

MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, covering NLP graduate students, university professors, and researchers in enterprises.The vision of the community is to promote communication and progress between academia, industry, and enthusiasts in natural language processing and machine learning, especially for beginners. Reprinted from | NewBeeNLP
Author: nghuyong Zhihu: https://zhuanlan.zhihu.com/p/580468546
“Paper”: Scaling Instruction-Finetuned Language Models “Link”: https://arxiv.org/abs/2210.11416 “Model”: https://huggingface.co/google/flan-t5-xxl
1
What is Flan-T5
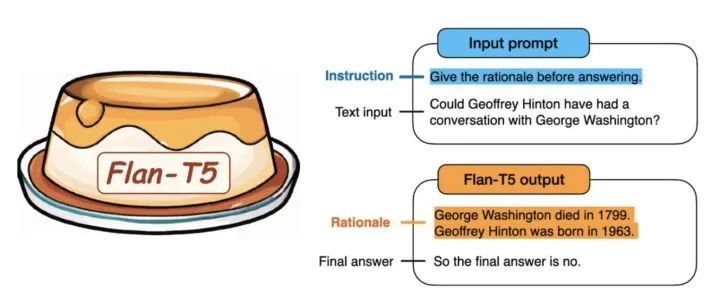
Flan-T5 is Google’s latest work that, through fine-tuning on a large scale, enables the language model to possess strong generalization capabilities, allowing a single model to perform well on over 1800 NLP tasks. This means that once the model is trained, it can be directly used for almost all NLP tasks, achieving “One model for ALL tasks”, which is very enticing!
Here, Flan refers to (Instruction fine-tuning), which is “instruction-based fine-tuning”; T5 is a language model released by Google in 2019. Note that the language model here can be replaced arbitrarily (it needs to have a Decoder part, so “pure Encoder language models like BERT are excluded”). The core contribution of the paper is to propose a multi-task fine-tuning scheme (Flan) to greatly enhance the generalization of language models.
Flat
For example, in the following article, once the model is trained, it can directly perform question answering:
The “model input” is: “Did Geoffrey Hinton and George Washington ever talk? Think about the reasons before answering.”
The “model output” is: Geoffrey Hinton is a computer scientist born in 1947; George Washington died in 1799. So they could not have talked. Therefore, the answer is “No”.
2
How It Works
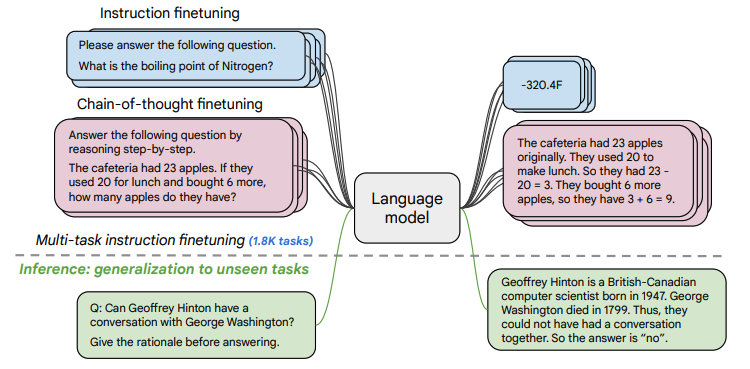
1800+ fine-tuning tasks
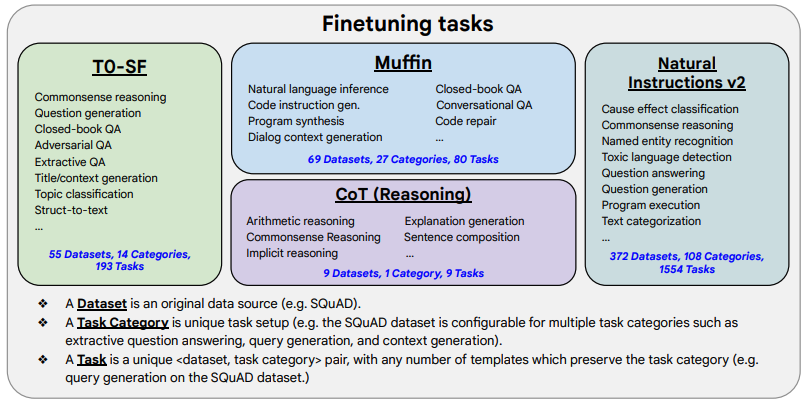
(1) Task Collection: The first step of the work is to collect a series of supervised data, where a task can be defined in the form of
(2) Format Rewrite: Since a single language model needs to complete over 1800 different tasks, it is necessary to convert all tasks into the same “input format” for model training, and the outputs of these tasks also need to be in a uniform “output format”.
