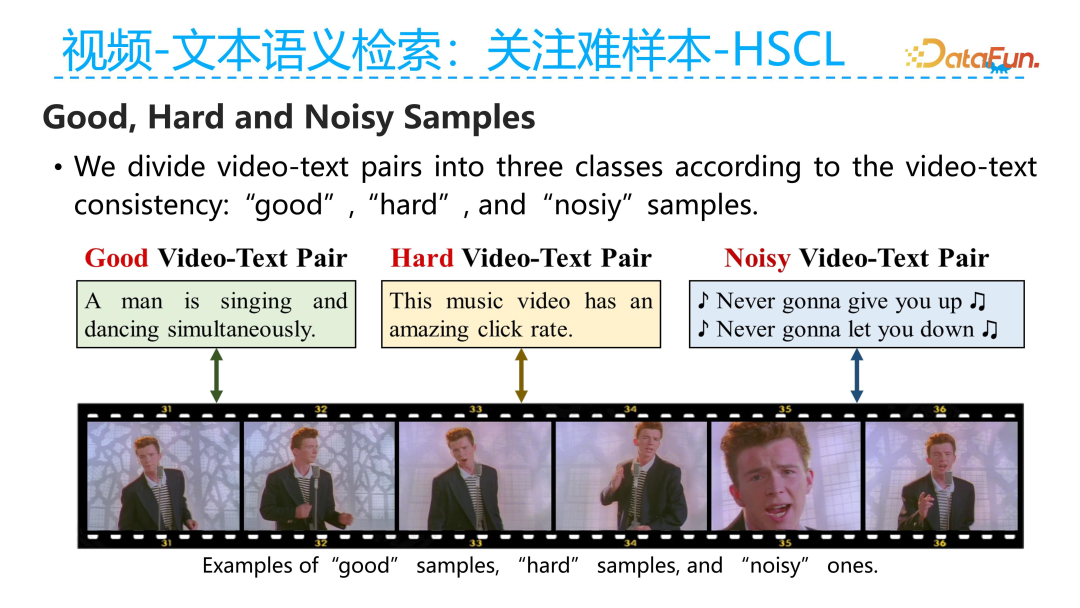
Samples in the training process can generally be divided into good samples, hard samples, and noise samples. Good samples are those with relatively high semantic alignment quality between the video-text pairs, where the text can clearly describe the content corresponding to the current video segment. Hard samples refer to those where the video and text are semantically aligned, but the semantics reflected in the text are weakly related to the video, yet still have some relevance. Noise samples are defined as those where the video and corresponding text have almost no semantic relevance, such as when the lyrics in the audio of the video do not closely relate to the video’s semantics, making it difficult to describe the current video’s semantics. We define these low-relevance video-text pairs as noise samples.
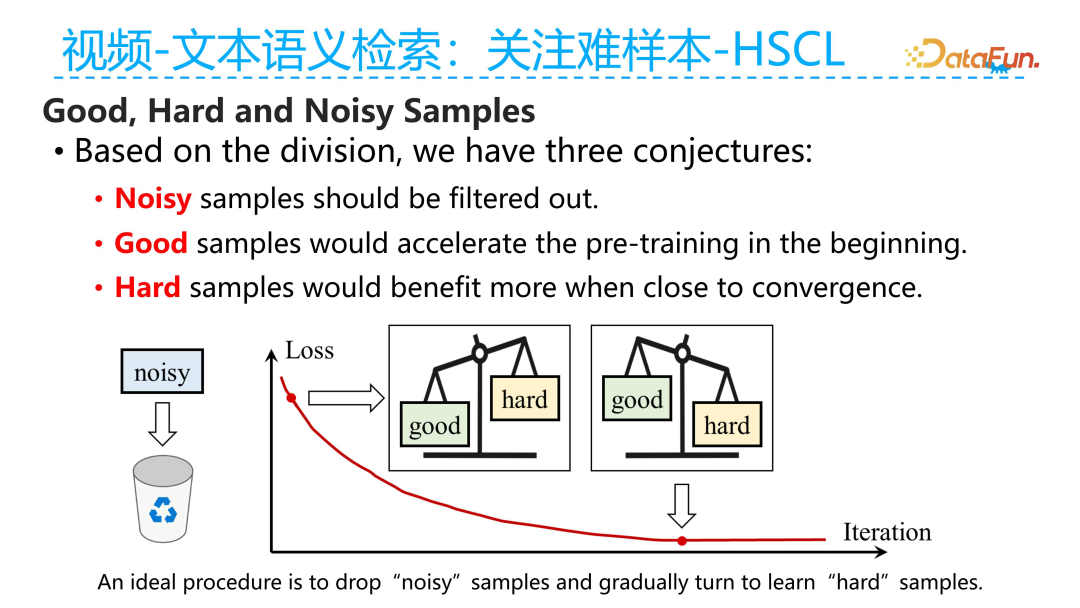
These three types of samples play different roles in the training process. First, noise samples negatively impact training, whether at the beginning or the end of training, so they should be discarded directly. For high-quality samples, the model should focus more on them during the initial training phase to accelerate convergence. For hard samples, the model should focus more on them once it has converged to a certain extent and has shown good performance, allowing the model to learn from difficult examples and further enhance its performance. However, if hard samples are focused on from the beginning, it may cause the model to learn incorrectly and fail to converge well.
