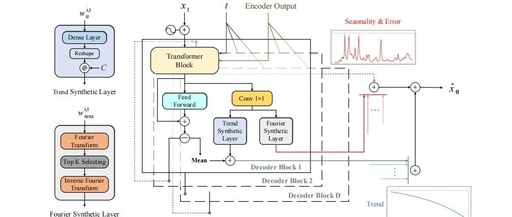
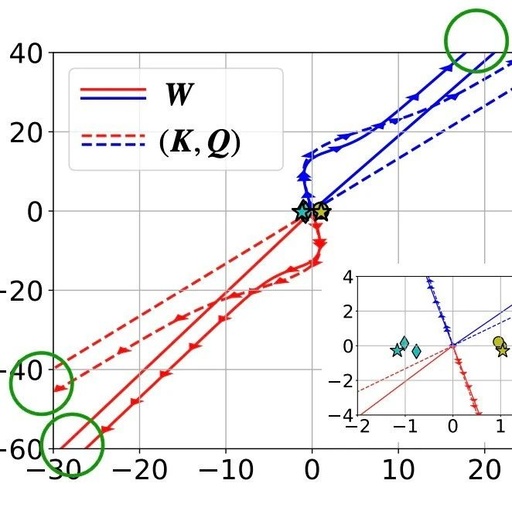
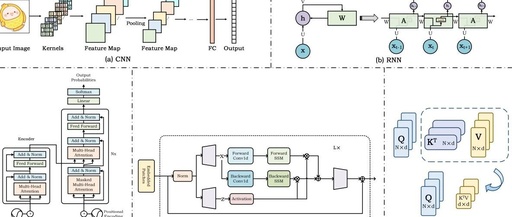
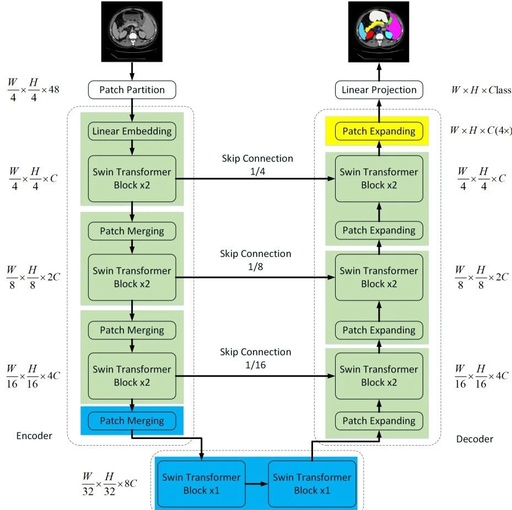
A Detailed Guide to Self-Attention Mechanism

Author: Greatness Comes from Perseverance @ Zhihu (Authorized) Source: https://zhuanlan.zhihu.com/p/410776234 Self-Attention is the core idea of Transformer. Recently, I re-read the paper and gained some new insights. Thus, I wrote this article to share my thoughts with readers. When I first encountered Self-Attention, the most confusing part for me was the three matrices Q, K, … Read more