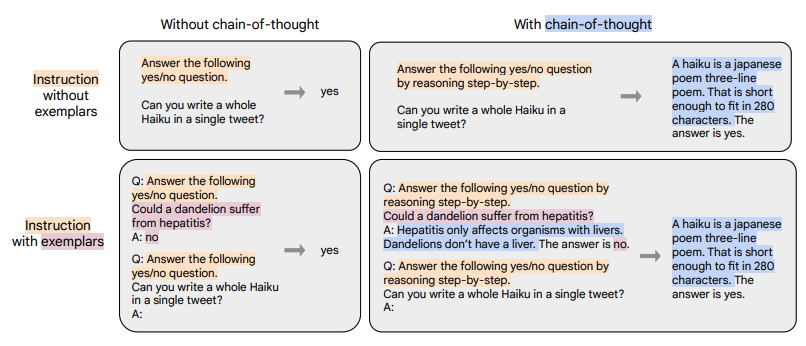
Input and Output Format
As shown in the figure above, based on “whether reasoning is required (CoT)” and “whether examples are provided (Few-shot)”, the input and output can be divided into four types:
-
chain-of-thought: ❎ and few-shot: ❎ (top left in the figure)
-
Input: Instruction + Question
-
Output: Answer
-
chain-of-thought: ✅ and few-shot: ❎ (top right in the figure)
-
Input: Instruction + CoT guide (by reasoning step by step) + Question
-
Output: Reason + Answer
-
chain-of-thought: ❎ and few-shot: ✅ (bottom left in the figure)
-
Input: Instruction + Example Question + Example Answer + Instruction + Question
-
Output: Answer
-
chain-of-thought: ✅ and few-shot: ✅ (bottom right in the figure)
-
Input: Instruction + CoT guide + Example Question + Example Reason + Example Answer + Instruction + CoT guide + Question
-
Output: Reason + Answer
(3) Training Process: A constant learning rate and the Adafactor optimizer are used for training; multiple training samples are “packed” into a single training sample, which are directly split by a special “end token”. During training, model evaluation is conducted on the “retained tasks” at each specified step, and the best checkpoint is saved.

Retained Tasks
Although there are many fine-tuning tasks, the computational load is significantly smaller compared to the pre-training process of the language model, only 0.2%. Therefore, through this scheme, language models trained by large companies can be effectively reused; we only need to perform “fine-tuning” without having to spend a lot of computational resources to train a language model again.

Comparison of Computational Load Between Fine-tuning and Pre-training
3
Some Conclusions
(1) Fine-tuning is Important
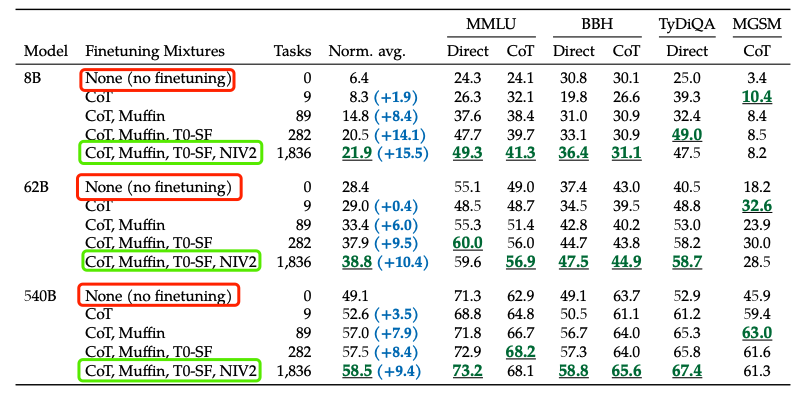
Direct Prediction (Red Box) vs. Fine-tuning (Green Box)
Compared to no fine-tuning, instruction-based fine-tuning (Flan) can significantly improve the performance of the language model.
(2) The Larger the Model, the Better the Performance
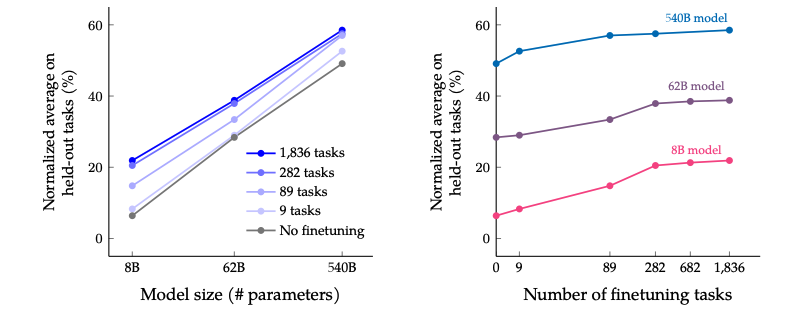
Impact of Model Size on Task Quantity and Performance
As the model size increases (left in the figure), especially exponentially, such as from 8B to 62B, and then from 62B to 540B, the performance improves significantly regardless of whether fine-tuning is applied, and no signs of convergence have been observed. It is possible that if a “trillion” parameter model is developed, performance can continue to improve.