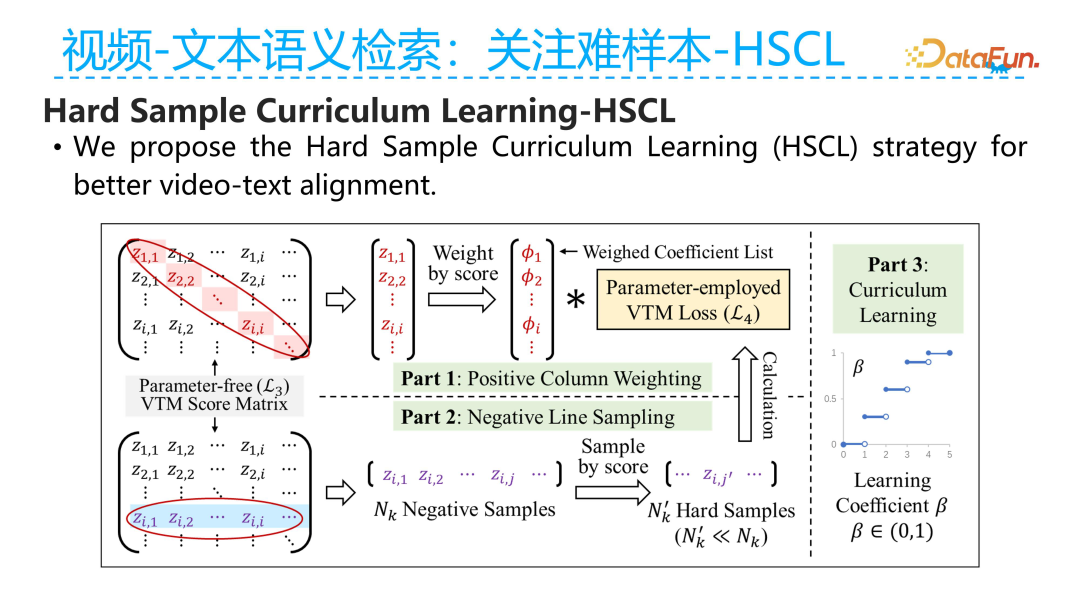
Based on this observation, we designed an algorithm for hard example curriculum learning. The core idea of the algorithm is to let the model focus more on good samples at the beginning and, after the model has a certain ability to discern relevance, attempt to mine hard examples, allowing the model to focus more on difficult samples in the later training stages.
The specific approach is illustrated in the figure above. First, we constructed a similarity matrix for video and text using contrastive learning. The diagonal of the similarity matrix consists of positive samples, while the off-diagonal entries are negative samples. Next, we determine whether the current positive sample is a hard sample or an easy sample based on the similarity value on the diagonal. Generally, if the similarity for a positive sample is high, it is likely an easy sample. We measure hard samples based on this approach in the column dimension. At the same time, we also measure hard samples in the row dimension, where each row represents the similarity of the current text to all videos in the current batch. We extract all negative samples, and if the current text has a high similarity to a negative sample, we consider the current video-text sample to be a hard example. Next, we combine the measurements based on rows and columns to construct the weight for the VTM (video-text matching) loss. This weight is derived from the combined row and column weighting, and the size of the weight coefficient is adjusted through a curriculum learning approach. Initially, the weight is set to 0, meaning no hard example mining loss is applied; as training progresses, the weight for loss gradually increases, allowing the model to focus on hard samples.
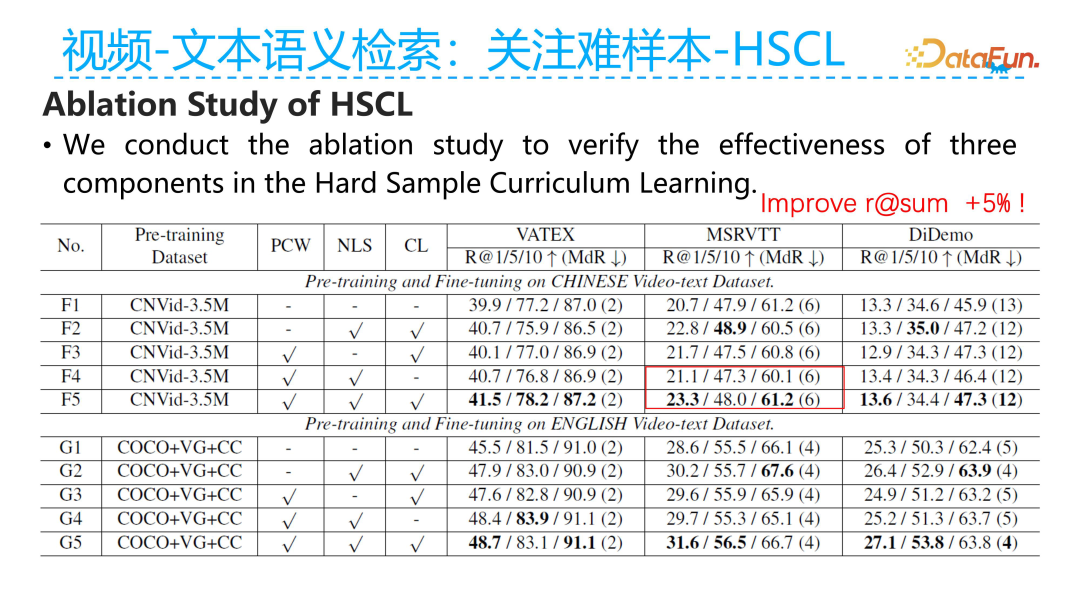
We analyzed the performance of the current model after adding the HSCL hard sample curriculum learning loss. We used two datasets: one is the Chinese pre-training and fine-tuning dataset CNVid-3.5M, and the other is an English pre-training and fine-tuning dataset COCO+VG+CC. The experiments found that after introducing the hard sample curriculum learning method, it could bring about a 5% improvement in the R@SUM metric for text-video retrieval.
The above introduction pertains to the manual method of specifying the focus on hard samples, which is not automated and requires hyperparameter tuning. We hope to allow the model to learn the focus on hard samples adaptively; therefore, we designed an adaptive method. The methods DMAE and NegNCE were published at the ACM MultiMedia 2023. This method can bring a 3.1% improvement in R@SUM.
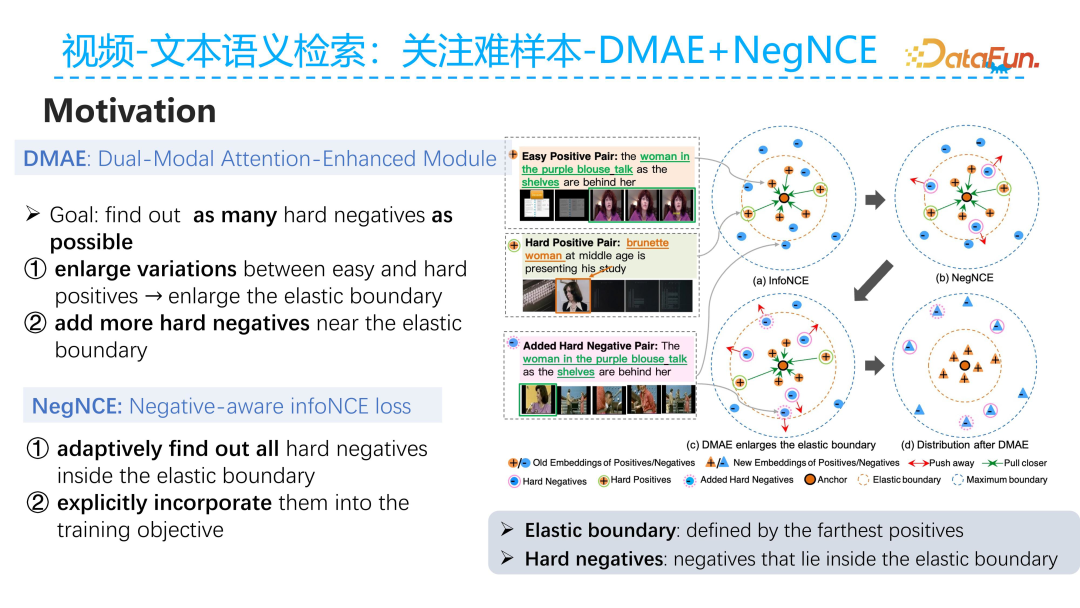
Next, let’s introduce the motivation behind DMAE and NegNCE.
