
In the era following deep learning, the Transformer architecture has demonstrated its powerful performance in pre-trained large models and various downstream tasks. However, the significant computational demands of this architecture have deterred many researchers. To further reduce the complexity of attention models, numerous efforts have been invested in designing more efficient methods. Among these, the State Space Model (SSM) has gained increasing attention as a potential alternative to Transformer models based on self-supervised learning. In this paper, we provide the first comprehensive review of these works and offer experimental comparisons and analyses to better showcase the features and advantages of SSM. Specifically, we first detail the principles to help readers quickly grasp the key ideas of SSM. Then, we thoroughly review existing SSMs and their various applications in natural language processing, computer vision, graphics, multimodal and multimedia, point clouds/event streams, time series data, and more. Additionally, we provide statistical comparisons and analyses of these models, hoping to assist readers in understanding the effectiveness of different structures across various tasks. We also propose possible research directions to better promote the development of SSM theoretical models and applications. More related work will be continuously updated on the following GitHub: https://github.com/Event-AHU/Mamba State Space Model Paper List.
https://www.zhuanzhi.ai/paper/b84be72b4ad41b3ec43132c107bd2e7a
The third wave of rapid development in artificial intelligence, which began in 2010, has seen deep learning technology based on connectionism play an extremely important role. The singularity of deep learning can be traced back to the introduction of AlexNet[1], which achieved the best performance in the ImageNet[2] competition (far surpassing the second place). Since then, various convolutional neural networks (CNNs) have been proposed, such as VGG[3], ResNet[4], GoogleNet[5], etc. The ideas of blocks, residual connections, and Inception have inspired many subsequent designs of deep neural networks[6],[7]. On the other hand, the family of recurrent neural networks (RNNs), such as Long Short-Term Memory networks (LSTM)[8] and Gated Recurrent Units (GRU)[9], has dominated the field of sequence-based learning, including natural language processing and audio processing. To further expand the application of deep neural networks to graph data, Graph Neural Networks (GNNs)[10],[11] were proposed. However, these mainstream models still face bottlenecks when dataset and computational power reach their limits.
To address the issue that CNN/RNN/GNN models can only capture local relationships, the Transformer[13], proposed in 2017, can effectively learn long-range feature representations. The core operation is the self-supervised learning mechanism, which transforms input tokens into query, key, and value features, and outputs long-range features through the similarity matrix obtained from the product of query and key features multiplied by value features. The Transformer architecture was first widely applied in the natural language processing community through the pre-training and fine-tuning paradigm[14], with models like BERT[15], ERNIE[16], BART[17], GPT[18]. Subsequently, other fields have also been propelled by these networks, such as ViT[19] and Swin-Transformer[20] released in computer vision. Many researchers have also explored hybrid network architectures by combining Transformers with other networks or adapting Transformers to multimodal research problems[21],[22]. At the current stage, large foundational models are emerging, and Parameter-Efficient Fine-Tuning (PEFT) strategies[23] have also developed significantly. However, current Transformer-based models still require high-end GPUs with large memory for training and testing/deployment, which greatly limits their widespread application.