(3) The More Tasks, the Better the Performance
As the number of tasks increases (right in the figure), the model’s performance also increases, but when the number of tasks exceeds 282, the improvement is not very significant. This is because adding new tasks, especially those similar to previous ones, will not provide new knowledge to the model; the essence of multi-task fine-tuning is that the model can better express the knowledge learned from pre-training. After a certain number of tasks, continuing to add similar tasks will not yield significant benefits in knowledge expression capability. Further statistics on the total number of tokens in all fine-tuning datasets show that they only account for 0.2% of the pre-training data tokens, indicating that there is still a lot of knowledge that has not been reactivated during the fine-tuning phase.
(4) Mixing CoT-related Tasks is Important
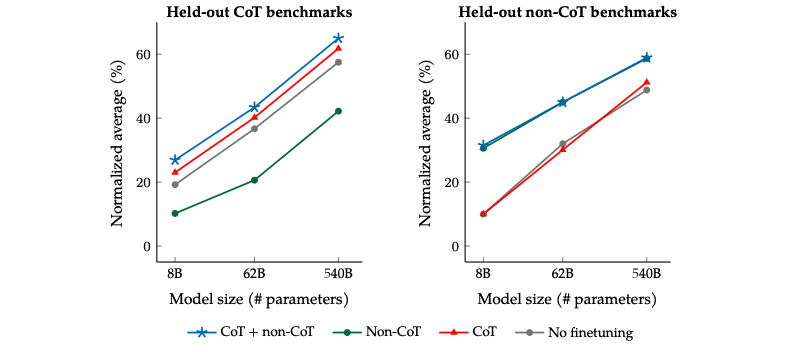
CoT-related Tasks and Non-CoT-related Tasks in Retained Tasks
Although there are only 9 tasks that require reasoning to provide answers (CoT tasks) among the 1800+ tasks, mixing these 9 tasks leads to significant improvements in the overall model. In predictions for CoT-related tasks, mixing CoT tasks during fine-tuning can lead to noticeable improvements (blue and green lines in the left figure); for non-CoT-related tasks, mixing CoT tasks during fine-tuning does not harm the model (blue and green lines in the right figure).
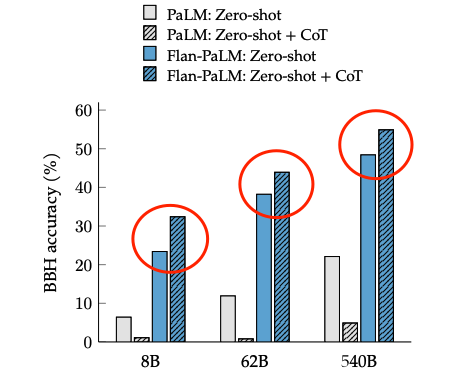
Comparison of Zero-shot with and without CoT
(5) Integration
Ultimately, experiments conducted on models of various sizes yield consistent conclusions: introducing the Flan fine-tuning scheme can significantly enhance the overall performance of language models on large-scale tasks.
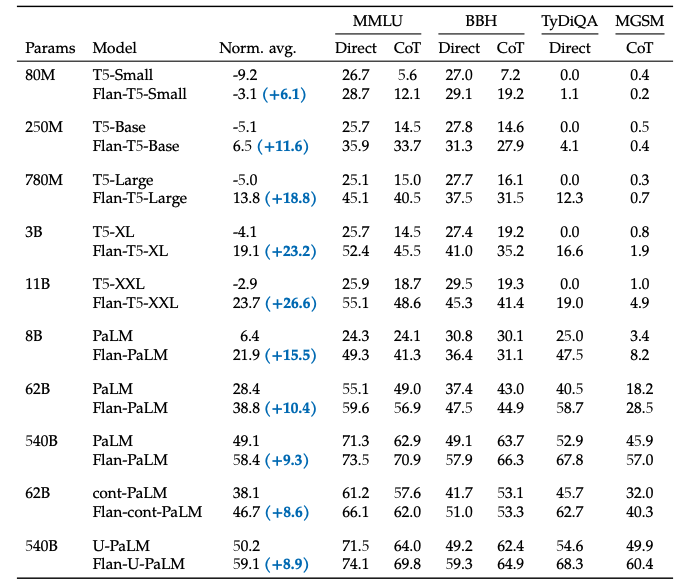
Different Versions of the Model
In summary, this work proposes the Flan fine-tuning framework, which has four core points: unified input-output format (4 types), introduction of chain-of-thought, significant increase in task quantity, and significant increase in model size; achieving the resolution of over 1800 NLP tasks with a single model, greatly enhancing the generalization performance of existing language models at a low cost, and showing hope for universal models, namely “One Model for ALL Tasks”.
Technical Group Invitation

△ Long press to add assistant
Scan the QR code to add the assistant on WeChat
Please note: Name – School/Company – Research Direction(e.g., Xiao Zhang – Harbin Institute of Technology – Dialogue Systems) to apply for joining Natural Language Processing / Pytorch and other technical groups
About Us
MLNLP Community is a grassroots academic community jointly built by scholars in machine learning and natural language processing from home and abroad. It has developed into a well-known machine learning and natural language processing community, aiming to promote progress among academia, industry, and enthusiasts in machine learning and natural language processing.The community can provide an open communication platform for practitioners’ further studies, employment, and research. Everyone is welcome to follow and join us.