DMAE is a dual-modal attention enhancement module, and its core idea is to find as many hard examples as possible. It mainly adopts two approaches: the first is to expand the boundary between easy and hard samples. As shown on the right side of the figure, from b to c, the addition of DMAE to NegNCE allows for more hard negative examples to be introduced, thereby enhancing the model’s ability to distinguish between samples. The core idea of NegNCE is to identify which hard samples truly need to be focused on. Since these hard samples may have already been addressed by the previous infoNCE contrastive loss, we hope to add an auxiliary NegNCE loss to the training objective to allow the model to dynamically focus on these hard samples.
Traditional infoNCE primarily focuses on positive samples, pulling positive samples closer and pushing negative samples away without considering hard negative samples. Introducing NegNCE allows the model to explicitly focus on hard samples. In the example shown in the figure, the hard negative samples are very close to the decision boundary. Although they are negative samples, their similarity to the current anchor may be closer than that of the positive samples. NegNCE can gradually push such negative samples further away. DMAE will extract more of these negative samples, encompassing more negative samples within the scope of the current model loss. In summary, DMAE extracts more negative samples, and NegNCE works to distinguish between negative samples, allowing the model to adaptively focus on hard samples during training.
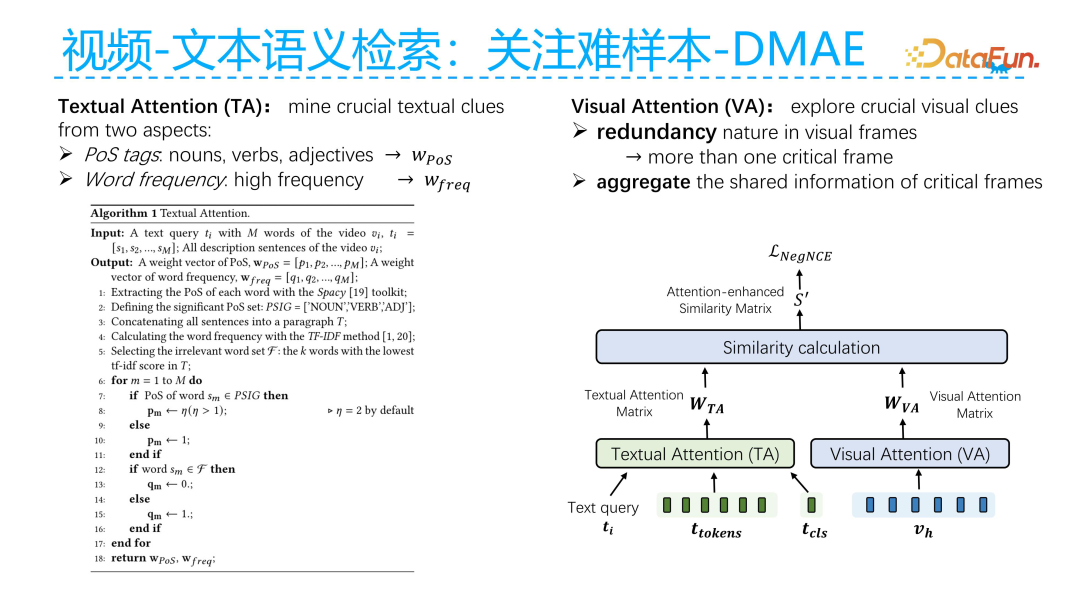
DMAE mainly focuses on two aspects: on the text side, because sentence expressions contain a lot of redundancy, we hope to enable the model to focus more on the key words in the sentence. These key words must first be important words such as nouns, verbs, and adjectives, and secondly, they should have a lower frequency, meaning that the words with lower frequency carry more information. By combining these two aspects, we can select the key words in the text and give them higher weights during text attention.
On the visual side, the main difference between videos and images is that videos contain many key frames, and there is some redundancy between these key frames, meaning that temporally adjacent frames may be very similar semantically and visually. This means that if a current frame has hard samples, there may also be many hard samples in another frame that is similar to it. We take the union of these two types of hard samples, and the combined hard sample set consists of the current frame and the other frame that is similar to it.