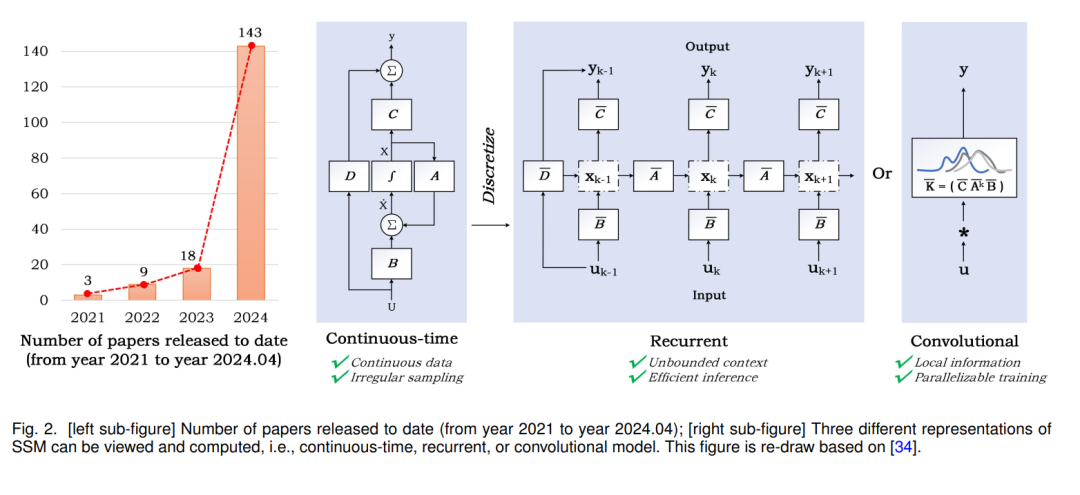
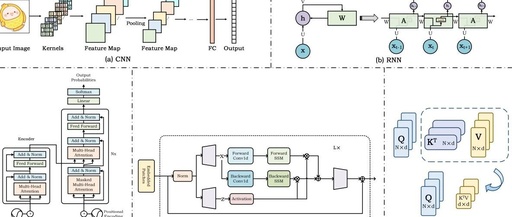
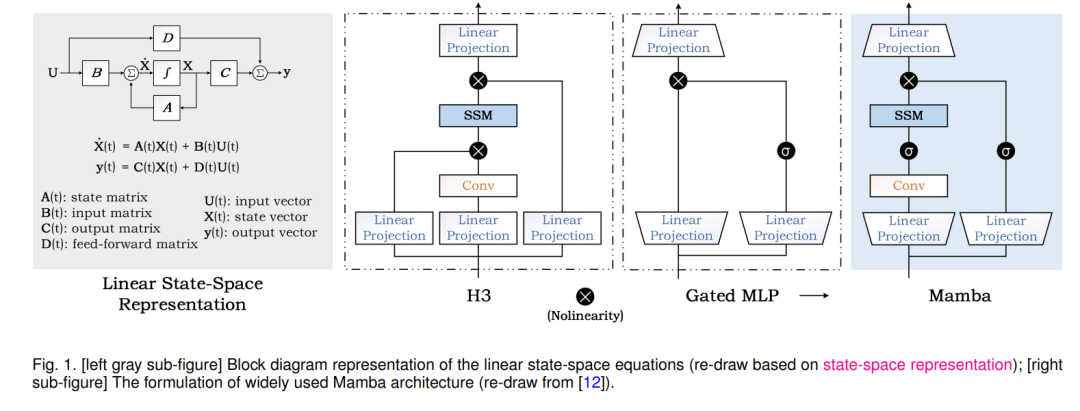
To further reduce computational costs while capturing long-range dependencies and maintaining high performance, many new models based on sparse attention or new neural network paradigms have been proposed[24]–[28]. Among them, State Space Models (e.g., Mamba [12], S4 [29], S4nd [30]), as shown in Figure 1, have become the center of attention. As shown in the left part of Figure 2, the publication volume of papers related to SSM shows an explosive growth trend. The State Space Model (SSM) was originally proposed as a framework to simulate dynamic systems in control theory, computational neuroscience, and other fields using state variables. When this concept is applied to deep learning, we typically refer to linear time-invariant (or stable) systems. The original SSM is a continuous dynamic system that can be discretized to fit the recursive and convolutional perspectives of computer processing. SSM can be used for various data processing and feature learning, including image/video data, text data, structured graph data, event streams/point cloud data, multimodal/multimedia data, audio and speech, time series data, tabular data, etc. It can also be used to build efficient generative models, such as SSM-based diffusion generative models[31]–[33]. To help readers better understand SSM and keep track of the latest research progress and various applications, this article provides a systematic review of the field and experimentally validates the performance of SSM models in downstream tasks. We hope this review can better guide and promote the development of the SSM field.