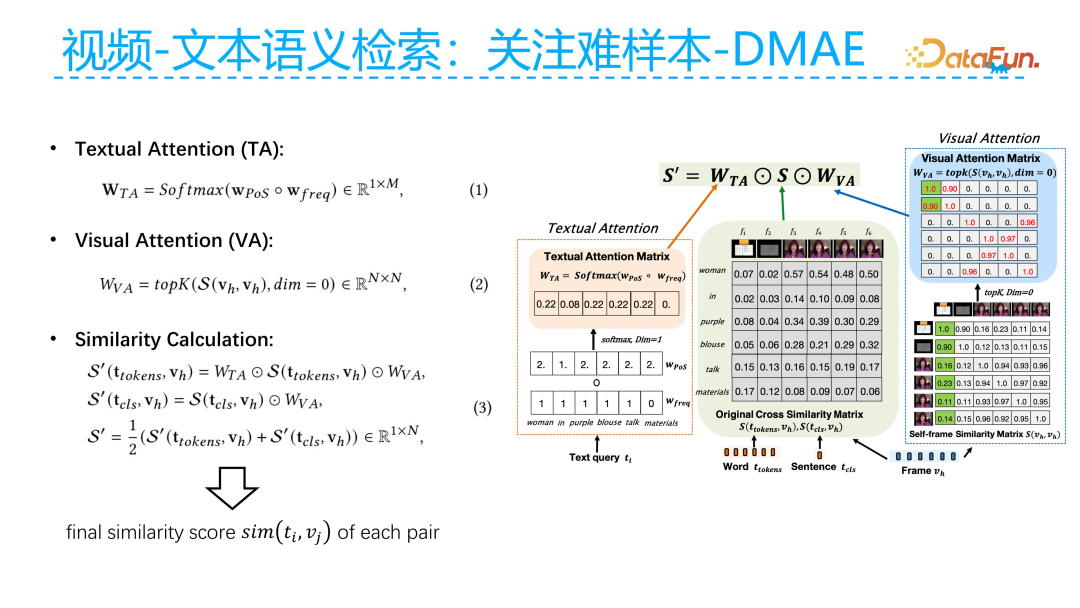
The specific implementation method is that after calculating the similarity matrix between video and text, we perform weighting on the text side. The weights on the text side are mainly determined by the part of speech and frequency of the words. Additionally, the weights on the video side are primarily based on the similarity matrix of the current video’s key frames. We then retain the top scores, for example, finding the most similar frames to each frame to identify hard samples, which are also considered hard samples for the current frame. Through this approach, we can mine more hard examples based on the similarity matrix, where the harder samples will ultimately receive higher scores in the similarity matrix.

After mining more hard examples, we hope that the model can dynamically distinguish these hard examples during the training process. Thus, we explicitly introduce the NegNCE loss. The traditional calculation of similarity between video and text uses InfoNCE loss, where the numerator is the positive sample and the denominator consists of all negative samples. InfoNCE focuses on pulling positive samples closer and pushing negative samples away without considering hard negative samples.
During training, NegNCE first determines which samples are negative. For the same text, if the similarity of the negative sample video to the text is higher than that of the positive sample video, it is considered a hard example. This way, during training, we can extract all video-text pairs where negative samples have higher similarity than positive samples and add an auxiliary loss (as shown in the formula above) specifically for mining difficult negative samples. The auxiliary loss is combined with the previous InfoNCE loss through weighted addition. We can adjust the model’s focus on hard samples during training by adjusting the weight of r2.
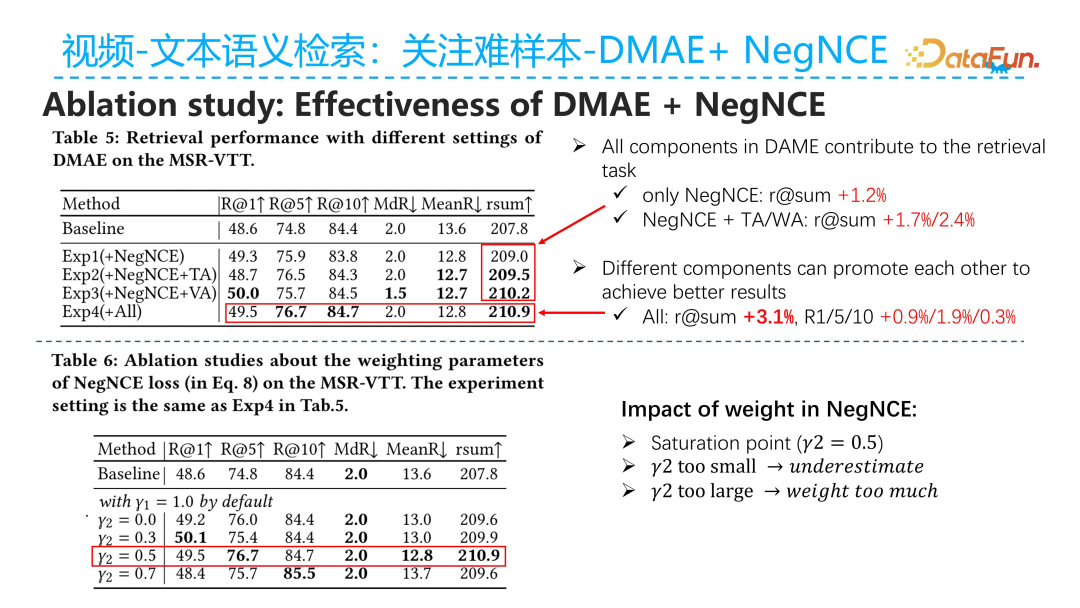
We verified the effectiveness of the hard sample strategy mentioned above. DMAE is primarily used to expand the range of hard samples, while NegNCE allows the model to focus more on difficult-to-distinguish negative samples after expanding the range of hard samples. We found that using DMAE along with NegNCE leads to an overall improvement of 3% in the R@SUM metric.
3. Introducing Fine Granularity
Next, we will introduce the third aspect, which is introducing fine granularity, which can quickly enhance the effectiveness of video-text semantic retrieval. In experiments, introducing fine granularity can improve the R@SUM metric by 2.8%.

Existing work on video-text semantic retrieval lacks the ability to distinguish finer semantic granularity. For example, commonly used Pairwise loss methods primarily rely on binary quantization to determine whether videos and texts are similar, which is a coarse-grained recognition approach essentially a binary classification. Another approach based on Triplet loss does not classify relevance or irrelevance but models the partial order relationship, allowing the model to model semantic relevance at a finer granularity. However, the core challenge is how to construct video-text pairs of different semantic granularities.