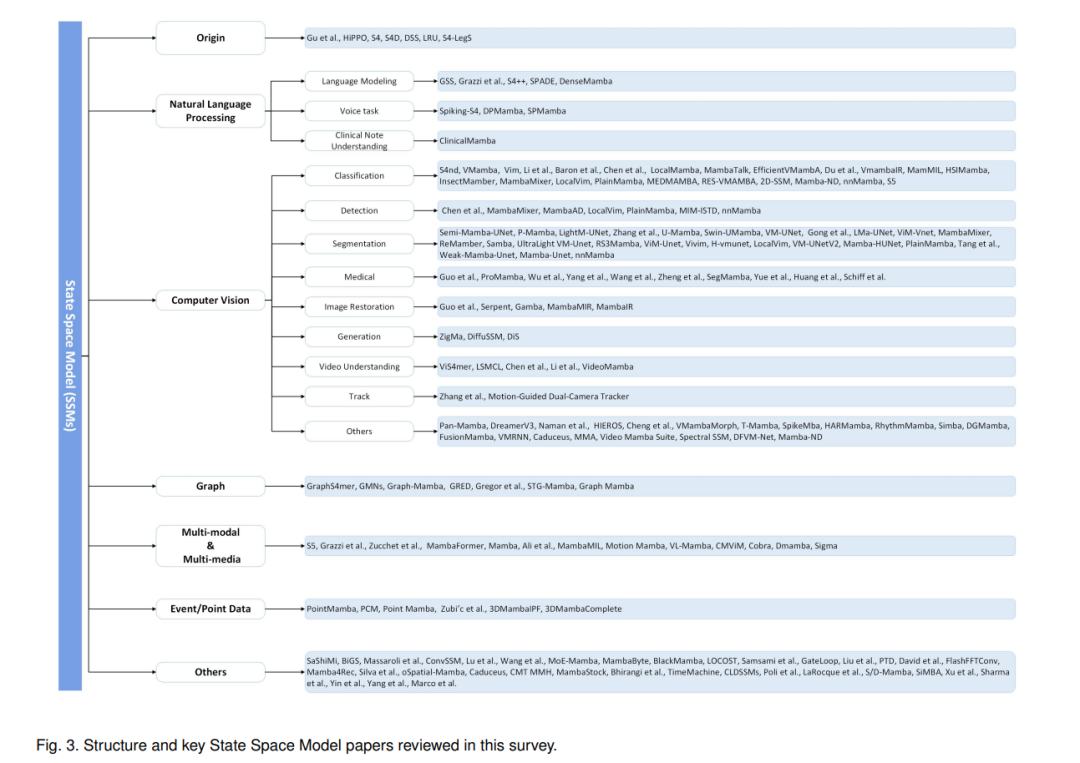
Organization of this Review. In this article, we first provide a preliminary overview of the working principles of State Space Models in Section 2. Then, in Section 3, we focus on reviewing related work on SSM from multiple aspects, including the origins and variants of SSM, natural language processing, computer vision, graphics, multimodal and multimedia, point clouds/event streams, time series data, and other fields. An overview of the structures and key papers related to State Space Models reviewed in this article is illustrated in Figure 3. More importantly, in Section 4, we conduct extensive experiments on multiple downstream tasks to validate the effectiveness of SSM in these tasks. The downstream tasks involve single/multi-label classification, visual object tracking, pixel-level segmentation, image-to-text generation, and person/vehicle re-identification. We also propose several possible research directions in Section 5 to facilitate the theory and applications of SSM. Finally, in Section 6, we summarize this article.
Convenient Access to ZHUANZHI
Convenient Download, please followZHUANZHI WeChat account (click the blue button above to follow ZHUANZHI)
Reply or send message “SSMT” to get the download link for “Is Transformer Indispensable? Latest Review on State Space Model (SSM)” from ZHUANZHI.

Click “Read the Original” to learn how to use ZHUANZHI and view over 100,000 AI-themed knowledge materials