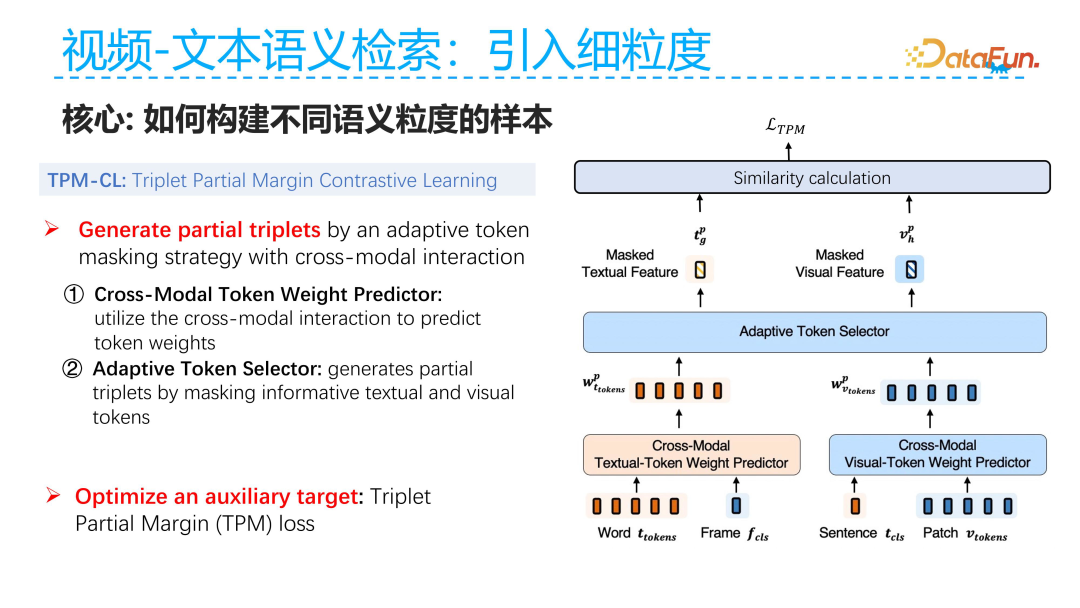
To construct video-text pairs with different semantic granularity, we adopt a generative approach to create such partial order pairs. The specific idea is to draw on the CSE work in unimodal text. When extending to multimodal, if the current complete text and the complete video are completely relevant, then if we remove some key frames from the video, the relevance of the video will gradually weaken. Thus, the constructed partial order relationship is: the relevance between the text and the complete video is greater than the relevance between the text and the video after removing key frames. Similarly, for the text side, the relevance between the current video and the text is greater than the relevance between the current video and the text after removing keywords. Based on this idea, we generate pairs with partial order relationships. Another difference from unimodal in generating partial order pairs is that in multimodal, we need to see the text to determine which frames in the video are important and which are not; similarly, for the text side, we need to see the video to determine which words in the text description are important and which are not.
Based on this observation, we proposed two modules: the first is the prediction of token importance across modalities, where the core algorithm is to predict the importance of tokens in one modality given an input from another modality. For example, given the global information input from the visual side, the model predicts the importance of the current text tokens, i.e., which words in the text are important; similarly, for the visual side, given the overall representation of the current text, the model predicts which tokens in the current visual are important. Through this approach, we can select the important text tokens and visual tokens and further mask these important tokens. The samples generated by masking are less relevant to the other modality than the complete text or video.

The specific implementation is divided into two stages: the first is to generate partial order samples, where we first predict which tokens are more critical for the other modality; after predicting the weights of these critical tokens, we determine which tokens to mask that have the greatest semantic impact on the current text tokens. The second step is to directly mask these tokens that have the greatest semantic impact, thus generating partial order pairs. Similar to the idea of Triplet loss, the samples after masking will have weaker relevance to the other modality. The triplet data establishes relevance among the three, meaning that the unmasked samples should have higher relevance to the text than the masked samples, and the unmasked text should have higher relevance to the video than the masked text.

We verified the specific effects of introducing fine granularity. After introducing the fine-grained TPM-CL method, compared to before, there was approximately a 2.8% improvement in the MSRVTT R@sum metric. It can also be used in conjunction with DMAE, and by expanding the introduction of more negative samples, TPM-CL allows the model to focus more on difficult-to-distinguish negative samples during training. The combination of these two methods brought a 4.4% improvement.
To summarize, the third method to quickly enhance video-text semantic retrieval is to introduce fine granularity, specifically the work done in generating partial order samples and introducing partial order loss.
This concludes the introduction of the three main optimization methods for video-text semantic retrieval. Next, we will introduce the application of video multimodal in the area of video-video source retrieval.
03. Video-Video Source Retrieval
The core of video-video source retrieval is how to efficiently and cost-effectively implement video infringement detection. In this field, we proposed a self-developed end-to-end segment matching localization technology that can quickly achieve copyright retrieval from video to video, saving 85% of storage space compared to traditional methods, and accelerating video infringement retrieval scenarios by 18 times. In terms of retrieval effectiveness, the F1 score improved by 2.78% compared to existing methods.
1. Challenges of Video-to-Video Source Retrieval
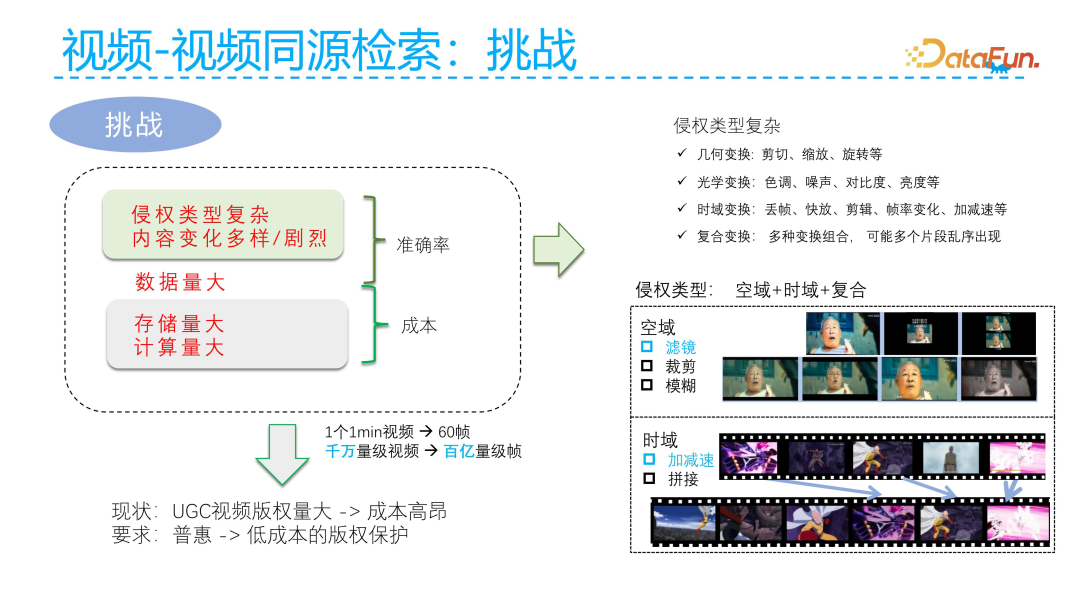
The challenges faced in video-to-video source retrieval mainly include:
-
First, the types of video infringement are complex, and the content changes are diverse and drastic. This can affect the accuracy of copyright retrieval. The complex infringement types involved include geometric transformations (such as cropping, scaling, rotation, etc.), optical transformations (such as hue, noise, contrast, brightness, etc.), temporal transformations (such as frame dropping, fast playback, editing, frame rate changes, acceleration, and deceleration), as well as composite transformations that use the above various transformations. These special transformations make it extremely difficult to perform source detection on videos. For example, adding various filters to the spatial domain of a video and cropping and blurring the original video results in all videos being infringements of the original video. Similarly, accelerating or decelerating the original video or splicing it also constitutes an infringement.
-
On the other hand, the massive amount of data means that every frame of the video needs to be computed and processed, leading to high computational and storage costs.
Therefore, to achieve video-to-video source retrieval, the core lies in how to improve retrieval accuracy and how to reduce costs.

Traditional video-to-video source retrieval methods cannot meet the demand. For example, the research of MultiMedia09 uses temporal networks based on dynamic programming to find the longest path for locating infringement segments. Its advantages are that it requires no supervision and has relatively precise localization, but its disadvantage is poor robustness, especially when faced with acceleration or deceleration, or composite transformations in the temporal and spatial domains, its performance is hard to meet expectations. Other works are based on deep learning models, processing the problem of whether a video infringes copyright as a binary classification problem, i.e., integrating video features, and marking them as label “1” if infringing and “0” if not. This method cannot achieve segment localization for video infringement detection.
2. Framework and Core Technologies
Based on the inability of existing algorithms to meet the demand, and given the significant business implications of video infringement detection, we developed a copyright detection framework to address the aforementioned effectiveness and cost issues.
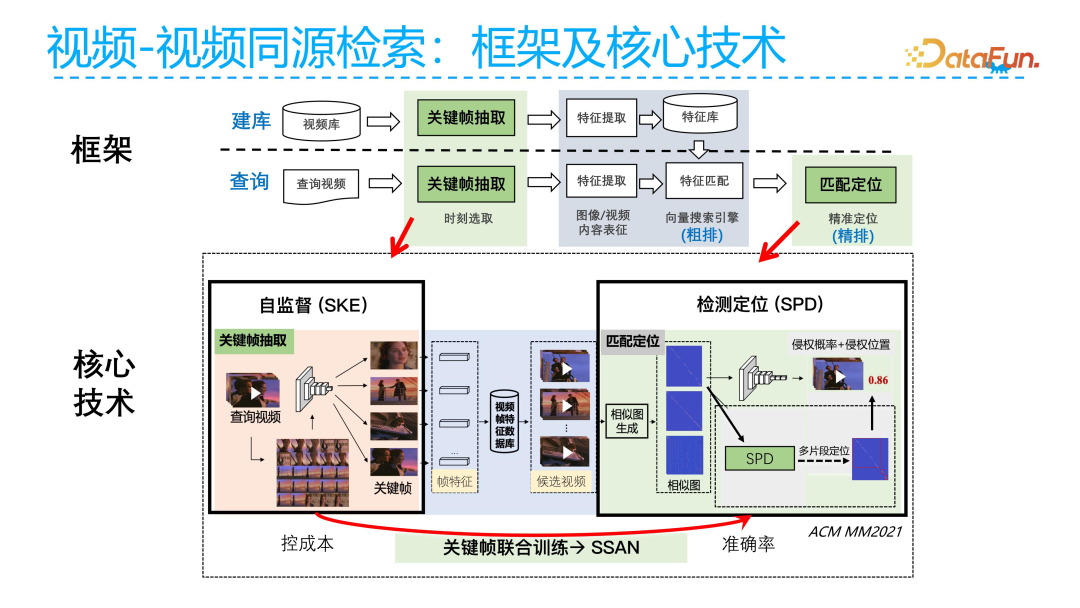
The overall design of the framework is illustrated in the figure above.
First, we process the video repository by extracting key frames from the video, then performing frame-level feature extraction and storing them in a feature repository. When processing the query video, the same key frame extraction and feature extraction are performed, followed by feature matching between the query video and the repository. After matching, fine sorting is conducted to determine whether the current query video infringes copyright.
The core technologies include two aspects: first, how to accurately extract key frames from videos, which is essentially a requirement to reduce costs. If we save every frame of the video, the storage costs will be relatively high. Therefore, we expect to replace the entire video with key frames to reduce costs during copyright retrieval. Secondly, how to quickly locate the infringing parts of the video, which involves balancing accuracy and cost. For example, the aforementioned ICCV research primarily involves pairwise video infringement detection, which may be theoretically feasible but cannot be implemented in practical business due to excessively high infringement comparison costs.
Our proposed self-developed solutions include the self-supervised SKE method and the detection localization SPD module. Next, we will elaborate on these two methods.
First, let’s introduce the SPD module. The core idea of this module is to compare the features of the key frames of the candidate video and the query video pairwise after providing the candidate video and the query video, constructing a similarity matrix. In the feature similarity graph, we can see that certain similarity values will be higher and exhibit a degree of continuity. Based on this observation, we can transform the problem of segment matching between videos into an operation of detecting infringement patterns on the feature similarity graph. This means we can build a training set of infringement similarity graphs and label the start and end times of infringements on the feature similarity graph, allowing us to directly train a YOLO object detection model on the feature similarity graph for rapid recognition. We can determine whether the candidate video has similarities with any video in the repository, thus identifying whether the video infringes copyright.
The core SPD module outperforms the mainstream dynamic programming methods in the industry, achieving a speed-up of 18 times. This is primarily due to the rapid object detection capabilities of YOLO. Additionally, for more complex scenarios, such as those involving accelerated or decelerated infringements and those processed with filters, we see significant enhancements compared to mainstream industry solutions.
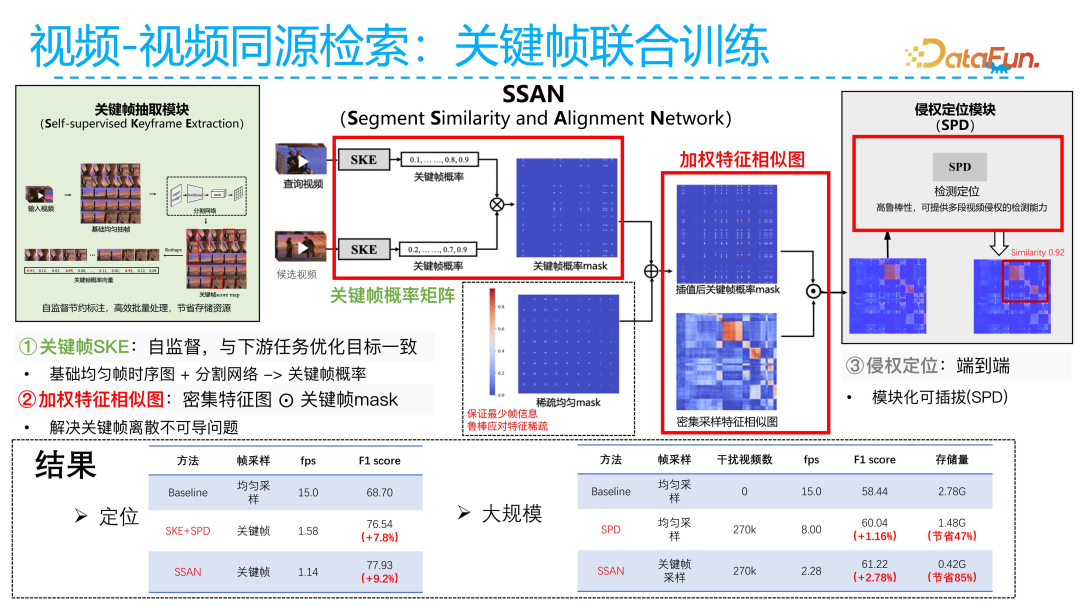
The second core task of infringement detection is to reduce costs. The core idea is to replace traditional uniform frames with key frames. Compared to uniform frames, the number of key frames is usually reduced by about 70% to 80%, thus significantly decreasing the corresponding storage space. Key frame detection is the core content of the key frame extraction module. First, we preprocess the video, flattening all its frames at the same time and stitching them into a large image. Next, we perform a task similar to image segmentation on the large image, aiming to output the exact category corresponding to each pixel. In our scenario, each pixel actually represents a key frame, so the goal is to output the probability of each frame becoming a key frame.
If we want to combine the above key frame extraction module with the infringement localization module, the core lies in selecting key frames. However, directly using the key frame extraction module is not differentiable, so we first output the probability mask for key frames while constructing a mask for uniform frames, and then add these two masks together. Finally, we use the mask to perform element-wise multiplication on the dense sampling uniform frame feature similarity graph. The resulting feature similarity graph can be jointly trained with the SPD module. This way, we can ensure that the gradients of the SPD module can dynamically backpropagate to the key frame extraction module, allowing the key frame extraction and SPD module to be jointly trained in an end-to-end manner, without needing to train the key frames first and then the other modules as in traditional methods.
Joint training of key frame extraction and SPD shows significant improvements compared to using SPD alone. Additionally, after testing on large-scale datasets, both storage and cost requirements show significant reductions. We can see that by storing key frames, we can save 85% of storage compared to using SPD alone. At the same time, in terms of infringement detection effectiveness, we can achieve better results with fewer key frames, leading to an overall performance improvement of 2.78%.
04. Summary
To review the content shared in this presentation, we mainly introduced two directions of video multimodal retrieval: one is video-text semantic retrieval, and the other is video-video source retrieval.

For video-text semantic retrieval, we proposed three methods for rapidly enhancing retrieval effectiveness: first, through video pre-training, which can bring a 24.5% improvement; second, by focusing on hard samples, which brought an 8.1% improvement, where hard samples are divided into two types: one based on manually specified focus on different hard samples at different training stages, and the other allowing the model to learn the focus on hard samples adaptively during training; third, introducing fine granularity, which can bring a 2.8% improvement, mainly involving how to generate partial order samples and introducing triplet partial order loss to model fine-grained semantics.
The video-video source retrieval section introduced our self-developed end-to-end segment matching localization method, which can save 85% of storage, accelerate infringement detection by 18 times, and significantly improve retrieval F1 scores compared to using uniform frames.

The works mentioned above are the publicly disclosed research achievements of Ant Group’s multimodal cognitive team over the past year, mainly involving advancements in video semantic retrieval and video-to-video copyright detection. If you are interested, we welcome you to learn more about our work. At the same time, we also warmly invite more individuals to join us in pushing forward related work.

05. Q&A
Q1: Does the key frame need to be annotated before training the segmentation model?
A1: The key frame module has two usage methods. If the module is extracted separately, it is similar to a segmentation model, which requires annotation. For example, one can manually annotate which frames are key frames and then train the model separately to extract key frames from the video.
However, if we adopt the end-to-end approach used here, the key frame module is combined with the downstream task of similarity frame comparison, where the downstream task is more about infringement localization, for example, comparing two similar videos and frames. This way, we achieve an adaptive end-to-end approach to select key frames without the need for annotation.
Q2: Are there any ready-made key frame extraction models available on Hugging Face?
A2: Currently, the model has not been open-sourced, but there are plans for open-sourcing, and it is currently undergoing internal open-source processes.
Q3: Multimodal embeddings often do not work well in downstream recommendation scenarios. What are some good solutions?
A3: We may prefer to refer to the content discussed earlier in the video-text semantic retrieval section. In the semantic retrieval layer, applying text semantic retrieval specifically to search or recommendation scenarios involves several closely collaborative steps. First, in the recall phase of search and recommendation, we can increase the recall by adding video-text links. Second, in the ranking phase, we can introduce the features of videos and texts after pre-training into the ranking features. Third, in the fine-tuning phase, we need to perform video disaggregation. At this point, we can use the trained embeddings for disaggregation. If the results are not satisfactory, it may relate to the specific business scenario or how to utilize these multimodal pre-training representations, and we may need to clarify the specific scenario and problem to provide an answer.
Q4: During the presentation, it was mentioned that storage was saved. What types of storage media are primarily used?
A4: For small-scale video copyright retrieval, it can be directly stored on NAS drives, which are ordinary hard drives. For large-scale storage, these features are stored directly in vector retrieval databases. Storing them in databases can save more storage compared to NAS, but using key frames will save a significant amount of storage space.
Q5: Can the key frame solution also be used in video-to-video translation for different languages?
A5: Video-to-video translation specifically refers to converting English videos into corresponding ASR voice transcripts.
The key to translating the audio content in videos is that not only must the audio tracks match, but the audio tracks must also correspond to the lip movements. Due to differences in speaking speed across languages, traditional translation methods may require editing work when converting from Chinese to English or vice versa, as the time required will vary. From another perspective, I believe this technology effectively addresses the alignment issue between two videos. While I do not have in-depth understanding of the translation scenarios I mentioned, I assume that if alignment issues exist between video segments, this method should be widely applicable.
Q6: Could you provide more details about the team’s recruitment situation?
A6: Thank you for your close attention to our team. We are the Ant Group’s multimodal cognitive team, and we are always committed to recruiting talent. The ongoing recruitment covers multiple fields, not limited to the development directions discussed today. Our main research areas include multimodal large models, video large models, and copyright detection, among others. Overall, our work can be divided into two major areas: video processing and image-text processing. In image-text processing, we focus on multimodal and large models; in video processing, we concentrate on real-time and semantic retrieval of video-text as well as video-to-video copyright detection. Students with strong interest or relevant experience in these fields are welcome to send us your resumes. Our recruitment bases are in Hangzhou and Beijing, and our teams in both locations warmly welcome your joining!
Q7: Does feature extraction from videos refer to visual input?
A7: The extraction of video features discussed here, for example, in the context of source retrieval, involves the following operational process: first, we extract frame-level key frames from the video and perform feature extraction on these key frames. For the previously mentioned video-text pre-training, the feature extraction process may be conducted directly at the video level, similar to the video swing model, which outputs the representation of the entire video. Therefore, there may be differences in the video feature extraction methods used in these two tasks, one focusing more on frame-level feature extraction while the other emphasizes video-level extraction. However, regardless of the approach, visual input is required.
Q8: How are video features extracted by merging key frame features?
A8: This is because the information discussed in today’s presentation primarily involves video frame-level information. The video segments, as important components, along with their underlying library and the matching of video key frames, collectively construct a similarity matrix feature vector matrix. However, this approach does not implement an aggregation process for overall video and key frame features to the entire video features.
In fact, commonly used aggregation methods include both non-parametric methods, such as pooling operations based on key frame features, and parametric methods, such as adding a temporary encoder on the upper layer to input the features of video frames as tokens similar to those used in Transformers for continuous modeling, possibly involving parameterized methods. Additionally, there may be strategies similar to temporal video modeling methods, such as the Token Shift method. These methods can convert frame-level features into video-level features. These methods have been practiced and attempted, yielding certain results.
Q9: Should it be understood that the video features are the features of the entire video, which may be artificially assigned, but the real features still reflect the essence? Is this the correct understanding?
A9: Yes. The actual operation is more influenced by the granularity of the problem being addressed. How to design video features? For example, in the video-text semantic retrieval domain, the core issue is how to retrieve videos from a text perspective. Since the entire video is treated as a whole, research in this area tends to focus on how to present the overall expression of the video, i.e., how to showcase the video content. In contrast, in the video-to-image retrieval scenario, this approach emphasizes image source retrieval, for instance, in copyright detection scenarios, where the retrieval results may include segments of the query video, which may pose a copyright risk relative to a segment in the repository. Therefore, research in this area focuses more on the expression of video segments or even more microscopic video frames. In this case, the focus of video features is not on the embedding representation of the entire video but rather on the representation of video frames. We should analyze based on specific problems.
Q10: Is ASR and OCR information from videos utilized?
A10: Yes, it is utilized. For example, in the source retrieval domain, it does not involve a large amount of text information; however, in semantic retrieval, when processing video data, we first need to introduce OCR (Optical Character Recognition) technology. Generally, when performing semantic retrieval operations, we construct the pairing relationship between video and text. When a video lacks an overall textual description, the pairing between video and text is usually obtained from ASR. The starting time and structure time of the ASR are associated with the video segments that correspond to the ASR text visually. Simultaneously, we also use the key frames in the visual segments corresponding to the current ASR to perform OCR, extracting the OCR text and adding it to the ASR. Therefore, ASR and OCR together constitute the content of the text. However, it is important to note that if OCR text is added to this part of the text, there may be some issues, as OCR text in key frames often has high similarity, requiring methods similar to video-level OCR for deduplication of OCR text.
Q11: Were the issues addressed in this part of the Q&A discussed in the video-text pre-training section?
A11: Yes. In fact, this research is not limited to video-text pre-training but also involves video-text semantic retrieval. The discussion on what kind of text to use pertains to how to improve the effectiveness of video-text retrieval at the model or data level. There is also an important perspective on how to construct text to make it more relevant to the video. For example, text can come from the video title, such as the title of the entire video, the cover description of the video, or the automatic speech recognition (ASR) corresponding to the segments of the video, or the optical character recognition (OCR) of the key frames in the video. All of these may closely relate to the video. The specific implementation needs to consider the specific business scenario; for instance, if you plan to utilize text from the video for video retrieval, then OCR must undoubtedly be included in the text.
Q12: How is noise, such as BGM, filtered out in ASR?
A12: The noise filtering model we designed has robust capabilities for recognizing BGM. This functionality utilizes mature open-source models. On the other hand, even if the model fails to filter out noise, it may not matter, as the BGM typically consists of lyrics. For purely musical BGM, ASR will not output any text. The background music that can output text is generally lyrics, but the correlation of lyrics to the video content can usually be adjusted through training vision-language relevance models, such as models similar to Chinese Clip.
Q13: Does video retrieval involve online real-time inference? Is it done offline T+1, or is it real-time streaming? If online real-time inference is performed, how does such a large model handle it?
A13: Real-time inference is possible. Taking video-text semantic retrieval as an example, after effective training, we can utilize the video at the time of storage to obtain the overall embedding of the video through the trained model. We can then store this embedding in a vector retrieval database. For text retrieval, the usual approach is to query text online. We can deploy relatively lightweight solutions, such as lightweight processing of the text model using quantization and enhanced streaming methods, to produce lightweight models that match the video part. In practical retrieval, we only need to run this lightweight model to extract the representation of the text in real-time and then conduct quantitative retrieval against the previously stored video vectors in the underlying database. There are many methods to enhance speed for retrieval, such as implementing real-time retrieval based on vector libraries like faiss.
Q14: What vector databases do you commonly use?
A14: Internally, we use a retrieval platform called Qianxun, which is not an open-source product. However, its implementation principles are fundamentally similar to those of the Facebook open-source vector retrieval database, faiss.
Thank you for your attention to this presentation.
Editor: Yu Tengkai
Proofreader: Lin Ganmin
